Chirp 3 est la dernière génération de modèles génératifs multilingues de reconnaissance vocale automatique de Google. Ils sont conçus pour répondre aux besoins des utilisateurs en fonction de leurs commentaires et de leur expérience. Chirp 3 offre une justesse et une vitesse supérieures à celles des modèles Chirp précédents et propose également l'identification des locuteurs et la détection automatique de la langue.
Informations sur le modèle
Chirp 3 : Transcription, est disponible exclusivement dans l'API Speech-to-Text V2.
Identifiants de modèle
Vous pouvez utiliser Chirp 3 : Transcription comme n'importe quel autre modèle en spécifiant l'identifiant de modèle approprié dans votre demande de reconnaissance lorsque vous utilisez l'API ou le nom du modèle dans la console Google Cloud . Spécifiez l'identifiant approprié dans votre reconnaissance.
| Modèle | Identifiant du modèle |
|---|---|
| Chirp 3 | chirp_3 |
Méthodes d'API
Les ensembles de langues disponibles ne sont pas les mêmes pour toutes les méthodes de reconnaissance. Chirp 3 étant disponible dans l'API Speech-to-Text V2, il est compatible avec les méthodes de reconnaissance suivantes :
| Version de l'API | Méthode API | Compatibilité |
|---|---|---|
| V2 | Speech.StreamingRecognize (convient pour le streaming et l'audio en temps réel) | Compatible |
| V2 | Speech.Recognize (convient pour les contenus audio de moins d'une minute) | Compatible |
| V2 | Speech.BatchRecognize (convient pour les contenus audio longs de 1 min à 1 h) | Compatible |
Disponibilité en fonction des régions
Chirp 3 est disponible dans les régions Google Cloud suivantes (d'autres sont prévues) :
| ZoneGoogle Cloud | Disponibilité pour le lancement |
|---|---|
us (multi-region) |
DG |
eu (multi-region) |
DG |
asia-northeast1 |
DG |
asia-southeast1 |
DG |
asia-south1 |
Preview |
europe-west2 |
Preview |
europe-west3 |
Preview |
northamerica-northeast1 |
Preview |
Comme expliqué ici, l'API de localisation vous permet de trouver la liste actualisée des régions, langues, paramètres régionaux et fonctionnalités Google Cloud compatibles pour chaque modèle de transcription.
Langues disponibles pour la transcription
Chirp 3 prend en charge la transcription dans les méthodes StreamingRecognize, Recognize et BatchRecognize dans les langues suivantes :
| Langue | BCP-47 Code |
Disponibilité pour le lancement |
| Catalan (Espagne) | ca-ES | DG |
| Chinois (simplifié, Chine) | cmn-Hans-CN | DG |
| Croate (Croatie) | hr-HR | DG |
| Danois (Danemark) | da-DK | DG |
| Néerlandais (Pays-Bas) | nl-NL | DG |
| Anglais (Australie) | en-AU | DG |
| Anglais (Royaume-Uni) | en-GB | DG |
| Anglais (Inde) | en-IN | DG |
| Anglais (États-Unis) | en-US | DG |
| Finnois (Finlande) | fi-FI | DG |
| Français (Canada) | fr-CA | DG |
| Français (France) | fr-FR | DG |
| Allemand (Allemagne) | de-DE | DG |
| Grec (Grèce) | el-GR | DG |
| Hindi (Inde) | hi-IN | DG |
| Italien (Italie) | it-IT | DG |
| Japonais (Japon) | ja-JP | DG |
| Coréen (Corée) | ko-KR | DG |
| Polonais (Pologne) | pl-PL | DG |
| Portugais (Brésil) | pt-BR | DG |
| Portugais (Portugal) | pt-PT | DG |
| Roumain (Roumanie) | ro-RO | DG |
| Russe (Russie) | ru-RU | DG |
| Espagnol (Espagne) | es-ES | DG |
| Espagnol (États-Unis) | es-US | DG |
| Suédois (Suède) | sv-SE | DG |
| Turc (Turquie) | tr-TR | DG |
| Ukrainien (Ukraine) | uk-UA | DG |
| Vietnamien (Viêt Nam) | vi-VN | DG |
| Arabe | ar-XA | Preview |
| Arabe (Algérie) | ar-DZ | Preview |
| Arabe (Bahreïn) | ar-BH | Preview |
| Arabe (Égypte) | ar-EG | Preview |
| Arabe (Israël) | ar-IL | Preview |
| Arabe (Jordanie) | ar-JO | Preview |
| Arabe (Koweït) | ar-KW | Preview |
| Arabe (Liban) | ar-LB | Preview |
| Arabe (Mauritanie) | ar-MR | Preview |
| Arabe (Maroc) | ar-MA | Preview |
| Arabe (Oman) | ar-OM | Preview |
| Arabe (Qatar) | ar-QA | Preview |
| Arabe (Arabie saoudite) | ar-SA | Preview |
| Arabe (État de Palestine) | ar-PS | Preview |
| Arabe (Syrie) | ar-SY | Preview |
| Arabe (Tunisie) | ar-TN | Preview |
| Arabe (Émirats arabes unis) | ar-AE | Preview |
| Arabe (Yémen) | ar-YE | Preview |
| Arménien (Arménie) | hy-AM | Preview |
| Bengali (Bangladesh) | bn-BD | Preview |
| Bengali (Inde) | bn-IN | Preview |
| Bulgare (Bulgarie) | bg-BG | Preview |
| Birman (Myanmar) | my-MM | Preview |
| Sorani (Irak) | ar-IQ | Preview |
| Chinois cantonais (traditionnel, Hong Kong) | yue-Hant-HK | Preview |
| Chinois mandarin (traditionnel, Taïwan) | cmn-Hant-TW | Preview |
| Tchèque (République tchèque) | cs-CZ | Preview |
| Anglais (Philippines) | en-PH | Preview |
| Estonien (Estonie) | et-EE | Preview |
| Philippin (Philippines) | fil-PH | Preview |
| Gujarati (Inde) | gu-IN | Preview |
| Hébreu (Israël) | iw-IL | Preview |
| Hongrois (Hongrie) | hu-HU | Preview |
| Indonésien (Indonésie) | id-ID | Preview |
| Kannada (Inde) | kn-IN | Preview |
| Khmer (Cambodge) | km-KH | Preview |
| Laotien (Laos) | lo-LA | Preview |
| Letton (Lettonie) | lv-LV | Preview |
| Lituanien (Lituanie) | lt-LT | Preview |
| Malais (Malaisie) | ms-MY | Preview |
| Malayalam (Inde) | ml-IN | Preview |
| Marathi (Inde) | mr-IN | Preview |
| Népalais (Népal) | ne-NP | Preview |
| Norvégien (Norvège) | no-NO | Preview |
| Persan (Iran) | fa-IR | Preview |
| Serbe (Serbie) | sr-RS | Preview |
| Slovaque (Slovaquie) | sk-SK | Preview |
| Slovène (Slovénie) | sl-SI | Preview |
| Espagnol (Mexique) | es-MX | Preview |
| Swahili | sw | Preview |
| Tamoul (Inde) | ta-IN | Preview |
| Télougou (Inde) | te-IN | Preview |
| Thaï (Thaïlande) | th-TH | Preview |
| Ouzbek (Ouzbékistan) | uz-UZ | Preview |
Langues disponibles pour l'identification des locuteurs
Chirp 3 prend en charge la transcription et l'identification des locuteurs uniquement dans les méthodes BatchRecognize et Recognize dans les langues suivantes :
| Langue | Code BCP-47 |
| Chinois (simplifié, Chine) | cmn-Hans-CN |
| Allemand (Allemagne) | de-DE |
| Anglais (Royaume-Uni) | en-GB |
| Anglais (Inde) | en-IN |
| Anglais (États-Unis) | en-US |
| Espagnol (Espagne) | es-ES |
| Espagnol (États-Unis) | es-US |
| Français (Canada) | fr-CA |
| Français (France) | fr-FR |
| Hindi (Inde) | hi-IN |
| Italien (Italie) | it-IT |
| Japonais (Japon) | ja-JP |
| Coréen (Corée) | ko-KR |
| Portugais (Brésil) | pt-BR |
Compatibilité des fonctionnalités et limites
Chirp 3 est compatible avec les fonctionnalités suivantes :
| Fonctionnalité | Description | Étape de lancement |
|---|---|---|
| Ponctuation automatique | Générée automatiquement par le modèle, elle peut être désactivée. | DG |
| Mise en majuscules automatique | Générée automatiquement par le modèle, elle peut être désactivée. | DG |
| Codes temporels au niveau de l'énoncé | Générée automatiquement par le modèle. | DG |
| Identification du locuteur | Identifie automatiquement les différents locuteurs dans un extrait audio à un seul canal (mono). Disponible uniquement dans BatchRecognize |
DG |
| Adaptation vocale (biais) | Fournit des suggestions au modèle sous la forme d'expressions ou de mots pour améliorer la justesse de la reconnaissance de termes ou de noms propres spécifiques. | DG |
| Transcription audio indépendante de la langue | Déduit automatiquement la langue la plus courante et transcrit dans cette langue. | DG |
Chirp 3 n'est pas compatible avec les fonctionnalités suivantes :
| Fonctionnalité | Description |
| Codes temporels au niveau du mot | Générée automatiquement par le modèle et peut être activée ou non. Une certaine dégradation de la transcription est à prévoir. |
| Scores de confiance au niveau du mot | L'API renvoie une valeur, mais ce n'est pas réellement un score de confiance. |
Transcrire avec Chirp 3
Découvrez comment utiliser Chirp 3 pour les tâches de transcription.
Effectuer une reconnaissance vocale en streaming
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_streaming_chirp3(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Effectuer une reconnaissance vocale synchrone
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Effectuer une reconnaissance vocale par lot
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text v2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Utiliser les fonctionnalités de Chirp 3
Découvrez comment utiliser les dernières fonctionnalités grâce à des exemples de code :
Effectuer une transcription indépendante de la langue
Chirp 3 peut identifier et transcrire automatiquement la langue dominante parlée dans l'audio, ce qui est essentiel pour les applications multilingues. Pour ce faire, définissez language_codes=["auto"] comme indiqué dans l'exemple de code :
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Effectuer une transcription limitée à une langue
Chirp 3 peut identifier et transcrire automatiquement la langue dominante d'un fichier audio. Vous pouvez également le conditionner selon des paramètres régionaux spécifiques attendus, par exemple ["en-US", "fr-FR"], ce qui concentrerait les ressources du modèle sur les langues les plus probables pour obtenir des résultats plus fiables, comme le montre l'exemple de code :
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_3_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 3.
Please see https://cloud.google.com/speech-to-text/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US", "fr-FR"], # Set language codes of the expected spoken locales
model="chirp_3",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Effectuer une transcription et une identification des locuteurs
Utilisez Chirp 3 pour les tâches de transcription et d'identification des locuteurs.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client.
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language.
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
# Enable diarization by setting empty diarization configuration.
diarization_config=cloud_speech.SpeakerDiarizationConfig(),
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Creates audio transcription job.
operation = client.batch_recognize(request=request)
print("Waiting for transcription job to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript
Améliorer la justesse grâce à l'adaptation de modèle
Chirp 3 peut améliorer la justesse de la transcription de vos contenus audio spécifiques grâce à l'adaptation de modèle. Cette fonctionnalité vous permet de fournir une liste de mots et d'expressions spécifiques, ce qui augmente la probabilité que le modèle les reconnaisse. Cela est particulièrement utile pour les termes spécifiques à un domaine, les noms propres ou le vocabulaire singulier.
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Activer la suppression du bruit et le filtrage par SNR
Chirp 3 peut améliorer la qualité audio en réduisant le bruit de fond et en filtrant les sons indésirables avant la transcription. Vous pouvez améliorer les résultats dans les environnements bruyants en activant la suppression du bruit intégrée et le filtrage du rapport signal/bruit (SNR).
Le paramètre denoiser_audio=true peut vous aider à réduire efficacement la musique ou les bruits de fond comme la pluie et la circulation.
Vous pouvez définir snr_threshold=X pour contrôler le volume sonore vocal minimal requis pour la transcription. Cela permet de filtrer les éléments audio non vocaux ou le bruit de fond, ce qui évite d'obtenir du texte indésirable dans vos résultats. Un snr_threshold élevé signifie que l'utilisateur doit parler plus fort pour que le modèle transcrive les énoncés.
Le filtrage par SNR peut être utilisé dans les cas d'utilisation de flux en temps réel pour éviter d'envoyer des sons inutiles à un modèle pour la transcription. Plus la valeur de ce paramètre est élevée, plus le volume de votre voix doit être élevé par rapport au bruit de fond pour être envoyé au modèle de transcription.
La configuration de snr_threshold interagira avec la valeur de denoise_audio (true ou false). Lorsque denoise_audio=true, le bruit de fond est supprimé et la voix devient relativement plus claire. Le SNR global de l'audio augmente.
Si votre cas d'utilisation n'implique que la voix de l'utilisateur sans que d'autres personnes parlent, définissez denoise_audio=true pour augmenter la sensibilité du filtrage par SNR, qui peut filtrer les bruits non vocaux. Si votre cas d'utilisation implique des personnes qui parlent en arrière-plan et que vous souhaitez éviter de transcrire les paroles en arrière-plan, envisagez de définir denoise_audio=false et d'abaisser le seuil de SNR.
Voici les valeurs de seuil de SNR recommandées. Une valeur snr_threshold raisonnable peut être définie entre 0 et 1000. La valeur 0 signifie qu'aucun filtre n'est appliqué, et la valeur 1000 signifie que tout est filtré. Ajustez la valeur si le paramètre recommandé ne fonctionne pas pour vous.
| Supprimer le bruit de l'audio | Seuil SNR | Sensibilité vocale |
|---|---|---|
| vrai | 10 | élevé |
| vrai | 20 | moyen |
| vrai | 40 | faible |
| vrai | 100 | très faible |
| faux | 0,5 | élevé |
| faux | 1 | moyen |
| faux | 2 | faible |
| faux | 5 | très faible |
Python
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
REGION = "us"
def transcribe_sync_chirp3_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 3 model of Google Cloud Speech-to-Text v2 API, which provides word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint=f"{REGION}-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_3",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/{REGION}/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Utiliser Chirp 3 dans la console Google Cloud
- Créez un compte Google Cloud et un projet.
- Accédez à Speech dans la console Google Cloud .
- Si l'API n'est pas activée, activez-la.
Assurez-vous de disposer d'un espace de travail de la console STT. Si vous n'avez pas d'espace de travail, vous devez en créer un.
Accédez à la page des transcriptions, puis cliquez sur Nouvelle transcription.
Ouvrez le menu déroulant Espace de travail et cliquez sur Nouvel espace de travail afin de créer un espace de travail pour la transcription.
Dans la barre latérale de navigation Créer un espace de travail, cliquez sur Parcourir.
Cliquez pour créer un nouveau bucket.
Saisissez un nom pour ce bucket, puis cliquez sur Continuer.
Cliquez sur Créer pour créer votre bucket Cloud Storage.
Une fois le bucket créé, cliquez sur Sélectionner pour le sélectionner.
Cliquez sur Créer pour terminer la création de votre espace de travail pour la console de l'API Speech-to-Text V2.
Effectuez une transcription de votre contenu audio.
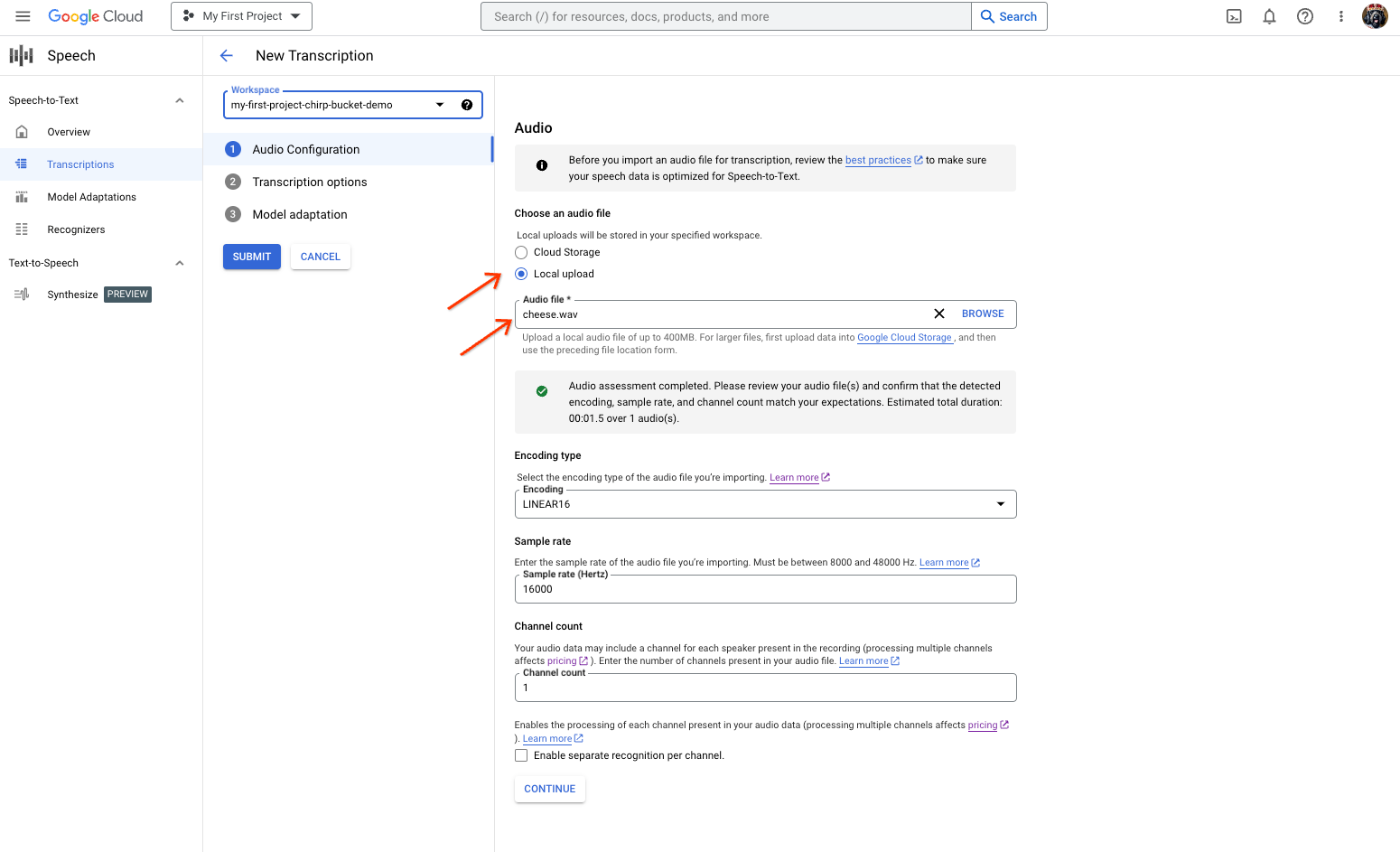
Page de création de la transcription Speech-to-Text, montrant la sélection ou l'importation de fichiers. Sur la page Nouvelle transcription, sélectionnez votre fichier audio via une importation (importation locale) ou en spécifiant un fichier Cloud Storage existant (Cloud Storage).
Cliquez sur Continuer pour passer aux Options de transcription.
Sélectionnez la Langue parlée que vous prévoyez d'utiliser pour la reconnaissance avec le modèle Chirp à partir de l'outil de reconnaissance que vous avez créé précédemment.
Dans le menu déroulant des modèles, sélectionnez chirp_3.
Dans le menu déroulant Outil de reconnaissance, sélectionnez l'outil de reconnaissance que vous venez de créer.
Cliquez sur Envoyer pour exécuter votre première requête de reconnaissance à l'aide de
chirp_3.
Affichez le résultat de la transcription Chirp 3.
Sur la page Transcriptions, cliquez sur le nom de la transcription pour afficher son résultat.
Sur la page Détails de la transcription, observez le résultat de votre transcription et, éventuellement, lancez la lecture du contenu audio dans le navigateur.