Este artigo é a terceira parte de uma série de quatro partes que discute como prever o valor de vida útil do cliente (CLV, na sigla em inglês) usando o AI Platform no Google Cloud.
Os artigos desta série incluem:
- Parte 1: Introdução. Introduz o conceito de CLV e apresenta duas técnicas de modelagem para prevê-lo.
- Parte 2: Treinamento do modelo. Aborda como preparar os dados e treinar os modelos.
- Parte 3: como implantar em produção (este artigo). Descreve como implantar os modelos discutidos na parte 2 em um sistema de produção.
- Parte 4: como usar as tabelas do AutoML. Mostra como usar tabelas do AutoML para criar e implantar um modelo.
Como instalar o código
Se você quiser seguir o processo descrito neste artigo, precisará instalar a amostra de código no GitHub.
Se a CLI gcloud estiver instalada, abra uma janela de terminal no computador para executar estes comandos. Se a CLI gcloud não estiver instalada, abra uma instância do Cloud Shel.
Clone o repositório do código de amostra:
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
Siga as instruções de instalação nas seções Instalação e Automação do arquivo README para configurar seu ambiente e implementar os componentes da solução. Eles incluem o conjunto de dados de exemplo e o ambiente do Cloud Composer.
Os exemplos de comando nas seções a seguir supõem que você concluiu essas duas etapas.
Como parte das instruções de instalação, você configura variáveis para seu ambiente conforme descrito na seção de configuração do arquivo README.
Altere a variável REGION para corresponder à região Google Cloud geograficamente mais próxima de você. Para uma lista de regiões, consulte
Regiões e zonas.
Arquitetura e implementação
O diagrama a seguir mostra a arquitetura usada nesta discussão.

A arquitetura é dividida nas funções a seguir:
- Ingestão de dados: os dados são importados para o BigQuery.
- Preparação de dados: os dados brutos são transformados para se tornarem utilizáveis pelos modelos.
- Treinamento de modelo: os modelos são criados, treinados e ajustados para que possam ser usados para executar predições.
- Serviço de predição: as predições off-line são armazenadas e disponibilizadas em latência baixa.
- Automação: todas essas tarefas são executadas e gerenciadas pelo Cloud Composer.
Como ingerir dados
Esta série de artigos não aborda uma maneira específica de realizar a ingestão de dados. Há muitas maneiras de o BigQuery ingerir dados, incluindo do Pub/Sub, do Cloud Storage e do serviço de transferência de dados do BigQuery. Para mais informações, consulte BigQuery para usuários de armazenamento de dados. Na abordagem descrita nesta série, usamos um conjunto de dados público. Você importa esse conjunto de dados para o BigQuery, conforme descrito no código de exemplo no arquivo README.
Como preparar dados
Para preparar dados, é necessário executar consultas no BigQuery como aquelas mostradas na Parte 2 desta série. Em uma arquitetura de produção, você executa as consultas como parte de um gráfico acíclico direcionado (DAG) do Apache Airflow. A seção sobre automação, mais adiante neste documento, apresenta mais detalhes sobre a execução de consultas para preparação de dados.
Como treinar o modelo no AI Platform
Esta seção apresenta uma visão geral da parte de treinamento da arquitetura.
Seja qual for o tipo de modelo escolhido, o código exibido nesta solução é empacotado para ser executado no AI Platform, para treinamento e predição. O AI Platform oferece os seguintes benefícios:
- Execute-o localmente ou na nuvem em um ambiente distribuído.
- conectividade integrada a outros produtos do Google, como o Cloud Storage
- possibilidade de execução com apenas alguns comandos
- facilidade de ajuste de hiperparâmetros
- Ele é dimensionado com alterações mínimas de infraestrutura, se houver.
Para que o AI Platform possa treinar e avaliar um modelo, você precisa fornecer conjuntos de dados de treinamento, avaliação e teste. Crie os conjuntos de dados executando consultas SQL como aquelas mostradas na Parte 2 desta série. Exporte esses conjuntos de dados das tabelas do BigQuery para o Cloud Storage. Na arquitetura de produção descrita neste artigo, as consultas são executadas por um DAG do Airflow, descrito mais detalhadamente na seção Automação abaixo. É possível executar o DAG manualmente, conforme descrito na seção Executar DAGs do arquivo README.
Como disponibilizar predições
As predições podem ser criadas on-line ou off-line. Mas criar é diferente de disponibilizar predições. Nesse contexto de CLV, eventos como um cliente acessando um site ou visitando uma loja de varejo não afetarão drasticamente o valor da vida útil dele. Portanto, as predições podem ser feitas off-line, mesmo que os resultados precisem ser apresentados em tempo real. A predição off-line tem os seguintes recursos operacionais:
- É possível executar as mesmas etapas de pré-processamento para o treinamento e a predição. Se o treinamento e a predição forem pré-processados de maneira diferente, é possível que suas predições sejam menos precisas. Esse fenômeno é chamado desvio na disponibilização de treinamento.
- É possível usar as mesmas ferramentas para preparar os dados para treinamento e para predição. A abordagem discutida nesta série emprega principalmente o BigQuery para preparar dados.
É possível usar o AI Platform para implantar o modelo e fazer previsões off-line usando um job em lote. Para predição, o AI Platform facilita tarefas como as seguintes:
- Gerenciamento de versões
- escalonamento com mudanças mínimas de infraestrutura
- Implantação em grande escala
- Interagir com outros Google Cloud produtos.
- Fornecimento de um SLA
A tarefa de predição em lote usa arquivos armazenados no Cloud Storage para entrada e saída. Para o modelo DNN, a função de exibição a seguir, definida em task.py, define o formato das entradas:
O formato de saída da previsão é definido em um EstimatorSpec retornado pela função de modelo Estimator neste código de model.py:
Como usar predições
Depois que você terminar de criar os modelos e implantá-los, poderá usá-los para realizar predições de CLV. Veja a seguir casos de uso comuns do CLV:
- Um especialista em dados pode aproveitar as predições off-line ao criar segmentos de usuários.
- Sua organização pode fazer ofertas específicas em tempo real quando um cliente interage com sua marca on-line ou em uma loja.
Google Analytics com o BigQuery
Compreender o CLV é fundamental para as ativações. Este artigo se concentra principalmente no cálculo do valor da vida útil com base nas vendas anteriores. Os dados de vendas geralmente vêm de ferramentas de gestão de relacionamento com o cliente (CRM), mas as informações sobre o comportamento do usuário podem ter outras fontes, como o Google Analytics 360.
Recomenda-se usar o BigQuery caso você tenha interesse em realizar uma das seguintes tarefas:
- Armazenar dados estruturados de várias fontes
- Transferir dados automaticamente de ferramentas de SaaS comuns, como o Google Analytics 360, o YouTube ou o AdWords
- Executar consultas específicas, incluindo junções em terabytes de dados do cliente
- Visualizar seus dados usando as principais ferramentas de business intelligence
Além da função de armazenamento gerenciado e mecanismo de consulta, o BigQuery pode executar algoritmos de machine learning diretamente usando o BigQuery ML. Ao carregar o valor CLV de cada cliente no BigQuery, você permite que analistas de dados, cientistas e engenheiros aproveitem métricas adicionais em suas tarefas. O DAG do Airflow discutido na próxima seção inclui uma tarefa para carregar as predições de CLV no BigQuery.
Como veicular com baixa latência usando o Datastore
É possível reutilizar as predições off-line para fornecer predições em tempo real. Neste cenário, a atualização das predições não é essencial, mas ter acesso aos dados no momento certo e de forma conveniente é.
O armazenamento de predições off-line para disponibilização em tempo real significa que as ações realizadas por um cliente não alteram o CLV imediatamente. No entanto, é importante ter acesso a esse CLV rapidamente. Por exemplo, sua empresa pode precisar reagir rapidamente quando um cliente usa seu site, faz uma pergunta ao seu helpdesk ou faz check-out usando seu ponto de venda. Em casos como esses, uma resposta rápida pode melhorar seu relacionamento com o cliente. Portanto, armazenar a saída de sua predição em um banco de dados rápido e disponibilizar consultas seguras para seu front-end são ações fundamentais para o sucesso.
Vamos supor que você tenha centenas de milhares de clientes únicos. O Datastore é uma boa opção pelos seguintes motivos:
- É compatível com bancos de dados de documentos NoSQL.
- Fornece acesso rápido aos dados usando uma chave (ID de cliente), mas também permite consultas SQL.
- É acessível por meio de uma API REST.
- Está pronto para usar, o que significa que não há sobrecarga de configuração.
- Escalona automaticamente.
Como não há como carregar diretamente um conjunto de dados CSV no Datastore, nesta solução usamos o Apache Beam no Dialogflow com um modelo JavaScript para carregar as predições de CLV no Datastore. O seguinte trecho de código do modelo JavaScript mostra como fazer isso:
Quando os dados estão no Datastore, é possível escolher como interagir com eles, incluindo:
- Usar as bibliotecas de cliente do Datastore no seu app.
- Criar um endpoint da API usando o Cloud Endpoints ou o Apigee API Platform.
- Usar as funções do Cloud Run para tarefas sem servidor.
Como automatizar a solução
As etapas descritas até agora são seguidas quando você está começando a usar os dados para executar as primeiras etapas de pré-processamento, de treinamento e de predição. Mas sua plataforma ainda não está pronta para produção, porque você ainda precisa de automação e de gerenciamento de falhas.
Alguns scripts podem ajudar a unir as etapas. No entanto, recomenda-se automatizar as etapas usando um gerenciador de fluxo de trabalho. O Apache Airflow (link em inglês) é uma ferramenta conhecida de gerenciamento de fluxo de trabalho. É possível usar o Cloud Composer (link em inglês) para executar um pipeline gerenciado do Airflow no Google Cloud.
O Airflow funciona com gráficos acíclicos direcionados (DAG, na sigla em inglês), que permitem especificar cada tarefa e como ela se relaciona com outras tarefas. Na abordagem descrita nesta série, você executa as seguintes etapas:
- Crie conjuntos de dados do BigQuery.
- Carregue o conjunto de dados público do Cloud Storage para o BigQuery.
- Limpe os dados de uma tabela do BigQuery e grave-os em uma nova.
- Crie recursos com base em dados de uma tabela do BigQuery e grave-os em outra.
- Se o modelo for uma rede neural profunda (DNN, na sigla em inglês), divida os dados em um conjunto de treinamento e outro de avaliação no BigQuery.
- Exporte os conjuntos de dados para o Cloud Storage e disponibilize-os para o AI Platform.
- Faça com que o AI Platform treine periodicamente o modelo.
- Implante o modelo atualizado no AI Platform.
- Execute periodicamente uma predição em lote em novos dados.
- Salve as previsões que já estão salvas no Cloud Storage no Datastore e no BigQuery.
Como configurar o Cloud Composer
Para saber como configurar o Cloud Composer, consulte as instruções no arquivo README do repositório do GitHub.
Gráficos acíclicos direcionados para esta solução
Esta solução usa dois DAGs. O primeiro DAG abrange os passos de 1 a 8 da sequência listada anteriormente:
O diagrama a seguir mostra a interface do usuário do Cloud Composer/Airflow, que resume as etapas de 1 a 8 do DAG do Airflow.
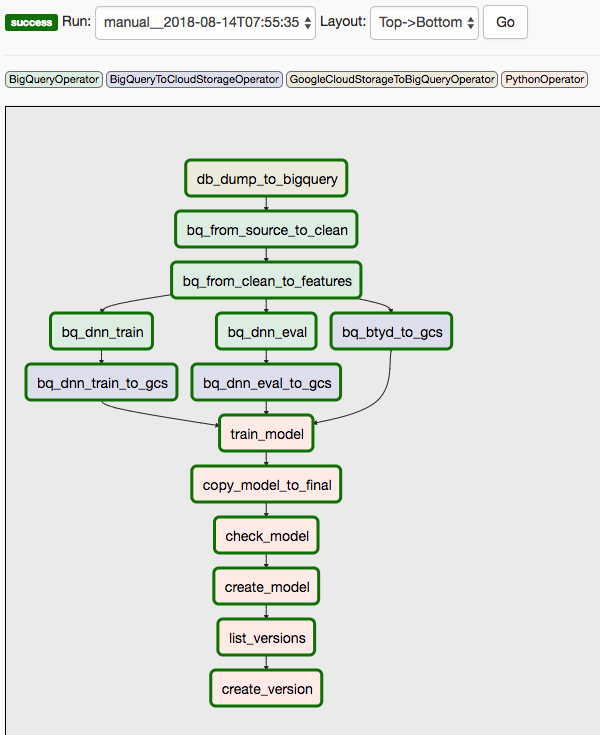
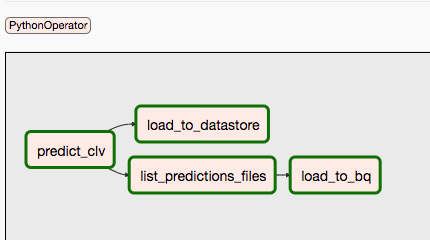
O segundo DAG abrange as etapas 9 e 10.
O diagrama a seguir resume as etapas 9 e 10 do processo do DAG do Airflow.
Os DAGs são separados porque as predições e o treinamento podem acontecer de forma independente e em um cronograma diferente. Por exemplo, é possível fazer o seguinte:
- Prever dados para clientes novos ou atuais diariamente.
- Treinar o modelo semanalmente para incorporar novos dados ou iniciá-lo após um número específico de novas transações ser recebido.
Para acionar o primeiro DAG manualmente, execute o comando na seção Run Dags do arquivo README no Cloud Shell ou use a CLI gcloud.
O parâmetro conf passa as variáveis para diferentes partes da automação. Por exemplo, na consulta SQL a seguir usada para extrair recursos dos dados limpos, as variáveis são usadas para parametrizar a cláusula FROM:
Você pode acionar o segundo DAG usando um comando semelhante. Para ver mais detalhes, veja o arquivo README no repositório do GitHub.
A seguir
- Execute o exemplo completo no repositório do GitHub.
- Execute novos recursos no modelo CLV usando alguns dos procedimentos a seguir:
- Dados de fluxo de cliques, que podem ajudar você a prever o CLV para clientes de quem você não tem dados históricos.
- Departamentos e categorias de produtos que podem oferecer mais contexto e ajudar a rede neural.
- Novos recursos que você cria usando as mesmas entradas usadas nessa solução. Os exemplos incluem tendências de vendas para as semanas ou meses finais antes da data limite.
- Leia a Parte 4: como usar as tabelas do AutoML para o modelo.
- Saiba mais sobre outras soluções de previsão preditiva.
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.