本教程介绍如何使用跨区域只读副本在 Cloud SQL for MySQL 中完成完整的灾难恢复 (DR) 故障切换和回退过程。
在本教程中,您将设置一个高可用性 (HA) Cloud SQL for MySQL 实例进行灾难恢复,并模拟服务中断情况。然后逐步完成灾难恢复过程,以便在解决服务中断问题后恢复初始部署。
本教程面向数据库架构师、管理员和工程师。
如需大致了解 SQL 灾难恢复的工作原理,请参阅 Cloud SQL 中的灾难恢复简介。
目标
- 创建高可用性 Cloud SQL for MySQL 实例。
- 使用 Cloud SQL for MySQL 在 Google Cloud 上部署一个跨区域只读副本。
- 使用 Cloud SQL for MySQL 模拟灾难和故障切换情况。
- 了解通过将回退过程与 Cloud SQL for MySQL 搭配使用来恢复初始部署的步骤。
本文档仅重点介绍跨区域灾难恢复故障切换和回退过程。如需了解单区域高可用性故障切换过程,请参阅高可用性配置概览。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
第 1 阶段:设置高可用性数据库实例进行灾难恢复
以下阶段 (1-3) 将引导您完成完整的故障切换和回退过程。您可以在 Cloud Shell 中使用
gcloud命令来运行所有命令。为了简化该过程,本教程会尽可能使用默认设置(例如,默认的 Cloud SQL 版本)。在生产环境中,您可以添加其他配置。设置环境变量
本部分提供环境变量示例,这些变量定义您在本教程中运行的命令所需的各种名称和区域。您可以根据需要调整这些示例变量。
下表介绍本教程中灾难恢复和回退过程的每个阶段的实例名称、角色及其部署区域。您也可以提供您自己的名称和区域。
初始阶段 实例名称 角色 区域 instance-1主要 us-west1instance-2备用实例 us-west1instance-3跨区域只读副本 us-west2灾难阶段 实例名称 角色 区域 instance-3主要 us-west2instance-4备用实例 us-west2instance-5跨区域只读副本 us-west3instance-6跨区域只读副本 us-west1回退(最终)阶段 实例名称 角色 区域 instance-6主要 us-west1instance-7备用实例 us-west1instance-8跨区域只读副本 us-west2前面的表格中的实例名称未使用其角色进行编码。在灾难恢复情况下,实例的功能可能会发生变化 - 例如,副本可能会成为主实例。如果新的主实例的名称包含
replica一词,则可能会出现混淆和冲突。因此,我们建议不要使用实例执行的功能或角色对实例名称进行编码。前面的表格列出了备用实例的名称。尽管本教程不练习高可用性故障切换,但本教程包含备用实例的名称以使得内容完整。
回退阶段会在相同的原始区域中重新创建初始阶段的原始部署。但是,在回退阶段,实例名称必须更改,因为原始名称不会立即可用,即使在原始实例遭到删除后也是如此。为了支持在回退阶段快速创建实例,您应该使用与初始阶段所使用的名称不匹配的实例名称。
在 Cloud Shell 中,根据上表中的规范设置环境变量:
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2如果要对主实例使用不同层级,请列出您可以使用的层级,然后为 primary_tier 赋予不同的值:
gcloud sql tiers list如需查看可在其中部署 Cloud SQL 的区域列表,请参阅实例设置。
创建主数据库实例
在 Cloud Shell 中,创建实例(指 Cloud SQL 实例):
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regiongcloud命令将暂停,直到创建了实例。设置 root 密码:
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
创建主数据库
在 Cloud Shell 中,登录 MySQL Shell 并在提示符处输入 root 密码:
gcloud sql connect $primary_name --user=root在 MySQL 提示符处,创建数据库并上传测试数据:
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");检查数据是否已成功提交:
SELECT * FROM entries;验证是否返回了两行数据。
退出 MySQL Shell:
exit;
此时,您已拥有一个包含一个表和一些测试数据的数据库。
将主实例切换为高可用性数据库实例
您只能将 Cloud SQL 配置为区域级高可用性系统,不能配置为跨区域系统。(设置跨区域只读副本不同于将 Cloud SQL 配置为跨区域系统。)如需了解详情,请参阅对实例启用和停用高可用性。
在 Cloud Shell 中,创建已启用高可用性的 Cloud SQL 实例:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
通过自动更新添加一个跨区域只读副本进行灾难恢复
以下步骤足以创建适合本教程的跨区域只读副本:
在 Cloud Shell 中,设置一个跨区域只读副本:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(可选)如需检查数据库是否已复制,请在Google Cloud 控制台中转到 Cloud SQL 实例页面。
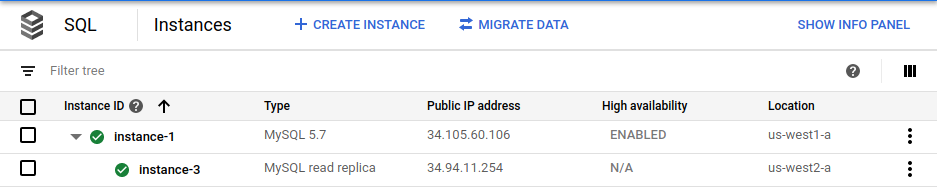
Google Cloud 控制台显示主实例 (
instance-1) 启用了高可用性,并且存在跨区域读取副本 (instance-3)。使用主实例的同一 root 密码登录跨区域只读副本:
gcloud sql connect $cross_region_replica_name --user=root在 MySQL 提示符处,选择数据以确保复制正常执行:
USE guestbook; SELECT * FROM entries;退出 MySQL Shell:
exit;
如需详细了解如何设置完整的跨区域只读副本,请参阅 Cloud SQL 文档
对于生产环境中的大型数据库,建议您备份主数据库并从备份创建跨区域只读副本。此步骤有助于缩短只读副本与主数据库同步所需的时间。下一部分会介绍此过程。不过,您可以选择跳过此步骤,继续执行第 2 阶段。
根据转储文件添加跨区域只读副本
如需优化跨区域只读副本的创建,一种方法是从先前一致的主数据库状态同步副本,而不是在访问新的主实例时进行同步。此类优化需要创建一个转储文件供副本用作启动状态。
如需了解根据转储文件创建副本的步骤,请参阅从外部服务器复制到 Cloud SQL (v1.1)。此方法对于大型生产数据库会很有帮助。但是,本教程跳过了此步骤,因为测试数据集够小,足以进行完整的复制。
第 2 阶段:模拟灾难情况(区域服务中断)
在此阶段,您将通过使主数据库不可用,模拟生产设置中主要区域服务中断的情况。
检查是否存在跨区域只读副本延迟
在以下步骤中,您将确定跨区域只读副本的复制延迟:
在 Google Cloud 控制台中,打开 Cloud SQL 实例页面。
点击只读副本 (instance-3)。
在指标下拉列表中,点击复制延迟:
此时,指标会更改为复制延迟。此图表显示无延迟:
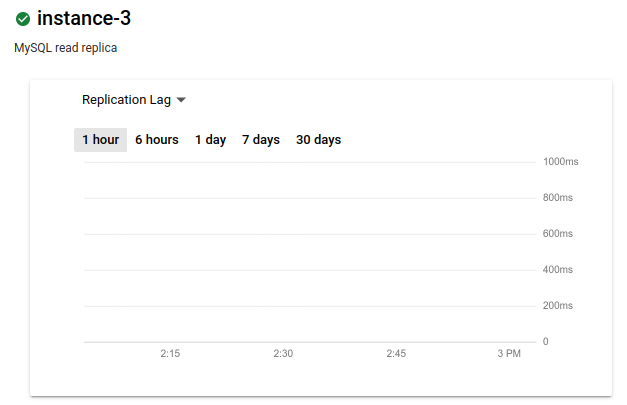
理想情况下,当主要区域发生服务中断时,复制延迟为零,因为延迟为零可确保复制所有事务。如果延迟不为零,则可能不会复制某些事务。在这种情况下,跨区域只读副本不会包含已在主实例上提交的所有事务。
使主实例不可用
在以下步骤中,您将通过停止主实例来模拟灾难情况。如果将跨区域只读副本附加到主实例,您必须先分离副本,否则无法停止 Cloud SQL 实例。
在 Cloud Shell 中,从主实例移除跨区域只读副本:
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replication当系统提示时,请接受继续操作的选项。
停止主数据库实例:
gcloud sql instances patch $primary_name --activation-policy NEVER
实施灾难恢复
在 Cloud Shell 中,将跨区域只读副本提升为独立实例:
gcloud sql instances promote-replica $cross_region_replica_name当系统提示时,请接受继续操作的选项。Cloud SQL 实例页面会显示之前的跨区域只读副本 (
instance-3) 作为新的主实例,而先前的主实例 (instance-1) 已停止:
将跨区域只读副本提升为新的主实例后,您便可以为其启用高可用性。最佳做法是使用适当的命名更新环境变量。
更新环境变量:
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3启动新的主实例:
gcloud sql instances patch $primary_name --activation-policy ALWAYS启用新的主实例作为高可用性区域实例:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_time在第三个区域中创建一个跨区域只读副本:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region在前面的步骤中,您已将
cross_region_replica_region环境变量设置为us-west3。故障切换完成后, Google Cloud 控制台中的 Cloud SQL 实例页面会显示新的主实例 (
instance-3) 启用了高可用性并具有跨区域读取副本 (instance-5):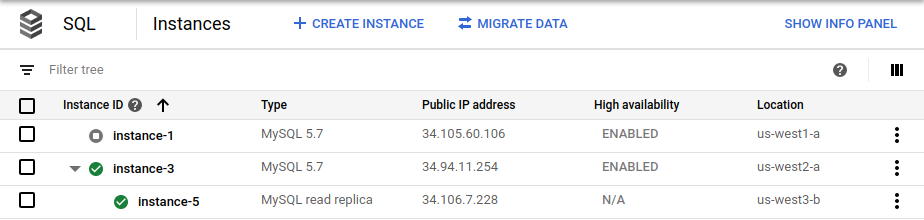
(可选)如果您有定期备份,请按照前面所述的过程操作,将新的主实例与最新的备份版本同步。
(可选)如果您使用的是 Cloud SQL 代理,请配置代理以使用新的主实例来恢复应用处理。
处理短期区域服务中断
触发故障切换的服务中断可能会在故障切换完成之前得到解决。在这种情况下,或许较佳的做法是取消故障切换过程并继续使用发生服务中断的区域中的 Cloud SQL 原始主实例。
根据故障切换过程的特定状态,可能已提升跨区域只读副本。在这种情况下,您必须将其删除,然后重新创建跨区域只读副本。
删除原始主实例可避免出现脑裂情况
为避免出现脑裂情况,您需要删除原始主实例(或使数据库客户端无法访问它)。
进行故障切换后,如果客户端同时写入原始主数据库和新的主数据库,则可能会发生脑裂情况。在这种情况下,两个数据库的内容不一致。进行故障切换后,原始主数据库已过时,不得接收任何读写流量。
在 Cloud Shell 中,删除原始主实例:
gcloud sql instances delete $former_primary_name当系统提示时,请接受继续操作的选项。
在 Google Cloud 控制台中,Cloud SQL 实例页面在部署过程中不再显示原始主实例 (
instance-1):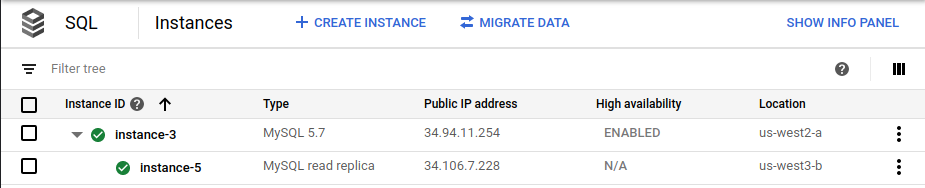
第 3 阶段:实施回退
如需在原始区域 (R1) 可用后回退到该区域,请遵循第 2 阶段中所述的过程。该过程总结如下:
在原始区域 (R1) 中创建第二个跨区域只读副本。此时,主实例有两个跨区域只读副本,一个位于区域 R3,另一个位于区域 R1。
将 R1 中的跨区域只读副本提升为最终主实例。
为最后的主实例启用高可用性。
在
us-west2中创建最终主实例的跨区域只读副本。为避免出现脑裂情况,请删除不再需要的所有实例(R3 中的原始主实例和跨区域只读副本)。
如前所述,最佳做法是创建一个初始备份,其中包含定义给新的主数据库的起始状态。
最终部署现在具有一个高可用性主实例(名称为
instance-6)和一个跨区域只读副本(名称为instance-8)。比较手动灾难恢复和自动灾难恢复的优缺点
下表介绍了手动或自动实施灾难恢复过程的优缺点。其目的不是为了确定正确的方法和错误的方法,而是提供条件来帮助您根据自己的需求确定最佳方法。
手动执行 自动执行 优势:
- 您需要严格控制每一个步骤。
- 您可以即时查看、解决和记录流程中的任何问题。
- 您可以在故障切换期间查看和检查每个流程步骤。
优势:
- 您可以实施和测试故障切换过程。
- 自动化技术可提供最快的实施方案,并最大限度地缩短延迟时间。
- 实施方案由人类操作员、操作员的知识以及他们可以参与的时间决定。
缺点:
- 手动实施流程会拖慢流程速度。
- 人为输入错误可能会导致问题。
- 测试此过程通常涉及多个角色和时间,从而阻碍您进行定期测试。
缺点:
- 如果出现不可预见的错误,您必须在生产故障切换期间进行调试。
- 如果在该过程中遇到错误,您需要使用脚本从上次中断的地方继续(恢复)。
- 您需要充分了解脚本及其实施方案,以便了解脚本的行为,尤其是在发生错误的情况下。
根据最佳做法,我们建议从手动实施开始入手。然后,自愿定期(最好是在生产环境中)运行该实施方案以确保手动过程正常运行,并且所有团队成员都知道各自的职责和责任。我们建议您在分步过程文档中定义手动过程。每次实施后,您应确认或优化过程文档。
对过程进行微调并确信它可靠之后,您便可以确定是否要自动执行该过程。如果您选择并实施自动化过程,则需要在生产环境中测试该过程,以确保能够可靠地实施该过程。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,您可以删除为本教程创建的 Google Cloud 项目。
删除项目
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
- 了解 Cloud SQL 灾难恢复。
- 了解 Compute Engine 上的 MySQL 的灾难恢复。
- 了解云基础架构服务中断的灾难恢复架构。
- 探索有关 Google Cloud 的参考架构、图表和最佳实践。查看我们的 Cloud 架构中心。