Die Pseudonymisierung ist eine De-Identifikationstechnik, die sensible Datenwerte durch kryptografisch generierte Tokens ersetzt. Die Pseudonymisierung ist in Branchen wie Finanzbranche und Gesundheitswesen weit verbreitet, um das Risiko der Datennutzung zu reduzieren, den Geltungsbereich der Compliance zu minimieren und die Exposition vertraulicher Daten in Systemen zu minimieren, ohne die Datennutzbarkeit und -genauigkeit zu beeinträchtigen.
Sensitive Data Protection unterstützt drei Pseudonymisierungsmethoden für die De-Identifikation und generiert Tokens durch Anwenden einer von drei kryptografischen Transformationsmethoden auf ursprünglich sensible Datenwerte. Jeder ursprüngliche sensible Wert wird dann durch das entsprechende Token ersetzt. Die Pseudonymisierung wird manchmal als Tokenisierung oder Wertersetzung bezeichnet.
Pseudonymisierungsmethoden aktivieren entweder unidirektionale oder bidirektionale Tokens. Ein unidirektionales Token wurde irreversibel transformiert, während ein Bidirektionales-Token umgekehrt werden kann. Da das Token mithilfe der symmetrischen Verschlüsselung erstellt wird, können Tokens mit demselben kryptografischen Schlüssel neu erstellt werden mit dem sie ebenfalls umgekehrt werden können. In Situationen, in denen keine Umkehrbarkeit erforderlich ist, können Sie unidirektionale Tokens mit sicheren Hashing-Mechanismen verwenden.
Es ist hilfreich, zu verstehen, wie Pseudonymisierung vertrauliche Daten schützen kann, während Ihre Geschäftsvorgänge und analytischen Workflows weiterhin einfachen Zugriff auf die benötigten Daten haben und diese verwenden können. In diesem Thema werden das Konzept der Pseudonymisierung und die drei kryptografischen Methoden zur Transformation von Daten erläutert, die vom Schutz sensibler Daten unterstützt werden.
Eine Anleitung zum Implementieren dieser Pseudonymisierungsmethoden und weitere Beispiele für die Verwendung von Sensitive Data Protection finden Sie unter Sensible Daten de-identifizieren.
Unterstützte kryptografische Methoden in Sensitive Data Protection
Der Schutz sensibler Daten unterstützt drei Pseudonymisierungstechniken, die alle drei kryptografische Schlüssel verwenden. Folgende Methoden sind verfügbar:
- Deterministische Verschlüsselung mit AES-SIV: Ein Eingabewert wird durch einen Wert ersetzt, der mit dem Verschlüsselungsalgorithmus AES-SIV mit einem kryptografischen Schlüssel verschlüsselt und mit base64 codiert wurde. Optional wird eine Ersatzannotation vorangestellt, sofern angegeben. Diese Methode erzeugt einen Hash-Wert, sodass der Zeichensatz oder die Länge des Eingabewerts nicht beibehalten wird. Verschlüsselte Hash-Werte können mit dem ursprünglichen kryptografischen Schlüssel und dem gesamten Ausgabewert, einschließlich der Ersatzannotation, neu identifiziert werden. Weitere Informationen zum Format der Werte, die mithilfe der AES-SIV-Verschlüsselung tokenisiert werden.
- Formaterhaltende Verschlüsselung:Ein Eingabewert wird durch einen Wert ersetzt, der mit dem Verschlüsselungsalgorithmus FPE-FFX mit einem kryptografischen Schlüssel verschlüsselt wurde. Wenn angegeben, wird eine Ersatzannotation vorangestellt. Sowohl der Zeichensatz als auch die Länge des Eingabewerts werden im Ausgabewert beibehalten. Verschlüsselte Werte können mit dem ursprünglichen kryptografischen Schlüssel und dem gesamten Ausgabewert, einschließlich Ersatzannotation, re-identifiziert werden. Wichtige Hinweise zur Verwendung dieser Verschlüsselungsmethode finden Sie weiter unten in diesem Thema unter Formaterhaltende Verschlüsselung.
- Kryptografisches Hashing: Ein Eingabewert wird durch einen Wert ersetzt, der mithilfe des Hash-basierten Message Authentication Code (HMAC)-Secure Hash-Algorithmus (SHA)-256 mit einem kryptografischen Schlüssel generiert und gehasht wurde. Die gehashte Ausgabe der Transformation hat immer dieselbe Länge und kann nicht re-identifiziert werden. Weitere Informationen zum Format von Werten, die mit kryptografischem Hashing tokenisiert werden.
Die Merkmale dieser Pseudonymisierungsmethoden sind in der folgenden Tabelle zusammengefasst. Die Tabellenzeilen werden im Anschluss an die Tabelle erläutert.
| Deterministische Verschlüsselung mit AES-SIV | Formaterhaltende Verschlüsselung | Kryptografisches Hashing | |
|---|---|---|---|
| Verschlüsselungstyp | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Unterstützte Eingabewerte | Mindestens 1 Zeichen lang; keine Zeichensatzbeschränkungen. | Mindestens 2 Zeichen lang, muss in ASCII codiert sein. | Muss ein String oder ein ganzzahliger Wert sein. |
| Ersatzannotation | Optional. | Optional. | – |
| Kontextoptimierung | Optional. | Optional. | – |
| Zeichensatz und Länge beibehalten | ✗ | ✓ | ✗ |
| Umkehrbar | ✓ | ✓ | ✗ |
| Referenzielle Integrität | ✓ | ✓ | ✓ |
- Verschlüsselungstyp: Die Art der Verschlüsselung, die in der De-Identifikationstransformation verwendet wird.
- Unterstützte Eingabewerte: Mindestanforderungen für Eingabewerte.
- Ersatzannotation:Eine benutzerdefinierte Annotation, die verschlüsselten Werten vorangestellt wird, um Nutzern Kontext zu bieten und Sensitive Data Protection Informationen zur Re-Identifikation eines de-identifizierten Werts zu geben. Für die Re-Identifikation unstrukturierter Daten ist eine Ersatzannotation erforderlich. Dies ist optional bei der Transformation einer Spalte von strukturierten oder tabellarischen Daten mit
RecordTransformation. - Kontextoptimierung: Ein Verweis auf ein Datenfeld, das den Eingabewert "optimiert", sodass identische Eingabewerte in verschiedene Ausgabewerte de-identifiziert werden können. Die Kontextoptimierung ist optional, wenn eine Spalte von strukturierten oder tabellarischen Daten mit
RecordTransformationtransformiert wird. Weitere Informationen finden Sie unter Kontextoptimierungen verwenden. - Zeichensatz und Länge beibehalten: Gibt an, ob ein de-identifizierter Wert aus demselben Zeichensatz wie der ursprüngliche Wert besteht, und ob die Länge des de-identifizierten Werts mit der Länge des ursprünglichen Werts übereinstimmt.
- Umkehrbar: Kann mit dem kryptografischen Schlüssel, der Ersatzannotation und jeder Kontextoptimierung re-identifiziert werden.
- Referenzielle Integrität:Durch referenzielle Integrität können Datensätze ihre Beziehung zueinander aufrechterhalten, auch wenn die Daten einzeln de-identifiziert werden. Bei gleichem kryptografischem Schlüssel und Kontextoptimierung wird eine Datentabelle bei jeder Transformation durch dieselbe verschleierte Form ersetzt, wodurch Verbindungen zwischen Werten (und bei strukturierten Daten auch zwischen Datensätzen) beibehalten werden, auch über Tabellen hinweg.
So funktioniert die Tokenisierung im Schutz sensibler Daten
Der grundlegende Ablauf der Tokenisierung ist für alle drei Methoden, die vom Schutz sensibler Daten unterstützt werden, identisch.
Schritt 1: Sensitive Data Protection wählt Daten zum Tokenisieren aus. Die gängigste Methode hierfür ist die Verwendung eines integrierten oder benutzerdefinierten infoType-Detektors, um die gewünschten sensiblen Datenwerte abzugleichen. Wenn Sie strukturierte Daten (z. B. eine BigQuery-Tabelle) durchsuchen, können Sie mithilfe von Datensatztransformationen auch die Tokenisierung für ganze Datenspalten durchführen.
Weitere Informationen zu den beiden Arten von Transformationen – "InfoType" und "Datensatz-Transformationen" – finden Sie unter Transformationen zur De-Identifikation.
Schritt 2: Sensitive Data Protection verschlüsselt mit einem kryptografischen Schlüssel jeden Eingabewert. Sie können diesen Schlüssel auf eine dieser drei Arten angeben:
- Durch Wrapping mit dem Cloud Key Management Service (Cloud KMS) Für maximale Sicherheit ist Cloud KMS die bevorzugte Methode.
- Mithilfe eines temporären Schlüssels, den Sensitive Data Protection zum Zeitpunkt der De-Identifikation generiert und dann verwirft. Ein temporärer Schlüssel behält die Integrität nur pro API-Anfrage. Verwenden Sie diesen Schlüsseltyp nicht, wenn Sie eine Integritätsprüfung benötigen oder vorhaben, diese Daten zu re-identifizieren.
- Direkt in Rohform mit Text. (nicht empfohlen).
Weitere Informationen finden Sie weiter unten in diesem Thema im Abschnitt Kryptografische Schlüssel verwenden.
Schritt 3 (nur kryptografisches Hashing und deterministische Verschlüsselung mit AES-SIV): Sensitive Data Protection codiert den verschlüsselten Wert mit base64. Beim kryptografischen Hashing ist der codierte, verschlüsselte Wert das Token, und der Vorgang wird mit Schritt 6 fortgesetzt. Bei der deterministischen Verschlüsselung mit AES-SIV ist dieser codierte, verschlüsselte Wert der Ersatzwert, der nur eine Komponente des Tokens ist. Der Vorgang wird mit Schritt 4 fortgesetzt.
Schritt 4 (nur formaterhaltende und deterministische Verschlüsselung mit AES-SIV): Sensitive Data Protection fügt dem verschlüsselten Wert eine optionale Ersatzannotation hinzu. Die Ersatzannotation dient dazu, verschlüsselte Ersatzwerte zu erkennen, indem diesen ein von Ihnen definierter beschreibender String vorangestellt wird. Beispiel: Ohne Annotation können Sie eine de-identifizierte Telefonnummer nicht von einer de-identifizierten Sozialversicherungsnummer oder eine andere Identifikationsnummer unterscheiden. Außerdem müssen Sie eine Ersatzannotation festlegen, wenn Sie Werte in unstrukturierten Daten re-identifizieren möchten, die entweder durch formaterhaltende Verschlüsselung oder deterministische Verschlüsselung de-identifiziert wurden. Ersatzannotationen sind nicht erforderlich, wenn Sie eine Spalte mit strukturierten oder tabellarischen Daten oder eine RecordTransformation-Transformation transformieren.
Schritt 5 (nur formaterhaltende und deterministische Verschlüsselung mit AES-SIV von strukturierten Daten): Der Schutz sensibler Daten kann einen optionalen Kontext aus einem anderen Feld verwenden, um das generierte Token zu „optimieren“. Auf diese Weise können Sie den Bereich des Tokens ändern. Beispiel: Sie haben eine Datenbank mit Marketingkampagnendaten, die E-Mail-Adressen enthält, und Sie möchten eindeutige Tokens für dieselbe E-Mail-Adresse generieren, die durch eine Kampagnen-ID "gekennzeichnet" sind. So lassen sich Daten für denselben Nutzer innerhalb derselben Kampagne zusammenführen, aber nicht aus verschiedenen Kampagnen. Wenn zur Erstellung des Tokens eine Kontextoptimierung verwendet wird, ist diese Kontextoptimierung auch erforderlich, um die De-Identifikations-Transformationen umzukehren. Formaterhaltende und deterministische Verschlüsselung mit AES-SIV-Unterstützungskontexten. Weitere Informationen zur Verwendung von Kontextoptimierungen.
Schritt 6: Sensitive Data Protection ersetzt den ursprünglichen Wert durch den de-identifizierten Wert.
Vergleich von tokenisierten Werten
In diesem Abschnitt wird beschrieben, wie typische Tokens nach der De-Identifikation mit jeder der drei Methoden aussehen, die in diesem Thema erläutert werden. Der Beispielwert für sensible Daten ist eine nordamerikanische Telefonnummer (1-206-555-0123).
Deterministische Verschlüsselung mit AES-SIV
Bei der De-Identifikation mit deterministischer Verschlüsselung und AES-SIV wird ein Eingabewert (und optional auch eine angegebene Kontextoptimierung) mit AES-SIV mit einem kryptografischen Schlüssel verschlüsselt und mit base64 codiert. Optional wird eine Ersatzannotation vorangestellt, sofern angegeben. Diese Methode behält den Zeichensatz (oder "Alphabet") des Eingabewerts nicht bei. Um eine druckbare Ausgabe zu erzeugen, wird der resultierende Wert in base64 codiert.
Das daraus resultierende Token, angenommen es wurde ein Ersatz-infoType festgelegt, hat folgendes Format:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Das folgende Diagramm zeigt ein Beispieltoken: Die Ausgabe eines De-Identifikationsvorgangs unter Verwendung der deterministischen Verschlüsselung mit AES-SIV für den Wert 1-206-555-0123. Der optionale Ersatz-infoType wurde auf NAM_PHONE_NUMB gesetzt:

- Ersatzannotation
- Ersatz-infoType (vom Nutzer definiert)
- Zeichenlänge des transformierten Werts
- Ersatzwert (transformiert)
Wenn Sie keine Ersatzannotationen angeben, entspricht das resultierende Token dem transformierten Wert oder Nr. 4 im Diagramm. Wenn Sie unstrukturierte Daten neu identifizieren möchten, benötigen Sie dieses gesamte Token, einschließlich der Ersatzannotation. Beim Transformieren strukturierter Daten wie einer Tabelle ist die Ersatzannotation optional. Sensitive Data Protection kann sowohl eine De-Identifikation als auch eine Re-Identifikation für eine ganze Spalte mit einem RecordTransformation ohne Ersatzannotationen ausführen.
Formaterhaltende Verschlüsselung
Bei der De-Identifikation mit formaterhaltender Verschlüsselung wird ein Eingabewert (und optional auch eine bestimmte Kontextoptimierung) mit dem FFX-Modus der formaterhaltenden Verschlüsselung ("FPE-FFX") mit einem kryptografischen Schlüssel verschlüsselt. Optional wird eine Ersatzannotation vorangestellt, sofern angegeben.
Im Gegensatz zu den anderen Methoden der Tokenisierung, die in diesem Thema beschrieben werden, hat der Ausgabewert die gleiche Länge wie der Eingabewert und ist nicht mit base64 codiert. Sie definieren den Zeichensatz oder das "Alphabet", aus dem der verschlüsselte Wert besteht. Sie haben drei Möglichkeiten, um das Alphabet für Sensitive Data Protection anzugeben, das im Ausgabewert verwendet werden soll:
- Verwenden Sie einen der vier Aufzählungswerte, die die vier häufigsten Zeichensätze/Alphabete darstellen.
- Verwenden Sie einen Radixwert, der die Größe des Alphabets angibt. Der kleinste Radixwert
2gibt ein Alphabet aus, das nur aus0und1besteht. Der größte Radixwert95gibt ein Alphabet aus, das alle numerischen Zeichen, alphanumerische Zeichen in Großbuchstaben, Kleinbuchstaben und Symbol-Zeichen enthält. - Erstellen Sie ein Alphabet, indem Sie die zu verwendenden Zeichen auflisten. Wenn Sie beispielsweise
1234567890-*angeben, erhalten Sie einen Ersatzwert, der nur aus Zahlen, Bindestrichen und Sternchen besteht.
In der folgenden Tabelle sind vier häufige Zeichensätze nach ihrem Aufzählungswert (FfxCommonNativeAlphabet), Radixwert und der Liste der Zeichensätze aufgeführt. Die letzte Zeile enthält den vollständigen Zeichensatz, der dem höchsten Radixwert entspricht.
| Name des Alphabets/Zeichensatzes | Radix | Zeichenliste |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
Das daraus resultierende Token, angenommen es wurde ein Ersatz-infoType festgelegt, hat folgendes Format:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Das folgende Diagramm zeigt die Ausgabe eines De-Identifikationsvorgangs für den Schutz sensibler Daten mit formaterhaltender Verschlüsselung des Werts 1-206-555-0123 mit einem Radixwert von 95. Der optionale Ersatz-infoType wurde auf NAM_PHONE_NUMB gesetzt:
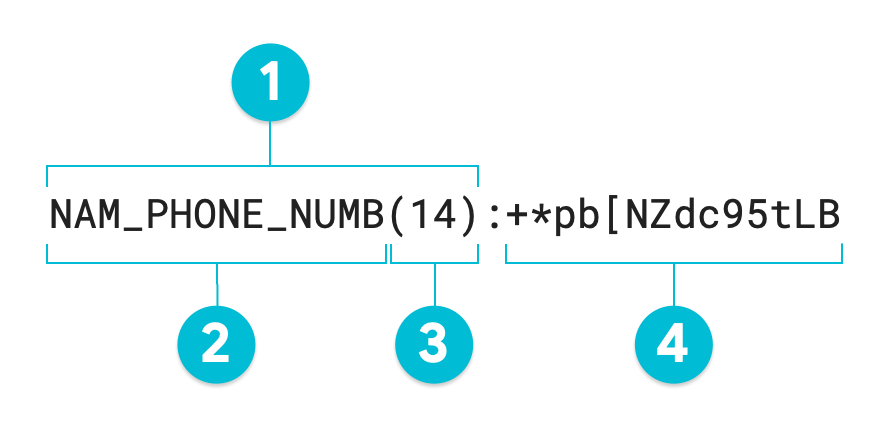
- Ersatzannotation
- Ersatz-infoType (vom Nutzer definiert)
- Zeichenlänge des transformierten Werts
- Ersatzwert (transformiert): Gleiche Länge wie der Eingabewert
Wenn Sie keine Ersatzannotationen angeben, entspricht das resultierende Token dem transformierten Wert oder Nr. 4 im Diagramm. Wenn Sie unstrukturierte Daten neu identifizieren möchten, benötigen Sie dieses gesamte Token, einschließlich der Ersatzannotation. Bei der Transformation strukturierter Daten wie einer Tabelle ist die Ersatzannotation optional. Sensitive Data Protection kann mit einem RecordTransformation ohne Ersatz eine De-Identifikation und Re-Identifikation für eine gesamte Spalte durchführen.
Kryptografisches Hashing
Bei der De-Identifikation mit kryptografischem Hashing wird ein Eingabewert mit HMAC-SHA-256 mit einem kryptografischen Schlüssel gehasht und dann mit base64 codiert. Der de-identifizierte Wert hat immer eine einheitliche Länge, die abhängig von der Größe des Schlüssels ist.
Im Gegensatz zu den anderen Methoden zur Tokenisierung, die in diesem Thema erläutert werden, wird durch das kryptografische Hashing ein unidirektionales Token erstellt. Das heißt, dass die De-Identifikation mit kryptografischem Hashing nicht rückgängig gemacht werden kann.
Im Folgenden ist die Ausgabe eines De-Identifikationsvorgangs mit kryptografischer Hash-Technologie für den Wert 1-206-555-0123 dargestellt. Diese Ausgabe ist eine base64-codierte Darstellung des Hashwerts:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Kryptografische Schlüssel verwenden
Es gibt drei Optionen für kryptografische Schlüssel, die Sie mit den kryptografischen De-Identifikationsmethoden in Sensitive Data Protection verwenden können:
Mit Cloud KMS Wrapping kryptografischer Schlüssel: Dies ist der sicherste Typ von kryptografischem Schlüssel, der mit den Sensitive Data Protection-De-Identifikationsmethoden verwendet werden kann. Ein Cloud KMS Wrapping-Schlüssel besteht aus einem kryptografischen Schlüssel mit 128, 192 oder 256 Bit, der mit einem weiteren Schlüssel verschlüsselt wurde. Sie geben den ersten kryptografischen Schlüssel an, der dann mit einem vom Cloud Key Management Service gespeicherten, kryptografischen Schlüssel generiert wird. Diese Arten von Schlüsseln werden zur späteren De-Identifikation in Cloud KMS gespeichert. Weitere Informationen zum Erstellen und Verpacken eines Schlüssels zum Zweck der De-Identifikation und Re-Identifikation finden Sie unter Kurzanleitung: Sensible Texte de-identifizieren und neu identifizieren.
.Temporärer kryptografischer Schlüssel: Ein temporärer kryptografischer Schlüssel wird von Sensitive Data Protection zum Zeitpunkt der De-Identifikation generiert und anschließend verworfen. Verwenden Sie aus diesem Grund keinen temporären kryptografischen Schlüssel mit einer kryptografischen De-Identifikationsmethode, die Sie umkehren möchten. Temporäre kryptografische Schlüssel behalten ihre Integrität nur pro API-Anfrage. Verwenden Sie diesen Schlüsseltyp nicht, wenn Sie die Integrität mehrerer API-Anfragen benötigen oder Ihre Daten re-identifizieren möchten.
Unverpackter kryptografischer Schlüssel: Ein nicht mit Wrapping verpackter Schlüssel ist ein base64-codierter kryptografischer Schlüssel von 128, 192 oder 256 Bit, den Sie in der De-Identifikationsanfrage an die DLP API bereitstellen. Sie sind dafür verantwortlich, diese Arten von kryptografischen Schlüsseln für eine spätere Re-Identifizierung aufzubewahren. Aufgrund des Risikos, dass der Schlüssel versehentlich gestohlen wird, werden diese Schlüsseltypen nicht empfohlen. Diese Schlüssel können für Tests nützlich sein, für Produktionsarbeitslasten wird jedoch ein mit Cloud KMS verpackter kryptografischer Schlüssel empfohlen.
Weitere Informationen zu den verfügbaren Optionen bei der Verwendung kryptografischer Schlüssel finden Sie unter CryptoKey in der Referenz zur DLP API.
Kontextoptimierungen verwenden
Standardmäßig haben alle kryptografischen Transformationsmethoden der De-Identifikation referenzielle Integrität, unabhängig davon, ob die Ausgabe-Tokens unidirektional oder bidirektional sind. Das heißt, dass ein Eingabewert mit demselben kryptografischen Schlüssel immer in denselben verschlüsselten Wert transformiert wird. In Situationen, in denen wiederholte Daten- oder Datenmuster auftreten können, erhöht sich das Risiko der Re-Identifikation. Damit stattdessen derselbe Eingabewert immer in einen anderen verschlüsselten Wert umgewandelt wird, können Sie eine eindeutige Kontextoptimierung angeben.
Sie geben eine Kontextoptimierung an (in der DLP API einfach als context bezeichnet), wenn Sie tabellarische Daten umwandeln, da die Optimierung faktisch ein Zeiger auf eine Datenspalte ist, z. B. eine ID.
Sensitive Data Protection verwendet den Wert in dem Feld, das von der Kontextoptimierung beim Verschlüsseln des Eingabewerts angegeben wird. Damit der verschlüsselte Wert immer ein eindeutiger Wert ist, geben Sie eine Spalte für die Optimierung an, die eindeutige IDs enthält.
Betrachten Sie dieses einfache Beispiel. Die folgende Tabelle enthält mehrere medizinische Datensätze, von denen einige doppelte Patienten-IDs enthalten.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
Wenn Sie den Schutz sensibler Daten anweisen, die IDs der Patienten in der Tabelle zu de-identifizieren, werden wiederholte Patienten-IDs standardmäßig für dieselben Werte de-identifiziert, wie in der folgenden Tabelle dargestellt. So werden beispielsweise beide Instanzen der Patienten-ID "43789" zu "47222" de-identifiziert. (Die Spalte patient_id zeigt die Tokenwerte nach der Pseudonymisierung mithilfe von FPE-FFX an und enthält keine Ersatz-Annotationen. Weitere Informationen finden Sie unter Formaterhaltende Verschlüsselung.)
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
Dies bedeutet, dass der Bereich der referenziellen Integrität für das gesamte Dataset gilt.
Wenn Sie den Bereich eingrenzen möchten, um dieses Verhalten zu vermeiden, legen Sie eine Kontextoptimierung fest. Sie können eine beliebige Spalte als Kontextoptimierung angeben. Um jedoch zu gewährleisten, dass jeder de-identifizierte Wert eindeutig ist, geben Sie eine Spalte an, in der jeder Wert eindeutig ist.
Angenommen, Sie möchten prüfen, ob derselbe Patient pro icd10_codes-Wert angezeigt wird, aber nicht, wenn derselbe Patient mit verschiedenen icd10_codes-Werten angezeigt wird. Dazu müssen Sie die Spalte icd10_codes als Kontextoptimierung angeben.
Das ist die Tabelle nach der De-Identifikation der Spalte patient_id mit der Spalte icd10_codes als Kontextoptimierung:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
Beachten Sie, dass der vierte und der fünfte patient_id-Wert (29460) identisch sind, da nicht nur die ursprünglichen patient_id-Werte identisch waren, sondern auch die icd10_codes-Werte der beiden Zeilen. Da Sie Analysen mit konsistenten Patienten-IDs innerhalb des Bereichs der icd10_codes ausführen müssen, ist dieses Verhalten genau das, wonach Sie suchen.
Sie können stattdessen die Spalte record_id zur Kontextoptimierung verwenden, um die referenzielle Integrität zwischen patient_id-Werten und icd10_codes-Werten vollständig zu korrelieren:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
Beachten Sie, dass jeder de-identifizierte patient_id-Wert in der Tabelle nun eindeutig ist.
Weitere Informationen zur Verwendung von Kontextoptimierungen in der DLP API finden Sie unter dem Begriff context in den folgenden Themen zu Transformationsmethoden:
- Formaterhaltende Verschlüsselung:
CryptoReplaceFfxFpeConfig - Deterministische Verschlüsselung mit AES-SIV:
CryptoDeterministicConfig - Datumsverschiebung:
DateShiftConfig