Auf dieser Seite werden zwei Sensitive Data Protection-Dienste beschrieben und verglichen, mit denen Sie Ihre Daten analysieren und Workflows zur Datenverwaltung aktivieren können: der Erkennungsdienst und der Prüfdienst.
Auffinden sensibler Daten
Der Erkennungsdienst überwacht Daten in Ihrer gesamten Organisation. Dieser Dienst wird kontinuierlich ausgeführt und erkennt, klassifiziert und profiliert Daten automatisch. Mit Discovery können Sie den Speicherort und die Art der Daten, die Sie speichern, nachvollziehen. Das gilt auch für Datenressourcen, die Ihnen möglicherweise nicht bekannt sind. Unbekannte Daten (manchmal auch als Schatten-Daten bezeichnet) unterliegen in der Regel nicht dem gleichen Grad an Data Governance und Risikomanagement wie bekannte Daten.
Die Erkennung wird auf verschiedenen Ebenen konfiguriert. Sie können für verschiedene Teilmengen Ihrer Daten unterschiedliche Profilerstellungszeitpläne festlegen. Sie können auch Teilmengen von Daten ausschließen, die Sie nicht analysieren müssen.
Ausgabe des Erkennungsscans: Datenprofile
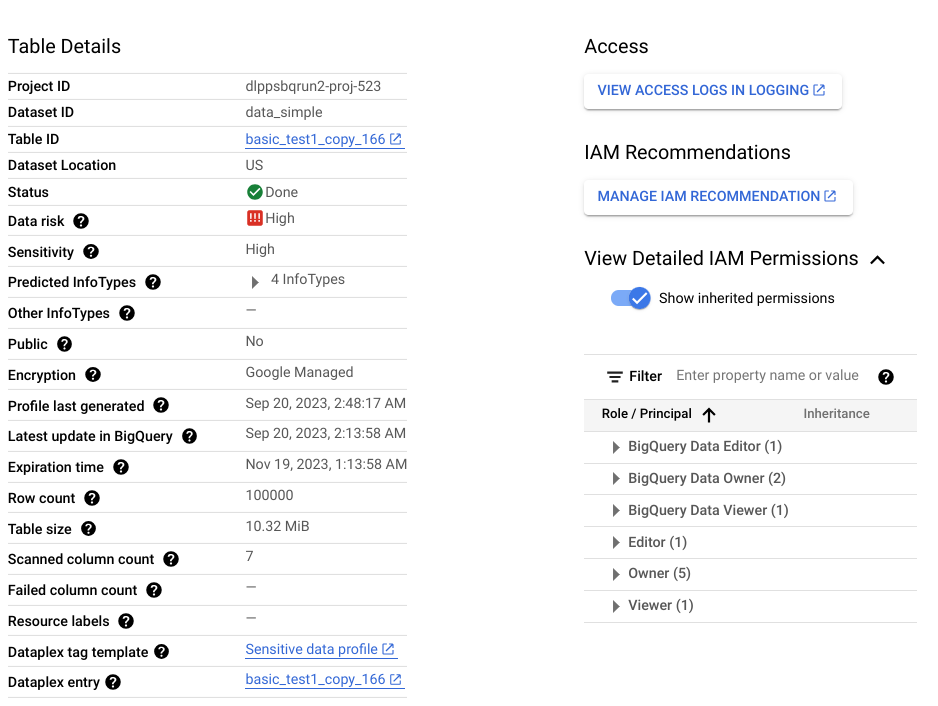
Die Ausgabe eines Discovery-Scans ist eine Reihe von Datenprofilen für jede Datenressource im Umfang. Bei einem Erkennungsscan von BigQuery- oder Cloud SQL-Daten werden beispielsweise Datenprofile auf Projekt-, Tabellen- und Spaltenebene generiert.
Ein Datenprofil enthält Messwerte und Statistiken zur Ressource, für die ein Profil erstellt wurde. Dazu gehören die Datenklassifizierungen (oder infoTypes), Vertraulichkeitsstufen, Datenrisikostufen, Datengröße, Datenform und andere Elemente, die die Art der Daten und ihre Datensicherheitslage (wie sicher die Daten sind) beschreiben. Sie können Datenprofile verwenden, um fundierte Entscheidungen darüber zu treffen, wie Sie Ihre Daten schützen, z. B. durch Festlegen von Zugriffsrichtlinien für die Tabelle.
Angenommen, es gibt eine BigQuery-Spalte mit dem Namen ccn, in der jede Zeile eine eindeutige Kreditkartennummer enthält und es keine Nullwerte gibt. Das generierte Datenprofil auf Spaltenebene enthält die folgenden Details:
| Anzeigename | Wert |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Außerdem ist dieses Profil auf Spaltenebene Teil eines Profils auf Tabellenebene, das Informationen wie den Datenspeicherort, den Verschlüsselungsstatus und die Frage enthält, ob die Tabelle öffentlich freigegeben ist. In der Google Cloud Console können Sie auch die Cloud Logging-Einträge für die Tabelle und die IAM-Hauptkonten mit Rollen für die Tabelle ansehen.
Eine vollständige Liste der in Datenprofilen verfügbaren Messwerte und Statistiken finden Sie in der Messwertreferenz.
Wann sollte Discovery verwendet werden?
Wenn Sie Ihren Ansatz für das Datenrisikomanagement planen, empfehlen wir, mit der Ermittlung zu beginnen. Der Ermittlungsdienst bietet Ihnen einen umfassenden Überblick über Ihre Daten und ermöglicht Benachrichtigungen, Berichte und Behebung von Problemen.
Außerdem können Sie mit dem Discovery-Dienst die Ressourcen identifizieren, in denen sich unstrukturierte Daten befinden. Solche Ressourcen erfordern möglicherweise eine umfassende Prüfung. Unstrukturierte Daten werden durch einen hohen Freitext-Wert auf einer Skala von 0 bis 1 angegeben.
Prüfung sensibler Daten
Der Inspektionsdienst führt einen umfassenden Scan einer einzelnen Ressource durch, um jedes einzelne Vorkommen sensibler Daten zu finden. Bei einer Prüfung wird für jede erkannte Instanz ein Ergebnis generiert.
Prüfungsjobs bieten eine Vielzahl von Konfigurationsoptionen, mit denen Sie die zu prüfenden Daten genau festlegen können. Sie können beispielsweise Stichproben aktivieren, um die zu untersuchenden Daten auf eine bestimmte Anzahl von Zeilen (für BigQuery-Daten) oder bestimmte Dateitypen (für Cloud Storage-Daten) zu beschränken. Sie können auch einen bestimmten Zeitraum festlegen, in dem die Daten erstellt oder geändert wurden.
Im Gegensatz zur Ermittlung, bei der Ihre Daten kontinuierlich überwacht werden, ist die Überprüfung ein On-Demand-Vorgang. Sie können jedoch wiederkehrende Inspektionsjobs planen, die als Job-Trigger bezeichnet werden.
Ausgabe des Prüfscans: Ergebnisse
Jedes Ergebnis enthält Details wie den Speicherort der erkannten Instanz, den potenziellen infoType und die Wahrscheinlichkeit (auch Wahrscheinlichkeit genannt), dass das Ergebnis mit dem infoType übereinstimmt. Je nach Ihren Einstellungen können Sie auch den tatsächlichen String abrufen, auf den sich das Ergebnis bezieht. Dieser String wird im Schutz sensibler Daten als Zitat bezeichnet.
Eine vollständige Liste der Details, die in einem Inspektionsergebnis enthalten sind, finden Sie unter Finding.
Wann sollte die Überprüfung verwendet werden?
Eine Überprüfung ist nützlich, wenn Sie unstrukturierte Daten (z. B. von Nutzern erstellte Kommentare oder Rezensionen) untersuchen und jedes Vorkommen von personenidentifizierbaren Informationen (PII) identifizieren müssen. Wenn bei einem Discovery-Scan Ressourcen mit unstrukturierten Daten gefunden werden, empfehlen wir, einen Inspektionsscan für diese Ressourcen auszuführen, um Details zu den einzelnen Ergebnissen zu erhalten.
Wann die Überprüfung nicht verwendet werden sollte
Die Untersuchung einer Ressource ist nicht sinnvoll, wenn die beiden folgenden Bedingungen zutreffen. Ein Erkennungsscan kann Ihnen helfen, zu entscheiden, ob ein Prüfscan erforderlich ist.
- Die Ressource enthält nur strukturierte Daten. Es gibt also keine Spalten mit Freiformdaten wie Nutzerkommentaren oder Rezensionen.
- Sie kennen die in dieser Ressource gespeicherten infoTypes bereits.
Angenommen, Datenprofile aus einem Erkennungsscan weisen darauf hin, dass eine bestimmte BigQuery-Tabelle keine Spalten mit unstrukturierten Daten, aber eine Spalte mit eindeutigen Kreditkartennummern enthält. In diesem Fall ist es nicht sinnvoll, die Tabelle nach Kreditkartennummern zu durchsuchen. Bei einer Überprüfung wird für jedes Element in der Spalte ein Ergebnis generiert. Wenn Sie 1 Million Zeilen haben und jede Zeile eine Kreditkartennummer enthält, werden bei einem Inspektionsjob 1 Million Ergebnisse für den infoType CREDIT_CARD_NUMBER generiert. In diesem Beispiel ist die Prüfung nicht erforderlich, da der Discovery-Scan bereits darauf hinweist, dass die Spalte eindeutige Kreditkartennummern enthält.
Datenstandort, Verarbeitung und Speicherung
Sowohl die Erkennung als auch die Überprüfung unterstützen Anforderungen an den Datenstandort:
- Der Dienst zur Erkennung sensibler Daten verarbeitet Ihre Daten dort, wo sie sich befinden, und speichert die generierten Datenprofile in derselben Region oder Multiregion wie die profilierten Daten. Weitere Informationen finden Sie unter Überlegungen zum Datenstandort.
- Wenn Daten in einem Google Cloud -Speichersystem geprüft werden, verarbeitet der Prüfdienst Ihre Daten in derselben Region, in der sich die Daten befinden, und speichert den Prüfjob in dieser Region. Wenn Sie Daten mit einem Hybridjob oder einer
content-Methode prüfen, können Sie mit dem Prüfdienst angeben, wo Ihre Daten verarbeitet werden sollen. Weitere Informationen finden Sie unter So werden Daten gespeichert.
Zusammenfassung des Vergleichs: Ermittlungs- und Prüfdienste
| Discovery | Prüfung | |
|---|---|---|
| Vorteile |
|
|
| Kosten |
10 TB kosten im Verbrauchsmodus etwa 300$pro Monat. |
10 TB kosten ca. 10.000$pro Scan. |
| Unterstützte Datenquellen | BigLake BigQuery Umgebungsvariablen für Cloud Run-Funktionen Umgebungsvariablen für Cloud Run-Dienstrevisionen Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datenspeicher Hybrid (beliebige Quelle)1 |
| Unterstützte Bereiche |
|
Eine einzelne BigQuery-Tabelle, ein Cloud Storage-Bucket oder eine Datastore-Art. |
| Integrierte Inspektionsvorlagen | Ja | Ja |
| Integrierte und benutzerdefinierte infoTypes | Ja | Ja |
| Scanausgabe | Gesamtübersicht (Datenprofile) über alle unterstützten Daten. | Konkrete Ergebnisse zu sensiblen Daten in der geprüften Ressource. |
| Ergebnisse in BigQuery speichern | Ja | Ja |
| Als Tags an Dataplex Universal Catalog senden (eingestellt) | Ja | Ja |
| Als Aspekte an Dataplex Universal Catalog senden | Ja | Nein |
| Ergebnisse in Security Command Center veröffentlichen | Ja | Ja |
| Ergebnisse in Google Security Operations veröffentlichen | Ja für die Suche auf Organisations- und Ordnerebene | Nein |
| In Pub/Sub veröffentlichen | Ja | Ja |
| Unterstützung für den Datenstandort | Ja | Ja |
1 Für die Hybrid-Inspektion gilt ein anderes Preismodell. Weitere Informationen finden Sie unter Prüfung von Daten aus beliebigen Quellen .
Nächste Schritte
- Empfohlene Strategien zur Minimierung des Datenrisikos (nächstes Dokument in dieser Reihe)