Generalization is the process of taking a distinguishing value and abstracting it into a more general, less distinguishing value. Generalization attempts to preserve data utility while also reducing the identifiability of the data.
There can be many levels of generalization depending on the data type. How much generalization is needed is something that you can measure across a dataset or a real world population using techniques like those included in Sensitive Data Protection's risk analysis.
One common generalization technique that Sensitive Data Protection supports is bucketing. With bucketing, you group records into smaller buckets in an attempt to minimize the risk of an attacker associating sensitive information with identifying information. Doing so can retain meaning and utility, but it will also obscure the individual values that have too few participants.
Bucketing scenario 1
Consider this numerical bucketing scenario: A database stores users' satisfaction scores, which range from 0 to 100. The database looks something like the following:
| user_id | score |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | ... |
Scanning over the data, you realize that some values are rarely used by users. In fact, there are a few scores that map to only one user. For example, the majority of users pick either 0, 25, 50, 75, or 100. However, five users picked 95, and just one user picked 92. Instead of keeping the raw data, you could generalize these values into groups and eliminate having any groups with too few participants. Depending on how the data is used, generalizing data in this way could help prevent re-identification.
You could choose to remove these rows of outlier data, or you could attempt to preserve their utility by using bucketing. For this example, let's bucket all values according to the following:
- 0 to 25: "Low"
- 26-75: "Medium"
- 76-100: "High"
Bucketing in Sensitive Data Protection is one of many primitive
transformations available for de-identification. The following JSON
configuration illustrates how to implement this bucketing scenario in the
DLP API. This JSON could be included in a request to the
content.deidentify
method:
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
Bucketing scenario 2
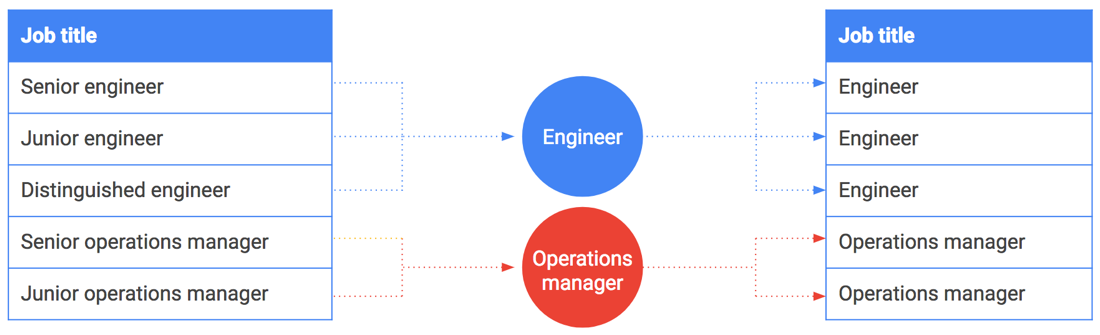
Bucketing can also be used on strings or enumerated values. Suppose you wanted to share salary data and include job titles. However, some job titles, such as CEO or distinguished engineer, can be linked to one person or a small group of people. Such job titles are easily matched to the employees who hold them.
Bucketing can help here as well. Instead of including exact job titles, generalize and bucket them. For example, "Senior Engineer," "Junior Engineer," and "Distinguished Engineer" become generalized and bucketed into simply "Engineer." The following table illustrates bucketing specific job titles into job title families.
Other scenarios
In these examples, we've applied the transformation to structured data. Bucketing can also be used on unstructured examples, as long as the value can be classified with a predefined or custom infoType. Below are some example scenarios:
- Classify dates and bucket them into year ranges
- Classify names and bucket them into groups based on the first letter (A-M, N-Z)
Resources
To learn more about generalization and bucketing, see De-identifying Sensitive Data in Text Content.
For API documentation, see:
projects.content.deidentifymethodBucketingConfigtransformation: Buckets values based on custom ranges.FixedSizeBucketingConfigtransformation: Buckets values based on fixed size ranges.