L-diversity is a property of a dataset and an extension of k-anonymity that measures the diversity of sensitive values for each column in which they occur. A dataset has l-diversity if, for every set of rows with identical quasi-identifiers, there are at least l distinct values for each sensitive attribute.
You can compute the l-diversity value based on one or more columns, or fields, of a dataset. This topic demonstrates how to compute l-diversity values for a dataset using Sensitive Data Protection. For more information about l-diversity or risk analysis in general, see the risk analysis concept topic before continuing on.
Before you begin
Before continuing, be sure you've done the following:
- Sign in to your Google Account.
- In the Google Cloud console, on the project selector page, select or create a Google Cloud project. Go to the project selector
- Make sure that billing is enabled for your Google Cloud project. Learn how to confirm billing is enabled for your project.
- Enable Sensitive Data Protection. Enable Sensitive Data Protection
- Select a BigQuery dataset to analyze. Sensitive Data Protection calculates the l-diversity metric by scanning a BigQuery table.
- Determine a sensitive field identifier (if applicable) and at least one quasi-identifier in the dataset. For more information, see Risk analysis terms and techniques.
Compute l-diversity
Sensitive Data Protection performs risk analysis whenever a risk analysis job runs. You must create the job first, either by using the Google Cloud console, sending a DLP API request, or using a Sensitive Data Protection client library.
Console
In the Google Cloud console, go to the Create risk analysis page.
In the Choose input data section, specify the BigQuery table to scan by entering the project ID of the project containing the table, the dataset ID of the table, and the name of the table.
Under Privacy metric to compute, select l-diversity.
In the Job ID section, you can optionally give the job a custom identifier and select a resource location in which Sensitive Data Protection will process your data. When you're done, click Continue.
In the Define fields section, you specify sensitive fields and quasi-identifiers for the l-diversity risk job. Sensitive Data Protection accesses the metadata of the BigQuery table you specified in the previous step and attempts to populate the list of fields.
- Select the appropriate checkbox to specify a field as either a sensitive field (S) or quasi-identifier (QI). You must select 1 sensitive field and at least 1 quasi-identifier.
- If Sensitive Data Protection isn't able to populate the fields, click Enter field name to manually enter one or more fields and set each one as sensitive field or quasi-identifier. When you're done, click Continue.
In the Add actions section, you can add optional actions to perform when the risk job is complete. The available options are:
- Save to BigQuery: Saves the results of the risk analysis scan to a BigQuery table.
Publish to Pub/Sub: Publishes a notification to a Pub/Sub topic.
Notify by email: Sends you an email with results. When you're done, click Create.
The l-diversity risk analysis job starts immediately.
C#
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Go
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Java
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Node.js
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
PHP
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Python
To learn how to install and use the client library for Sensitive Data Protection, see Sensitive Data Protection client libraries.
To authenticate to Sensitive Data Protection, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
REST
To run a new risk analysis job to compute l-diversity, send a request to the
projects.dlpJobs
resource, where PROJECT_ID indicates your project
identifier:
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs
The request contains a
RiskAnalysisJobConfig
object, which is composed of the following:
A
PrivacyMetricobject. This is where you specify that you're calculating l-diversity by including anLDiversityConfigobject.A
BigQueryTableobject. Specify the BigQuery table to scan by including all of the following:projectId: The project ID of the project containing the table.datasetId: The dataset ID of the table.tableId: The name of the table.
A set of one or more
Actionobjects, which represent actions to run, in the order given, at the completion of the job. EachActionobject can contain one of the following actions:SaveFindingsobject: Saves the results of the risk analysis scan to a BigQuery table.PublishToPubSubobject: Publishes a notification to a Pub/Sub topic.JobNotificationEmailsobject: Sends you an email with results.
Within the
LDiversityConfigobject, you specify the following:quasiIds[]: A set of quasi-identifiers (FieldIdobjects) that indicate how equivalence classes are defined for the l-diversity computation. As withKAnonymityConfig, when you specify multiple fields, they are considered a single composite key.sensitiveAttribute: Sensitive field (FieldIdobject) for computing the l-diversity value.
As soon as you send a request to the DLP API, it starts the risk analysis job.
List completed risk analysis jobs
You can view a list of the risk analysis jobs that have been run in the current project.
Console
To list running and previously run risk analysis jobs in the Google Cloud console, do the following:
In the Google Cloud console, open Sensitive Data Protection.
Click the Jobs & job triggers tab at the top of the page.
Click the Risk jobs tab.
The risk job listing appears.
Protocol
To list running and previously run risk analysis jobs, send a GET request to
the
projects.dlpJobs
resource. Adding a job type filter (?type=RISK_ANALYSIS_JOB) narrows the
response to only risk analysis jobs.
https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs?type=RISK_ANALYSIS_JOB
The response you receive contains a JSON representation of all current and previous risk analysis jobs.
View l-diversity job results
Sensitive Data Protection in the Google Cloud console features built-in visualizations for completed l-diversity jobs. After following the instructions in the previous section, from the risk analysis job listing, select the job for which you want to view results. Assuming the job has run successfully, the top of the Risk analysis details page looks like this:

At the top of the page is information about the l-diversity risk job, including its job ID and, under Container, its resource location.
To view the results of the l-diversity calculation, click the L-diversity tab. To view the risk analysis job's configuration, click the Configuration tab.
The L-diversity tab first lists the sensitive value and the quasi-identifiers used to calculate l-diversity.
Risk chart
The Re-identification risk chart plots, on the y-axis, the potential percentage of data loss for both unique rows and unique quasi-identifier combinations to achieve, on the x-axis, an l-diversity value. The chart's color also indicates risk potential. Darker shades of blue indicate a higher risk, while lighter shades indicate less risk.
Higher l-diversity values indicate less diversity of values, which can make a dataset less re-identifiable and more secure. To achieve higher l-diversity values, however, you would need to remove higher percentages of the total rows and higher unique quasi-identifier combinations, which might decrease the utility of the data. To see a specific potential percentage loss value for a certain l-diversity value, hover your cursor over the chart. As shown in the screenshot, a tooltip appears on the chart.
To view more detail about a specific l-diversity value, click the corresponding data point. A detailed explanation is shown under the chart and a sample data table appears further down the page.
Risk sample data table
The second component to the risk job results page is the sample data table. It displays quasi-identifier combinations for a given target l-diversity value.
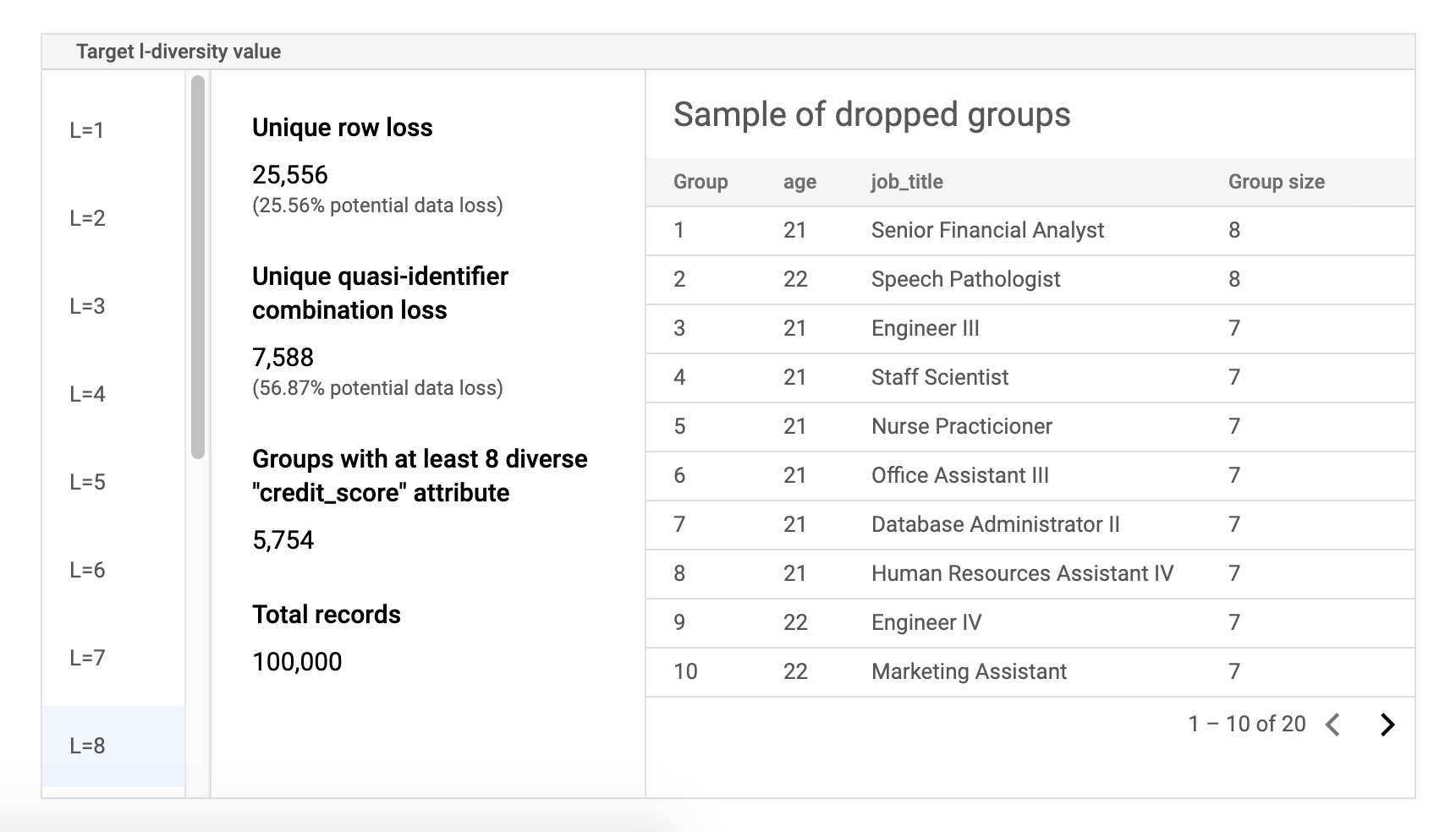
The first column of the table lists the k-anonymity values. Click an l-diversity value to view corresponding sample data that would need to be dropped to achieve that value.
The second column displays the respective potential data loss of unique rows and quasi-identifier combinations to achieve the selected l-diversity value, as well as the number of groups with at least l sensitive attributes and the total number of records.
The last column displays a sample of groups that share a quasi-identifier combination, along with the number of records that exist for that combination.
Retrieve job details using REST
To retrieve the results of the l-diversity risk analysis job using the REST
API, send the following GET request to the
projects.dlpJobs
resource. Replace PROJECT_ID with your project ID and
JOB_ID with the identifier of the job you want to obtain results for.
The job ID was returned when you started the job, and can also be retrieved by
listing all jobs.
GET https://dlp.googleapis.com/v2/projects/PROJECT_ID/dlpJobs/JOB_ID
The request returns a JSON object containing an instance of the job. The results
of the analysis are inside the "riskDetails" key, in an
AnalyzeDataSourceRiskDetails
object. For more information, see the API reference for the
DlpJob
resource.
What's next
- Learn how to calculate the k-anonymity value for a dataset.
- Learn how to calculate the k-map value for a dataset.
- Learn how to calculate the δ-presence value for a dataset.