Exporte recomendações para o BigQuery
Vista geral
Com o BigQuery Export, pode ver instantâneos diários das recomendações para a sua organização. Isto é feito através do Serviço de transferência de dados do BigQuery. Consulte este documento para ver que recomendadores estão incluídos no BigQuery Export atualmente.
Antes de começar
Conclua os passos seguintes antes de criar uma transferência de dados para recomendações:
- Permita que o Serviço de transferência de dados do BigQuery tenha autorização para gerir a sua transferência de dados. Se usar a IU Web do BigQuery para criar a transferência, tem de permitir pop-ups de
console.cloud.google.comno seu navegador para poder ver as autorizações. Para mais detalhes, consulte o artigo ative um Serviço de transferência de dados do BigQuery. - Crie um
conjunto de dados do BigQuery para armazenar dados.
- A transferência de dados usa a mesma região onde o conjunto de dados é criado. A localização é imutável depois de o conjunto de dados e a transferência serem criados.
- O conjunto de dados vai conter estatísticas e recomendações de todas as regiões em todo o mundo. Assim, esta operação agregaria todos esses dados numa região global durante o processo. Consulte o serviço de apoio ao cliente do Google Cloud se tiver preocupações sobre a residência de dados.
- Se a localização do conjunto de dados tiver sido lançada recentemente, pode haver um atraso na disponibilidade dos dados de exportação iniciais.
Preços
A exportação de recomendações para o BigQuery está disponível para todos os clientes do recomendador com base no respetivo nível de preços do recomendador.
Autorizações necessárias
Ao configurar a transferência de dados, precisa das seguintes autorizações ao nível do projeto onde cria uma transferência de dados:
bigquery.transfers.update: permite-lhe criar a transferênciabigquery.datasets.update– Permite-lhe atualizar ações no conjunto de dados de destinoresourcemanager.projects.update– Permite-lhe selecionar um projeto onde quer que os dados de exportação sejam armazenadospubsub.topics.list– Permite-lhe selecionar um tópico do Pub/Sub para receber notificações acerca da sua exportação
A seguinte autorização é necessária ao nível da organização. Esta organização corresponde àquela para a qual a exportação está a ser configurada.
recommender.resources.export- Permite exportar recomendações para o BigQuery
São necessárias as seguintes autorizações para exportar preços negociados para recomendações de poupanças de custos:
billing.resourceCosts.get at project level- Permite exportar preços negociados para recomendações ao nível do projetobilling.accounts.getSpendingInformation at billing account level- Permite exportar preços negociados para recomendações ao nível da conta de faturação
Sem estas autorizações, as recomendações de poupança de custos são exportadas com preços padrão em vez de preços negociados.
Conceder autorizações
As seguintes funções têm de ser concedidas no projeto onde cria a transferência de dados:
- Função de administrador do BigQuery:
roles/bigquery.admin - Função de proprietário do projeto:
roles/owner - Função Project Owner:
roles/owner - Função Project Viewer:
roles/viewer - Função Editor do projeto:
roles/editor - Função de administrador da conta de faturação:
roles/billing.admin - Função de gestor de custos da conta de faturação:
roles/billing.costsManager - Função Visitante da conta de faturação:
roles/billing.viewer
Para lhe permitir criar uma transferência e atualizar ações no conjunto de dados de destino, tem de conceder a seguinte função:
Existem várias funções que contêm autorizações para selecionar um projeto para armazenar os seus dados de exportação e para selecionar um tópico do Pub/Sub para receber notificações. Para ter estas duas autorizações disponíveis, pode conceder a seguinte função:
Existem várias funções que contêm a autorização billing.resourceCosts.get para exportar preços negociados para recomendações ao nível do projeto de poupanças de custos. Pode conceder qualquer uma delas:
Existem várias funções que contêm a autorização billing.accounts.getSpendingInformation para exportar preços negociados para recomendações ao nível da conta de faturação de poupanças de custos. Pode conceder qualquer uma delas:
Tem de conceder a seguinte função ao nível da organização:
- Função Exportador de recomendações (
roles/recommender.exporter) na consola Google Cloud .
Também pode criar funções personalizadas que contenham as autorizações necessárias.
Crie uma transferência de dados para recomendações
Inicie sessão na Google Cloud consola.
No ecrã Página inicial, clique no separador Recomendações.
Clique em Exportar para ver o formulário de exportação do BigQuery.
Selecione um projeto de destino para armazenar os dados de recomendações e clique em Seguinte.
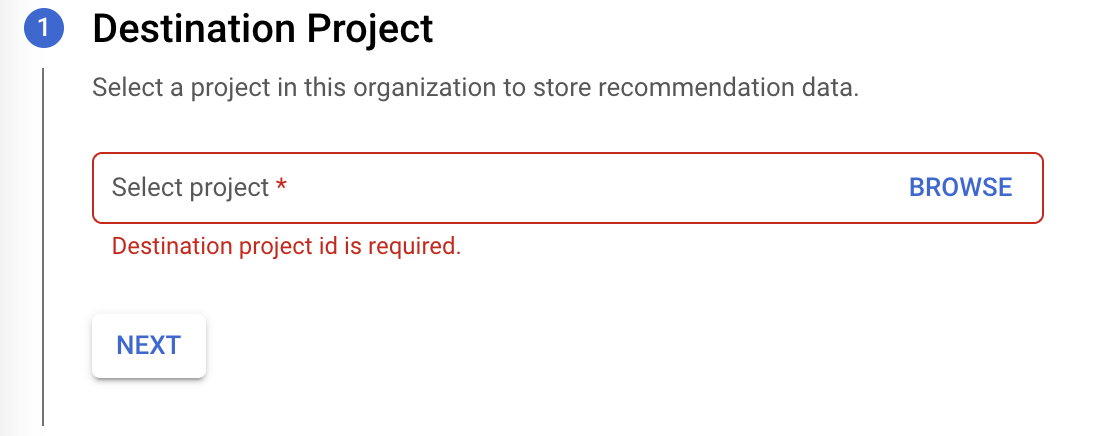
Clique em Ativar APIs para ativar as APIs BigQuery para a exportação. Este processo pode demorar vários segundos. Quando terminar, clique em Continuar.
No formulário Configurar transferência, indique os seguintes detalhes:
Na secção Nome da configuração da transferência, em Nome a apresentar, introduza um nome para a transferência. O nome da transferência pode ser qualquer valor que lhe permita identificar facilmente a transferência se precisar de a modificar mais tarde.

Na secção Opções de programação, para Programação, deixe o valor predefinido (Começar agora) ou clique em Começar a uma hora definida.
Para Repetições, escolha uma opção para a frequência de execução da transferência.
- Diariamente (predefinição)
- Semanalmente
- Mensalmente
- Personalizado
- A pedido
Para Data de início e tempo de execução, introduza a data e a hora de início da transferência. Se escolher Começar agora, esta opção é desativada.

Na secção Definições de destino, para Conjunto de dados de destino, escolha o ID do conjunto de dados que criou para armazenar os seus dados.
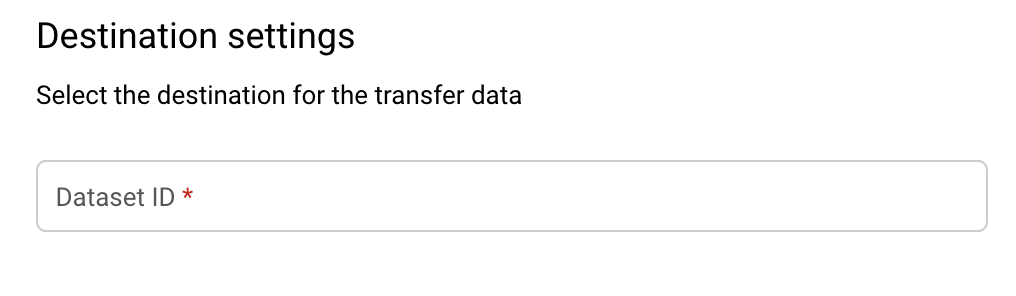
Na secção Detalhes da origem de dados:
O valor predefinido de organization_id é a organização para a qual está a ver recomendações. Se quiser exportar recomendações para outra organização, pode alterar esta opção na parte superior da consola no visualizador da organização.

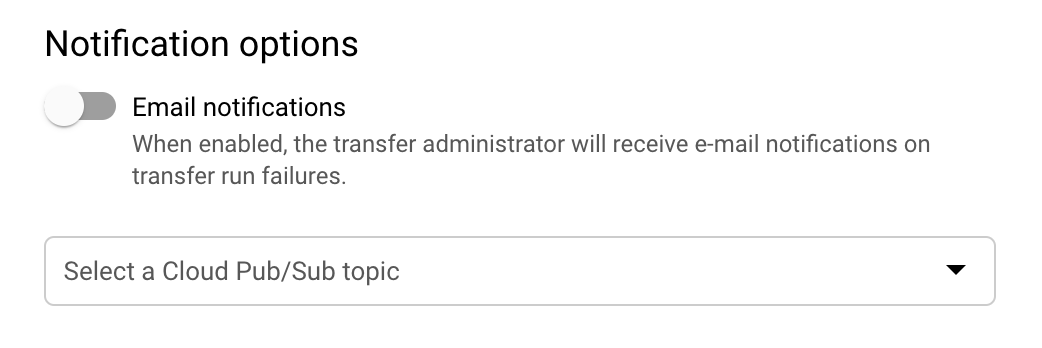
(Opcional) Na secção Opções de notificação:
- Clique no botão para ativar as notificações por email. Quando ativa esta opção, o administrador da transferência recebe uma notificação por email quando uma execução de transferência falha.
- Em Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar um tópico. Esta opção configura notificações executadas pelo Pub/Sub para a transferência.
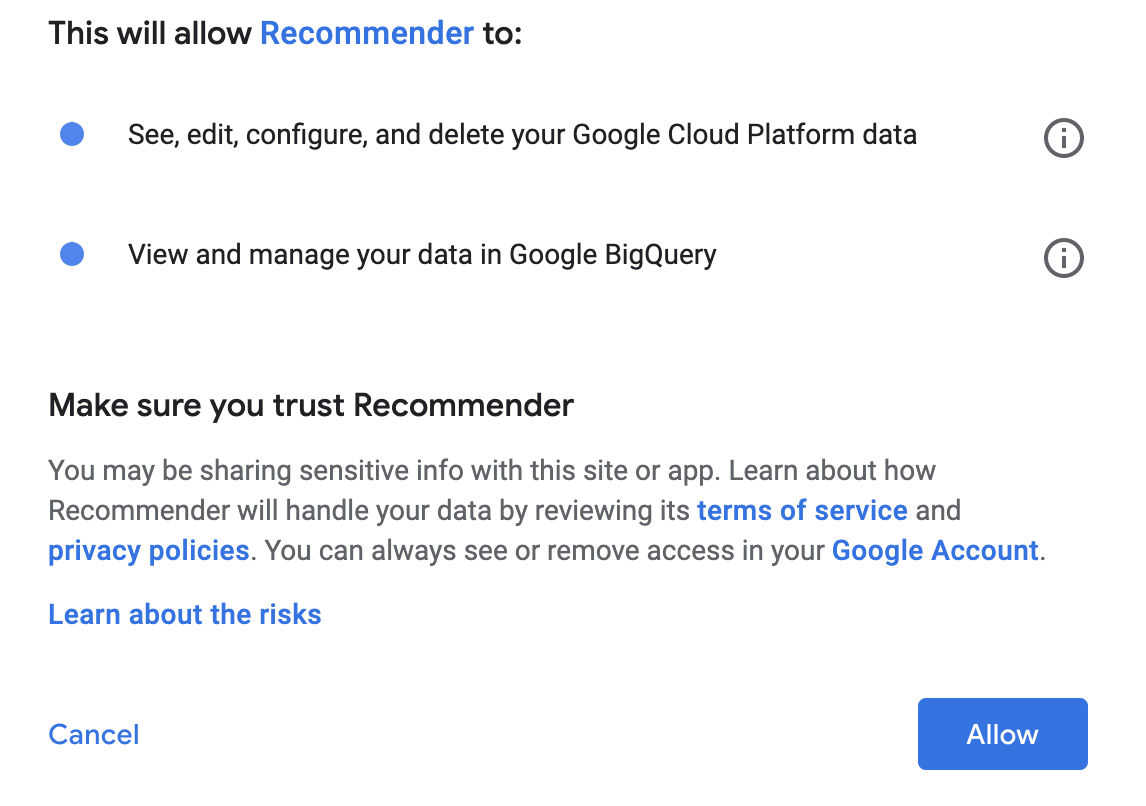
Clique em Criar para criar a transferência.
Clique em Permitir no pop-up de consentimento.
Depois de criar a transferência, é feito o redirecionamento novamente para o Active Assist. Pode clicar no link para aceder aos detalhes da configuração da transferência. Em alternativa, pode aceder às transferências fazendo o seguinte:
Aceda à página do BigQuery na Google Cloud consola.
Clique em Transferências de dados. Pode ver todas as transferências de dados disponíveis.
Veja o histórico de execuções de uma transferência
Para ver o histórico de execuções de uma transferência, faça o seguinte:
Aceda à página do BigQuery na Google Cloud consola.
Clique em Transferências de dados. Pode ver todas as transferências de dados disponíveis.
Clique na transferência adequada na lista.
Na lista de transferências de execuções apresentadas no separador HISTÓRICO DE EXECUÇÕES, selecione a transferência cujos detalhes quer ver.
O painel Detalhes da execução é apresentado para a transferência de execução individual que selecionou. Alguns dos possíveis detalhes de execução apresentados são:
- Transferência adiada devido a dados de origem indisponíveis.
- Tarefa que indica o número de linhas exportadas para uma tabela
- Autorizações em falta para uma origem de dados que tem de conceder e, posteriormente, agendar um preenchimento.
Quando é que os seus dados são exportados?
Quando cria uma transferência de dados, a primeira exportação ocorre em dois dias. Após a primeira exportação, as tarefas de exportação são executadas na cadência que solicitou no momento da configuração. Aplicam-se as seguintes condições:
A tarefa de exportação de um dia específico (D) exporta os dados de final do dia (D) para o seu conjunto de dados do BigQuery, o que normalmente termina até ao final do dia seguinte (D+1). A tarefa de exportação é executada no fuso horário PST e pode parecer ter um atraso adicional para outros fusos horários.
A tarefa de exportação diária não é executada até que todos os dados para exportação estejam disponíveis. Isto pode resultar em variações e, por vezes, atrasos no dia e na hora em que o conjunto de dados é atualizado. Por conseguinte, é melhor usar a imagem instantânea de dados mais recente disponível do que ter uma dependência sensível ao tempo em tabelas com datas específicas.
A tarefa de exportação transfere os dados mais recentes disponíveis por região. Isto significa que pode haver uma diferença na data mais recente para a qual as recomendações de diferentes regiões estão disponíveis.
Mensagens de estado comuns numa exportação
Saiba mais sobre as mensagens de estado comuns que pode ver ao exportar recomendações para o BigQuery.
O utilizador não tem a autorização necessária
A seguinte mensagem ocorre quando o utilizador não tem a autorização necessária recommender.resources.export. É apresentada a seguinte mensagem:
User does not have required permission "recommender.resources.export". Please, obtain the required permissions for the datasource and try again by triggering a backfill for this date
Para resolver este problema, conceda a função do IAM roles/recommender.exporter ao user/service account que configura a exportação ao nível organizacional para a organização para a qual a exportação foi configurada. Pode ser concedido através dos comandos gcloud abaixo:
No caso do utilizador:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='user:*<user_name>*' --role='roles/recommender.exporter'No caso de uma conta de serviço:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'
Transferência adiada porque os dados de origem não estão disponíveis
A seguinte mensagem ocorre quando a transferência é reagendada porque os dados de origem ainda não estão disponíveis. Isto não é um erro. Significa que os pipelines de exportação ainda não foram concluídos para o dia. A transferência é executada novamente na nova hora agendada e tem êxito quando os pipelines de exportação estiverem concluídos. É apresentada a seguinte mensagem:
Transfer deferred due to source data not being available
Dados de origem não encontrados
A seguinte mensagem ocorre quando os pipelines F1toPlacer são concluídos, mas não foram encontradas recomendações nem estatísticas para a organização para a qual a exportação foi configurada. É apresentada a seguinte mensagem:
Source data not found for 'recommendations_export$<date>'insights_export$<date>
Esta mensagem ocorre pelos seguintes motivos:
- O utilizador configurou a exportação há menos de 2 dias. O guia do cliente informa os clientes de que existe um atraso de um dia antes de a exportação estar disponível.
- Não existem recomendações nem estatísticas disponíveis para a respetiva organização para o dia específico. Este pode ser o caso real ou os pipelines podem ter sido executados antes de todas as recomendações ou estatísticas estarem disponíveis para o dia.
Veja tabelas para uma transferência
Quando exporta recomendações para o BigQuery, o conjunto de dados contém duas tabelas particionadas por data:
- recommendations_export
- insight_export
Para mais detalhes sobre tabelas e esquemas, consulte os artigos Criar e usar tabelas e Especificar um esquema.
Para ver as tabelas de uma transferência de dados, faça o seguinte:
Aceda à página do BigQuery na Google Cloud consola. Aceda à página do BigQuery
Clique em Transferências de dados. Pode ver todas as transferências de dados disponíveis.
Clique na transferência adequada na lista.
Clique no separador CONFIGURAÇÃO e clique no conjunto de dados.
No painel Explorador, expanda o projeto e selecione um conjunto de dados. A descrição e os detalhes são apresentados no painel de detalhes. As tabelas de um conjunto de dados são apresentadas com o nome do conjunto de dados no painel Explorador.
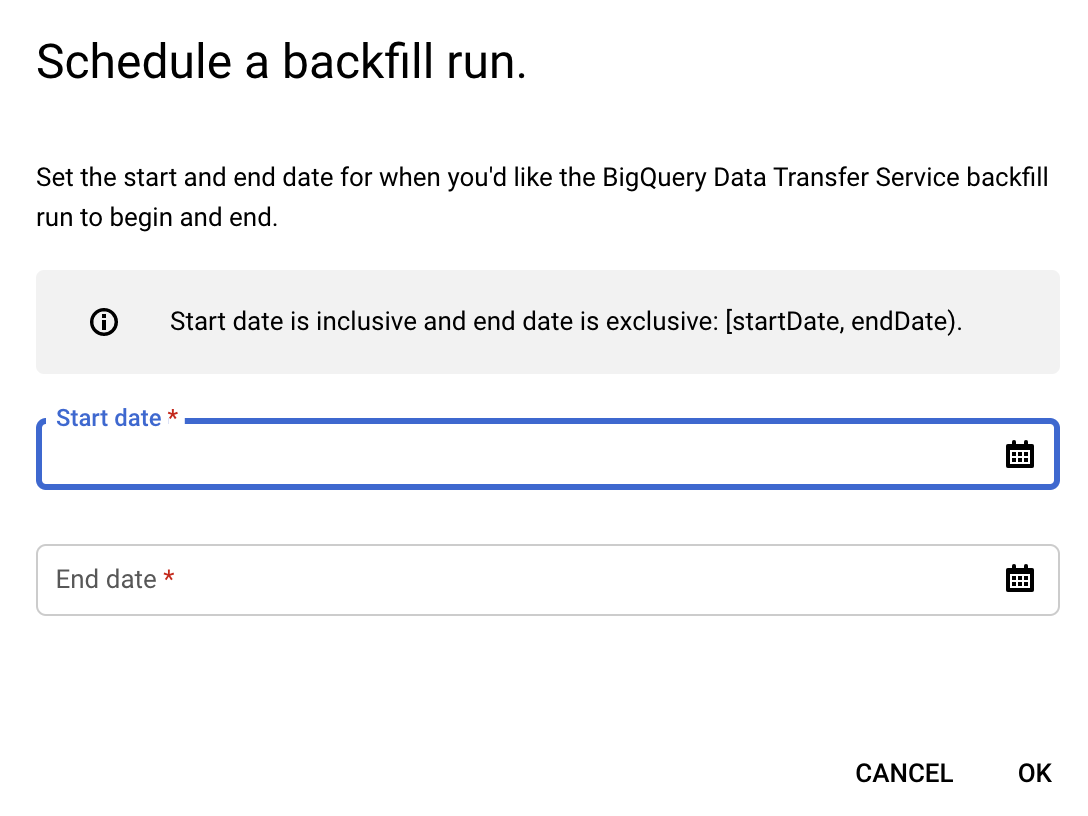
Agende um repreenchimento
As recomendações para uma data no passado (esta data é posterior à data em que a organização optou pela exportação) podem ser exportadas agendando um preenchimento. Para agendar um preenchimento, faça o seguinte:
Aceda à página do BigQuery na Google Cloud consola.
Clique em Transferências de dados.
Na página Transferências, clique numa transferência adequada na lista.
Clique em Agendar preenchimento.
Na caixa de diálogo Agendar preenchimento, escolha a Data de início e a Data de fim.
Para mais informações sobre como trabalhar com transferências, consulte o artigo Trabalhar com transferências.
Esquema de exportação
Tabela de exportação de recomendações:
schema:
fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: recommender
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: recommender_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: primary_impact
type: RECORD
description: |
Required. The primary impact that this recommendation can have while trying to optimize
for one category.
schema:
fields:
- name: category
type: STRING
description: |
Category that is being targeted.
Values can be the following:
CATEGORY_UNSPECIFIED:
Default unspecified category. Do not use directly.
COST:
Indicates a potential increase or decrease in cost.
SECURITY:
Indicates a potential increase or decrease in security.
PERFORMANCE:
Indicates a potential increase or decrease in performance.
RELIABILITY:
Indicates a potential increase or decrease in reliability.
- name: cost_projection
type: RECORD
description: Optional. Use with CategoryType.COST
schema:
fields:
- name: cost
type: RECORD
description: |
An approximate projection on amount saved or amount incurred.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: cost_in_local_currency
type: RECORD
description: |
An approximate projection on amount saved or amount incurred in the local currency.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: duration
type: RECORD
description: Duration for which this cost applies.
schema:
fields:
- name: seconds
type: INTEGER
description: |
Signed seconds of the span of time. Must be from -315,576,000,000
to +315,576,000,000 inclusive. Note: these bounds are computed from:
60 sec/min * 60 min/hr * 24 hr/day * 365.25 days/year * 10000 years
- name: nanos
type: INTEGER
description: |
Signed fractions of a second at nanosecond resolution of the span
of time. Durations less than one second are represented with a 0
`seconds` field and a positive or negative `nanos` field. For durations
of one second or more, a non-zero value for the `nanos` field must be
of the same sign as the `seconds` field. Must be from -999,999,999
to +999,999,999 inclusive.
- name: pricing_type_name
type: STRING
description: |
A pricing type can either be based on the price listed on GCP (LIST) or a custom
price based on past usage (CUSTOM).
- name: reliability_projection
type: RECORD
description: Optional. Use with CategoryType.RELIABILITY
schema:
fields:
- name: risk_types
type: STRING
mode: REPEATED
description: |
The risk associated with the reliability issue.
RISK_TYPE_UNSPECIFIED:
Default unspecified risk. Do not use directly.
SERVICE_DISRUPTION:
Potential service downtime.
DATA_LOSS:
Potential data loss.
ACCESS_DENY:
Potential access denial. The service is still up but some or all clients
can not access it.
- name: details_json
type: STRING
description: |
Additional reliability impact details that is provided by the recommender in JSON
format.
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_insights
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: recommendation_details
type: STRING
description: |
Additional details about the recommendation in JSON format.
schema:
- name: overview
type: RECORD
description: Overview of the recommendation in JSON format
- name: operation_groups
type: OperationGroup
mode: REPEATED
description: Operations to one or more Google Cloud resources grouped in such a way
that, all operations within one group are expected to be performed
atomically and in an order. More here: https://cloud.google.com/recommender/docs/key-concepts#operation_groups
- name: operations
type: Operation
description: An Operation is the individual action that must be performed as one of the atomic steps in a suggested recommendation. More here: https://cloud.google.com/recommender/docs/key-concepts?#operation
- name: state_metadata
type: map with key: STRING, value: STRING
description: A map of STRING key, STRING value of metadata for the state, provided by user or automations systems.
- name: additional_impact
type: Impact
mode: REPEATED
description: Optional set of additional impact that this recommendation may have when
trying to optimize for the primary category. These may be positive
or negative. More here: https://cloud.google.com/recommender/docs/key-concepts?#recommender_impact
- name: priority
type: STRING
description: |
Priority of the recommendation:
PRIORITY_UNSPECIFIED:
Default unspecified priority. Do not use directly.
P4:
Lowest priority.
P3:
Second lowest priority.
P2:
Second highest priority.
P1:
Highest priority.
Tabela de exportação de estatísticas:
schema:
- fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: insight_type
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: insight_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: category
type: STRING
description: |
Category being targeted by the insight. Can be one of:
Unspecified category.
CATEGORY_UNSPECIFIED = Unspecified category.
COST = The insight is related to cost.
SECURITY = The insight is related to security.
PERFORMANCE = The insight is related to performance.
MANAGEABILITY = The insight is related to manageability.
RELIABILITY = The insight is related to reliability.;
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_recommendations
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: insight_details
type: STRING
description: |
Additional details about the insight in JSON format
schema:
fields:
- name: content
type: STRING
description: |
A struct of custom fields to explain the insight.
Example: "grantedPermissionsCount": "1000"
- name: observation_period
type: TIMESTAMP
description: |
Observation period that led to the insight. The source data used to
generate the insight ends at last_refresh_time and begins at
(last_refresh_time - observation_period).
- name: state_metadata
type: STRING
description: |
A map of metadata for the state, provided by user or automations systems.
- name: severity
type: STRING
description: |
Severity of the insight:
SEVERITY_UNSPECIFIED:
Default unspecified severity. Do not use directly.
LOW:
Lowest severity.
MEDIUM:
Second lowest severity.
HIGH:
Second highest severity.
CRITICAL:
Highest severity.
Consultas de exemplo
Pode usar as seguintes consultas de exemplo para analisar os dados exportados.
Ver poupanças de custos para recomendações em que a duração da recomendação é apresentada em dias
SELECT name, recommender, target_resources,
case primary_impact.cost_projection.cost.units is null
when true then round(primary_impact.cost_projection.cost.nanos * power(10,-9),2)
else
round( primary_impact.cost_projection.cost.units +
(primary_impact.cost_projection.cost.nanos * power(10,-9)), 2)
end
as dollar_amt,
primary_impact.cost_projection.duration.seconds/(60*60*24) as duration_in_days
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and primary_impact.category = "COST"
Ver a lista de funções de IAM não usadas
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REMOVE_ROLE"
Ver uma lista de funções concedidas que têm de ser substituídas por funções mais pequenas
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REPLACE_ROLE"
Ver estatísticas de uma recomendação
SELECT recommendations.name as recommendation_name,
insights.name as insight_name,
recommendations.cloud_entity_id,
recommendations.cloud_entity_type,
recommendations.recommender,
recommendations.recommender_subtype,
recommendations.description,
recommendations.target_resources,
recommendations.recommendation_details,
recommendations.state,
recommendations.last_refresh_time as recommendation_last_refresh_time,
insights.insight_type,
insights.insight_subtype,
insights.category,
insights.description,
insights.insight_details,
insights.state,
insights.last_refresh_time as insight_last_refresh_time
FROM `<project>.<dataset>.recommendations_export` as recommendations,
`<project>.<dataset>.insights_export` as insights
WHERE DATE(recommendations._PARTITIONTIME) = "<date>"
and DATE(insights._PARTITIONTIME) = "<date>"
and insights.name in unnest(recommendations.associated_insights)
Ver recomendações para projetos pertencentes a uma pasta específica
Esta consulta devolve pastas principais até cinco níveis do projeto.
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and "<folder_id>" in unnest(ancestors.folder_ids)
A ver recomendações para a data mais recente disponível exportada até agora
DECLARE max_date TIMESTAMP;
SET max_date = (
SELECT MAX(_PARTITIONTIME) FROM
`<project>.<dataset>.recommendations_export`
);
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE _PARTITIONTIME = max_date
Use o Sheets para explorar dados do BigQuery
Em alternativa à execução de consultas no BigQuery, pode aceder, analisar, visualizar e partilhar milhares de milhões de linhas de dados do BigQuery a partir da sua folha de cálculo com a funcionalidade Connected Sheets, o novo conetor de dados do BigQuery. Para mais informações, consulte o artigo Comece a usar os dados do BigQuery no Google Sheets.
Configure a exportação através da linha de comandos do BigQuery e da API REST
Obtenha as autorizações necessárias:
Pode obter as autorizações de gestão de identidade e acesso necessárias através da Google Cloud consola ou da linha de comandos.
- Linha de comandos para contas de serviço
- Linha de comandos para utilizadores:
Por exemplo, para usar a linha de comandos para obter a autorização recommender.resources.export ao nível da organização para a conta de serviço:
gcloud organizations add-iam-policy-binding *<organization_id>* --member=serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'Inscreva o projeto na origem de dados do BigQuery
Datasource to use: 6063d10f-0000-2c12-a706-f403045e6250Crie a exportação:
Usar a linha de comandos do BigQuery:
bq mk \ --transfer_config \ --project_id=project_id \ --target_dataset=dataset_id \ --display_name=name \ --params='parameters' \ --data_source=data_source \ --service_account_name=service_account_name
Onde:
- project_id é o ID do seu projeto.
- dataset é o ID do conjunto de dados de destino para a configuração de transferência.
- name é o nome a apresentar da configuração de transferência. O nome da transferência pode ser qualquer valor que lhe permita identificar facilmente a transferência se precisar de a modificar mais tarde.
- parameters contém os parâmetros da configuração de transferência criada no formato JSON. Para o BigQuery Export de recomendações e estatísticas, tem de fornecer o organization_id para o qual as recomendações e as estatísticas têm de ser exportadas. Formato dos parâmetros: "{"organization_id":"<org id>"}"
- data_source Origem de dados a usar: "6063d10f-0000-2c12-a706-f403045e6250"
- service_account_name é o nome da conta de serviço usado para autenticar a sua exportação. A conta de serviço deve ser propriedade da mesma
project_idusada para criar a transferência e deve ter todas as autorizações necessárias indicadas acima.
Faça a gestão de uma exportação existente através da IU ou da linha de comandos do BigQuery:
Nota: a exportação é executada como o utilizador que configurou a conta, independentemente de quem atualizar a configuração de exportação no futuro. Por exemplo, se a exportação estiver configurada através de uma conta de serviço e, posteriormente, um utilizador humano atualizar a configuração de exportação através da IU do Serviço de transferência de dados do BigQuery, a exportação continua a ser executada como a conta de serviço. Neste caso, a verificação de autorização para "recommender.resources.export" é feita para a conta de serviço sempre que a exportação é executada.