Empfehlungen in BigQuery exportieren.
Übersicht
Mit dem BigQuery-Export können Sie sich tägliche Snapshots von Empfehlungen für Ihre Organisation anzeigen lassen. Dies geschieht mithilfe von BigQuery Data Transfer Service. In diesem Dokument erfahren Sie, welche Recommender derzeit in BigQuery Export enthalten sind.
Hinweis
Führen Sie die folgenden Schritte aus, bevor Sie eine Datenübertragung für Empfehlungen erstellen:
- Gewähren Sie BigQuery Data Transfer Service die Berechtigung zum Verwalten Ihrer Datenübertragung. Wenn Sie die Übertragung mit der BigQuery-Web-UI erstellen, müssen Sie Pop-ups von
console.cloud.google.comin Ihrem Browser zulassen, damit die Berechtigungen angezeigt werden können. Weitere Informationen finden Sie unter BigQuery Data Transfer Service aktivieren. - Erstellen Sie ein BigQuery-Dataset zum Speichern Ihrer Daten.
- Für die Datenübertragung wird dieselbe Region verwendet, in der das Dataset erstellt wird. Der Speicherort ist unveränderlich, sobald das Dataset und die Übertragung erstellt wurden.
- Das Dataset enthält Statistiken und Empfehlungen aus allen Regionen der Welt. Bei diesem Vorgang werden alle diese Daten in einer globalen Region zusammengefasst. Wenden Sie sich an Google Cloud Customer Care, wenn es Bedenken hinsichtlich des Datenstandort gibt.
- Wenn der Dataset-Speicherort neu eingeführt wurde, kann es zu einer Verzögerung bei der Verfügbarkeit der ersten Exportdaten kommen.
Preise
Der Export von Empfehlungen nach BigQuery steht allen Recommender-Kunden basierend auf ihrer Recommender-Preisstufe zur Verfügung.
Erforderliche Berechtigungen
Beim Einrichten der Datenübertragung benötigen Sie die folgenden Berechtigungen auf der Projektebene, auf der Sie eine Datenübertragung erstellen:
bigquery.transfers.update– Ermöglicht das Erstellen der Übertragungbigquery.datasets.update– ermöglicht das Aktualisieren von Aktionen für das Ziel-Datasetresourcemanager.projects.update– Ermöglicht die Auswahl eines Projekts, in dem die Exportdaten gespeichert werden sollenpubsub.topics.list: Ermöglicht die Auswahl eines Pub/Sub-Themas, um Benachrichtigungen zu Ihrem Export zu erhalten
Die folgende Berechtigung ist auf Organisationsebene erforderlich. Diese Organisation entspricht der Organisation, für die der Export eingerichtet wird.
recommender.resources.export– ermöglicht das Exportieren von Empfehlungen nach BigQuery
Die folgenden Berechtigungen sind erforderlich, um ausgehandelte Preise für Empfehlungen zur Kosteneinsparung zu exportieren:
billing.resourceCosts.get at project level: Ermöglicht den Export von ausgehandelten Preisen für Empfehlungen auf Projektebenebilling.accounts.getSpendingInformation at billing account level: Ermöglicht den Export von ausgehandelten Preisen für Empfehlungen auf Rechnungskontoebene
Ohne diese Berechtigungen werden Empfehlungen zur Kosteneinsparung mit Standardpreisen statt mit ausgehandelten Preisen exportiert.
Berechtigungen erteilen
Die folgenden Rollen müssen für das Projekt gewährt werden, in dem Sie die Datenübertragung erstellen:
- BigQuery-Administratorrolle –
roles/bigquery.admin - Rolle "Projektinhaber"
roles/owner - Rolle Projektinhaber –
roles/owner - Rolle Projektbetrachter –
roles/viewer - Rolle Projektbearbeiter –
roles/editor - Rolle Rechnungskontoadministrator –
roles/billing.admin - Rolle Rechnungskonto-Kostenverwalter –
roles/billing.costsManager - Rolle Rechnungskonto-Betrachter –
roles/billing.viewer
Damit Sie Übertragungs- und Aktualisierungsaktionen für das Ziel-Dataset erstellen können, müssen Sie die folgende Rolle zuweisen:
Es gibt mehrere Rollen, die Berechtigungen zum Auswählen eines Projekts zum Speichern Ihrer Exportdaten und zum Auswählen eines Pub/Sub-Themas zum Empfangen von Benachrichtigungen enthalten. Um diese beiden Berechtigungen zu haben, können Sie die folgende Rolle zuweisen:
Es gibt mehrere Rollen, die die Berechtigung „billing.resourceCosts.get“ enthalten, um ausgehandelte Preise für Empfehlungen auf Projektebene zu Kosteneinsparungen zu exportieren. Sie können eine beliebige davon zuweisen:
Es gibt mehrere Rollen, die die Berechtigung „billing.accounts.getSpendingInformation“ zum Exportieren ausgehandelter Preise für Empfehlungen auf Rechnungskontoebene zu Kosteneinsparungen enthalten. Sie können eine beliebige davon zuweisen:
Sie müssen auf Organisationsebene die folgende Rolle zuweisen:
- Rolle Empfehlungsexporteur (
roles/recommender.exporter) in der Google Cloud -Konsole.
Sie können auch benutzerdefinierte Rollen erstellen, die die erforderlichen Berechtigungen enthalten.
Datenübertragung für Empfehlungen erstellen
In der Google Cloud Console anmelden
Klicken Sie auf der Startseite auf den Tab Empfehlungen.
Klicken Sie auf Exportieren, um das BigQuery-Exportformular aufzurufen.
Wählen Sie ein Zielprojekt aus, um die Empfehlungsdaten zu speichern, und klicken Sie auf Weiter.
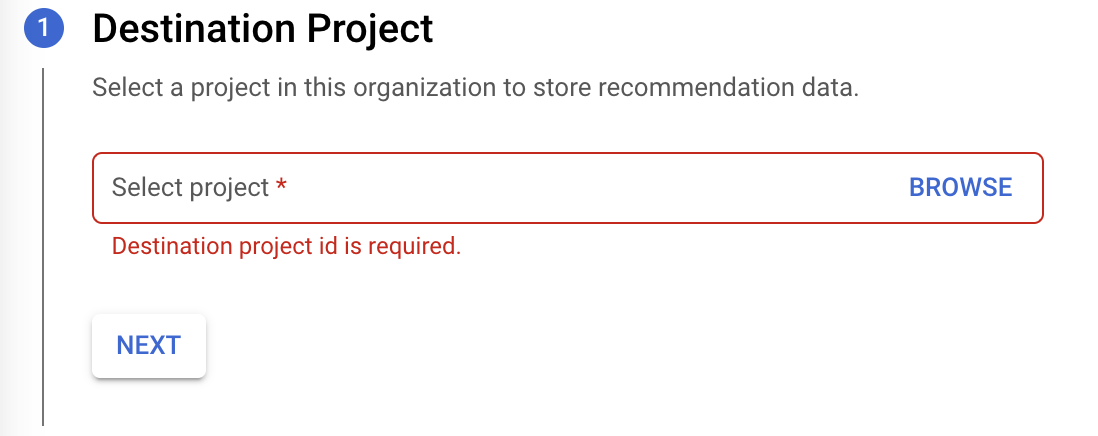
Klicken Sie auf APIs aktivieren, um die BigQuery APIs für den Export zu aktivieren. Dieser Vorgang kann einige Sekunden dauern. Klicken Sie anschließend auf Weiter.
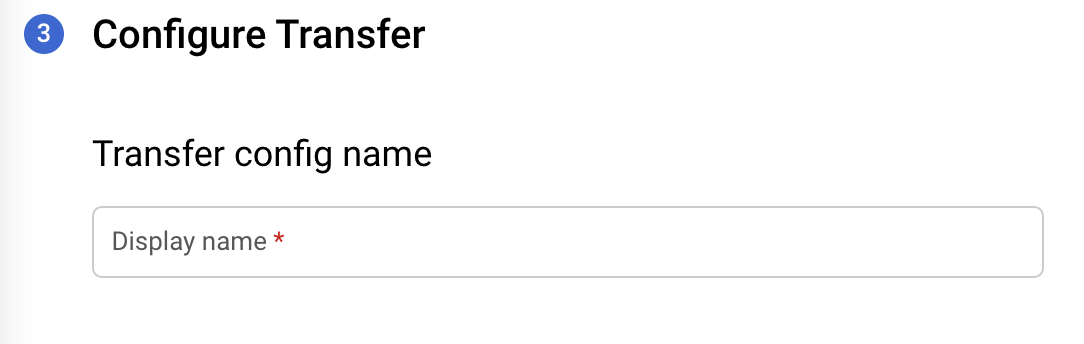
Geben Sie im Formular Configure Transfer (Übertragung konfigurieren) folgende Details an:
Geben Sie im Abschnitt Transfer config name (Konfigurationsname für Übertragung) für Display name (Anzeigename) einen Namen für die Übertragung ein. Der Anzeigename kann ein beliebiger Wert sein, mit dem Sie die Übertragung einfach identifizieren können, wenn Sie sie später ändern möchten.
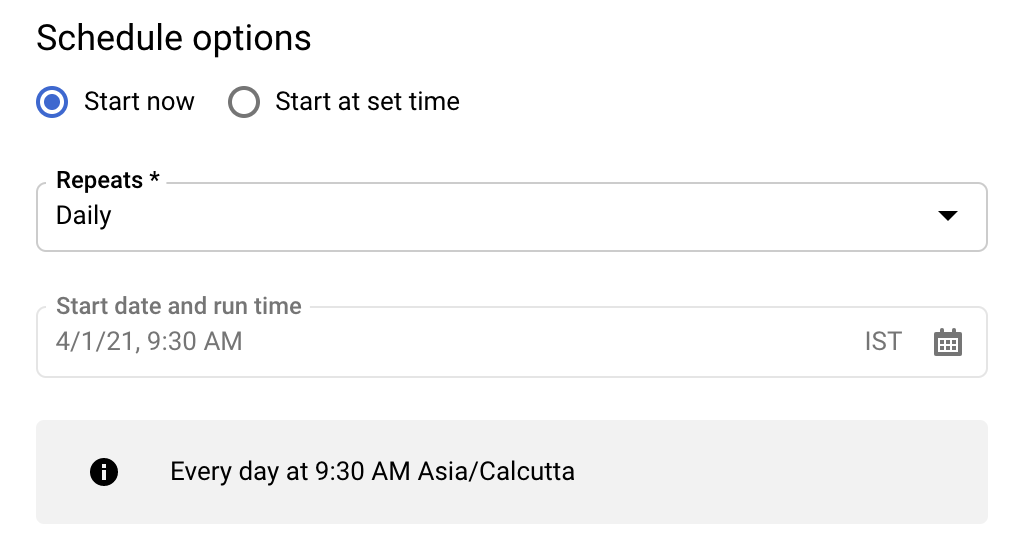
Übernehmen Sie im Abschnitt Schedule options (Zeitplanoptionen) für Schedule (Zeitplan) den Standardwert (Start now) (Jetzt starten) oder klicken Sie auf Start at a set time (Zu einer festgelegten Zeit starten).
Wählen Sie für Repeats (Wiederholungen) eine Option aus, um festzulegen, wie oft die Übertragung ausgeführt werden soll.
- Täglich (Standardeinstellung)
- Wöchentlich
- Monatlich
- Benutzerdefiniert
- On demand
Geben Sie für Start date and run time (Startdatum und Laufzeit) das Datum und die Uhrzeit für den Start der Übertragung ein. Wenn Sie Jetzt starten auswählen, ist diese Option deaktiviert.
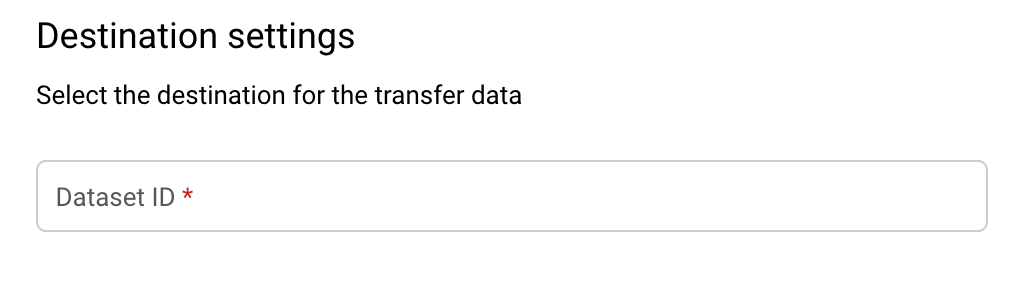
Wählen Sie im Abschnitt Destination settings (Zieleinstellungen) für Destination dataset (Ziel-Dataset) das Dataset aus, das Sie zum Speichern Ihrer Daten erstellt haben.
Im Abschnitt Data source details (Details zur Datenquelle):
Der Standardwert für organization_id ist die Organisation, für die Sie derzeit Empfehlungen sehen. Wenn Sie Empfehlungen in eine andere Organisation exportieren möchten, können Sie dies in der Organisationsanzeige oben in der Konsole ändern.

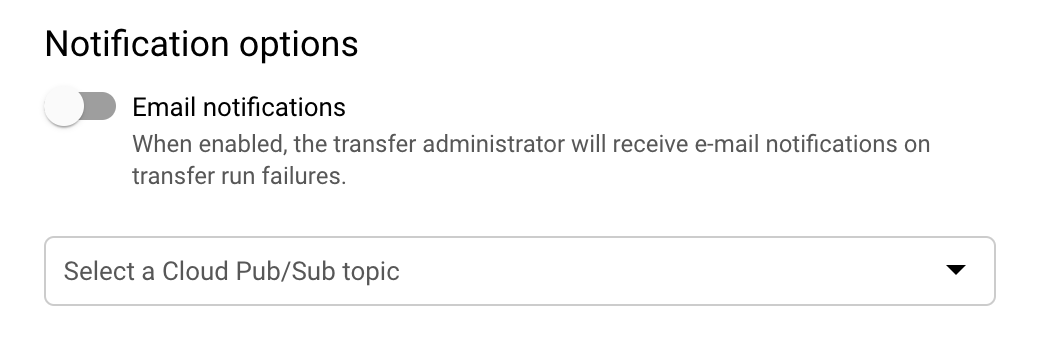
Optional: Im Abschnitt Notification options (Benachrichtigungsoptionen):
- Klicken Sie auf die Umschaltfläche, um E-Mail-Benachrichtigungen zu aktivieren. Wenn Sie diese Option aktivieren, erhält der Übertragungsadministrator eine E-Mail-Benachrichtigung, wenn ein Übertragungsvorgang fehlschlägt.
- Wählen Sie unter Pub/Sub-Thema auswählen Ihr Thema aus oder klicken Sie auf Thema erstellen. Mit dieser Option werden Pub/Sub-Ausführungsbenachrichtigungen für Ihre Übertragung konfiguriert.
Klicken Sie auf Erstellen, um die Übertragung zu erstellen.
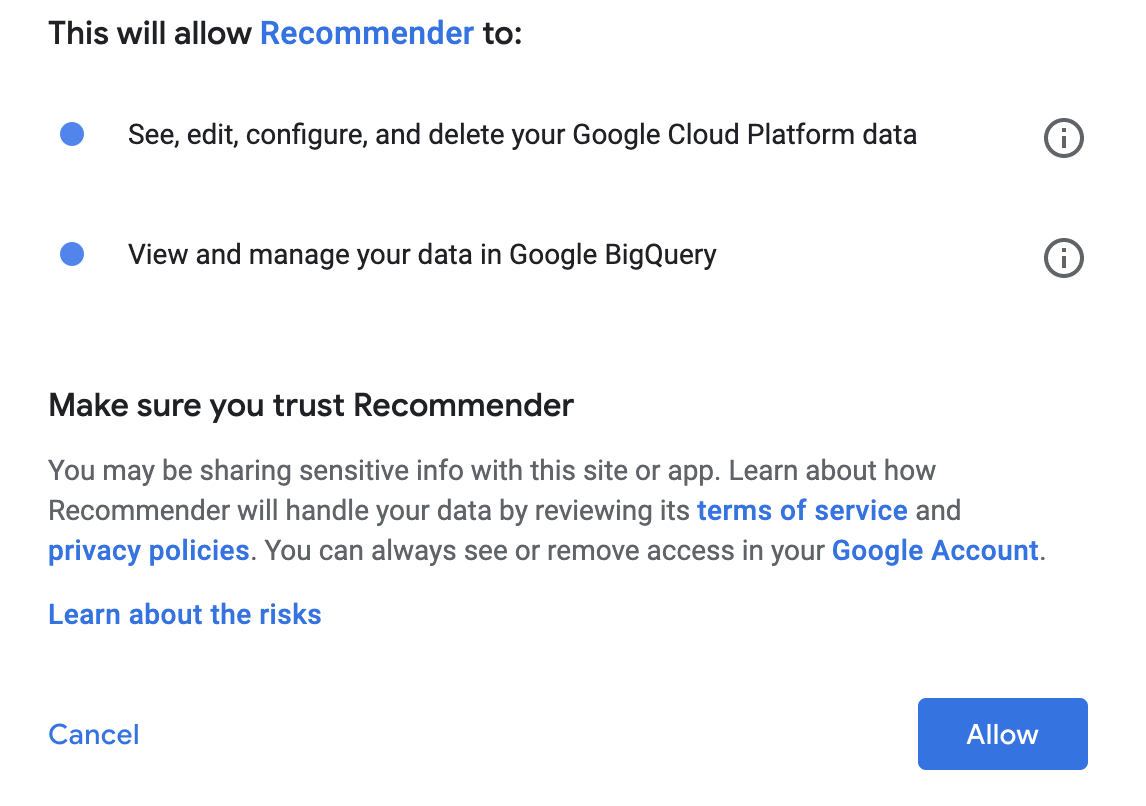
Klicken Sie im Pop-up für die Einwilligung auf Zulassen.
Nach der Erstellung der Übertragung werden Sie zu Active Assist zurückgeleitet. Sie können auf den Link klicken, um auf die Übertragungskonfiguration zuzugreifen. Alternativ können Sie auch folgendermaßen auf die Übertragungen zugreifen:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie auf Datenübertragungen. Sie können sich alle verfügbaren Datenübertragungen ansehen.
Ausführungsverlauf für eine Übertragung aufrufen
So rufen Sie den Ausführungsverlauf für eine Übertragung auf:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie auf Datenübertragungen. Sie können sich alle verfügbaren Datenübertragungen ansehen.
Klicken Sie in der Liste auf die entsprechende Übertragung.
Wählen Sie in der Liste der ausgeführten Übertragungen, die auf dem Tab VERLAUF VERWALTEN angezeigt werden, die Übertragung aus, deren Details Sie sehen möchten.
Der Bereich Ausführungsdetails wird für die ausgewählte Übertragung angezeigt, die Sie ausgewählt haben. Im Folgenden werden einige der möglichen Ausführungsdetails angezeigt:
- Die Übertragung wurde aufgrund von nicht verfügbaren Quelldaten verschoben.
- Job, der die Anzahl der in eine Tabelle exportierten Zeilen angibt
- Fehlende Berechtigungen für eine Datenquelle, die Sie gewähren und später einen Backfill planen müssen.
Wann werden Ihre Daten exportiert?
Wenn Sie eine Datenübertragung erstellen, erfolgt der erste Export innerhalb von zwei Tagen. Nach dem ersten Export werden die Exportjobs in dem Rhythmus ausgeführt, den Sie bei der Einrichtung angefordert haben. Dabei gelten folgende Bedingungen:
Der Exportjob für einen bestimmten Tag (D) exportiert die Daten des Endes des Tages (D) in Ihr BigQuery-Dataset, das normalerweise am Ende des nächsten Tages abgeschlossen ist (D+1). Der Exportjob wird in der PST-Zeitzone ausgeführt und kann bei anderen Zeitzonen länger dauern.
Der tägliche Exportjob wird erst ausgeführt, wenn alle Daten für den Export verfügbar sind. Das kann zu Abweichungen und manchmal zu Verzögerungen beim Tag und bei der Uhrzeit der Aktualisierung des Datasets führen. Daher ist es am besten, den neuesten verfügbaren Snapshot von Daten zu verwenden, statt eine feste zeitbasierte Abhängigkeit von bestimmten datierten Tabellen zu haben.
Beim Exportjob werden die neuesten verfügbaren Daten pro Region übertragen. Das bedeutet, dass sich das letzte Datum, für das Empfehlungen für verschiedene Regionen verfügbar sind, unterscheiden kann.
Gängige Statusmeldungen bei einem Export
Informationen zu gängigen Statusmeldungen, die Sie beim Exportieren von Empfehlungen nach BigQuery sehen können.
Nutzer hat nicht die erforderliche Berechtigung
Die folgende Meldung wird angezeigt, wenn der Nutzer nicht die erforderliche Berechtigung recommender.resources.export hat. Die folgende Meldung wird angezeigt:
User does not have required permission "recommender.resources.export". Please, obtain the required permissions for the datasource and try again by triggering a backfill for this date
Zum Beheben dieses Problems erteilen Sie dem user/service account, das den Export auf Organisationsebene für die Organisation einrichtet, für die der Export eingerichtet wurde, die IAM-Rolle roles/recommender.exporter. Sie kann über die folgenden gcloud-Befehle zugewiesen werden:
Für den Nutzer:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='user:*<user_name>*' --role='roles/recommender.exporter'Für das Dienstkonto:
gcloud organizations add-iam-policy-binding *<organization_id>* --member='serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'
Übertragung verzögert, weil keine Quelldaten verfügbar sind
Die folgende Meldung wird angezeigt, wenn die Übertragung neu geplant wird, weil die Quelldaten noch nicht verfügbar sind. Dies ist kein Fehler. Dies bedeutet, dass die Exportpipelines für den Tag noch nicht abgeschlossen wurden. Die Übertragung wird zum neuen geplanten Zeitpunkt noch einmal ausgeführt und ist erfolgreich, sobald die Export-Pipelines abgeschlossen sind. Die folgende Meldung wird angezeigt:
Transfer deferred due to source data not being available
Quelldaten nicht gefunden
Die folgende Meldung tritt auf, wenn F1toPlacer-Pipelines abgeschlossen sind, aber keine Empfehlungen oder Statistiken für die Organisation gefunden wurden, für die der Export eingerichtet wurde. Die folgende Meldung wird angezeigt:
Source data not found for 'recommendations_export$<date>'insights_export$<date>
Diese Meldung tritt aus folgenden Gründen auf:
- Der Nutzer hat den Export vor weniger als 2 Tagen eingerichtet. Im Kundenleitfaden werden die Kunden darüber informiert, dass es einen Tag dauern kann, bis der Export verfügbar ist.
- Für den jeweiligen Tag sind keine Empfehlungen oder Statistiken für ihre Organisation verfügbar. Das kann tatsächlich der Fall sein oder die Pipelines wurden ausgeführt, bevor alle Empfehlungen oder Statistiken für den Tag verfügbar waren.
Tabellen für eine Übertragung aufrufen
Wenn Sie Empfehlungen nach BigQuery exportieren, enthält das Dataset zwei Tabellen, die nach Datum partitioniert sind:
- recommendations_export
- insight_export
Weitere Informationen zu Tabellen und Schemas finden Sie unter Tabellen erstellen und verwenden und Schema angeben.
So rufen Sie die Tabellen für eine Datenübertragung auf:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf. Zur Seite „BigQuery“
Klicken Sie auf Datenübertragungen. Sie können sich alle verfügbaren Datenübertragungen ansehen.
Klicken Sie in der Liste auf die entsprechende Übertragung.
Klicken Sie auf den Tab KONFIGURATION und dann auf das Dataset.
Maximieren Sie im Bereich Explorer Ihr Projekt und wählen Sie ein Dataset aus. Die Beschreibung und die Details werden im Detailbereich angezeigt. Die Tabellen für ein Dataset werden im Bereich Explorer mit dem Namen des Datasets aufgeführt.
Planen Sie einen Backfill.
Empfehlungen für ein Datum in der Vergangenheit (das Datum liegt nach dem Datum, an dem die Organisation für den Export aktiviert war) können mit einem Backfill exportiert werden. So planen Sie einen Backfill:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie auf Datenübertragungen.
Klicken Sie auf der Seite Übertragungen auf eine geeignete Übertragung in der Liste.
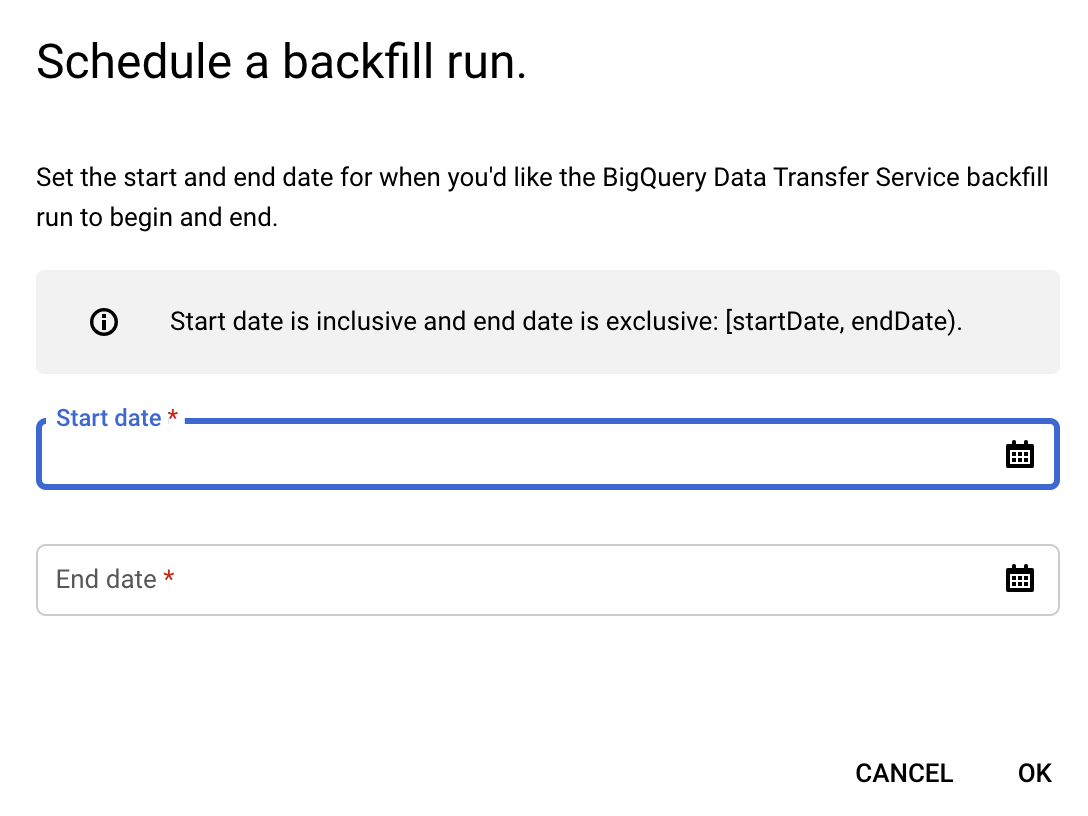
Klicken Sie auf Backfill planen.
Wählen Sie im Dialogfeld Backfill planen das Startdatum und das Enddatum aus.
Weitere Informationen zum Arbeiten mit Übertragungen finden Sie unter Mit Übertragungen arbeiten.
Exportschema
Tabelle mit Empfehlungen exportieren:
schema:
fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: recommender
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: recommender_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: primary_impact
type: RECORD
description: |
Required. The primary impact that this recommendation can have while trying to optimize
for one category.
schema:
fields:
- name: category
type: STRING
description: |
Category that is being targeted.
Values can be the following:
CATEGORY_UNSPECIFIED:
Default unspecified category. Do not use directly.
COST:
Indicates a potential increase or decrease in cost.
SECURITY:
Indicates a potential increase or decrease in security.
PERFORMANCE:
Indicates a potential increase or decrease in performance.
RELIABILITY:
Indicates a potential increase or decrease in reliability.
- name: cost_projection
type: RECORD
description: Optional. Use with CategoryType.COST
schema:
fields:
- name: cost
type: RECORD
description: |
An approximate projection on amount saved or amount incurred.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: cost_in_local_currency
type: RECORD
description: |
An approximate projection on amount saved or amount incurred in the local currency.
Negative cost units indicate cost savings and positive cost units indicate
increase. See google.type.Money documentation for positive/negative units.
schema:
fields:
- name: currency_code
type: STRING
description: The 3-letter currency code defined in ISO 4217.
- name: units
type: INTEGER
description: |
The whole units of the amount. For example if `currencyCode` is `"USD"`,
then 1 unit is one US dollar.
- name: nanos
type: INTEGER
description: |
Number of nano (10^-9) units of the amount.
The value must be between -999,999,999 and +999,999,999 inclusive.
If `units` is positive, `nanos` must be positive or zero.
If `units` is zero, `nanos` can be positive, zero, or negative.
If `units` is negative, `nanos` must be negative or zero.
For example $-1.75 is represented as `units`=-1 and `nanos`=-750,000,000.
- name: duration
type: RECORD
description: Duration for which this cost applies.
schema:
fields:
- name: seconds
type: INTEGER
description: |
Signed seconds of the span of time. Must be from -315,576,000,000
to +315,576,000,000 inclusive. Note: these bounds are computed from:
60 sec/min * 60 min/hr * 24 hr/day * 365.25 days/year * 10000 years
- name: nanos
type: INTEGER
description: |
Signed fractions of a second at nanosecond resolution of the span
of time. Durations less than one second are represented with a 0
`seconds` field and a positive or negative `nanos` field. For durations
of one second or more, a non-zero value for the `nanos` field must be
of the same sign as the `seconds` field. Must be from -999,999,999
to +999,999,999 inclusive.
- name: pricing_type_name
type: STRING
description: |
A pricing type can either be based on the price listed on GCP (LIST) or a custom
price based on past usage (CUSTOM).
- name: reliability_projection
type: RECORD
description: Optional. Use with CategoryType.RELIABILITY
schema:
fields:
- name: risk_types
type: STRING
mode: REPEATED
description: |
The risk associated with the reliability issue.
RISK_TYPE_UNSPECIFIED:
Default unspecified risk. Do not use directly.
SERVICE_DISRUPTION:
Potential service downtime.
DATA_LOSS:
Potential data loss.
ACCESS_DENY:
Potential access denial. The service is still up but some or all clients
can not access it.
- name: details_json
type: STRING
description: |
Additional reliability impact details that is provided by the recommender in JSON
format.
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_insights
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: recommendation_details
type: STRING
description: |
Additional details about the recommendation in JSON format.
schema:
- name: overview
type: RECORD
description: Overview of the recommendation in JSON format
- name: operation_groups
type: OperationGroup
mode: REPEATED
description: Operations to one or more Google Cloud resources grouped in such a way
that, all operations within one group are expected to be performed
atomically and in an order. More here: https://cloud.google.com/recommender/docs/key-concepts#operation_groups
- name: operations
type: Operation
description: An Operation is the individual action that must be performed as one of the atomic steps in a suggested recommendation. More here: https://cloud.google.com/recommender/docs/key-concepts?#operation
- name: state_metadata
type: map with key: STRING, value: STRING
description: A map of STRING key, STRING value of metadata for the state, provided by user or automations systems.
- name: additional_impact
type: Impact
mode: REPEATED
description: Optional set of additional impact that this recommendation may have when
trying to optimize for the primary category. These may be positive
or negative. More here: https://cloud.google.com/recommender/docs/key-concepts?#recommender_impact
- name: priority
type: STRING
description: |
Priority of the recommendation:
PRIORITY_UNSPECIFIED:
Default unspecified priority. Do not use directly.
P4:
Lowest priority.
P3:
Second lowest priority.
P2:
Second highest priority.
P1:
Highest priority.
Tabelle „Statistikexport“:
schema:
- fields:
- name: cloud_entity_type
type: STRING
description: |
Represents what cloud entity type the recommendation was generated for - eg: project number, billing account
- name: cloud_entity_id
type: STRING
description: |
Value of the project number or billing account id
- name: name
type: STRING
description: |
Name of recommendation. A project recommendation is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/recommenders/[RECOMMENDER_ID]/recommendations/[RECOMMENDATION_ID]
- name: location
type: STRING
description: |
Location for which this recommendation is generated
- name: insight_type
type: STRING
description: |
Recommender ID of the recommender that has produced this recommendation
- name: insight_subtype
type: STRING
description: |
Contains an identifier for a subtype of recommendations produced for the
same recommender. Subtype is a function of content and impact, meaning a
new subtype will be added when either content or primary impact category
changes.
Examples:
For recommender = "google.iam.policy.Recommender",
recommender_subtype can be one of "REMOVE_ROLE"/"REPLACE_ROLE"
- name: target_resources
type: STRING
mode: REPEATED
description: |
Contains the fully qualified resource names for resources changed by the
operations in this recommendation. This field is always populated. ex:
[//cloudresourcemanager.googleapis.com/projects/foo].
- name: description
type: STRING
description: |
Required. Free-form human readable summary in English.
The maximum length is 500 characters.
- name: last_refresh_time
type: TIMESTAMP
description: |
Output only. Last time this recommendation was refreshed by the system that created it in the first place.
- name: category
type: STRING
description: |
Category being targeted by the insight. Can be one of:
Unspecified category.
CATEGORY_UNSPECIFIED = Unspecified category.
COST = The insight is related to cost.
SECURITY = The insight is related to security.
PERFORMANCE = The insight is related to performance.
MANAGEABILITY = The insight is related to manageability.
RELIABILITY = The insight is related to reliability.;
- name: state
type: STRING
description: |
Output only. The state of the recommendation:
STATE_UNSPECIFIED:
Default state. Do not use directly.
ACTIVE:
Recommendation is active and can be applied. Recommendations content can
be updated by Google.
ACTIVE recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
CLAIMED:
Recommendation is in claimed state. Recommendations content is
immutable and cannot be updated by Google.
CLAIMED recommendations can be marked as CLAIMED, SUCCEEDED, or FAILED.
SUCCEEDED:
Recommendation is in succeeded state. Recommendations content is
immutable and cannot be updated by Google.
SUCCEEDED recommendations can be marked as SUCCEEDED, or FAILED.
FAILED:
Recommendation is in failed state. Recommendations content is immutable
and cannot be updated by Google.
FAILED recommendations can be marked as SUCCEEDED, or FAILED.
DISMISSED:
Recommendation is in dismissed state.
DISMISSED recommendations can be marked as ACTIVE.
- name: ancestors
type: RECORD
description: |
Ancestry for the recommendation entity
schema:
fields:
- name: organization_id
type: STRING
description: |
Organization to which the recommendation project
- name: folder_ids
type: STRING
mode: REPEATED
description: |
Up to 5 levels of parent folders for the recommendation project
- name: associated_recommendations
type: STRING
mode: REPEATED
description: |
Insights associated with this recommendation. A project insight is represented as
projects/[PROJECT_NUMBER]/locations/[LOCATION]/insightTypes/[INSIGHT_TYPE_ID]/insights/[insight_id]
- name: insight_details
type: STRING
description: |
Additional details about the insight in JSON format
schema:
fields:
- name: content
type: STRING
description: |
A struct of custom fields to explain the insight.
Example: "grantedPermissionsCount": "1000"
- name: observation_period
type: TIMESTAMP
description: |
Observation period that led to the insight. The source data used to
generate the insight ends at last_refresh_time and begins at
(last_refresh_time - observation_period).
- name: state_metadata
type: STRING
description: |
A map of metadata for the state, provided by user or automations systems.
- name: severity
type: STRING
description: |
Severity of the insight:
SEVERITY_UNSPECIFIED:
Default unspecified severity. Do not use directly.
LOW:
Lowest severity.
MEDIUM:
Second lowest severity.
HIGH:
Second highest severity.
CRITICAL:
Highest severity.
Beispielabfragen
Sie können die folgenden Beispielabfragen verwenden, um Ihre exportierten Daten zu analysieren.
Kosteneinsparungen für Empfehlungen ansehen, wenn die Dauer der Empfehlung in Tagen angezeigt wird
SELECT name, recommender, target_resources,
case primary_impact.cost_projection.cost.units is null
when true then round(primary_impact.cost_projection.cost.nanos * power(10,-9),2)
else
round( primary_impact.cost_projection.cost.units +
(primary_impact.cost_projection.cost.nanos * power(10,-9)), 2)
end
as dollar_amt,
primary_impact.cost_projection.duration.seconds/(60*60*24) as duration_in_days
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and primary_impact.category = "COST"
Liste der nicht verwendeten IAM-Rollen ansehen
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REMOVE_ROLE"
Liste der zugewiesenen Rollen ansehen, die durch kleinere Rollen ersetzt werden müssen
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and recommender = "google.iam.policy.Recommender"
and recommender_subtype = "REPLACE_ROLE"
Statistiken für eine Empfehlung aufrufen
SELECT recommendations.name as recommendation_name,
insights.name as insight_name,
recommendations.cloud_entity_id,
recommendations.cloud_entity_type,
recommendations.recommender,
recommendations.recommender_subtype,
recommendations.description,
recommendations.target_resources,
recommendations.recommendation_details,
recommendations.state,
recommendations.last_refresh_time as recommendation_last_refresh_time,
insights.insight_type,
insights.insight_subtype,
insights.category,
insights.description,
insights.insight_details,
insights.state,
insights.last_refresh_time as insight_last_refresh_time
FROM `<project>.<dataset>.recommendations_export` as recommendations,
`<project>.<dataset>.insights_export` as insights
WHERE DATE(recommendations._PARTITIONTIME) = "<date>"
and DATE(insights._PARTITIONTIME) = "<date>"
and insights.name in unnest(recommendations.associated_insights)
Empfehlungen für Projekte aufrufen, die zu einem bestimmten Ordner gehören
Diese Abfrage gibt übergeordnete Ordner bis zu fünf Ebenen aus dem Projekt zurück.
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE DATE(_PARTITIONTIME) = "<date>"
and "<folder_id>" in unnest(ancestors.folder_ids)
Empfehlungen für den neuesten verfügbaren Exportierungszeitpunkt ansehen
DECLARE max_date TIMESTAMP;
SET max_date = (
SELECT MAX(_PARTITIONTIME) FROM
`<project>.<dataset>.recommendations_export`
);
SELECT *
FROM `<project>.<dataset>.recommendations_export`
WHERE _PARTITIONTIME = max_date
BigQuery-Daten mit Google Sheets untersuchen
Als Alternative zum Ausführen von Abfragen in BigQuery können Sie Milliarden von Zeilen mit BigQuery-Daten aus Ihrer Tabelle mit dem neuen BigQuery-Daten-Connector aufrufen, analysieren, visualisieren und freigeben. Weitere Informationen finden Sie unter Erste Schritte mit BigQuery-Daten in Google Sheets.
Export mit BigQuery-Befehlszeile und REST API einrichten
Erforderliche Berechtigungen abrufen
Sie können die erforderlichen IAM-Berechtigungen (Identity and Access Management) über die Google Cloud -Konsole oder die Befehlszeile abrufen.
- Befehlszeile für Dienstkonten
- Befehlszeile für Nutzer:
Wenn Sie beispielsweise über die Befehlszeile die Berechtigung "Recommender.resources.export" auf Organisationsebene für das Dienstkonto abrufen möchten:
gcloud organizations add-iam-policy-binding *<organization_id>* --member=serviceAccount:*<service_acct_name>*' --role='roles/recommender.exporter'Projekt in der BigQuery-Datenquelle registrieren
Datasource to use: 6063d10f-0000-2c12-a706-f403045e6250Erstellen Sie den Export:
bq mk \ --transfer_config \ --project_id=project_id \ --target_dataset=dataset_id \ --display_name=name \ --params='parameters' \ --data_source=data_source \ --service_account_name=service_account_name
Dabei gilt:
- project_id ist die Projekt-ID.
- dataset ist die Ziel-Dataset-ID für die Übertragungskonfiguration.
- name ist der Anzeigename für die Übertragungskonfiguration. Der Name der Übertragung kann ein beliebiger Wert sein, mit dem Sie die Übertragung einfach identifizieren können, wenn Sie sie später ändern müssen.
- parameters enthält die Parameter für die erstellte Übertragungskonfiguration im JSON-Format. Für den BigQuery Export von Empfehlungen und Insights müssen Sie die Organisations-ID angeben, für die Empfehlungen und Insights exportiert werden sollen. Parameterformat: '{“organization_id":"<org id>"}'
- data_source Zu verwendende Datenquelle: "6063d10f-0000-2c12-a706-f403045e6250"
- service_account_name ist der Name des Dienstkontos, der zur Authentifizierung des Exports verwendet wird. Das Dienstkonto sollte zum selben
project_idgehören, das für die Erstellung der Übertragung verwendet wurde, und sollte alle oben aufgeführten erforderlichen Berechtigungen haben.
So verwalten Sie einen vorhandenen Export über die Benutzeroberfläche oder die BigQuery-Befehlszeile:
Hinweis: Der Export wird als der Nutzer ausgeführt, der das Konto einrichtet, unabhängig davon, wer die Exportkonfiguration in Zukunft aktualisiert. Wenn der Export beispielsweise mit einem Dienstkonto eingerichtet wird und später ein Nutzer die Exportkonfiguration über die BigQuery Data Transfer Service-UI aktualisiert, wird der Export weiterhin als Dienstkonto ausgeführt. Die Berechtigungsprüfung für recommendrecommender.resources.export“ wird in diesem Fall für das Dienstkonto bei jedem Ausführung des Exports durchgeführt.