데이터세트 크기와 모델의 복잡성 정도에 따라 모델 학습 시간이 오래 걸릴 수도 있습니다. 실제 데이터를 기반으로 한 학습은 수 시간이 소요될 수도 있습니다. 학습이 실행되는 동안 다양한 측면에서 작업을 모니터링할 수 있습니다.
작업 상태 확인
Google Cloud Console의 AI Platform Training 작업 페이지를 사용하면 작업의 전체 상태를 가장 쉽게 확인할 수 있습니다. 프로그래매틱 방식 및 Google Cloud CLI를 사용하여 동일한 세부정보를 확인할 수 있습니다.
콘솔
Google Cloud Console에서 AI Platform Training 작업 페이지를 엽니다.
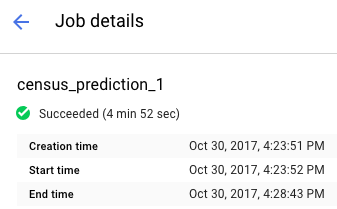
목록에서 작업 이름을 클릭하여 작업 세부정보 페이지를 엽니다.
보고서 상단에서 작업 상태를 확인합니다. 아이콘과 텍스트로 작업의 현재 상태를 알 수 있습니다.
작업 필터링
작업 페이지에서 유형 , JobID , 상태, 작업 생성 시간을 포함한 여러 가지 매개변수로 작업을 필터링할 수 있습니다.
- 작업 목록 위에 있는 프리픽스로 필터링 필드 안쪽을 클릭합니다. 필터링에 사용할 프리픽스를 선택합니다. 예를 들어 유형을 선택합니다.
필터를 완성하려면 사용하려는 필터 서픽스를 클릭합니다. 예를 들어 유형 프리픽스의 서픽스 옵션은 다음과 같습니다.
- 커스텀 코드 학습
- 기본 제공 알고리즘 학습
- 예측
필터가 작업 목록에 적용되고 필터 이름이 필터 필드에 표시됩니다. 예를 들어 커스텀 코드 학습을 선택한 경우 Type:Custom code training(유형: 커스텀 코드 학습)이 맨 위에 표시되고 작업 목록이 필터링됩니다. 필요한 경우 여러 필터를 추가할 수 있습니다.
초매개변수 시도 보기
작업 세부정보 페이지의 HyperTune trials(HyperTune 시도) 표에서 각 시도에 대한 측정항목을 볼 수 있습니다. 이 표는 초매개변수 미세 조정을 사용하는 작업에만 표시됩니다. 최고 또는 최저 rmse, Training steps, learning_rate를 기준으로 시도를 표시하도록 측정항목을 전환할 수 있습니다.
특정 시도에 대한 로그를 보려면
gcloud
gcloud ai-platform jobs describe를 사용해 명령줄에서 작업의 현재 상태에 대한 세부정보를 가져옵니다.
gcloud ai-platform jobs describe job_name
gcloud ai-platform jobs list로 작업 상태 및 생성 시간 등 프로젝트 관련 작업 목록을 가져올 수 있습니다.
가장 단순한 형태로 이 명령어를 실행하면 프로젝트에 생성한 모든 작업이 나열됩니다. 보고되는 작업 수를 제한하려면 요청의 범위를 지정해야 합니다. 다음 예시를 참조하세요.
작업 수를 제한하려면 --limit 인수를 사용합니다. 이 예시에서는 최근 작업 5개를 나열합니다.
gcloud ai-platform jobs list --limit=5
주어진 속성 값이 있는 작업으로 작업 목록을 제한하려면 --filter 인수를 사용합니다. 하나 이상의 Job 객체 속성을 기준으로 필터링할 수 있습니다. 주요 작업 속성뿐 아니라 TrainingInput 객체와 같이 작업에 포함된 객체를 기준으로 필터링할 수도 있습니다.
목록 필터링의 예:
특정 시간 이후에 시작된 모든 작업을 나열합니다. 이 예시에서는 2017년 1월 15일 저녁 7시 정각을 사용합니다.
gcloud ai-platform jobs list --filter='createTime>2017-01-15T19:00'특정 문자열로 시작하는 이름을 가진 마지막 작업 세 개를 나열합니다. 예를 들어 문자열은 특정 모델의 모든 학습 작업에 사용하는 이름을 나타낼 수 있습니다. 이 예시에서는 작업 식별자가 'census'이고 작업마다 증가하는 색인이 서픽스로 추가된 모델을 사용합니다.
gcloud ai-platform jobs list --filter='jobId:census*' --limit=3이름이 'rnn'으로 시작하는 실패한 모든 작업을 나열합니다.
gcloud ai-platform jobs list --filter='jobId:rnn* AND state:FAILED'
필터 옵션에서 지원하는 표현식에 대한 자세한 내용은 gcloud 명령어 관련 문서를 참조하세요.
Python
프로젝트 이름과 작업 이름을
'projects/your_project_name/jobs/your_job_name'형식으로 결합하여 작업 식별자 문자열을 조합합니다.projectName = 'your_project_name' projectId = 'projects/{}'.format(projectName) jobName = 'your_job_name' jobId = '{}/jobs/{}'.format(projectId, jobName)projects.jobs.get으로 요청을 작성합니다.
request = ml.projects().jobs().get(name=jobId)요청을 실행합니다. 이 예시에서는
execute호출을try블록에 넣어 예외를 포착합니다.response = None try: response = request.execute() except errors.HttpError, err: # Something went wrong. Handle the exception in an appropriate # way for your application.HTTP 오류와 관계없이 서비스 호출이 데이터를 반환했는지 응답을 확인합니다.
if response == None: # Treat this condition as an error as best suits your # application.상태 데이터를 가져옵니다. 응답 객체는 전체 TrainingInput 리소스 및 TrainingInput 리소스의 적용 가능한 멤버를 비롯하여 TrainingOutput 리소스의 적용 가능한 멤버를 모두 포함하는 사전입니다. 다음 예시에서는 작업 상태 및 작업에서 소비한 ML 단위 수를 출력합니다.
print('Job status for {}.{}:'.format(projectName, jobName)) print(' state : {}'.format(response['state'])) print(' consumedMLUnits : {}'.format( response['trainingOutput']['consumedMLUnits']))
학습 애플리케이션 또는 AI Platform Training 인프라에 문제가 있으면 작업이 실패할 수 있습니다. Cloud Logging을 사용하여 디버깅을 시작할 수 있습니다.
학습 작업이 실행되는 동안 대화형 셸을 사용하여 학습 컨테이너를 검사할 수도 있습니다.
리소스 소비 모니터링
작업 세부정보 페이지에서 학습 작업에 대한 다음과 같은 리소스 사용률 차트를 확인할 수 있습니다.
- 작업의 집계 CPU 또는 GPU 사용률 및 메모리 사용률. 이는 마스터, 작업자, 매개변수 서버별로 분류됩니다.
- 초당 바이트 수 단위로 측정된 작업의 네트워크 사용량. 전송된 바이트 수와 수신된 바이트 수에 대한 별도의 차트가 있습니다.
Google Cloud Console에서 AI Platform Training 작업 페이지로 이동합니다.
목록에서 작업을 찾습니다.
목록에서 작업 이름을 클릭하여 작업 세부정보 페이지를 엽니다.
CPU, GPU 또는 네트워크 라벨이 있는 표를 선택하여 관련 리소스 사용률 차트를 봅니다.
또한 학습 작업에서 Cloud Monitoring과 함께 사용하는 온라인 리소스에 대한 정보에 액세스할 수 있습니다. AI Platform Training은 측정항목을 Cloud Monitoring으로 내보냅니다.
각 AI Platform Training 측정항목 유형 이름에는 'training'이 포함됩니다. 예를 들면 ml.googleapis.com/training/cpu/utilization 또는 ml.googleapis.com/training/accelerator/memory/utilization입니다.
텐서보드를 사용한 모니터링
요약 데이터를 저장하도록 학습 애플리케이션을 구성한 후 TensorBoard를 사용하여 해당 데이터를 조사하고 시각화할 수 있습니다.
요약 데이터를 Cloud Storage 위치에 저장하고 텐서보드가 해당 위치를 가리키도록 설정하여 데이터를 조사합니다. 텐서보드가 여러 작업의 출력을 포함하는 하위 디렉터리를 갖는 디렉터리를 가리키도록 설정할 수도 있습니다.
텐서보드 및 AI Platform Training에 대한 자세한 내용은 시작 가이드를 참조하세요.
다음 단계
- 학습 작업 관련 문제 해결
- 온라인 테스트 및 예측 제공을 위해 학습된 모델 배포