This page describes the architecture of Dual Run for batch comparison and its components.
Dual Run architecture overview
Dual Run is deployed in your own private Google Cloud project, and runs as a set of microservices on top of Google Kubernetes Engine (GKE), interacting with other Google Cloud products.
The following diagram shows the Dual Run architecture for batch file comparison, as described in more details in the following sections.
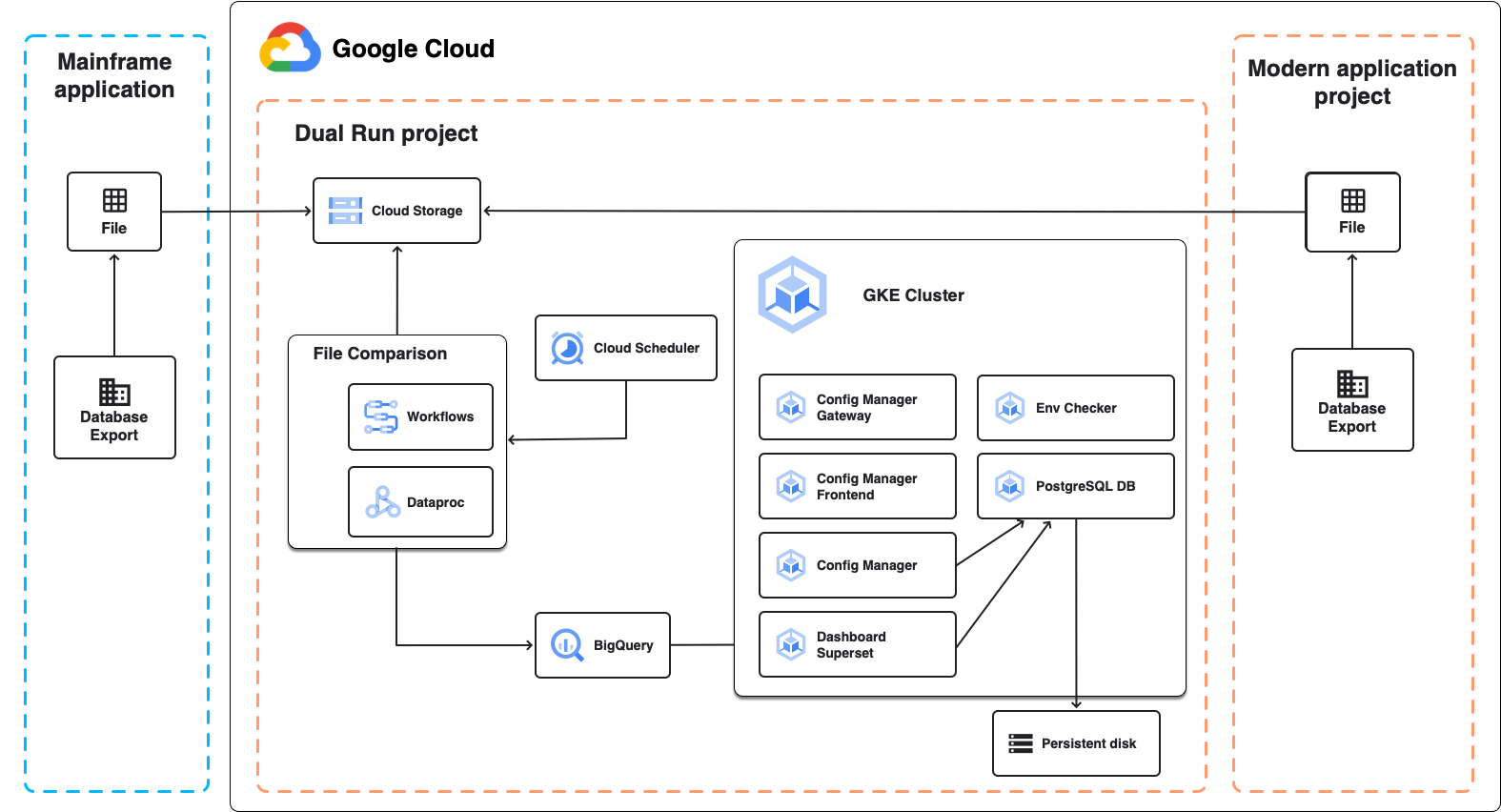
Dual Run architecture with a file comparison job between the mainframe and Google Cloud.
Dual Run components
Dual Run has the following components:
- File Comparison
- Config Manager: user interface and dashboards
- Env Checker
File Comparison
File Comparison is a Dual Run component that lets you compare the expected and actual file outputs of your Dual Run setup. When performing a comparison, you can set the level of tolerance to mark the results as equivalent.
File Comparison uses Dataproc, a fully managed Apache Spark cluster running on Google Cloud, to perform the comparison. Dataproc can be configured in two ways, depending on the size of data that you plan to compare and on your infrastructure requirements:
- A managed serverless Spark-based environment running on Google Cloud Dataproc that is created as part of the Dual Run deployment. It uses a fixed configuration that lets you compare files of up to several GB.
- A Spark cluster on Dataproc that you create and configure after the
Dual Run deployment. This is useful in the following cases:
- You plan to use special VMs or disk configurations.
- You need to compare files larger than several GB.
- You want to run multiple comparison jobs at the same time.
Config Manager
Config Manager is the Dual Run frontend. This component lets you configure user access and permissions, by using Google Cloud Identity and Access Management.
Config Manager provides also the dashboard environment where you can review the results of the file comparison jobs. The dashboard lets you view a summary of the comparison results based on filters that you apply, and lets you review the details of the results for each individual record. It also lets you create customized reports and queries.
Env Checker
Env Checker is the Dual Run component that verifies that the installation and deployment of Dual Run completed successfully. It checks that all the necessary Dual Run components are correctly configured and running, and reports any errors or misconfigurations otherwise.
Google Cloud dependencies
Dual Run internally relies on multiple Google Cloud services. They are automatically enabled and configured during the Dual Run deployment, and you don't need to manually configure them.
- Google Kubernetes Engine (GKE): Dual Run uses GKE to run its microservices in pods.
- Cloud Storage: Dual Run uses Storage buckets to store the configuration files of the environment, and the artifacts that you want to compare.
- BigQuery: Dual Run uses BigQuery to store the results of the File Comparison outputs.
- Pub/Sub: Dual Run uses Pub/Sub as an internal messaging system to pass configuration changes between the different pods.
- Dataproc: Dual Run uses Dataproc to create a serverless Spark cluster that you can use to run the file comparison.
- Workflows and Cloud Functions: Dual Run uses Workflows to manage the Cloud Functions that perform the file comparison jobs.
- Identity Platform: Dual Run relies on Identity Platform as an authentication service, which provides identity and access management capabilities. Identity Platform lets you use Google or SAML identity providers to authenticate users and authorize roles.
- Cloud SQL: Dual Run creates an instance of a Cloud SQL database for compatibility with the future updates.
What's next
Learn more about Dual Run File Comparison, which is the component responsible for comparing data generated by the mainframe and by the modern Google Cloud application.