在大型机上本地转码数据是一项 CPU 密集型进程,会导致每秒百万条指令 (MIPS) 消耗量较高。为避免这种情况,您可以使用 Cloud Run 在Google Cloud上远程移动和转码大型主机数据。这样,您就可以将大型机释放出来执行业务关键任务,同时还能减少 MIPS 消耗。
如果您想将大量数据(每天约 500 GB 或更多)从大型机迁移到 Google Cloud,但不想使用大型机来完成此任务,则可以使用支持云的虚拟磁带库 (VTL) 解决方案将数据传输到 Cloud Storage 存储分区。然后,您可以使用 Cloud Run 对存储分区中的数据进行转码,并将其移至 BigQuery。
本页介绍了如何读取复制到 Cloud Storage 存储分区中的大型机数据,将其从扩展二进制编码十进制交换码 (EBCDIC) 数据集转码为 UTF-8 中的 ORC 格式,并将数据集加载到 BigQuery 表中。
以下图表展示了如何使用 VTL 解决方案将大型主机数据移至 Cloud Storage 存储分区,使用 Cloud Run 将数据转码为 ORC 格式,然后将内容移至 BigQuery。
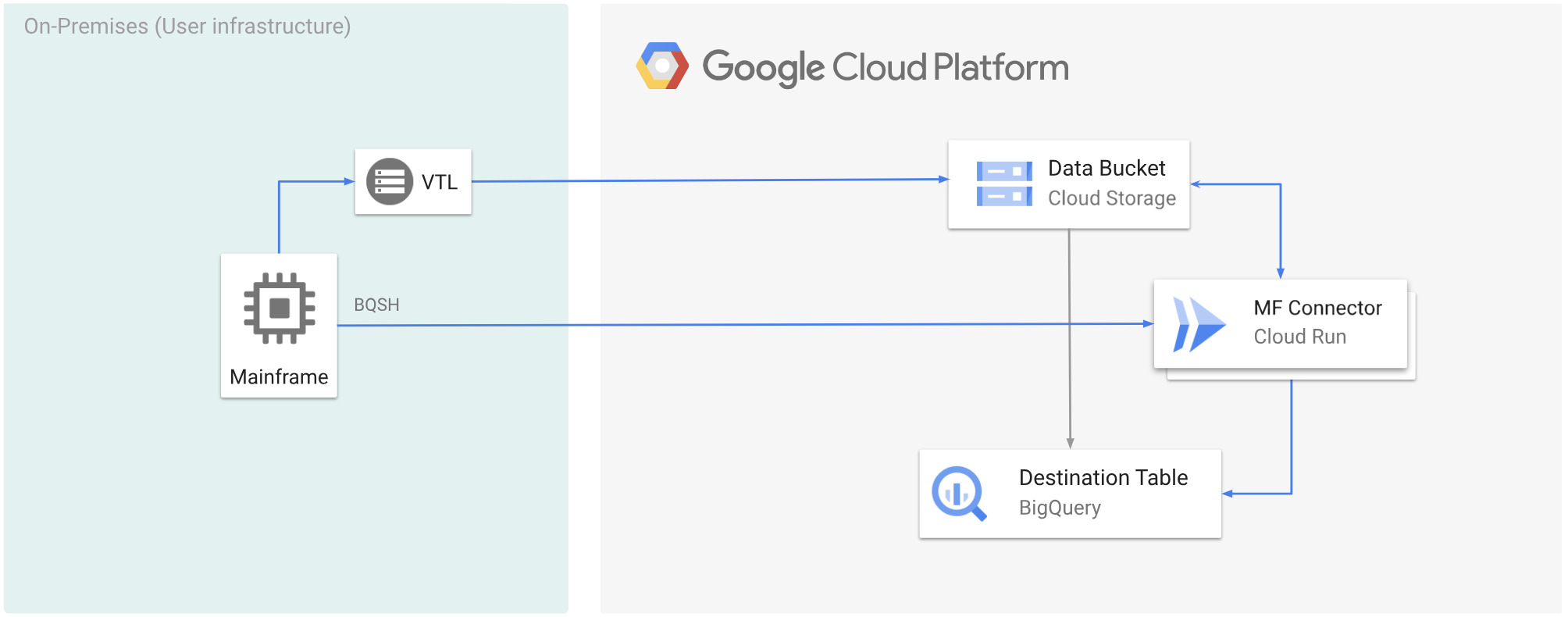
准备工作
- 选择符合您要求的 VTL 解决方案,将大型机数据移至 Cloud Storage 存储分区并将其保存为
.dat。确保向上传的.dat文件添加名为x-goog-meta-lrecl的元数据键,并且元数据键长度等于原始文件的记录长度,例如 80。 - 在 Cloud Run 上部署 Mainframe Connector。
- 在大型主机中,将
GCSDSNURI环境变量设置为您在 Cloud Storage 存储分区中为大型主机数据使用的前缀。export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET:Cloud Storage 存储分区的名称。
- PREFIX:您要在存储分区中使用的前缀。
- 创建服务账号或指定要与大型机连接器搭配使用的现有服务账号。此服务账号必须具有访问 Cloud Storage 存储分区、BigQuery 数据集以及您要使用的任何其他资源的权限。 Google Cloud
- 确保为您创建的服务账号分配了 Cloud Run Invoker 角色。
转码上传到 Cloud Storage 存储分区的大型主机数据
如需使用 VTL 将大型主机数据移至 Google Cloud 并远程进行转码,您必须执行以下任务:
- 读取 Cloud Storage 存储分区中的数据并将其转码为 ORC 格式。转码操作会将大型机 EBCDIC 数据集转换为 UTF-8 格式的 ORC 格式。
- 将数据集加载到 BigQuery 表中。
- (可选)对 BigQuery 表执行 SQL 查询。
- (可选)将数据从 BigQuery 导出到 Cloud Storage 中的二进制文件。
如需执行上述任务,请按以下步骤操作:
在大型机中,创建一个作业来从 Cloud Storage 存储分区中的
.dat文件读取数据,并将其转码为 ORC 格式,如下所示。如需查看 Mainframe 连接器支持的环境变量的完整列表,请参阅环境变量。
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*替换以下内容:
PROJECT_NAME:您要执行查询的项目的名称。INPUT_FILENAME:您上传到 Cloud Storage 存储分区的.dat文件的名称。
如果您想记录在此过程中执行的命令,可以启用加载统计信息。
(可选)创建并提交一个 BigQuery 查询作业,用于从 QUERY DD 文件执行 SQL 读取。通常,查询将是导致转换 BigQuery 表的
MERGE或SELECT INTO DML语句。请注意,Mainframe Connector 会记录作业指标,但不会将查询结果写入文件。您可以通过多种方式查询 BigQuery,包括内嵌方式、使用 DD 的单独数据集,或使用 DSN 的单独数据集。
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*替换以下内容:
PROJECT_NAME:您要执行查询的项目的名称。LOCATION:查询的执行位置。我们建议您在靠近数据的位置执行查询。
(可选)创建并提交一个导出作业,用于从 QUERY DD 文件执行 SQL 读取,并将生成的数据集作为二进制文件导出到 Cloud Storage。
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*替换以下内容:
PROJECT_NAME:您要执行查询的项目的名称。DATASET_ID:包含要导出的表的 BigQuery 数据集 ID。DESTINATION_TABLE:您要导出的 BigQuery 表。BUCKET:将包含输出二进制文件的 Cloud Storage 存储分区。