许多 Looker 客户希望帮助用户不仅能够报告数据仓库中的数据,还能够实际回写和更新该数据仓库。
Looker 通过其 Action API 支持任何数据仓库或目标平台的此类使用情形。此文档页面面向使用 Google Cloud 基础架构的客户,介绍了如何在 Cloud Run functions 函数上部署解决方案,以写回 BigQuery。本页面涵盖以下主题:
解决方案注意事项
请参考以下注意事项,验证此解决方案是否符合您的需求。
- Cloud Run functions
- 为何选择 Cloud Run functions?作为 Google 的“无服务器”产品,Cloud Run 函数在操作和维护方面非常便捷,因此是不错的选择。需要注意的一点是,延迟时间(尤其是冷调用的延迟时间)可能比依赖专用服务器的解决方案长。
- 语言和运行时:Cloud Run functions 支持多种语言和运行时。此文档页面将重点介绍 JavaScript 和 Node.js 中的示例。不过,这些概念可以直接转换为其他受支持的语言和运行时。
- BigQuery
- 为何选择 BigQuery?虽然此文档页面假设您已在使用 BigQuery,但从总体上来说,BigQuery 是数据仓库的绝佳选择。请注意以下几点:
- BigQuery Storage Write API:BigQuery 提供了多个接口来更新数据仓库中的数据,例如基于 SQL 的作业中的数据操纵语言 (DML) 语句。不过,对于大批量写入,最佳选择是 BigQuery Storage Write API。
- 附加而非更新:即使此解决方案只会附加行,而不会更新行,您也可以始终在查询时从仅附加日志中派生出“当前状态”表,从而模拟更新。
- 为何选择 BigQuery?虽然此文档页面假设您已在使用 BigQuery,但从总体上来说,BigQuery 是数据仓库的绝佳选择。请注意以下几点:
- 支持服务
- Secret Manager: Secret Manager 用于保存密文值,以确保这些值不会存储在过于容易访问的位置,例如直接存储在函数的配置中。
- Identity and Access Management (IAM): IAM 授权该函数在运行时访问必要的 Secret 并写入目标 BigQuery 表。
- Cloud Build:虽然本页不会深入讨论 Cloud Build,但 Cloud Run functions 会在后台使用它,您也可以使用 Cloud Build 自动将持续部署的更新从 Git 代码库中的源代码更改部署到函数。
- 操作和用户身份验证
- Cloud Run 服务账号:将 Looker 操作与组织自己的第一方资产和资源集成的主要方法也是最简单的方法是,使用 Looker Action API 的基于令牌的身份验证机制,将请求验证为来自 Looker 实例,然后使用服务账号授权该函数更新 BigQuery 中的数据。
- OAuth:另一种选择(本页未介绍)是使用 Looker Action API 的 OAuth 功能。这种方法较为复杂,通常不需要,但如果您需要使用 IAM 定义最终用户对表的写入权限,而不是使用他们在 Looker 中的访问权限或函数代码中的临时逻辑,则可以使用这种方法。
演示代码演示
我们有一个包含演示操作的完整逻辑的单个文件可在 GitHub 上获取。在本部分中,我们将详细介绍代码的关键元素。
设置代码
第一部分包含一些演示常量,用于标识操作将写入的表。在本页后面的部署指南部分中,您将需要将项目 ID 替换为您自己的项目 ID,这是对代码唯一必要的修改。
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
下一部分声明并初始化了您的操作将使用的一些代码依赖项。我们提供了一个使用 Secret Manager Node.js 模块“在代码中”访问 Secret Manager 的示例;不过,您也可以使用 Cloud Run 函数的内置功能在初始化期间为您检索密文,从而消除此代码依赖项。
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
请注意,引用的 @google-cloud 依赖项也在我们的 package.json 文件中声明,以便预加载依赖项并使其可供我们的 Node.js 运行时使用。crypto 是一个内置 Node.js 模块,未在 package.json 中声明。
HTTP 请求处理和路由
代码向 Cloud Run 函数运行时公开的主要接口是一个导出的 JavaScript 函数,该函数遵循 Node.js Express Web 服务器惯例。具体来说,您的函数会收到两个实参:第一个实参表示 HTTP 请求,您可以从中读取各种请求参数和值;第二个实参表示响应对象,您可以在其中发出响应数据。虽然您可以为函数指定任意名称,但稍后您必须将该名称提供给 Cloud Run functions,如部署指南部分中所述。
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
httpHandler 函数的第一部分声明了我们的操作将识别的各种路由,这些路由与单个操作所需的 Action API 端点非常相似,并且声明了稍后将在文件中定义的处理每个路由的函数。
虽然某些操作 + Cloud Run functions 示例会为每个此类路由部署单独的函数,以与 Cloud Run functions 的默认路由保持一对一的对应关系,但函数能够在代码中应用额外的“子路由”,如本示例所示。这最终取决于个人偏好,但在代码中执行此额外路由可最大限度地减少我们需要部署的函数数量,并有助于我们在所有操作端点中保持单一连贯的代码状态。
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
HTTP 处理程序函数的其余部分实现了针对上述路由声明的 HTTP 请求处理,并将这些处理程序的返回值连接到响应对象。
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
在处理完 HTTP 处理程序和路由声明后,我们将深入探讨必须实现的三个主要操作端点:
操作列表端点
当 Looker 管理员首次将 Looker 实例连接到 Action 服务器时,Looker 会调用所提供的网址(称为“操作列表端点”),以获取有关可通过该服务器执行的操作的信息。
在之前展示的路由声明中,我们使此端点在函数网址的根路径 (/) 下可用,并指明它将由 hubListing 函数处理。
从以下函数定义中可以看出,它根本没有太多“代码” - 它每次都只返回相同的 JSON 数据。需要注意的一点是,它确实会动态地将“自己的”网址纳入某些字段中,从而使 Looker 实例能够将后续请求发送回同一函数。
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
出于演示目的,我们的代码不需要进行身份验证即可检索此商家信息。不过,如果您认为操作元数据属于敏感信息,也可以要求对此路由进行身份验证,如下一部分所示。
另请注意,我们的 Cloud Run 函数可以公开和处理多项操作,这说明了我们的 /action-X/... 路由惯例。不过,我们的演示 Cloud Run 函数将仅实现一项操作。
操作表单端点
虽然并非所有使用情形都需要表单,但表单非常适合数据库回写的使用情形,因为用户可以在 Looker 中检查数据,然后提供要插入到数据库中的值。由于我们的操作列表提供了 form_url 参数,因此当用户开始与您的操作互动时,Looker 将调用此 Action Form 端点,以确定要从用户那里捕获哪些额外数据。
在路由声明中,我们将此端点设为可通过 /action-0/form 路径访问,并为其关联了两个处理程序:requireInstanceAuth 和 action0Form。
我们设置了路由声明,以允许使用多个处理程序(如上所示),因为某些逻辑可以重复用于多个端点。
例如,我们可以看到 requireInstanceAuth 用于多条路线。无论何时,只要我们想要求请求必须来自我们的 Looker 实例,就会使用此处理程序。处理程序从 Secret Manager 中检索预期令牌值,并拒绝任何不具有该预期令牌值的请求。
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
请注意,我们使用的是 timingSafeEqual 实现,而不是标准等值检查 (==),以防止泄露旁道时间信息,从而让攻击者快速找出我们密钥的值。
假设请求通过了实例身份验证检查,然后由 action0Form 处理程序处理该请求。
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
虽然我们的演示示例非常静态,但在某些使用情形下,表单代码可以更具互动性。例如,根据用户在初始下拉菜单中的选择,可以显示不同的字段。
操作执行端点
操作执行端点是任何操作的大部分逻辑所在的位置,我们将在其中深入了解特定于 BigQuery 插入用例的逻辑。
在我们的路由声明中,我们使此端点在 /action-0/execute 路径下可用,并将其与三个处理程序相关联:requireInstanceAuth、processRequestBody 和 action0Execute。
我们已经介绍了 requireInstanceAuth,而 processRequestBody 处理程序主要提供一些不太重要的预处理,以将 Looker 请求正文中的某些不方便的字段转换为更方便的格式,但您可以在完整代码文件中参考它。
action0Execute 函数首先展示了从操作请求的多个部分提取有用信息的示例。在实践中,请注意,我们的代码中称为 formParams 和 actionParams 的请求元素可以包含不同的字段,具体取决于您在 Listing 和 Form 端点中声明的内容。
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
然后,代码会转换为一些标准 BigQuery 代码,以实际插入数据。请注意,BigQuery Storage Write API 还提供其他更复杂的变体,更适合用于持久的流式传输连接或批量插入多条记录;不过,对于在 Cloud Run 函数的上下文中响应单个用户互动,这是最直接的变体。
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
演示代码还包含一个用于问题排查的“状态”端点,但此端点不是 Action API 集成所必需的。
部署指南
最后,我们将提供一个分步指南,帮助您自行部署演示,其中涵盖前提条件、Cloud Run 函数部署、BigQuery 配置和 Looker 配置。
项目和服务前提条件
在开始配置任何具体内容之前,请查看此列表,了解解决方案需要哪些服务和政策:
- 新项目:您需要一个新项目来存放示例中的资源。
- 服务:首次在 Cloud 控制台界面中使用 BigQuery 和 Cloud Run functions 时,系统会提示您为所需服务启用必需的 API,包括 BigQuery、Artifact Registry、Cloud Build、Cloud Functions、Cloud Logging、Pub/Sub、Cloud Run Admin 和 Secret Manager。
- 未经身份验证的调用的政策:此使用情形要求我们部署“允许公开访问”的 Cloud Run 函数,因为我们将根据 Action API 在代码中处理传入请求的身份验证,而不是使用 IAM。虽然默认情况下允许这样做,但组织政策通常会限制这种用法。具体来说,
constraints/iam.allowedPolicyMemberDomains政策会限制可以向哪些人授予 IAM 权限,您可能需要调整该政策,以允许allUsers主账号进行未经身份验证的访问。如果您发现自己无法允许公开访问,请参阅本指南如何在实施网域限定共享时创建公共 Cloud Run 服务,了解详情。 - 其他政策:请注意,其他Google Cloud 组织政策限制条件也可能会阻止部署默认情况下允许的服务。
部署 Cloud Run 函数
创建新项目后,请按以下步骤部署 Cloud Run 函数
- 在 Cloud Run 函数中,点击创建函数。
- 为函数选择任意名称(例如“demo-bq-insert-action”)。
- 在触发器设置下:
- 触发器类型应已为“HTTPS”。
- 将身份验证设置为允许未通过身份验证的调用。
- 将 网址 值复制到剪贴板。
- 在运行时 > 运行时环境变量设置下:
- 点击添加变量。
- 将变量名称设置为
CALLBACK_URL_PREFIX。 - 粘贴上一步中的网址作为值。
- 点击下一步。
- 点击
package.json文件,然后粘贴内容。 - 点击
index.js文件,然后粘贴内容。 - 将文件顶部的
projectId变量分配给您自己的项目 ID。 - 将入口点设置为
httpHandler。 - 点击部署。
- 向 build 服务账号授予所请求的权限(如有)。
- 等待部署完成。
- 如果在后续任何步骤中,您收到一条错误消息,指示您查看 Google Cloud 日志,请注意,您可以在此页面上的日志标签页中访问此函数的日志。
- 在离开 Cloud Run 函数的页面之前,请在详情标签页下找到并记下该函数所拥有的服务账号。我们将在后续步骤中使用此变量,以确保该函数具有所需的权限。
- 在浏览器中访问该网址,直接测试函数部署。您应该会看到包含您的集成信息的 JSON 响应。
- 如果您收到 403 错误,则可能是由于组织政策,您尝试设置允许未经身份验证的调用的操作已悄然失败。检查您的函数是否允许未经身份验证的调用,查看组织政策设置,然后尝试更新该设置。
对 BigQuery 目标表的访问权限
实际上,要插入的目标表可以位于不同的 Google Cloud 项目中;但出于演示目的,我们将在同一项目中创建一个新的目标表。无论哪种情况,您都需要确保 Cloud Run 函数的服务账号有权写入该表。
- 前往 BigQuery 控制台。
创建演示表:
- 在“探索器”栏中,使用项目旁边的省略号菜单,然后选择创建数据集。
- 为数据集指定 ID
demo_dataset,然后点击创建数据集。 - 使用新创建的数据集上的省略号菜单,然后选择创建表。
- 为表格命名为
demo_table。 在架构下,选择以文本形式修改,使用以下架构,然后点击创建表。
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
分配权限:
- 在探索器栏中,点击您的数据集。
- 在数据集页面上,依次点击共享 > 权限。
- 点击添加主账号。
- 将新主账号设置为您函数的服务账号(本页上文已提及)。
- 分配 BigQuery Data Editor 角色。
- 点击保存。
正在连接到 Looker
现在,您的函数已部署,接下来我们将把 Looker 连接到该函数。
- 我们需要一个共享密钥,以便您的操作验证请求是否来自您的 Looker 实例。生成一个长的随机字符串,并妥善保管。我们将在后续步骤中将其用作 Looker Secret 值。
- 在 Cloud 控制台中,前往 Secret Manager。
- 点击创建 Secret。
- 将名称设置为
LOOKER_SECRET。(此名称已在此演示的代码中硬编码,但您在处理自己的代码时可以有效选择任何名称。) - 将密钥值设置为您生成的密钥值。
- 点击创建 Secret。
- 在密钥页面上,点击权限标签页。
- 点击授予访问权限。
- 将新的主账号设置为您之前记下的函数的服务账号。
- 分配 Secret Manager Secret Accessor 角色。
- 点击保存。
- 您可以访问附加到函数网址的
/status路由,确认函数是否成功访问了 Secret。
- 在 Looker 实例中:
- 依次前往“管理”>“平台”>“操作”。
- 前往页面底部,点击添加行动中心。
- 提供函数的网址(例如 https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action),然后点击 Add Action Hub 进行确认。
- 您现在应该会看到一个新的 Action Hub 条目,其中包含一个名为 Demo BigQuery Insert 的操作。
- 在“操作中心”条目中,点击配置授权。
- 将生成的 Looker Secret 输入到 Authorization Token 字段中,然后点击 Update Token。
- 在 Demo BigQuery Insert 操作上,点击启用。
- 将已启用开关切换为开启。
- 系统应会自动运行操作测试,以确认您的函数正在接受 Looker 的请求并正确响应表单端点。
- 点击保存。
端到端测试
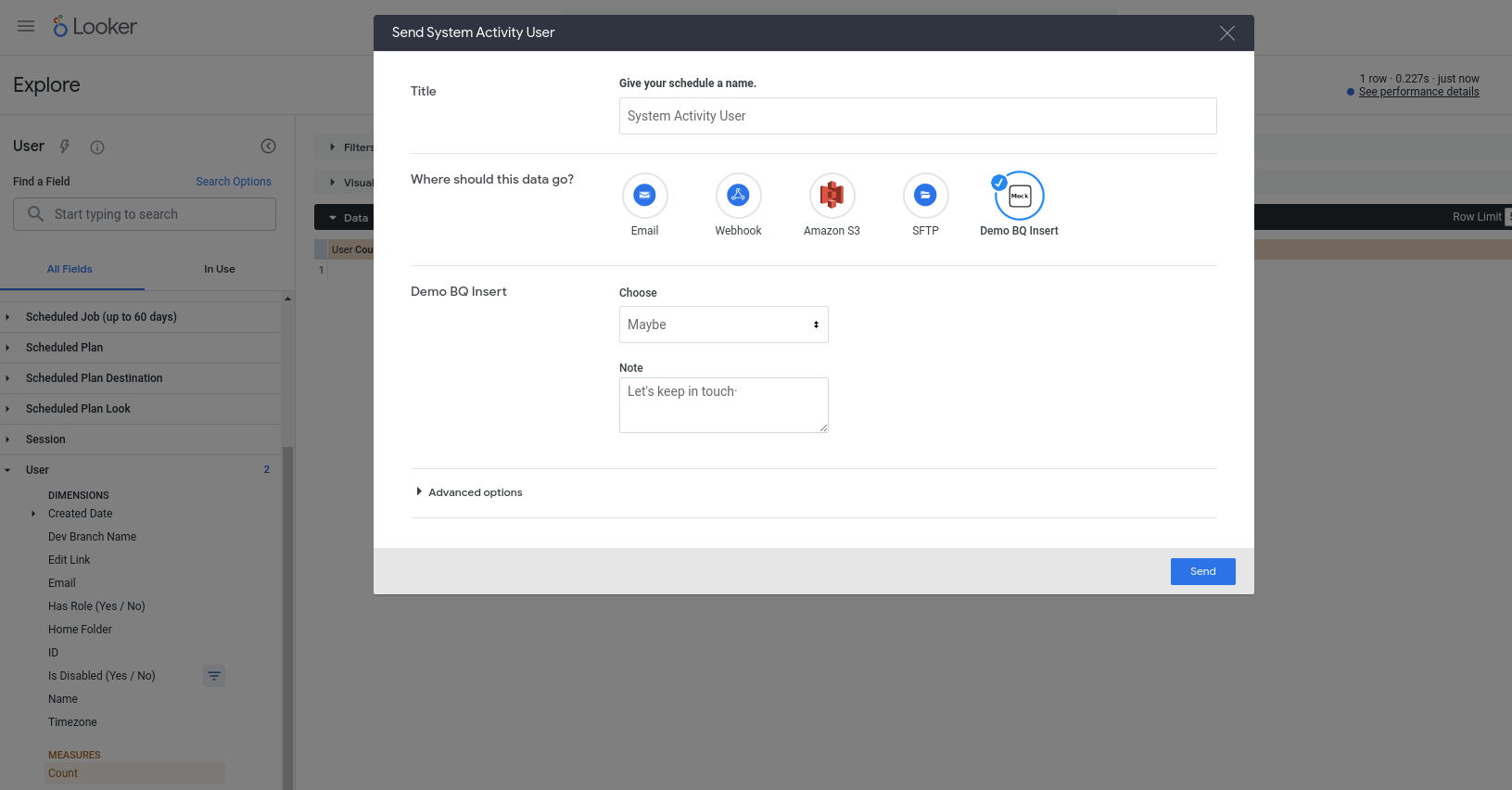
现在,我们应该能够实际使用新操作了。此操作配置为可处理任何查询,因此请选择任意探索(例如内置的“系统活动”探索),向新查询添加一些字段,运行该查询,然后从齿轮菜单中选择发送。您应该会看到该操作是可用的目的地之一,并且系统会提示您输入一些字段:
按 Send 后,您应该会在 BigQuery 表中看到插入的新行(并且 Looker 用户账号的电子邮件地址已在 invoked_by 列中标识出来)!