Muitos clientes do Looker querem permitir que os respetivos utilizadores vão além da criação de relatórios sobre os dados no respetivo data warehouse para, na verdade, escreverem e atualizarem esse data warehouse.
Através da respetiva API Action, o Looker suporta este exemplo de utilização para qualquer data warehouse ou destino. Esta página de documentação explica aos clientes que usam Google Cloud infraestrutura como implementar uma solução em funções do Cloud Run para escrever novamente no BigQuery. Esta página aborda os seguintes tópicos:
Considerações sobre a solução
Use esta lista de considerações para validar se esta solução se alinha com as suas necessidades.
- Funções do Cloud Run
- Porquê as funções do Cloud Run? Como oferta "sem servidor" da Google, o Cloud Run Functions é uma excelente escolha para facilitar as operações e a manutenção. Uma consideração a ter em conta é que a latência, particularmente para invocações a frio, pode ser mais longa do que com uma solução que dependa de um servidor dedicado.
- Idioma e tempo de execução As funções do Cloud Run suportam vários idiomas e tempos de execução. Esta página de documentação vai focar-se num exemplo em JavaScript e Node.js. No entanto, os conceitos são diretamente traduzíveis para os outros idiomas e tempos de execução suportados.
- BigQuery
- Porquê o BigQuery? Embora esta página de documentação parta do princípio de que já está a usar o BigQuery, o BigQuery é uma excelente escolha para um armazém de dados em geral. Tenha em atenção as seguintes considerações:
- API BigQuery Storage Write: o BigQuery oferece várias interfaces para atualizar dados no seu armazém de dados, incluindo, por exemplo, declarações de linguagem de manipulação de dados (DML) em tarefas baseadas em SQL. No entanto, a melhor opção para gravações de grande volume é a API Storage Write do BigQuery.
- Anexar em vez de atualizar: embora esta solução apenas anexe linhas e não as atualize, pode sempre derivar tabelas de "estado atual" no momento da consulta a partir de um registo apenas de anexação, simulando assim as atualizações.
- Porquê o BigQuery? Embora esta página de documentação parta do princípio de que já está a usar o BigQuery, o BigQuery é uma excelente escolha para um armazém de dados em geral. Tenha em atenção as seguintes considerações:
- Serviços de apoio técnico
- Secret Manager: o Secret Manager contém valores secretos para garantir que não são armazenados em locais demasiado acessíveis, como diretamente na configuração da função.
- Identity and Access Management (IAM): o IAM autoriza a função a aceder ao segredo necessário no tempo de execução e a escrever na tabela do BigQuery pretendida.
- Cloud Build: embora o Cloud Build não seja abordado em detalhe nesta página, as funções do Cloud Run usam-no em segundo plano, e pode usar o Cloud Build para automatizar atualizações implementadas continuamente nas suas funções a partir de alterações ao seu código-fonte num repositório Git.
- Ação e autenticação do utilizador
- Conta de serviço do Cloud Run A forma principal e mais fácil de usar ações do Looker para integração com os recursos e os ativos originais da sua organização é autenticar os pedidos como provenientes da sua instância do Looker através do mecanismo de autenticação baseado em tokens da API Looker Action e, em seguida, autorizar a função a atualizar dados no BigQuery através de uma conta de serviço.
- OAuth: outra opção, não abordada nesta página, seria usar a funcionalidade OAuth da API Looker Action. Esta abordagem é mais complexa e, geralmente, não é necessária, mas pode ser usada se precisar de definir o acesso dos utilizadores finais para escrever na tabela através do IAM, em vez de usar o respetivo acesso no Looker ou na lógica ad hoc no código da função.
Instruções passo a passo do código de demonstração
Temos um único ficheiro que contém toda a lógica da nossa ação de demonstração disponível no GitHub. Nesta secção, vamos analisar os elementos-chave do código.
Código de configuração
A primeira secção tem algumas constantes de demonstração que identificam a tabela na qual a ação vai escrever. Na secção Guia de implementação mais adiante nesta página, vai receber instruções para substituir o ID do projeto pelo seu, o que será a única modificação necessária ao código.
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
A secção seguinte declara e inicializa algumas dependências de código que a sua ação vai usar. Fornecemos um exemplo que acede ao Secret Manager "no código" através do módulo Node.js do Secret Manager. No entanto, também pode eliminar esta dependência de código usando a funcionalidade incorporada das funções do Cloud Run para obter um segredo para si durante a inicialização.
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
Tenha em atenção que as dependências @google-cloud referenciadas também são declaradas no nosso ficheiro package.json para permitir que as dependências sejam pré-carregadas e estejam disponíveis para o nosso tempo de execução do Node.js. crypto é um módulo Node.js incorporado e não está declarado em package.json.
Processamento e encaminhamento de pedidos HTTP
A interface principal que o seu código expõe ao tempo de execução das funções do Cloud Run é uma função JavaScript exportada que segue as convenções do servidor Web Node.js Express. Em particular, a sua função recebe dois argumentos: o primeiro representa o pedido HTTP, a partir do qual pode ler vários parâmetros e valores do pedido; e o segundo representa um objeto de resposta, ao qual envia os seus dados de resposta. Embora o nome da função possa ser o que quiser, tem de fornecer o nome às funções do Cloud Run mais tarde, conforme detalhado na secção Guia de implementação.
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
A primeira secção da função httpHandler declara as várias rotas que a nossa ação vai reconhecer, espelhando de perto os pontos finais necessários da API Actions para uma única ação, e as funções que vão processar cada rota, definidas mais tarde no ficheiro.
Embora alguns exemplos de funções do Cloud Run + ações implementem uma função separada para cada rota desse tipo, de modo a alinhar-se individualmente com a predefinição de encaminhamento das funções do Cloud Run, as funções são capazes de aplicar "subencaminhamento" adicional no respetivo código, conforme demonstrado aqui. Em última análise, isto é uma questão de preferência, mas fazer este encaminhamento adicional no código minimiza o número de funções que temos de implementar e ajuda-nos a manter um único estado de código coerente em todos os pontos finais das ações.
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
O resto da função do controlador HTTP implementa o processamento do pedido HTTP em relação às declarações de rotas anteriores e associa os valores de retorno desses controladores ao objeto de resposta.
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
Com o controlador HTTP e as declarações de rotas resolvidos, vamos analisar os três principais pontos finais de ações que temos de implementar:
Ponto final da lista de ações
Quando um administrador do Looker associa pela primeira vez uma instância do Looker a um servidor de ações, o Looker chama o URL fornecido, denominado "ponto final da lista de ações", para obter informações sobre as ações disponíveis através do servidor.
Nas declarações de rotas que mostrámos anteriormente, disponibilizámos este ponto final no caminho raiz (/) no URL da nossa função e indicámos que seria processado pela função hubListing.
Como pode ver na definição da função seguinte, não existe muito "código" – apenas devolve os mesmos dados JSON sempre. Tenha em atenção que inclui dinamicamente o seu "próprio" URL em alguns dos campos, o que permite à instância do Looker enviar pedidos posteriores de volta para a mesma função.
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
Para fins de demonstração, o nosso código não exigiu autenticação para obter esta ficha. No entanto, se considerar que os metadados de ações são confidenciais, também pode exigir autenticação para esta rota, conforme mostrado na secção seguinte.
Tenha também em atenção que a nossa função do Cloud Run pode expor e processar várias ações, o que explica a nossa convenção de rotas de /action-X/.... No entanto, a nossa função de demonstração do Cloud Run implementa apenas uma ação.
Ponto final do formulário de ação
Embora nem todos os exemplos de utilização exijam um formulário, ter um enquadra-se bem no exemplo de utilização de gravações na base de dados, uma vez que os utilizadores podem inspecionar os dados no Looker e, em seguida, fornecer valores a inserir na base de dados. Uma vez que a nossa lista de ações forneceu um parâmetro form_url, o Looker invoca este ponto final do formulário de ação quando um utilizador começa a interagir com a sua ação, para determinar que dados adicionais captar do utilizador.
Nas nossas declarações de rotas, disponibilizámos este ponto final no caminho /action-0/form e associámos-lhe dois processadores: requireInstanceAuth e action0Form.
Configuramos as nossas declarações de rotas para permitir vários processadores desta forma porque alguma lógica pode ser reutilizada para vários pontos finais.
Por exemplo, podemos ver que o requireInstanceAuth é usado para vários trajetos. Usamos este controlador sempre que queremos exigir que um pedido tenha de ter origem na nossa instância do Looker. O controlador obtém o valor do token secreto esperado do Secret Manager e rejeita todos os pedidos que não tenham esse valor do token esperado.
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
Tenha em atenção que usamos uma implementação timingSafeEqual, em vez da verificação de igualdade padrão (==), para evitar a fuga de informações de tempo do canal lateral que permitiriam a um atacante descobrir rapidamente o valor do nosso segredo.
Partindo do princípio de que um pedido passa na verificação de autenticação da instância, o pedido é então processado pelo controlador action0Form.
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
Embora o nosso exemplo de demonstração seja muito estático, o código do formulário pode ser mais interativo para determinados exemplos de utilização. Por exemplo, consoante a seleção de um utilizador num menu pendente inicial, podem ser apresentados campos diferentes.
Ponto final de execução de ações
O ponto final Action Execute é onde reside a maior parte da lógica de qualquer ação e onde vamos abordar a lógica específica do exemplo de utilização de inserção do BigQuery.
Nas nossas declarações de rotas, disponibilizámos este ponto final no caminho /action-0/execute e associámos-lhe três processadores: requireInstanceAuth, processRequestBody e action0Execute.
Já abordámos o requireInstanceAuth, e o controlador processRequestBody fornece um pré-processamento maioritariamente desinteressante para transformar determinados campos inconvenientes no corpo do pedido do Looker num formato mais conveniente, mas pode consultá-lo no ficheiro de código completo.
A função action0Execute começa por mostrar exemplos de extração de informações de várias partes do pedido de ação que podem ser úteis. Na prática, tenha em atenção que os elementos de pedido a que o nosso código se refere como formParams e actionParams podem conter campos diferentes, consoante o que declarar nos seus pontos finais de fichas e formulários.
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
Em seguida, o código passa para algum código padrão do BigQuery para inserir realmente os dados. Tenha em atenção que as APIs BigQuery Storage Write oferecem outras variações mais complexas mais adequadas para uma ligação de streaming persistente ou inserções em massa de muitos registos. No entanto, para responder a interações individuais dos utilizadores no contexto de uma função do Cloud Run, esta é a variação mais direta.
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
O código de demonstração também inclui um ponto final "status" para fins de resolução de problemas, mas este ponto final não é necessário para a integração da API Actions.
Guia de implementação
Por último, vamos fornecer um guia passo a passo para implementar a demonstração, que abrange os pré-requisitos, a implementação da função do Cloud Run, a configuração do BigQuery e a configuração do Looker.
Pré-requisitos do projeto e do serviço
Antes de começar a configurar detalhes específicos, reveja esta lista para compreender os serviços e as políticas de que a solução vai precisar:
- Um novo projeto: precisa de um novo projeto para alojar os recursos do nosso exemplo.
- Serviços: quando usar as funções do BigQuery e do Cloud Run pela primeira vez na IU da Cloud Console, é-lhe pedido que ative as APIs necessárias para os serviços necessários, incluindo o BigQuery, o Artifact Registry, o Cloud Build, o Cloud Functions, o Cloud Logging, o Pub/Sub, o Cloud Run Admin e o Secret Manager.
- Política para invocações não autenticadas: este exemplo de utilização requer que implementemos funções do Cloud Run que "permitam invocações não autenticadas", uma vez que vamos processar a autenticação de pedidos recebidos no nosso código de acordo com a API Actions, em vez de usar o IAM. Embora esta opção seja permitida por predefinição, a política organizacional restringe frequentemente esta utilização. Em concreto, a política
constraints/iam.allowedPolicyMemberDomainsrestringe a quem podem ser concedidas autorizações de IAM e pode ter de a ajustar para permitir o principalallUserspara acesso não autenticado. Consulte este guia, Como criar serviços públicos do Cloud Run quando a partilha restrita por domínio é aplicada, para mais informações se não conseguir permitir invocações não autenticadas. - Outras políticas: tenha em atenção que outras Google Cloud restrições de políticas organizacionais também podem impedir a implementação de serviços que, de outra forma, são permitidos por predefinição.
Implementar a função do Cloud Run
Depois de criar um novo projeto, siga estes passos para implementar a função do Cloud Run
- Em Funções do Cloud Run, clique em Criar função.
- Escolha qualquer nome para a sua função (por exemplo, "demo-bq-insert-action").
- Em Definições do acionador:
- O tipo de acionador já deve ser "HTTPS".
- Defina a Autenticação como Permitir invocações não autenticadas.
- Copie o valor do URL para a área de transferência.
- Nas definições de Tempo de execução > Variáveis de ambiente de tempo de execução:
- Clique em Adicionar variável.
- Defina o nome da variável como
CALLBACK_URL_PREFIX. - Cole o URL do passo anterior como valor.
- Clicar em Seguinte.
- Clique no ficheiro
package.jsone cole o conteúdo. - Clique no ficheiro
index.jse cole o conteúdo. - Atribua a variável
projectIdna parte superior do ficheiro ao seu próprio ID do projeto. - Defina o Entry Point como
httpHandler. - Clique em Implementar.
- Conceda as autorizações pedidas (se existirem) à conta de serviço de compilação.
- Aguarde a conclusão da implementação.
- Se, em passos futuros, receber um erro que lhe indique que reveja os Google Cloud registos, tenha em atenção que pode aceder aos registos desta função a partir do separador Registos nesta página.
- Antes de sair da página da função do Cloud Run, no separador Detalhes, localize e tome nota da conta de serviço que a função tem. Vamos usar isto nos passos posteriores para garantir que a função tem as autorizações de que precisa.
- Teste a implementação da função diretamente no navegador visitando o URL. Deve ver uma resposta JSON com a ficha da sua integração.
- Se receber um erro 403, a sua tentativa de definir Permitir invocações não autenticadas pode ter falhado silenciosamente como resultado de uma política da organização. Verifique se a sua função está a permitir invocações não autenticadas, reveja a definição da política da organização e tente atualizar a definição.
Acesso à tabela de destino do BigQuery
Na prática, a tabela de destino a inserir pode residir num Google Cloud projeto diferente, mas, para fins de demonstração, vamos criar uma nova tabela de destino no mesmo projeto. Em qualquer dos casos, tem de garantir que a conta de serviço da função do Cloud Run tem autorizações para escrever na tabela.
- Navegue para a consola do BigQuery.
Crie a tabela de demonstração:
- Na barra do explorador, use o menu de reticências junto ao seu projeto e selecione Create dataset (Criar conjunto de dados).
- Atribua ao conjunto de dados o ID
demo_datasete clique em Criar conjunto de dados. - Use o menu de reticências no conjunto de dados recém-criado e selecione Criar tabela.
- Atribua o nome
demo_tableà tabela. Em Esquema, selecione Editar como texto, use o seguinte esquema e, de seguida, clique em Criar tabela.
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
Atribua autorizações:
- Na barra do Explorador, clique no conjunto de dados.
- Na página do conjunto de dados, clique em Partilha > Autorizações.
- Clique em Adicionar diretor.
- Defina o Novo principal como a conta de serviço da sua função, referida anteriormente nesta página.
- Atribua a função de editor de dados do BigQuery.
- Clique em Guardar.
A estabelecer ligação ao Looker
Agora que a sua função está implementada, vamos associar o Looker à mesma.
- Precisamos de um segredo partilhado para que a sua ação autentique que os pedidos estão a ser enviados a partir da sua instância do Looker. Gere uma string aleatória longa e mantenha-a segura. Vamos usá-lo nos passos seguintes como o valor do segredo do Looker.
- Na Cloud Console, navegue para Secret Manager.
- Clique em Criar segredo.
- Defina o Nome como
LOOKER_SECRET. (Isto está codificado no código desta demonstração, mas pode escolher efetivamente qualquer nome quando trabalhar com o seu próprio código.) - Defina o valor secreto para o valor secreto que gerou.
- Clique em Criar segredo.
- Na página Segredo, clique no separador Autorizações.
- Clique em Conceder acesso.
- Defina Novos membros como a conta de serviço da sua função, indicada anteriormente.
- Atribua a função Secret Manager Secret Accessor.
- Clique em Guardar.
- Pode confirmar que a sua função está a aceder com êxito ao segredo visitando a rota
/statusanexada ao URL da função.
- Na sua instância do Looker:
- Navegue para Administração > Plataforma > Ações.
- Aceda à parte inferior da página para clicar em Adicionar centro de ações.
- Indique o URL da sua função (por exemplo, https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action) e confirme clicando em Adicionar centro de ações.
- Agora, deve ver uma nova entrada do Action Hub com uma ação denominada Demo BigQuery Insert.
- Na entrada do centro de ações, clique em Configurar autorização.
- Introduza o seu segredo do Looker gerado no campo Token de autorização e clique em Atualizar token.
- Na ação Inserção de demonstração do BigQuery, clique em Ativar.
- Ative o switch Ativado.
- Deve ser executado automaticamente um teste da ação, confirmando que a sua função está a aceitar o pedido do Looker e a responder corretamente ao ponto final do formulário.
- Clique em Guardar.
Teste ponto a ponto
Agora, devemos poder usar a nossa nova ação. Esta ação está configurada para funcionar com qualquer consulta. Por isso, escolha qualquer exploração (por exemplo, uma exploração de atividade do sistema incorporada), adicione alguns campos a uma nova consulta, execute-a e, em seguida, escolha Enviar no menu de engrenagem. Deve ver a ação como um dos destinos disponíveis e ser-lhe pedido que introduza alguns campos:
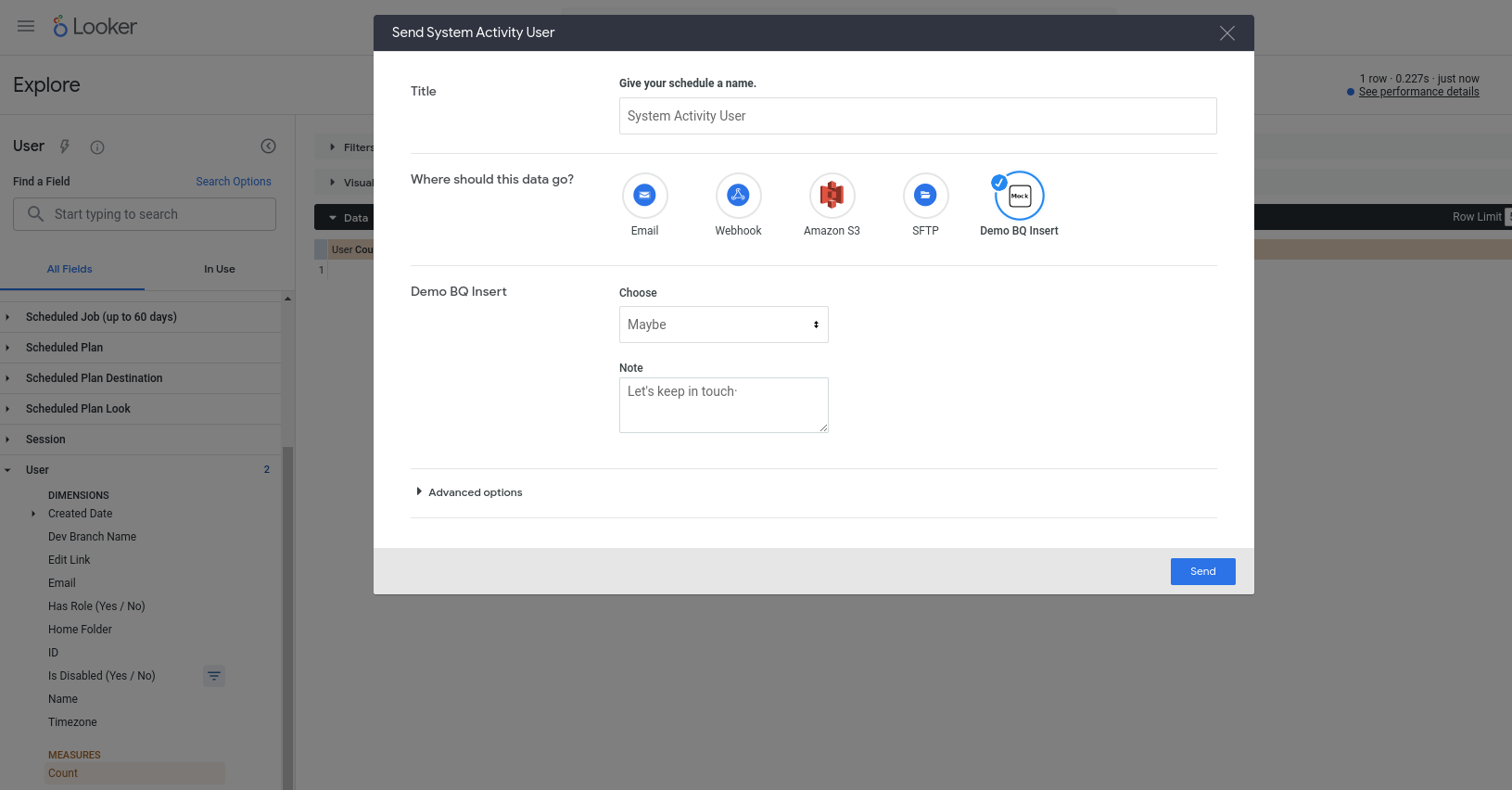
Depois de premir Enviar, deve ter uma nova linha inserida na tabela do BigQuery (e o email da sua conta de utilizador do Looker identificado na coluna invoked_by)!