Neste tutorial, mostramos como disponibilizar modelos de linguagem grandes (LLMs) usando Unidades de Processamento de Tensor (TPUs) no Google Kubernetes Engine (GKE) com o framework de disponibilização vLLM. Neste tutorial, você vai disponibilizar o Llama 3.1 70b, usar TPU Trillium e configurar o escalonamento automático horizontal de pods usando métricas do servidor vLLM.
Este documento é um bom ponto de partida se você precisar do controle granular, da escalonabilidade, da resiliência, da portabilidade e da economia do Kubernetes gerenciado ao implantar e disponibilizar suas cargas de trabalho de IA/ML.
Contexto
Ao usar a TPU Trillium no GKE, é possível implementar uma solução de veiculação robusta e pronta para produção com todos os benefícios do Kubernetes gerenciado, incluindo escalonabilidade eficiente e maior disponibilidade. Esta seção descreve as principais tecnologias usadas neste guia.
TPU Trillium
TPUs são circuitos integrados de aplicação específica (ASICs) desenvolvidos especialmente pelo Google. As TPUs são usadas para acelerar modelos de machine learning e de IA criados com o uso de frameworks como TensorFlow, PyTorch e JAX. Este tutorial usa a TPU Trillium, que é a TPU de sexta geração do Google.
Antes de usar TPUs no GKE, recomendamos que você conclua o seguinte programa de aprendizado:
- Saiba mais sobre a arquitetura do sistema da TPU Trillium.
- Saiba mais sobre TPUs no GKE.
vLLM
O vLLM é um framework de código aberto altamente otimizado para veiculação de LLMs. Ele pode aumentar a capacidade de veiculação em TPUs, com recursos como:
- Otimização da implementação do transformador com PagedAttention.
- Lotes contínuos para melhorar a capacidade geral de exibição.
- Paralelismo de tensor e exibição distribuída em várias TPUs.
Para saber mais, consulte a documentação do vLLM.
Cloud Storage FUSE
O Cloud Storage FUSE fornece acesso do seu cluster do GKE ao Cloud Storage para pesos de modelo que residem em buckets de armazenamento de objetos. Neste tutorial, o bucket do Cloud Storage criado vai estar vazio inicialmente. Quando o vLLM é iniciado, o GKE faz o download do modelo do Hugging Face e armazena os pesos em cache no bucket do Cloud Storage. Na reinicialização do pod ou no aumento da escala de implantação, os carregamentos de modelo subsequentes vão baixar dados armazenados em cache do bucket do Cloud Storage, aproveitando downloads paralelos para um desempenho ideal.
Para saber mais, consulte a documentação do driver CSI do Cloud Storage FUSE.
Criar um cluster do GKE
É possível disponibilizar os LLMs em TPUs em um cluster do GKE Autopilot ou Standard. Recomendamos que você use um cluster do Autopilot para ter uma experiência totalmente gerenciada do Kubernetes. Para escolher o modo de operação do GKE mais adequado para suas cargas de trabalho, consulte Escolher um modo de operação do GKE.
Piloto automático
Crie um cluster do GKE Autopilot:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Padrão
Crie um cluster do GKE Standard:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverCrie um pool de nós de fração da TPU:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2O GKE cria os seguintes recursos para o LLM:
- Um cluster do GKE Standard que usa a federação de identidade da carga de trabalho para o GKE e tem o driver CSI do Cloud Storage FUSE ativado.
- Um pool de nós da TPU Trillium com um tipo de máquina
ct6e-standard-8t. Esse pool de nós tem um nó, oito chips de TPU e o escalonamento automático ativado.
Configure o kubectl para se comunicar com o cluster
Para configurar o kubectl para se comunicar com o cluster, execute o comando a seguir:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Criar um Secret do Kubernetes para as credenciais do Hugging Face
Crie um namespace Pule esta etapa se estiver usando o namespace
default:kubectl create namespace ${NAMESPACE}Crie um secret do Kubernetes que contenha o token do Hugging Face e execute o seguinte comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Criar um bucket do Cloud Storage
No Cloud Shell, execute este comando:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
Isso cria um bucket do Cloud Storage para armazenar os arquivos de modelo transferidos por download do Hugging Face.
Configurar uma conta de serviço do Kubernetes para acessar o bucket
Crie a conta de serviço do Kubernetes:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Conceda acesso de leitura/gravação à ServiceAccount do Kubernetes para acessar o bucket do Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Como alternativa, conceda acesso de leitura e gravação a todos os buckets do Cloud Storage no projeto:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"O GKE cria os seguintes recursos para o LLM:
- Um bucket do Cloud Storage para armazenar o modelo baixado e o cache de compilação. Um driver CSI do Cloud Storage FUSE lê o conteúdo do bucket.
- Volumes com cache de arquivos ativado e o recurso de download paralelo do Cloud Storage FUSE.
Prática recomendada: Use um cache de arquivos com suporte de
tmpfsouHyperdisk / Persistent Diskdependendo do tamanho esperado do conteúdo do modelo, por exemplo, arquivos de peso. Neste tutorial, você vai usar o cache de arquivos do Cloud Storage FUSE com suporte de RAM.
Implantar o servidor de modelos do vLLM
Para implantar o servidor de modelos vLLM, este tutorial usa uma implantação do Kubernetes. Uma implantação é um objeto da API Kubernetes que permite executar várias réplicas de pods distribuídos entre os nós de um cluster.
Inspecione o seguinte manifesto de implantação salvo como
vllm-llama3-70b.yaml, que usa uma única réplica:Se você aumentar o escalonamento do Deployment para várias réplicas, as gravações simultâneas no
VLLM_XLA_CACHE_PATHvão causar o erro:RuntimeError: filesystem error: cannot create directories. Para evitar esse erro, você tem duas opções:Remova o local do cache XLA excluindo o seguinte bloco do YAML de implantação. Isso significa que todas as réplicas vão recompilar o cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Escalone o Deployment para
1e aguarde até que a primeira réplica fique pronta e grave no cache XLA. Em seguida, faça o escalonamento para réplicas adicionais. Isso permite que o restante das réplicas leia o cache sem tentar gravar nele.
Execute este comando para aplicar o manifesto:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Confira os registros do servidor de modelos em execução:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}A saída será parecida com esta:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Disponibilizar o modelo
Para saber o endereço IP externo do serviço VLLM, execute o seguinte comando:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Interaja com o modelo usando
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'A saída será semelhante a esta:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configurar o autoescalador personalizado
Nesta seção, você configura o escalonamento automático horizontal de pods usando métricas personalizadas do Prometheus. Você usa as métricas do Google Cloud Managed Service para Prometheus do servidor vLLM.
Para saber mais, consulte Google Cloud Managed Service para Prometheus. Essa opção precisa estar ativada por padrão no cluster do GKE.
Configure o adaptador de métricas personalizadas do Stackdriver no cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAdicione o papel de leitor do Monitoring à conta de serviço usada pelo adaptador de métricas personalizadas do Stackdriver:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSalve o seguinte manifesto como
vllm_pod_monitor.yaml:Aplique ao cluster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Criar carga no endpoint vLLM
Crie carga para o servidor vLLM e teste como o GKE faz o escalonamento automático com uma métrica personalizada do vLLM.
Execute um script bash (
load.sh) para enviarNsolicitações paralelas ao endpoint vLLM:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitSubstitua PARALLEL_PROCESSES pelo número de processos paralelos que você quer executar.
Execute o script bash:
chmod +x load.sh nohup ./load.sh &
Verificar se o Google Cloud Managed Service para Prometheus ingere as métricas
Depois que o Google Cloud Managed Service para Prometheus extrair as métricas e você adicionar carga ao endpoint vLLM, será possível conferir as métricas no Cloud Monitoring.
No console Google Cloud , acesse a página Metrics Explorer.
Clique em < > PromQL.
Insira a seguinte consulta para observar as métricas de tráfego:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
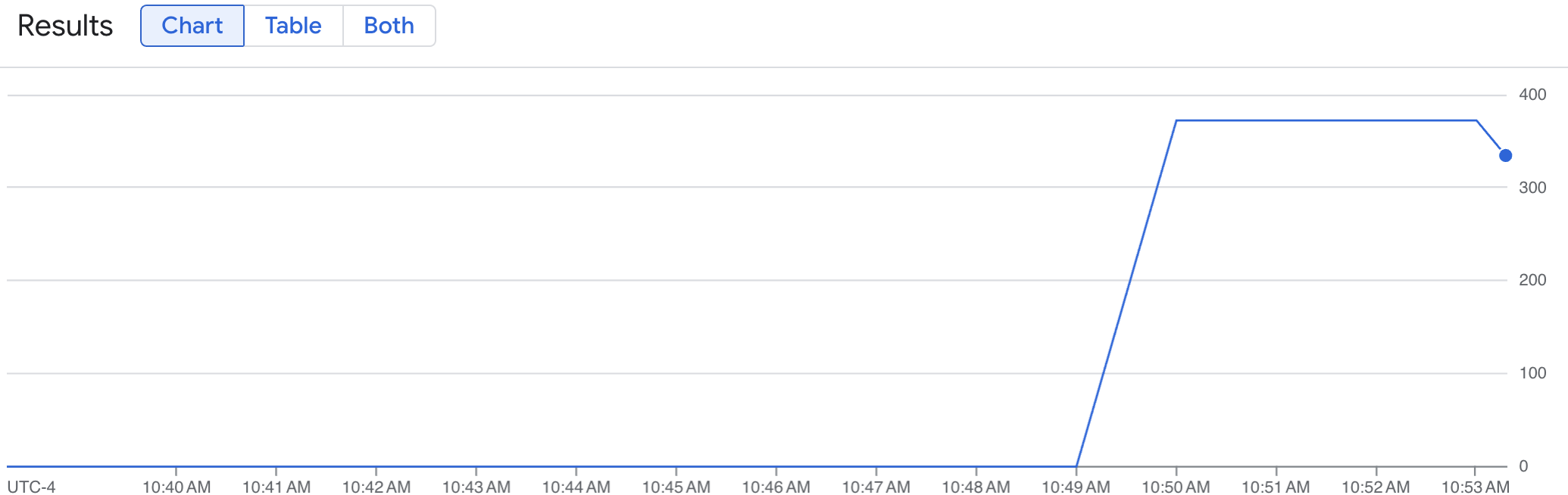
Um gráfico de linhas mostra sua métrica de vLLM (num_requests_waiting) medida ao longo do tempo. A métrica vLLM aumenta de 0 (pré-carga) para um valor (pós-carga). Esse gráfico confirma que as métricas do vLLM estão sendo ingeridas no Google Cloud Managed Service para Prometheus. O gráfico de exemplo a seguir mostra um valor de pré-carga inicial de 0, que atinge um valor máximo de pós-carga de quase 400 em um minuto.
Implantar a configuração do escalonador automático horizontal de pods
Ao decidir qual métrica usar para o escalonamento automático, recomendamos as seguintes métricas para a TPU do vLLM:
num_requests_waiting: essa métrica se relaciona ao número de solicitações aguardando na fila do servidor do modelo. Esse número começa a crescer visivelmente quando o cache de KV está cheio.gpu_cache_usage_perc: essa métrica está relacionada à utilização do cache de kv, que se correlaciona diretamente com o número de solicitações processadas em um determinado ciclo de inferência no servidor de modelo. Essa métrica funciona da mesma forma em GPUs e TPUs, embora esteja vinculada ao esquema de nomenclatura de GPU.
Recomendamos usar num_requests_waiting ao otimizar a capacidade de processamento e o custo e quando as metas de latência forem alcançáveis com a capacidade de processamento máxima do servidor de modelo.
Recomendamos que você use gpu_cache_usage_perc quando tiver cargas de trabalho sensíveis à latência em que o escalonamento baseado em fila não é rápido o suficiente para atender aos seus requisitos.
Para mais explicações, confira Práticas recomendadas para o escalonamento automático de cargas de trabalho de inferência de modelos de linguagem grandes (LLM) com TPUs.
Ao selecionar uma averageValue meta para sua configuração de HPA, você precisará determinar isso experimentalmente. Confira a postagem do blog Economize em GPUs: escalonamento automático mais inteligente para suas cargas de trabalho de inferência do GKE para mais ideias sobre como otimizar essa parte. O profile-generator usado nesta postagem do blog também funciona para a TPU do vLLM.
Nas instruções a seguir, você implanta a configuração do HPA usando a métrica num_requests_waiting. Para fins de demonstração, defina a métrica com um valor baixo para que a configuração do HPA dimensione as réplicas do vLLM para duas. Para implantar a configuração do escalonador automático horizontal de pods usando num_requests_waiting, siga estas etapas:
Salve o seguinte manifesto como
vllm-hpa.yaml:As métricas do vLLM no Google Cloud Managed Service para Prometheus seguem o formato
vllm:metric_name.Prática recomendada: Use
num_requests_waitingpara escalonar a capacidade. Usegpu_cache_usage_percpara casos de uso de TPU sensíveis à latência.Implante a configuração do escalonador automático horizontal de pods:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}O GKE programa outro pod para implantação, o que aciona o escalonador automático do pool de nós para adicionar um segundo nó antes de implantar a segunda réplica do vLLM.
Acompanhe o progresso do escalonamento automático de pods:
kubectl get hpa --watch -n ${NAMESPACE}O resultado será assim:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sAguarde 10 minutos e repita as etapas na seção Verificar se o Google Cloud Managed Service para Prometheus ingere as métricas. O Google Cloud Managed Service para Prometheus ingere as métricas dos dois endpoints vLLM agora.