Visão geral
Neste guia, mostramos como disponibilizar modelos de linguagem grandes (LLMs) de última geração, como DeepSeek-R1 671B ou Llama 3.1 405B no Google Kubernetes Engine (GKE) usando unidades de processamento gráfico (GPUs) em vários nós.
Este guia mostra como usar tecnologias portáteis de código aberto (Kubernetes, vLLM e a API LeaderWorkerSet [LWS]) para implantar e disponibilizar cargas de trabalho de IA/ML no GKE, aproveitando o controle granular, a escalonabilidade, a resiliência, a portabilidade e a economia do GKE.
Antes de ler esta página, confira se você conhece os seguintes conceitos:
Contexto
Esta seção descreve as principais tecnologias usadas neste guia, incluindo os dois LLMs usados como exemplos: DeepSeek-R1 e Llama 3.1 405B.
DeepSeek-R1
O DeepSeek-R1, um modelo de linguagem grande com 671 bilhões de parâmetros da DeepSeek, foi projetado para inferência lógica, raciocínio matemático e resolução de problemas em tempo real em várias tarefas baseadas em texto. O GKE lida com as demandas computacionais do DeepSeek-R1, oferecendo suporte aos recursos dele com recursos escalonáveis, computação distribuída e rede eficiente.
Para saber mais, consulte a documentação do DeepSeek.
Llama 3.1 405B
O Llama 3.1 405B é um modelo de linguagem grande da Meta projetado para uma ampla variedade de tarefas de processamento de linguagem natural, incluindo geração de texto, tradução e resposta a perguntas. O GKE oferece a infraestrutura robusta necessária para oferecer suporte às necessidades de treinamento e disponibilização distribuídos de modelos dessa escala.
Para saber mais, consulte a documentação do Llama.
Serviço gerenciado do Kubernetes do GKE
Google Cloud oferece uma ampla variedade de serviços, incluindo o GKE, que é adequado para implantação e gerenciamento de cargas de trabalho de IA/ML. O GKE é um serviço gerenciado do Kubernetes que simplifica a implantação, o escalonamento e o gerenciamento de aplicativos conteinerizados. O GKE oferece a infraestrutura necessária, incluindo recursos escalonáveis, computação distribuída e rede eficiente, para lidar com as demandas computacionais dos LLMs.
Para saber mais sobre os principais conceitos do Kubernetes, consulte Começar a aprender sobre o Kubernetes. Para saber mais sobre o GKE e como ele ajuda você a escalonar, automatizar e gerenciar o Kubernetes, consulte a visão geral do GKE.
GPUs
As unidades de processamento gráfico (GPUs) permitem acelerar cargas de trabalho específicas, como machine learning e processamento de dados. O GKE oferece nós equipados com essas GPUs potentes, permitindo que você configure seu cluster para ter o desempenho ideal em tarefas de machine learning e processamento de dados. O GKE oferece uma variedade de opções de tipo de máquina para configuração de nós, incluindo tipos de máquinas com GPUs NVIDIA H100, L4 e A100.
Para saber mais, consulte Sobre GPUs no GKE.
LeaderWorkerSet (LWS)
O LeaderWorkerSet (LWS) é uma API de implantação do Kubernetes que aborda padrões comuns de implantação de cargas de trabalho de inferência multinó de IA/ML. O serviço de vários nós usa vários pods, cada um potencialmente executado em um nó diferente, para processar a carga de trabalho de inferência distribuída. Ele permite lidar com vários pods como um grupo, simplificando o gerenciamento da disponibilização de modelos distribuídos.
vLLM e veiculação de vários hosts
Ao veicular LLMs com uso intensivo de computação, recomendamos usar o vLLM e executar as cargas de trabalho em GPUs.
O vLLM é um framework de exibição de LLM de código aberto altamente otimizado que pode aumentar a capacidade de exibição em GPUs, com recursos como:
- Otimização da implementação do transformador com PagedAttention
- Lotes contínuos para melhorar a capacidade geral de exibição
- Exibição distribuída em várias GPUs
Com LLMs especialmente intensivos em computação que não cabem em um único nó de GPU, é possível usar vários nós de GPU para disponibilizar o modelo. O vLLM oferece suporte à execução de cargas de trabalho em GPUs com duas estratégias:
O paralelismo de tensor divide as multiplicações de matriz na camada do transformador em várias GPUs. No entanto, essa estratégia exige uma rede rápida devido à comunicação necessária entre as GPUs, o que a torna menos adequada para a execução de cargas de trabalho em nós.
O paralelismo de pipeline divide o modelo por camada ou verticalmente. Essa estratégia não exige comunicação constante entre as GPUs, o que a torna uma opção melhor para a execução de modelos em vários nós.
Você pode usar as duas estratégias na disponibilização multinó. Por exemplo, ao usar dois nós com oito GPUs H100 cada, é possível usar as duas estratégias:
- Paralelismo de pipeline bidirecional para dividir o modelo entre os dois nós
- Paralelismo de tensor de oito vias para dividir o modelo entre as oito GPUs em cada nó
Para saber mais, consulte a documentação do vLLM.
Criar um cluster do GKE
É possível disponibilizar modelos usando o vLLM em vários nós de GPU em um cluster do GKE Autopilot ou Standard. Recomendamos que você use um cluster do Autopilot para ter uma experiência totalmente gerenciada do Kubernetes. Para escolher o modo de operação do GKE mais adequado para suas cargas de trabalho, consulte Escolher um modo de operação do GKE.
Piloto automático
No Cloud Shell, execute este comando:
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
Padrão
Crie um cluster do GKE Standard com dois nós de CPU:
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-16Crie um pool de nós A3 com dois nós, cada um com oito H100s:
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
Configure kubectl para se comunicar com o cluster
Configure kubectl para se comunicar com o cluster usando o seguinte comando:
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
Criar um Secret do Kubernetes para as credenciais do Hugging Face
Crie um secret do Kubernetes que contenha o token do Hugging Face usando o seguinte comando:
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
Instalar o LeaderWorkerSet
Para instalar o LWS, execute este comando:
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
Valide se o controlador LeaderWorkerSet está em execução no namespace lws-system
usando o seguinte comando:
kubectl get pod -n lws-system
O resultado será assim:
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
Implantar o servidor de modelos do vLLM
Para implantar o servidor de modelos vLLM, siga estas etapas:
Aplique o manifesto, dependendo do LLM que você quer implantar.
DeepSeek-R1
Inspecione o manifesto
vllm-deepseek-r1-A3.yaml.Execute este comando para aplicar o manifesto:
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
Inspecione o manifesto
vllm-llama3-405b-A3.yaml.Execute este comando para aplicar o manifesto:
kubectl apply -f vllm-llama3-405b-A3.yaml
Aguarde a conclusão do download do checkpoint do modelo. Essa operação pode levar vários minutos para ser concluída.
Confira os registros do servidor de modelos em execução com o seguinte comando:
kubectl logs vllm-0 -c vllm-leaderA saída será parecida com esta:
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Disponibilizar o modelo
Configure o encaminhamento de portas para o modelo executando o seguinte comando:
kubectl port-forward svc/vllm-leader 8080:8080
Interagir com o modelo usando curl
Para interagir com o modelo usando curl, siga estas instruções:
DeepSeek-R1
Em um novo terminal, envie uma solicitação ao servidor:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
A saída será semelhante a esta:
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
Em um novo terminal, envie uma solicitação ao servidor:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
A saída será semelhante a esta:
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configurar o autoescalador personalizado
Nesta seção, você configura o escalonamento automático horizontal de pods para usar métricas personalizadas do Prometheus. Você usa as métricas do Google Cloud Managed Service para Prometheus do servidor vLLM.
Para saber mais, consulte Google Cloud Managed Service para Prometheus. Essa opção precisa estar ativada por padrão no cluster do GKE.
Configure o adaptador de métricas personalizadas do Stackdriver no cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAdicione o papel de leitor do Monitoring à conta de serviço usada pelo adaptador de métricas personalizadas do Stackdriver:
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSalve o seguinte manifesto como
vllm_pod_monitor.yaml:Aplique o manifesto ao cluster:
kubectl apply -f vllm_pod_monitor.yaml
Criar carga no endpoint vLLM
Crie carga no servidor vLLM para testar como o GKE faz o escalonamento automático com uma métrica vLLM personalizada.
Configure o encaminhamento de portas para o modelo:
kubectl port-forward svc/vllm-leader 8080:8080Execute um script bash (
load.sh) para enviarNsolicitações paralelas ao endpoint vLLM:#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitSubstitua PARALLEL_PROCESSES pelo número de processos paralelos que você quer executar.
Execute o script bash:
nohup ./load.sh &
Verificar se o Google Cloud Managed Service para Prometheus ingere as métricas
Depois que o Google Cloud Managed Service para Prometheus extrair as métricas e você adicionar carga ao endpoint vLLM, será possível conferir as métricas no Cloud Monitoring.
No console Google Cloud , acesse a página Metrics Explorer.
Clique em < > PromQL.
Insira a seguinte consulta para observar as métricas de tráfego:
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
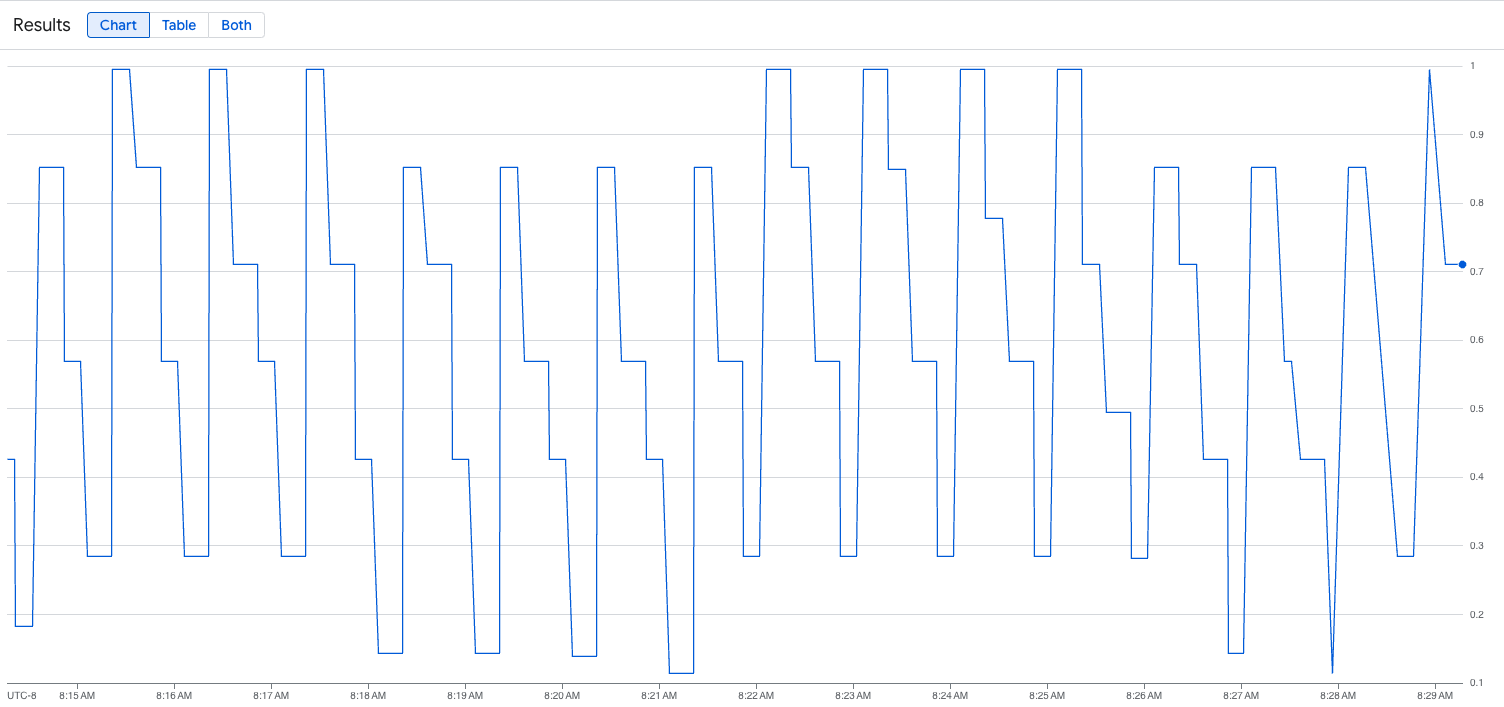
A imagem a seguir é um exemplo de gráfico após a execução do script de carregamento. Este gráfico mostra que o Google Cloud Managed Service para Prometheus está ingerindo as métricas de tráfego em resposta à carga adicionada ao endpoint vLLM:
Implantar a configuração do escalonador automático horizontal de pods
Ao decidir qual métrica usar para o escalonamento automático, recomendamos as seguintes métricas para o vLLM:
num_requests_waiting: essa métrica se relaciona ao número de solicitações aguardando na fila do servidor do modelo. Esse número começa a crescer visivelmente quando o cache de KV está cheio.gpu_cache_usage_perc: essa métrica está relacionada à utilização do cache de KV, que está diretamente correlacionada ao número de solicitações processadas para um determinado ciclo de inferência no servidor de modelo.
Recomendamos usar num_requests_waiting ao otimizar a capacidade de processamento e o custo e quando as metas de latência forem alcançáveis com a capacidade de processamento máxima do servidor de modelo.
Recomendamos que você use gpu_cache_usage_perc quando tiver cargas de trabalho sensíveis à latência em que o escalonamento baseado em fila não é rápido o suficiente para atender aos seus requisitos.
Para mais explicações, consulte Práticas recomendadas para o escalonamento automático de cargas de trabalho de inferência de modelos de linguagem grandes (LLM) com GPUs.
Ao selecionar uma meta de averageValue para sua configuração do HPA, você precisa determinar qual métrica usar para o escalonamento automático experimental. Para mais ideias sobre como otimizar seus experimentos, consulte a postagem do blog Economize em GPUs: escalonamento automático mais inteligente para suas cargas de trabalho de inferência do GKE. O profile-generator usado nesta postagem do blog também funciona com o vLLM.
Para implantar a configuração do escalonador automático horizontal de pods usando num_requests_waiting, siga estas etapas:
Salve o seguinte manifesto como
vllm-hpa.yaml:As métricas do vLLM no Google Cloud Managed Service para Prometheus seguem o formato
vllm:metric_name.Prática recomendada: Use
num_requests_waitingpara escalonar a capacidade. Usegpu_cache_usage_percpara casos de uso de GPU sensíveis à latência.Implante a configuração do escalonador automático horizontal de pods:
kubectl apply -f vllm-hpa.yamlO GKE programa outro pod para implantação, o que aciona o escalonador automático do pool de nós para adicionar um segundo nó antes de implantar a segunda réplica do vLLM.
Acompanhe o progresso do escalonamento automático de pods:
kubectl get hpa --watchO resultado será assim:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
Acelere os tempos de carregamento de modelos com o Hyperdisk ML do Google Cloud
Com esses tipos de LLMs, o vLLM pode levar muito tempo para fazer o download, carregar e aquecer cada nova réplica. Por exemplo, esse processo pode levar cerca de 90 minutos com o Llama 3.1 405B. É possível reduzir esse tempo (para 20 minutos com o Llama 3.1 405B) fazendo o download do modelo diretamente para um volume do Hyperdisk ML e montando esse volume em cada pod. Para concluir esta operação, este tutorial usa um volume do Hyperdisk ML e um job do Kubernetes. Um controlador de job no Kubernetes cria um ou mais pods e garante que eles executem uma tarefa específica com sucesso.
Para acelerar os tempos de carregamento do modelo, siga estas etapas:
Salve o seguinte manifesto de exemplo como
producer-pvc.yaml:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800GiSalve o seguinte manifesto de exemplo como
producer-job.yaml:DeepSeek-R1
Llama 3.1 405B
Siga as instruções em Acelerar o carregamento de dados de IA/ML com o Hyperdisk ML, usando os dois arquivos criados nas etapas anteriores.
Depois dessa etapa, você terá criado e preenchido o volume de ML do Hyperdisk com os dados do modelo.
Implante a implantação do servidor de GPU de vários nós do vLLM, que usará o volume de ML do Hyperdisk recém-criado para dados do modelo.
DeepSeek-R1
Llama 3.1 405B