Ringkasan
Panduan ini menunjukkan cara menayangkan model bahasa besar (LLM) canggih seperti DeepSeek-R1 671B atau Llama 3.1 405B di Google Kubernetes Engine (GKE) menggunakan unit pemrosesan grafis (GPU) di beberapa node.
Panduan ini menunjukkan cara menggunakan teknologi open source portabel—Kubernetes, vLLM, dan API LeaderWorkerSet (LWS)—untuk men-deploy dan menayangkan workload AI/ML di GKE, dengan memanfaatkan kontrol terperinci, skalabilitas, ketahanan, portabilitas, dan efektivitas biaya GKE.
Sebelum membaca halaman ini, pastikan Anda memahami hal-hal berikut:
Latar belakang
Bagian ini menjelaskan teknologi utama yang digunakan dalam panduan ini, termasuk dua LLM yang digunakan sebagai contoh dalam panduan ini—DeepSeek-R1 dan Llama 3.1 405B.
DeepSeek-R1
DeepSeek-R1, model bahasa besar dengan 671 miliar parameter dari DeepSeek, dirancang untuk inferensi logis, penalaran matematika, dan pemecahan masalah real-time dalam berbagai tugas berbasis teks. GKE menangani tuntutan komputasi DeepSeek-R1, mendukung kemampuannya dengan resource yang dapat diskalakan, komputasi terdistribusi, dan jaringan yang efisien.
Untuk mempelajari lebih lanjut, lihat dokumentasi DeepSeek.
Llama 3.1 405B
Llama 3.1 405B adalah model bahasa besar dari Meta yang dirancang untuk berbagai tugas natural language processing, termasuk pembuatan teks, terjemahan, dan question answering. GKE menawarkan infrastruktur yang andal yang diperlukan untuk mendukung kebutuhan pelatihan dan inferensi terdistribusi model dalam skala ini.
Untuk mempelajari lebih lanjut, lihat dokumentasi Llama.
Layanan Kubernetes terkelola GKE
Google Cloud menawarkan berbagai layanan, termasuk GKE, yang sangat cocok untuk men-deploy dan mengelola workload AI/ML. GKE adalah layanan Kubernetes terkelola yang menyederhanakan deployment, penskalaan, dan pengelolaan aplikasi dalam container. GKE menyediakan infrastruktur yang diperlukan, termasuk resource yang skalabel, komputasi terdistribusi, dan jaringan yang efisien, untuk menangani permintaan komputasi LLM.
Untuk mempelajari lebih lanjut konsep utama Kubernetes, lihat Mulai mempelajari Kubernetes. Untuk mempelajari lebih lanjut GKE dan cara GKE membantu Anda melakukan penskalaan, mengotomatiskan, dan mengelola Kubernetes, lihat Ringkasan GKE.
GPU
Unit pemrosesan grafis (GPU) memungkinkan Anda mempercepat workload tertentu seperti machine learning dan pemrosesan data. GKE menawarkan node yang dilengkapi dengan GPU berperforma tinggi ini, sehingga Anda dapat mengonfigurasi cluster untuk performa optimal dalam tugas machine learning dan pemrosesan data. GKE menyediakan berbagai opsi jenis mesin untuk konfigurasi node, termasuk jenis mesin dengan GPU NVIDIA H100, L4, dan A100.
Untuk mempelajari lebih lanjut, lihat Tentang GPU di GKE.
LeaderWorkerSet (LWS)
LeaderWorkerSet (LWS) adalah API deployment Kubernetes yang menangani pola deployment umum dari workload inferensi multi-node AI/ML. Penayangan multi-node memanfaatkan beberapa Pod, yang masing-masing berpotensi berjalan di node yang berbeda, untuk menangani workload inferensi terdistribusi. LWS memungkinkan memperlakukan beberapa Pod sebagai grup, sehingga menyederhanakan pengelolaan penayangan model terdistribusi.
vLLM dan penayangan multi-host
Saat menayangkan LLM dengan komputasi intensif, sebaiknya gunakan vLLM dan jalankan workload di seluruh GPU.
vLLM adalah framework penayangan LLM open source yang sangat dioptimalkan yang dapat meningkatkan throughput penayangan di GPU, dengan fitur seperti berikut:
- Implementasi transformer yang dioptimalkan dengan PagedAttention
- Batch berkelanjutan untuk meningkatkan throughput penayangan secara keseluruhan
- Inferensi terdistribusi pada beberapa GPU
Dengan LLM yang sangat intensif secara komputasi dan tidak dapat dimuat ke dalam satu node GPU, Anda dapat menggunakan beberapa node GPU untuk menyajikan model. vLLM mendukung menjalankan workload di seluruh GPU dengan dua strategi:
Paralelisme tensor membagi perkalian matriks di lapisan transformer di beberapa GPU. Namun, strategi ini memerlukan jaringan yang cepat karena komunikasi yang diperlukan antar-GPU, sehingga kurang cocok untuk menjalankan workload di seluruh node.
Paralelisme pipeline membagi model berdasarkan lapisan, atau secara vertikal. Strategi ini tidak memerlukan komunikasi konstan antar-GPU, sehingga menjadi opsi yang lebih baik saat menjalankan model di seluruh node.
Anda dapat menggunakan kedua strategi ini dalam penayangan multi-node. Misalnya, saat menggunakan dua node dengan delapan GPU H100 di setiap node, Anda dapat menggunakan kedua strategi:
- Paralelisme pipeline dua arah untuk membagi model di dua node
- Paralelisme tensor delapan arah untuk membagi model di delapan GPU di setiap node
Untuk mempelajari lebih lanjut, lihat dokumentasi vLLM.
Membuat cluster GKE
Anda dapat menyajikan model menggunakan vLLM di beberapa node GPU dalam cluster GKE Autopilot atau Standard. Sebaiknya gunakan cluster Autopilot untuk pengalaman Kubernetes yang terkelola sepenuhnya. Untuk memilih mode operasi GKE yang paling sesuai untuk workload Anda, lihat Memilih mode operasi GKE.
Autopilot
Jalankan perintah berikut di Cloud Shell:
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
Standar
Buat cluster GKE Standard dengan dua node CPU:
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-16Buat node pool A3 dengan dua node, masing-masing dengan delapan H100:
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
Konfigurasi kubectl untuk berkomunikasi dengan cluster Anda
Konfigurasi kubectl untuk berkomunikasi dengan cluster Anda menggunakan perintah berikut:
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
Buat Secret Kubernetes untuk kredensial Hugging Face
Buat Secret Kubernetes yang berisi token Hugging Face menggunakan perintah berikut:
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
Instal LeaderWorkerSet
Untuk menginstal LWS, jalankan perintah berikut:
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
Validasi bahwa pengontrol LeaderWorkerSet berjalan di namespace lws-system
menggunakan perintah berikut:
kubectl get pod -n lws-system
Outputnya mirip dengan hal berikut ini:
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
Men-deploy Server Model vLLM
Untuk men-deploy server model vLLM, ikuti langkah-langkah berikut:
Terapkan manifes, bergantung pada LLM yang ingin Anda deploy.
DeepSeek-R1
Periksa manifes
vllm-deepseek-r1-A3.yaml.Terapkan manifes dengan menjalankan perintah berikut:
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
Periksa manifes
vllm-llama3-405b-A3.yaml.Terapkan manifes dengan menjalankan perintah berikut:
kubectl apply -f vllm-llama3-405b-A3.yaml
Tunggu hingga checkpoint model selesai didownload. Penyelesaian operasi ini mungkin memerlukan waktu beberapa menit.
Lihat log dari server model yang sedang berjalan dengan perintah berikut:
kubectl logs vllm-0 -c vllm-leaderOutput-nya akan terlihat seperti berikut:
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Menyajikan model
Siapkan penerusan port ke model dengan menjalankan perintah berikut:
kubectl port-forward svc/vllm-leader 8080:8080
Berinteraksi dengan model menggunakan curl
Untuk berinteraksi dengan model menggunakan curl, ikuti petunjuk berikut:
DeepSeek-R1
Di terminal baru, kirim permintaan ke server:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
Outputnya akan mirip dengan berikut ini:
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
Di terminal baru, kirim permintaan ke server:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
Outputnya akan mirip dengan berikut ini:
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Menyiapkan autoscaler kustom
Di bagian ini, Anda akan menyiapkan penskalaan otomatis Pod horizontal untuk menggunakan metrik Prometheus kustom. Anda menggunakan metrik Google Cloud Managed Service for Prometheus dari server vLLM.
Untuk mempelajari lebih lanjut, lihat Google Cloud Managed Service for Prometheus. Fitur ini harus diaktifkan secara default di cluster GKE.
Siapkan Adaptor Stackdriver Metrik Kustom di cluster Anda:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlTambahkan peran Monitoring Viewer ke akun layanan yang digunakan oleh Custom Metrics Stackdriver Adapter:
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSimpan manifes berikut sebagai
vllm_pod_monitor.yaml:Terapkan manifes ke cluster:
kubectl apply -f vllm_pod_monitor.yaml
Membuat beban pada endpoint vLLM
Buat beban di server vLLM untuk menguji cara GKE melakukan penskalaan otomatis dengan metrik vLLM kustom.
Siapkan penerusan port ke model:
kubectl port-forward svc/vllm-leader 8080:8080Jalankan skrip bash (
load.sh) untuk mengirimkanNjumlah permintaan paralel ke endpoint vLLM:#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitGanti PARALLEL_PROCESSES dengan jumlah proses paralel yang ingin Anda jalankan.
Jalankan skrip bash:
nohup ./load.sh &
Pastikan bahwa Google Cloud Managed Service for Prometheus menyerap metrik
Setelah Google Cloud Managed Service for Prometheus meng-scrape metrik dan Anda menambahkan beban ke endpoint vLLM, Anda dapat melihat metrik di Cloud Monitoring.
Di konsol Google Cloud , buka halaman Metrics explorer.
Klik < > PromQL.
Masukkan kueri berikut untuk mengamati metrik traffic:
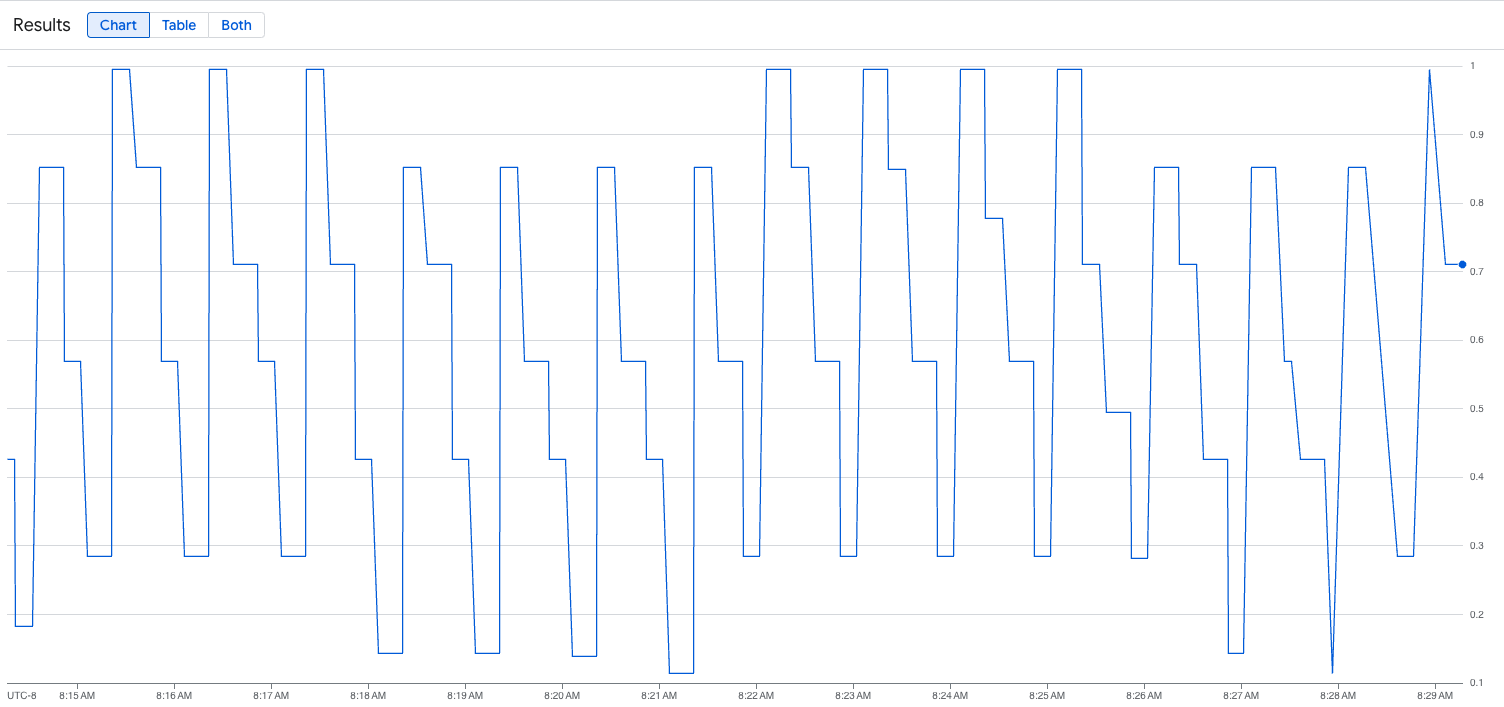
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
Gambar berikut adalah contoh grafik setelah eksekusi skrip pemuatan. Grafik ini menunjukkan bahwa Google Cloud Managed Service for Prometheus menyerap metrik traffic sebagai respons terhadap beban yang ditambahkan ke endpoint vLLM:
Men-deploy konfigurasi Horizontal Pod Autoscaler
Saat Anda memutuskan metrik mana yang akan digunakan untuk penskalaan otomatis, sebaiknya gunakan metrik berikut untuk vLLM:
num_requests_waiting: metrik ini terkait dengan jumlah permintaan yang menunggu dalam antrean server model. Jumlah ini mulai bertambah secara signifikan saat cache kv penuh.gpu_cache_usage_perc: metrik ini terkait dengan pemanfaatan cache KV, yang secara langsung berkorelasi dengan jumlah permintaan yang diproses untuk siklus inferensi tertentu di server model.
Sebaiknya gunakan num_requests_waiting saat Anda mengoptimalkan
throughput dan biaya, serta saat target latensi dapat dicapai dengan throughput maksimum server model Anda.
Sebaiknya gunakan gpu_cache_usage_perc jika Anda memiliki workload yang sensitif terhadap latensi dan penskalaan berbasis antrean tidak cukup cepat untuk memenuhi persyaratan Anda.
Untuk penjelasan lebih lanjut, lihat Praktik terbaik untuk menskalakan otomatis workload inferensi model bahasa besar (LLM) dengan GPU.
Saat memilih target averageValue untuk konfigurasi HPA, Anda perlu menentukan metrik mana yang akan digunakan untuk penskalaan otomatis secara eksperimental. Untuk mendapatkan ide tambahan tentang cara mengoptimalkan eksperimen, lihat postingan blog Hemat GPU: Penskalaan otomatis yang lebih cerdas untuk workload inferensi GKE Anda. profile-generator yang digunakan dalam postingan blog ini juga berfungsi untuk vLLM.
Untuk men-deploy konfigurasi Horizontal Pod Autoscaler menggunakan num_requests_waiting, ikuti langkah-langkah berikut:
Simpan manifes berikut sebagai
vllm-hpa.yaml:Metrik vLLM di Google Cloud Managed Service for Prometheus mengikuti format
vllm:metric_name.Praktik terbaik: Gunakan
num_requests_waitinguntuk menskalakan throughput. Gunakangpu_cache_usage_percuntuk kasus penggunaan GPU yang sensitif terhadap latensi.Deploy konfigurasi Horizontal Pod Autoscaler:
kubectl apply -f vllm-hpa.yamlGKE menjadwalkan Pod lain untuk di-deploy, yang memicu autoscaler node pool untuk menambahkan node kedua sebelum men-deploy replika vLLM kedua.
Lihat progres penskalaan otomatis Pod:
kubectl get hpa --watchOutputnya mirip dengan hal berikut ini:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
Mempercepat waktu pemuatan model dengan Google Cloud Hyperdisk ML
Dengan jenis LLM ini, vLLM dapat memerlukan waktu yang cukup lama untuk didownload, dimuat, dan di-warm up pada setiap replika baru. Misalnya, proses tersebut dapat memakan waktu sekitar 90 menit dengan Llama 3.1 405B. Anda dapat mengurangi waktu ini (menjadi 20 menit dengan Llama 3.1 405B) dengan mendownload model langsung ke volume Hyperdisk ML dan memasang volume tersebut ke setiap Pod. Untuk menyelesaikan operasi ini, tutorial ini menggunakan volume ML Hyperdisk dan Tugas Kubernetes. Pengontrol Tugas di Kubernetes membuat satu atau beberapa Pod dan memastikan bahwa Pod tersebut berhasil menjalankan tugas tertentu.
Untuk mempercepat waktu pemuatan model, lakukan langkah-langkah berikut:
Simpan contoh manifes berikut sebagai
producer-pvc.yaml:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800GiSimpan contoh manifes berikut sebagai
producer-job.yaml:DeepSeek-R1
Llama 3.1 405B
Ikuti petunjuk di Mempercepat pemuatan data AI/ML dengan Hyperdisk ML, menggunakan dua file yang Anda buat pada langkah sebelumnya.
Setelah langkah ini, Anda telah membuat dan mengisi volume ML Hyperdisk dengan data model.
Deploy deployment server GPU multi-node vLLM, yang akan menggunakan volume Hyperdisk ML yang baru dibuat untuk data model.
DeepSeek-R1
Llama 3.1 405B