Información general
En esta guía se muestra cómo ofrecer modelos de lenguaje extensos (LLMs) de última generación, como DeepSeek-R1 671B o Llama 3.1 405B, en Google Kubernetes Engine (GKE) mediante unidades de procesamiento gráfico (GPUs) en varios nodos.
En esta guía se muestra cómo usar tecnologías portátiles de código abierto (Kubernetes, vLLM y la API LeaderWorkerSet [LWS]) para desplegar y servir cargas de trabajo de IA y aprendizaje automático en GKE, aprovechando el control granular, la escalabilidad, la resiliencia, la portabilidad y la rentabilidad de GKE.
Antes de leer esta página, asegúrese de que conoce los siguientes conceptos:
Fondo
En esta sección se describen las tecnologías clave que se usan en esta guía, incluidos los dos LLMs que se usan como ejemplos en esta guía: DeepSeek-R1 y Llama 3.1 405B.
DeepSeek-R1
DeepSeek-R1, un modelo de lenguaje extenso de 671.000 millones de parámetros de DeepSeek, se ha diseñado para la inferencia lógica, el razonamiento matemático y la resolución de problemas en tiempo real en diversas tareas basadas en texto. GKE gestiona las demandas computacionales de DeepSeek-R1, lo que permite que este modelo aproveche sus funciones con recursos escalables, computación distribuida y redes eficientes.
Para obtener más información, consulta la documentación de DeepSeek.
Llama 3.1 405B
Llama 3.1 405B es un modelo de lenguaje extenso de Meta diseñado para una amplia gama de tareas de procesamiento del lenguaje natural, como la generación de texto, la traducción y la respuesta a preguntas. GKE ofrece la infraestructura sólida necesaria para admitir las necesidades de entrenamiento y servicio distribuidos de modelos de esta escala.
Para obtener más información, consulta la documentación de Llama.
Servicio de Kubernetes gestionado de GKE
Google Cloud ofrece una amplia gama de servicios, incluido GKE, que es ideal para desplegar y gestionar cargas de trabajo de IA y aprendizaje automático. GKE es un servicio de Kubernetes gestionado que simplifica el despliegue, el escalado y la gestión de aplicaciones en contenedores. GKE proporciona la infraestructura necesaria, incluidos recursos escalables, computación distribuida y redes eficientes, para gestionar las demandas computacionales de los LLMs.
Para obtener más información sobre los conceptos clave de Kubernetes, consulta Empezar a aprender sobre Kubernetes. Para obtener más información sobre GKE y cómo te ayuda a escalar, automatizar y gestionar Kubernetes, consulta la descripción general de GKE.
GPUs
Las unidades de procesamiento gráfico (GPUs) te permiten acelerar cargas de trabajo específicas, como el aprendizaje automático y el procesamiento de datos. GKE ofrece nodos equipados con estas potentes GPUs, lo que te permite configurar tu clúster para que tenga un rendimiento óptimo en las tareas de aprendizaje automático y procesamiento de datos. GKE ofrece una amplia gama de opciones de tipos de máquinas para la configuración de nodos, incluidos los tipos de máquinas con GPUs NVIDIA H100, L4 y A100.
Para obtener más información, consulta Acerca de las GPUs en GKE.
LeaderWorkerSet (LWS)
LeaderWorkerSet (LWS) es una API de implementación de Kubernetes que aborda patrones de implementación comunes de cargas de trabajo de inferencia multinodo de IA y aprendizaje automático. El servicio de varios nodos utiliza varios pods, cada uno de los cuales puede ejecutarse en un nodo diferente, para gestionar la carga de trabajo de inferencia distribuida. LWS permite tratar varios pods como un grupo, lo que simplifica la gestión del servicio de modelos distribuidos.
vLLM y servicio multihost
Cuando sirvas LLMs que requieran muchos recursos de computación, te recomendamos que uses vLLM y ejecutes las cargas de trabajo en GPUs.
vLLM es un framework de servicio de LLMs de código abierto muy optimizado que puede aumentar el rendimiento del servicio en GPUs. Incluye funciones como las siguientes:
- Implementación optimizada de Transformer con PagedAttention
- Agrupación continua para mejorar el rendimiento general del servicio
- Servicio distribuido en varias GPUs
En el caso de los LLMs que requieren muchos recursos computacionales y no caben en un solo nodo de GPU, puedes usar varios nodos de GPU para servir el modelo. vLLM admite la ejecución de cargas de trabajo en GPUs con dos estrategias:
El paralelismo de tensores divide las multiplicaciones de matrices de la capa de transformador en varias GPUs. Sin embargo, esta estrategia requiere una red rápida debido a la comunicación necesaria entre las GPUs, por lo que no es la más adecuada para ejecutar cargas de trabajo en varios nodos.
El paralelismo de la canalización divide el modelo por capas, es decir, de forma vertical. Esta estrategia no requiere una comunicación constante entre las GPUs, por lo que es una mejor opción cuando se ejecutan modelos en varios nodos.
Puedes usar ambas estrategias en el servicio de varios nodos. Por ejemplo, si usas dos nodos con ocho GPUs H100 cada uno, puedes usar ambas estrategias:
- Paralelismo de canalización bidireccional para fragmentar el modelo en los dos nodos
- Paralelismo de tensores de ocho vías para fragmentar el modelo en las ocho GPUs de cada nodo
Para obtener más información, consulta la documentación de vLLM.
Crear un clúster de GKE
Puedes servir modelos con vLLM en varios nodos de GPU de un clúster Autopilot o Estándar de GKE. Te recomendamos que uses un clúster de Autopilot para disfrutar de una experiencia de Kubernetes totalmente gestionada. Para elegir el modo de funcionamiento de GKE que mejor se adapte a tus cargas de trabajo, consulta Elegir un modo de funcionamiento de GKE.
Autopilot
En Cloud Shell, ejecuta el siguiente comando:
gcloud container clusters create-auto ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--location=${REGION} \
--cluster-version=${CLUSTER_VERSION}
Estándar
Crea un clúster de GKE Standard con dos nodos de CPU:
gcloud container clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --num-nodes=2 \ --location=REGION \ --machine-type=e2-standard-16Crea un grupo de nodos A3 con dos nodos, cada uno con ocho H100:
gcloud container node-pools create gpu-nodepool \ --node-locations=ZONE \ --num-nodes=2 \ --machine-type=a3-highgpu-8g \ --accelerator=type=nvidia-h100-80gb,count=8,gpu-driver-version=LATEST \ --placement-type=COMPACT \ --cluster=CLUSTER_NAME --location=${REGION}
Configurar kubectl para que se comunique con tu clúster
Configura kubectl para que se comunique con tu clúster mediante el siguiente comando:
gcloud container clusters get-credentials CLUSTER_NAME --location=REGION
Crear un secreto de Kubernetes para las credenciales de Hugging Face
Crea un secreto de Kubernetes que contenga el token de Hugging Face con el siguiente comando:
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HF_TOKEN} \
--dry-run=client -o yaml | kubectl apply -f -
Instalar LeaderWorkerSet
Para instalar LWS, ejecuta el siguiente comando:
kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/latest/download/manifests.yaml
Valida que el controlador LeaderWorkerSet se esté ejecutando en el espacio de nombres lws-system
con el siguiente comando:
kubectl get pod -n lws-system
El resultado debería ser similar al siguiente:
NAME READY STATUS RESTARTS AGE
lws-controller-manager-546585777-crkpt 1/1 Running 0 4d21h
lws-controller-manager-546585777-zbt2l 1/1 Running 0 4d21h
Desplegar el servidor de modelos vLLM
Para implementar el servidor de modelos vLLM, sigue estos pasos:
Aplica el manifiesto en función del LLM que quieras implementar.
DeepSeek-R1
Inspecciona el archivo de manifiesto
vllm-deepseek-r1-A3.yaml.Aplica el manifiesto ejecutando el siguiente comando:
kubectl apply -f vllm-deepseek-r1-A3.yaml
Llama 3.1 405B
Inspecciona el archivo de manifiesto
vllm-llama3-405b-A3.yaml.Aplica el manifiesto ejecutando el siguiente comando:
kubectl apply -f vllm-llama3-405b-A3.yaml
Espera a que se termine de descargar el punto de control del modelo. Esta operación puede tardar varios minutos en completarse.
Consulta los registros del servidor de modelos en ejecución con el siguiente comando:
kubectl logs vllm-0 -c vllm-leaderLa salida debería ser similar a la siguiente:
INFO 08-09 21:01:34 api_server.py:297] Route: /detokenize, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/models, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /version, Methods: GET INFO 08-09 21:01:34 api_server.py:297] Route: /v1/chat/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/completions, Methods: POST INFO 08-09 21:01:34 api_server.py:297] Route: /v1/embeddings, Methods: POST INFO: Started server process [7428] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Aplicar el modelo
Configura la redirección de puertos al modelo ejecutando el siguiente comando:
kubectl port-forward svc/vllm-leader 8080:8080
Interactuar con el modelo mediante curl
Para interactuar con el modelo mediante curl, sigue estas instrucciones:
DeepSeek-R1
En una nueva terminal, envía una solicitud al servidor:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "I have four boxes. I put the red box on the bottom and put the blue box on top. Then I put the yellow box on top the blue. Then I take the blue box out and put it on top. And finally I put the green box on the top. Give me the final order of the boxes from bottom to top. Show your reasoning but be brief",
"max_tokens": 1024,
"temperature": 0
}'
La salida debería ser similar a la siguiente:
{
"id": "cmpl-f2222b5589d947419f59f6e9fe24c5bd",
"object": "text_completion",
"created": 1738269669,
"model": "deepseek-ai/DeepSeek-R1",
"choices": [
{
"index": 0,
"text": ".\n\nOkay, let's see. The user has four boxes and is moving them around. Let me try to visualize each step. \n\nFirst, the red box is placed on the bottom. So the stack starts with red. Then the blue box is put on top of red. Now the order is red (bottom), blue. Next, the yellow box is added on top of blue. So now it's red, blue, yellow. \n\nThen the user takes the blue box out. Wait, blue is in the middle. If they remove blue, the stack would be red and yellow. But where do they put the blue box? The instruction says to put it on top. So after removing blue, the stack is red, yellow. Then blue is placed on top, making it red, yellow, blue. \n\nFinally, the green box is added on the top. So the final order should be red (bottom), yellow, blue, green. Let me double-check each step to make sure I didn't mix up any steps. Starting with red, then blue, then yellow. Remove blue from the middle, so yellow is now on top of red. Then place blue on top of that, so red, yellow, blue. Then green on top. Yes, that seems right. The key step is removing the blue box from the middle, which leaves yellow on red, then blue goes back on top, followed by green. So the final order from bottom to top is red, yellow, blue, green.\n\n**Final Answer**\nThe final order from bottom to top is \\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}.\n</think>\n\n1. Start with the red box at the bottom.\n2. Place the blue box on top of the red box. Order: red (bottom), blue.\n3. Place the yellow box on top of the blue box. Order: red, blue, yellow.\n4. Remove the blue box (from the middle) and place it on top. Order: red, yellow, blue.\n5. Place the green box on top. Final order: red, yellow, blue, green.\n\n\\boxed{red}, \\boxed{yellow}, \\boxed{blue}, \\boxed{green}",
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 76,
"total_tokens": 544,
"completion_tokens": 468,
"prompt_tokens_details": null
}
}
Llama 3.1 405B
En una nueva terminal, envía una solicitud al servidor:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
La salida debería ser similar a la siguiente:
{"id":"cmpl-0a2310f30ac3454aa7f2c5bb6a292e6c",
"object":"text_completion","created":1723238375,"model":"meta-llama/Llama-3.1-405B-Instruct","choices":[{"index":0,"text":" top destination for foodies, with","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Configurar el escalador automático personalizado
En esta sección, configurará el autoescalado horizontal de pods para usar métricas de Prometheus personalizadas. Usas las métricas de Google Cloud Managed Service para Prometheus del servidor vLLM.
Para obtener más información, consulta Google Cloud Managed Service para Prometheus. Esta opción debería estar habilitada de forma predeterminada en el clúster de GKE.
Configura el adaptador de Stackdriver de métricas personalizadas en tu clúster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlAñade el rol Lector de Monitoring a la cuenta de servicio que usa el adaptador de Stackdriver de métricas personalizadas:
gcloud projects add-iam-policy-binding projects/PROJECT_ID \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/PROJECT_NUMBER/locations/global/workloadIdentityPools/PROJECT_ID.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterGuarda el siguiente archivo de manifiesto como
vllm_pod_monitor.yaml:Aplica el manifiesto al clúster:
kubectl apply -f vllm_pod_monitor.yaml
Crear carga en el endpoint de vLLM
Crea carga en el servidor vLLM para probar cómo se adapta automáticamente GKE con una métrica vLLM personalizada.
Configura la redirección de puertos al modelo:
kubectl port-forward svc/vllm-leader 8080:8080Ejecuta una secuencia de comandos bash (
load.sh) para enviarNsolicitudes paralelas al endpoint de vLLM:#!/bin/bash # Set the number of parallel processes to run. N=PARALLEL_PROCESSES # Get the external IP address of the vLLM load balancer service. export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}') # Loop from 1 to N to start the parallel processes. for i in $(seq 1 $N); do # Start an infinite loop to continuously send requests. while true; do # Use curl to send a completion request to the vLLM service. curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 100, "temperature": 0}' done & # Run in the background done # Keep the script running until it is manually stopped. waitSustituye PARALLEL_PROCESSES por el número de procesos paralelos que quieras ejecutar.
Ejecuta la secuencia de comandos bash:
nohup ./load.sh &
Verificar que Google Cloud Managed Service para Prometheus ingiere las métricas
Una vez que Managed Service para Prometheus de Google Cloud haya recogido las métricas y añadas carga al endpoint de vLLM, podrás ver las métricas en Cloud Monitoring.
En la Google Cloud consola, ve a la página Explorador de métricas.
Haz clic en < > PromQL.
Introduce la siguiente consulta para observar las métricas de tráfico:
vllm:gpu_cache_usage_perc{cluster='CLUSTER_NAME'}
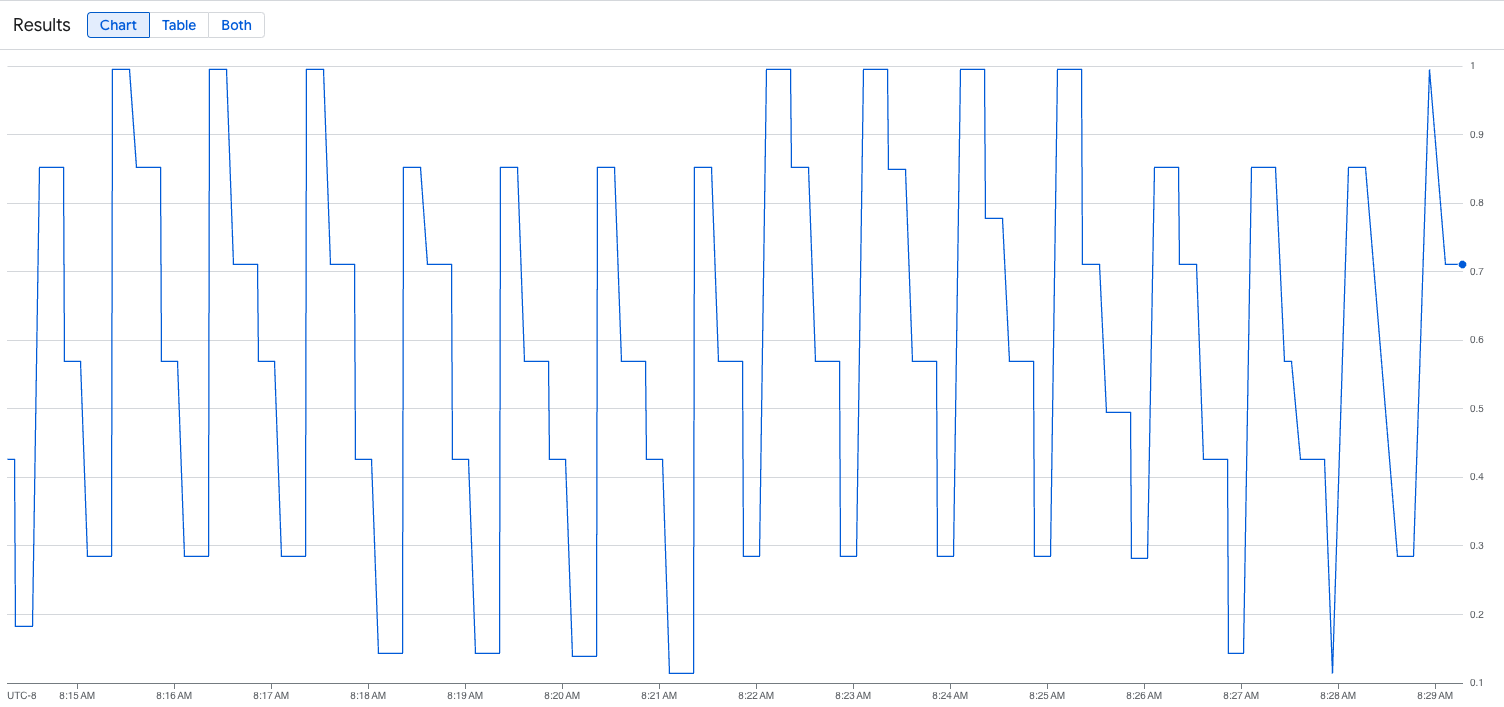
La siguiente imagen es un ejemplo de un gráfico después de ejecutar la secuencia de comandos de carga. Este gráfico muestra que Google Cloud Managed Service para Prometheus está ingiriendo las métricas de tráfico en respuesta a la carga añadida al endpoint de vLLM:
Desplegar la configuración de la herramienta de adaptación dinámica horizontal de pods
Cuando decidas en qué métrica basar el autoescalado, te recomendamos las siguientes métricas para vLLM:
num_requests_waiting: esta métrica se refiere al número de solicitudes que esperan en la cola del servidor del modelo. Este número empieza a crecer de forma notable cuando la caché de pares clave-valor está llena.gpu_cache_usage_perc: esta métrica está relacionada con la utilización de la caché de pares clave-valor, que se corresponde directamente con el número de solicitudes que se procesan en un ciclo de inferencia determinado en el servidor del modelo.
Te recomendamos que uses num_requests_waiting cuando optimices el rendimiento y el coste, y cuando puedas alcanzar tus objetivos de latencia con el rendimiento máximo del servidor de tu modelo.
Te recomendamos que uses gpu_cache_usage_perc cuando tengas cargas de trabajo sensibles a la latencia en las que el escalado basado en colas no sea lo suficientemente rápido para cumplir tus requisitos.
Para obtener más información, consulta las prácticas recomendadas para autoescalar cargas de trabajo de inferencia de modelos de lenguaje extensos (LLMs) con GPUs.
Cuando seleccionas un averageValue objetivo para tu configuración de HPA, debes determinar en qué métrica se va a basar el ajuste de escala automático de forma experimental. Para obtener más ideas sobre cómo optimizar tus experimentos, consulta la entrada de blog Ahorra en GPUs: autoescalado más inteligente para tus cargas de trabajo de inferencia de GKE. El generador de perfiles que se usa en esta entrada de blog también funciona con vLLM.
Para implementar la configuración de Horizontal Pod Autoscaler mediante num_requests_waiting, sigue estos pasos:
Guarda el siguiente archivo de manifiesto como
vllm-hpa.yaml:Las métricas de vLLM de Google Cloud Managed Service para Prometheus siguen el formato
vllm:metric_name.Práctica recomendada: Usa
num_requests_waitingpara escalar el rendimiento. Usagpu_cache_usage_percpara los casos prácticos de GPU sensibles a la latencia.Despliega la configuración de la herramienta de adaptación dinámica horizontal de pods:
kubectl apply -f vllm-hpa.yamlGKE programa otro pod para desplegarlo, lo que activa el escalador automático del grupo de nodos para añadir un segundo nodo antes de desplegar la segunda réplica de vLLM.
Supervisa el progreso del autoescalado de pods:
kubectl get hpa --watchEl resultado debería ser similar al siguiente:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 1/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 4/1 1 2 1 6d1h lws-hpa LeaderWorkerSet/vllm 0/1 1 2 2 6d1h
Acelerar los tiempos de carga de los modelos con Hyperdisk ML de Google Cloud
Con estos tipos de LLMs, vLLM puede tardar mucho tiempo en descargarse, cargarse y calentarse en cada réplica nueva. Por ejemplo, ese proceso puede tardar unos 90 minutos con Llama 3.1 405B. Puedes reducir este tiempo (a 20 minutos con Llama 3.1 405B) descargando el modelo directamente en un volumen de Hyperdisk ML y montando ese volumen en cada pod. Para completar esta operación, en este tutorial se usa un volumen de Hyperdisk ML y un trabajo de Kubernetes. Un controlador de trabajo de Kubernetes crea uno o varios pods y se asegura de que ejecuten correctamente una tarea específica.
Para acelerar los tiempos de carga de los modelos, sigue estos pasos:
Guarda el siguiente manifiesto de ejemplo como
producer-pvc.yaml:kind: PersistentVolumeClaim apiVersion: v1 metadata: name: producer-pvc spec: # Specifies the StorageClass to use. Hyperdisk ML is optimized for ML workloads. storageClassName: hyperdisk-ml accessModes: - ReadWriteOnce resources: requests: storage: 800GiGuarda el siguiente manifiesto de ejemplo como
producer-job.yaml:DeepSeek-R1
Llama 3.1 405B
Sigue las instrucciones de Acelerar la carga de datos de IA o aprendizaje automático con Hyperdisk ML con los dos archivos que has creado en los pasos anteriores.
Después de este paso, habrá creado y rellenado el volumen de Hyperdisk ML con los datos del modelo.
Despliega la implementación del servidor de GPU multinodo de vLLM, que usará el volumen de aprendizaje automático de Hyperdisk recién creado para los datos del modelo.
DeepSeek-R1
Llama 3.1 405B