Cette page explique comment utiliser le démarrage rapide GKE Inference pour simplifier le déploiement des charges de travail d'inférence d'IA/ML sur Google Kubernetes Engine (GKE). Inference Quickstart est un utilitaire qui vous permet de spécifier vos exigences commerciales en matière d'inférence et d'obtenir des configurations Kubernetes optimisées basées sur les bonnes pratiques et les benchmarks de Google pour les modèles, les serveurs de modèles, les accélérateurs (GPU, TPU), le scaling et le stockage. Cela vous permet d'éviter le processus fastidieux d'ajustement et de test manuels des configurations.
Cette page s'adresse aux ingénieurs en machine learning (ML), aux administrateurs et opérateurs de plate-forme, ainsi qu'aux spécialistes des données et de l'IA qui souhaitent comprendre comment gérer et optimiser efficacement GKE pour l'inférence d'IA/ML. Pour en savoir plus sur les rôles courants et les exemples de tâches que nous citons dans le contenu Google Cloud , consultez Rôles utilisateur et tâches courantes de GKE.
Pour en savoir plus sur les concepts et la terminologie de la mise en service de modèles, et sur la façon dont les fonctionnalités d'IA générative de GKE peuvent améliorer et soutenir les performances de mise en service de vos modèles, consultez À propos de l'inférence de modèles sur GKE.
Avant de lire cette page, assurez-vous de maîtriser Kubernetes, GKE et le service de modèles.
Utiliser le démarrage rapide de l'inférence
Le démarrage rapide de l'inférence vous permet d'analyser les performances et la rentabilité de vos charges de travail d'inférence, et de prendre des décisions basées sur les données concernant l'allocation des ressources et les stratégies de déploiement de modèles.
Voici les grandes étapes à suivre pour utiliser le guide de démarrage rapide de l'inférence :
Analysez les performances et les coûts : explorez les configurations disponibles et filtrez-les en fonction de vos exigences en termes de performances et de coûts à l'aide de la commande
gcloud container ai profiles list. Pour afficher l'ensemble complet des données de benchmarking pour une configuration spécifique, utilisez la commandegcloud container ai profiles benchmarks list. Cette commande vous permet d'identifier le matériel le plus économique pour vos besoins spécifiques en termes de performances.Déployer des fichiers manifestes : après votre analyse, vous pouvez générer un fichier manifeste Kubernetes optimisé et le déployer. Vous pouvez éventuellement activer les optimisations pour le stockage et l'autoscaling. Vous pouvez effectuer un déploiement à partir de la console Google Cloud ou à l'aide de la commande
kubectl apply. Avant de déployer, vous devez vous assurer de disposer d'un quota d'accélérateurs suffisant pour les GPU ou TPU sélectionnés dans votre projet Google Cloud .(Facultatif) Exécutez vos propres benchmarks : les configurations et les données de performances fournies sont basées sur des benchmarks qui utilisent l'ensemble de données ShareGPT. Les performances de vos charges de travail peuvent varier par rapport à cette référence. Pour mesurer les performances de votre modèle dans différentes conditions, vous pouvez utiliser l'outil de benchmark d'inférence expérimental.
Avantages
Le guide de démarrage rapide de l'inférence vous aide à gagner du temps et des ressources en fournissant des configurations optimisées. Ces optimisations améliorent les performances et réduisent les coûts d'infrastructure de la manière suivante :
- Vous recevez des bonnes pratiques détaillées et personnalisées pour définir les configurations de l'accélérateur (GPU et TPU), du serveur de modèle et du scaling. GKE met régulièrement à jour le guide de démarrage rapide sur l'inférence avec les derniers correctifs, images et benchmarks de performances.
- Vous pouvez spécifier les exigences de latence et de débit de votre charge de travail à l'aide de l'interface utilisateur de la consoleGoogle Cloud ou d'une interface de ligne de commande, et obtenir des bonnes pratiques détaillées et personnalisées sous forme de fichiers manifestes de déploiement Kubernetes.
Fonctionnement
Le démarrage rapide de l'inférence fournit des bonnes pratiques personnalisées basées sur les benchmarks internes exhaustifs de Google sur les performances d'une seule réplique pour les combinaisons de modèles, de serveurs de modèles et de topologies d'accélérateurs. Ces benchmarks représentent graphiquement la latence par rapport au débit, y compris la taille de la file d'attente et les métriques du cache KV, qui tracent les courbes de performances pour chaque combinaison.
Comment sont générées les bonnes pratiques personnalisées ?
Nous mesurons la latence en délai normalisé par jeton de sortie (NTPOT) et en délai avant le premier jeton (TTFT) en millisecondes, et le débit en jetons de sortie par seconde, en saturant les accélérateurs. Pour en savoir plus sur ces métriques de performances, consultez À propos de l'inférence de modèles sur GKE.
L'exemple de profil de latence suivant illustre le point d'inflexion où le débit se stabilise (en vert), le point post-inflexion où la latence se dégrade (en rouge) et la zone idéale (en bleu) pour un débit optimal à la latence cible. Le guide de démarrage rapide de l'inférence fournit des données de performances et des configurations pour cette zone idéale.
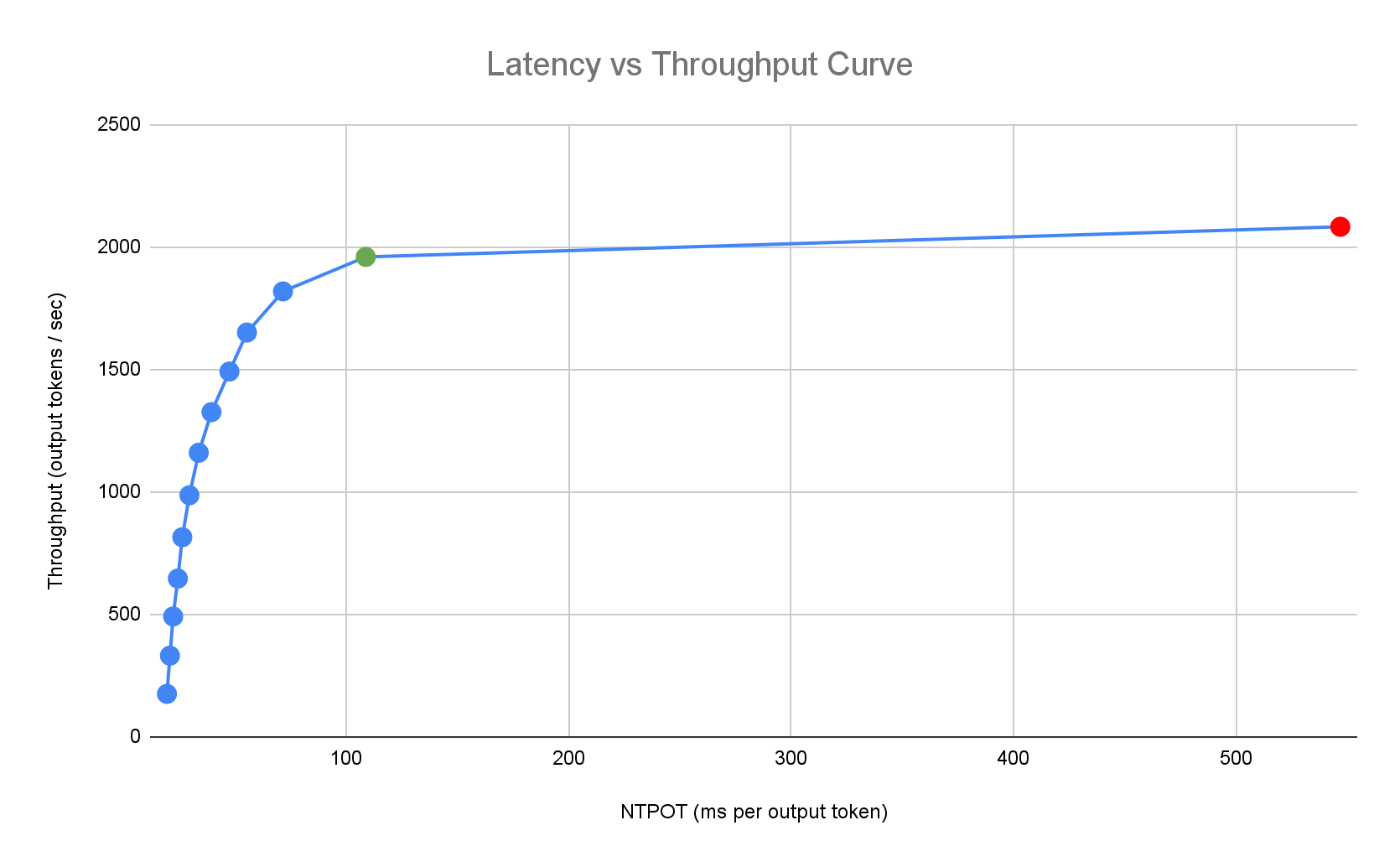
En fonction des exigences de latence d'une application d'inférence, le démarrage rapide de l'inférence identifie les combinaisons appropriées et détermine le point de fonctionnement optimal sur la courbe de latence-débit. Ce point définit le seuil de l'autoscaler horizontal de pods (AHP), avec une marge pour tenir compte de la latence de scale-up. Le seuil global indique également le nombre initial de répliques nécessaires, bien que le AHP ajuste dynamiquement ce nombre en fonction de la charge de travail.
Calcul des coûts
Pour calculer les coûts, le démarrage rapide de l'inférence utilise un rapport de coût sortie/entrée configurable. Par exemple, si ce ratio est défini sur 4, on suppose que chaque jeton de sortie coûte quatre fois plus cher qu'un jeton d'entrée. Les équations suivantes sont utilisées pour calculer les métriques de coût par jeton :
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
Où :
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Analyse comparative
Les configurations et les données de performances fournies sont basées sur des benchmarks qui utilisent l'ensemble de données ShareGPT pour envoyer du trafic avec la distribution d'entrées et de sorties suivante.
| Jetons d'entrée | Jetons de sortie | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Médiane | Moyenne | P90 | P99 | Max | Min | Médiane | Moyenne | P90 | P99 | Max |
| 4 | 108 | 226 | 635 | 887 | 1 024 | 1 | 132 | 195 | 488 | 778 | 1 024 |
Avant de commencer
Avant de commencer, effectuez les tâches suivantes :
- Activez l'API Google Kubernetes Engine. Activer l'API Google Kubernetes Engine
- Si vous souhaitez utiliser Google Cloud CLI pour cette tâche, installez puis initialisez gcloud CLI. Si vous avez déjà installé la gcloud CLI, obtenez la dernière version en exécutant la commande
gcloud components update. Il est possible que les versions antérieures de gcloud CLI ne permettent pas d'exécuter les commandes de ce document.
Dans la console Google Cloud , sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud .
Assurez-vous que la facturation est activée pour votre projet Google Cloud .
Assurez-vous que votre projet dispose d'une capacité d'accélérateur suffisante :
- Si vous utilisez des GPU : consultez la page "Quotas".
- Si vous utilisez des TPU, consultez Garantir un quota pour les TPU et les autres ressources GKE.
Se préparer à utiliser l'interface utilisateur GKE AI/ML
Si vous utilisez la console Google Cloud , vous devez également créer un cluster Autopilot, si aucun n'a déjà été créé dans votre projet. Suivez les instructions de la section Créer un cluster Autopilot.
Se préparer à utiliser l'interface de ligne de commande
Si vous utilisez gcloud CLI pour exécuter le guide de démarrage rapide sur l'inférence, vous devez également exécuter les commandes supplémentaires suivantes :
Activez l'API
gkerecommender.googleapis.com:gcloud services enable gkerecommender.googleapis.comDéfinissez le projet de quota de facturation que vous utilisez pour les appels d'API :
gcloud config set billing/quota_project PROJECT_IDVérifiez que votre version de gcloud CLI est au moins la version 536.0.1. Si ce n'est pas le cas, exécutez la commande suivante :
gcloud components update
Limites
Avant de commencer à utiliser le guide de démarrage rapide de l'inférence, tenez compte des limites suivantes :
- Le déploiement de modèles dans la consoleGoogle Cloud n'est possible que sur les clusters Autopilot.
- Le guide de démarrage rapide de l'inférence ne fournit pas de profils pour tous les modèles compatibles avec un serveur de modèle donné.
- Si vous ne définissez pas la variable d'environnement
HF_HOMElorsque vous utilisez un fichier manifeste généré pour un grand modèle (90 Gio ou plus) à partir de Hugging Face, vous devez utiliser un cluster avec des disques de démarrage plus grands que ceux par défaut ou modifier le fichier manifeste pour définirHF_HOMEsur/dev/shm/hf_cache. La RAM sera utilisée pour le cache au lieu du disque de démarrage du nœud. Pour en savoir plus, consultez la section Dépannage. - L'importation de modèles depuis Cloud Storage n'est compatible qu'avec le déploiement sur des clusters sur lesquels le pilote CSI Cloud Storage FUSE et la fédération d'identité de charge de travail pour GKE sont activés. Ces deux fonctionnalités sont activées par défaut dans les clusters Autopilot. Pour en savoir plus, consultez Configurer le pilote CSI Cloud Storage FUSE pour GKE.
Analyser et afficher les configurations optimisées pour l'inférence de modèle
Cette section explique comment explorer et analyser les recommandations de configuration à l'aide de Google Cloud CLI.
Utilisez la commande gcloud container ai profiles pour explorer et analyser les profils optimisés (combinaisons de modèle, de serveur de modèle, de version du serveur de modèle et d'accélérateurs) :
Modèles
Pour explorer et sélectionner un modèle, utilisez l'option models.
gcloud container ai profiles models list
Profils
Utilisez la commande list pour explorer les profils générés et les filtrer en fonction de vos exigences en termes de performances et de coûts. Exemple :
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
La sortie affiche les profils compatibles avec des métriques de performances telles que le débit, la latence et le coût par million de jetons au point d'inflexion. Il ressemble à ce qui suit :
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
Les valeurs représentent les performances observées au point où le débit cesse d'augmenter et où la latence commence à augmenter de manière spectaculaire (c'est-à-dire le point d'inflexion ou de saturation) pour un profil donné avec ce type d'accélérateur. Pour en savoir plus sur ces métriques de performances, consultez À propos de l'inférence de modèles sur GKE.
Pour obtenir la liste complète des options que vous pouvez définir, consultez la documentation de la commande list.
Toutes les informations sur les tarifs sont disponibles uniquement en dollars américains et sont définies par défaut sur la région us-east5, à l'exception des configurations qui utilisent des machines A3, qui sont définies par défaut sur la région us-central1.
Benchmarks
Pour obtenir toutes les données de benchmarking d'un profil spécifique, utilisez la commande benchmarks list.
Exemple :
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
La sortie contient une liste de métriques de performances issues de benchmarks exécutés à différents taux de requêtes.
La commande affiche le résultat au format CSV. Pour stocker la sortie dans un fichier, utilisez la redirection de sortie. Par exemple :
gcloud container ai profiles benchmarks list > profiles.csv.
Pour obtenir la liste complète des options que vous pouvez définir, consultez la documentation de la commande benchmarks list.
Une fois que vous avez choisi un modèle, un serveur de modèles, une version de serveur de modèles et un accélérateur, vous pouvez créer un fichier manifeste de déploiement.
Déployer les configurations recommandées
Cette section explique comment générer et déployer des recommandations de configuration à l'aide de la console Google Cloud ou de la ligne de commande.
Console
- Dans la console Google Cloud , accédez à la page "IA/ML GKE".
- Cliquez sur Déployer des modèles.
Sélectionnez le modèle que vous souhaitez déployer. Les modèles compatibles avec le guide de démarrage rapide de l'inférence sont indiqués par le tag Optimisé.
- Si vous avez sélectionné un modèle de fondation, une page de modèle s'ouvre. Cliquez sur Déployer. Vous pouvez toujours modifier la configuration avant le déploiement réel.
- Vous êtes invité à créer un cluster Autopilot s'il n'y en a pas dans votre projet. Suivez les instructions de la section Créer un cluster Autopilot. Après avoir créé le cluster, revenez à la page GKE AI/ML de la console Google Cloud pour sélectionner un modèle.
La page de déploiement du modèle est préremplie avec le modèle que vous avez sélectionné, ainsi que le serveur de modèles et l'accélérateur recommandés. Vous pouvez également configurer des paramètres tels que la latence maximale et la source du modèle.
(Facultatif) Pour afficher le fichier manifeste avec la configuration recommandée, cliquez sur Afficher YAML.
Pour déployer le fichier manifeste avec la configuration recommandée, cliquez sur Déployer. L'opération de déploiement peut prendre plusieurs minutes.
Pour afficher votre déploiement, accédez à la page Kubernetes Engine > Charges de travail.
gcloud
Préparez-vous à charger des modèles depuis votre registre de modèles : le démarrage rapide de l'inférence permet de charger des modèles depuis Hugging Face ou Cloud Storage.
Hugging Face
Si vous n'en avez pas encore, générez un jeton d'accès Hugging Face et un secret Kubernetes correspondant.
Pour créer un secret Kubernetes contenant le jeton Hugging Face, exécutez la commande suivante :
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACERemplacez les valeurs suivantes :
- HUGGING_FACE_TOKEN : jeton Hugging Face que vous avez créé précédemment.
- NAMESPACE : espace de noms Kubernetes dans lequel vous souhaitez déployer votre serveur de modèle.
Certains modèles peuvent également vous demander d'accepter et de signer leur contrat de licence.
Cloud Storage
Vous pouvez charger des modèles compatibles depuis Cloud Storage avec une configuration Cloud Storage FUSE optimisée. Pour ce faire, vous devez d'abord charger le modèle Hugging Face dans votre bucket Cloud Storage.
Vous pouvez déployer ce Job Kubernetes pour transférer le modèle, en remplaçant
MODEL_IDpar le modèle compatible avec le guide de démarrage rapide de l'inférence.Générer des fichiers manifestes : vous disposez des options suivantes pour générer des fichiers manifestes :
- Configuration de base : génère les fichiers manifestes Kubernetes Deployment, Service et PodMonitoring standards pour déployer un serveur d'inférence à réplique unique.
- (Facultatif) Configuration optimisée pour le stockage : génère un fichier manifeste avec une configuration Cloud Storage FUSE ajustée pour charger les modèles à partir d'un bucket Cloud Storage. Vous activez cette configuration à l'aide de l'option
--model-bucket-uri. Une configuration Cloud Storage FUSE optimisée peut multiplier par plus de sept le temps de démarrage des pods LLM. (Facultatif) Configuration optimisée pour l'autoscaling : génère un fichier manifeste avec un autoscaler horizontal de pods (AHP) pour ajuster automatiquement le nombre de répliques du serveur de modèle en fonction du trafic. Pour activer cette configuration, spécifiez une latence cible à l'aide d'indicateurs tels que
--target-ntpot-milliseconds.
Configuration de base
Dans le terminal, utilisez l'option
manifestspour générer les fichiers manifestes Deployment, Service et PodMonitoring :gcloud container ai profiles manifests createUtilisez les paramètres obligatoires
--model,--model-serveret--accelerator-typepour personnaliser votre fichier manifeste.Vous pouvez également définir les paramètres suivants :
--target-ntpot-milliseconds: définissez ce paramètre pour spécifier votre seuil AHP. Ce paramètre vous permet de définir un seuil de scaling pour maintenir la latence NTPOT (Normalized Time Per Output Token) P50, mesurée au 50e centile, en dessous de la valeur spécifiée. Choisissez une valeur supérieure à la latence minimale de votre accélérateur. Le HPA est configuré pour un débit maximal si vous spécifiez une valeur NTPOT supérieure à la latence maximale de votre accélérateur. Exemple :gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: filtre les profils qui dépassent la latence cible du TTFT.--output-path: si cette option est spécifiée, le résultat est enregistré dans le chemin d'accès fourni au lieu d'être imprimé dans le terminal. Vous pouvez ainsi modifier le résultat avant de le déployer. Par exemple, vous pouvez l'utiliser avec l'option--output=manifestsi vous souhaitez enregistrer votre fichier manifeste dans un fichier YAML. Exemple :gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Pour obtenir la liste complète des options que vous pouvez définir, consultez la documentation sur la commande
manifests create.Optimisé pour le stockage
Vous pouvez améliorer le temps de démarrage des pods en chargeant les modèles depuis Cloud Storage à l'aide d'une configuration Cloud Storage FUSE optimisée. Le chargement à partir de Cloud Storage nécessite GKE version 1.29.6-gke.1254000, 1.30.2-gke.1394000 ou ultérieure.
Pour ce faire, procédez comme suit :
- Chargez le modèle depuis le dépôt Hugging Face vers votre bucket Cloud Storage.
Définissez l'indicateur
--model-bucket-urilorsque vous générez votre fichier manifeste. Cette opération configure le modèle pour qu'il se charge à partir d'un bucket Cloud Storage à l'aide du pilote CSI Cloud Storage FUSE. L'URI doit pointer vers le chemin d'accès contenant le fichierconfig.jsonet les pondérations du modèle. Vous pouvez spécifier le chemin d'accès à un répertoire dans le bucket en l'ajoutant à l'URI du bucket.Exemple :
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlRemplacez
BUCKET_NAMEpar le nom de votre bucket Cloud Storage.Avant d'appliquer le fichier manifeste, vous devez exécuter la commande
gcloud storage buckets add-iam-policy-bindingqui se trouve dans les commentaires du fichier manifeste. Cette commande est nécessaire pour autoriser le compte de service GKE à accéder au bucket Cloud Storage à l'aide de la fédération d'identité de charge de travail pour GKE.Si vous prévoyez de mettre à l'échelle votre déploiement sur plusieurs répliques, vous devez choisir l'une des options suivantes pour éviter les erreurs d'écriture simultanée dans le chemin d'accès au cache XLA (
VLLM_XLA_CACHE_PATH) :- Option 1 (recommandée) : Commencez par mettre à l'échelle le déploiement sur une réplique. Attendez que le pod soit prêt, ce qui lui permet d'écrire dans le cache XLA. Ensuite, augmentez le nombre de réplicas souhaité. Les réplicas suivants liront à partir du cache rempli sans conflits d'écriture.
- Option 2 : Supprimez complètement la variable d'environnement
VLLM_XLA_CACHE_PATHdu fichier manifeste. Cette approche est plus simple, mais elle désactive la mise en cache pour toutes les répliques.
Sur les types d'accélérateurs TPU, ce chemin de cache est utilisé pour stocker le cache de compilation XLA, ce qui accélère la préparation du modèle pour les déploiements répétés.
Pour obtenir d'autres conseils sur l'amélioration des performances, consultez Optimiser les performances du pilote CSI Cloud Storage FUSE pour GKE.
Optimisé pour l'autoscaling
Vous pouvez configurer l'autoscaler horizontal de pods (AHP) pour qu'il ajuste automatiquement le nombre de répliques du serveur de modèle en fonction de la charge. Cela permet à vos serveurs de modèles de gérer efficacement les charges variables en augmentant ou en diminuant la capacité selon les besoins. La configuration HPA suit les bonnes pratiques d'autoscaling des guides GPU et TPU.
Pour inclure des configurations AHP lors de la génération de fichiers manifestes, utilisez une ou les deux options
--target-ntpot-millisecondset--target-ttft-milliseconds. Ces paramètres définissent un seuil de scaling pour le AHP afin de maintenir la latence P50 pour NTPOT ou TTFT en dessous de la valeur spécifiée. Si vous ne définissez qu'un seul de ces indicateurs, seule cette métrique sera prise en compte pour le scaling.Choisissez une valeur supérieure à la latence minimale de votre accélérateur. Le HPA est configuré pour un débit maximal si vous spécifiez une valeur supérieure à la latence maximale de votre accélérateur.
Exemple :
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Créer un cluster : vous pouvez diffuser votre modèle sur des clusters GKE Autopilot ou Standard. Nous vous recommandons d'utiliser un cluster Autopilot pour une expérience Kubernetes entièrement gérée. Pour choisir le mode de fonctionnement GKE le mieux adapté à vos charges de travail, consultez la section Choisir un mode de fonctionnement GKE.
Si vous n'avez pas de cluster existant, procédez comme suit :
Autopilot
Suivez ces instructions pour créer un cluster Autopilot. GKE gère le provisionnement des nœuds avec une capacité de GPU ou de TPU en fonction des fichiers manifestes de déploiement, si vous disposez du quota nécessaire dans votre projet.
Standard
- Créez un cluster zonal ou régional.
Créez un pool de nœuds avec les accélérateurs appropriés. Suivez ces étapes en fonction du type d'accélérateur choisi :
- GPU : commencez par consulter la page Quotas dans la console Google Cloud pour vous assurer que vous disposez d'une capacité de GPU suffisante. Suivez ensuite les instructions de la section Créer un pool de nœuds GPU.
- TPU : tout d'abord, assurez-vous de disposer de suffisamment de TPU en suivant les instructions de la section Garantir un quota pour les TPU et les autres ressources GKE. Ensuite, créez un pool de nœuds TPU.
(Facultatif, mais recommandé) Activez les fonctionnalités d'observabilité : dans la section des commentaires du fichier manifeste généré, des commandes supplémentaires sont fournies pour activer les fonctionnalités d'observabilité suggérées. L'activation de ces fonctionnalités fournit plus d'insights pour vous aider à surveiller les performances et l'état des charges de travail et de l'infrastructure sous-jacente.
Voici un exemple de commande permettant d'activer les fonctionnalités d'observabilité :
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLPour en savoir plus, consultez Surveiller vos charges de travail d'inférence.
(AHP uniquement) Déployez un adaptateur de métriques : un adaptateur de métriques, tel que l'adaptateur de métriques personnalisées Stackdriver, est nécessaire si des ressources AHP ont été générées dans les manifestes de déploiement. L'adaptateur de métriques permet à AHP d'accéder aux métriques du serveur de modèle qui utilisent l'API kube external metrics. Pour déployer l'adaptateur, consultez la documentation de l'adaptateur sur GitHub.
Déployez les fichiers manifestes : exécutez la commande
kubectl applyet transmettez le fichier YAML pour vos fichiers manifestes. Exemple :kubectl apply -f ./manifests.yaml
Tester les points de terminaison de votre déploiement
Si vous avez déployé le fichier manifeste, le service déployé est exposé au point de terminaison suivant :
http://model-model_server-service:8000/
Le serveur de modèles, tel que vLLM, écoute généralement sur le port 8000.
Pour tester votre déploiement, vous devez configurer le transfert de port. Exécutez la commande suivante dans un terminal distinct :
kubectl port-forward service/model-model_server-service 8000:8000
Pour obtenir des exemples de création et d'envoi d'une requête à votre point de terminaison, consultez la documentation vLLM.
Gestion des versions du fichier manifeste
Le guide de démarrage rapide de l'inférence fournit les derniers fichiers manifestes validés sur les versions récentes des clusters GKE. Le fichier manifeste renvoyé pour un profil peut changer au fil du temps afin que vous receviez une configuration optimisée lors du déploiement. Si vous avez besoin d'un fichier manifeste stable, enregistrez-le et stockez-le séparément.
Le fichier manifeste inclut des commentaires et une annotation recommender.ai.gke.io/version au format suivant :
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
L'annotation précédente présente les valeurs suivantes :
- DATE : date de génération du fichier manifeste.
- CLUSTER_VERSION : version du cluster GKE utilisée pour la validation.
- NODE_VERSION : version du nœud GKE utilisée pour la validation.
- GPU_DRIVER_VERSION : (GPU uniquement) version du pilote de GPU utilisée pour la validation.
- MODEL_SERVER : serveur de modèle utilisé dans le fichier manifeste.
- MODEL_SERVER_VERSION : version du serveur de modèle utilisée dans le fichier manifeste.
Surveiller vos charges de travail d'inférence
Pour surveiller vos charges de travail d'inférence déployées, accédez à l'explorateur de métriques dans la console Google Cloud .
Activer la surveillance automatique
GKE inclut une fonctionnalité de surveillance automatique qui fait partie des fonctionnalités d'observabilité plus larges. Cette fonctionnalité analyse le cluster à la recherche de charges de travail qui s'exécutent sur des serveurs de modèles compatibles et déploie les ressources PodMonitoring qui permettent d'afficher les métriques de ces charges de travail dans Cloud Monitoring. Pour en savoir plus sur l'activation et la configuration de l'autosurveillance, consultez Configurer la surveillance automatique des applications pour les charges de travail.
Une fois la fonctionnalité activée, GKE installe des tableaux de bord prédéfinis pour surveiller les applications pour les charges de travail compatibles.
Si vous effectuez le déploiement à partir de la page "IA/ML GKE" de la console Google Cloud , les ressources PodMonitoring et AHP sont créées automatiquement pour vous à l'aide de la configuration targetNtpot.
Dépannage
- Si vous définissez une latence trop faible, le guide de démarrage rapide de l'inférence risque de ne pas générer de recommandation. Pour résoudre ce problème, sélectionnez une latence cible comprise entre la latence minimale et maximale observée pour les accélérateurs sélectionnés.
- Le guide de démarrage rapide pour l'inférence existe indépendamment des composants GKE. La version de votre cluster n'a donc pas d'incidence directe sur l'utilisation du service. Toutefois, nous vous recommandons d'utiliser un cluster récent ou à jour pour éviter toute divergence de performances.
- Si vous obtenez une erreur
PERMISSION_DENIEDpour les commandesgkerecommender.googleapis.comindiquant qu'un projet de quota est manquant, vous devez le définir manuellement. Exécutezgcloud config set billing/quota_project PROJECT_IDpour résoudre ce problème.
Pod évincé en raison d'un stockage éphémère insuffisant
Lorsque vous déployez un grand modèle (90 Gio ou plus) à partir de Hugging Face, votre pod peut être expulsé et un message d'erreur semblable à celui-ci peut s'afficher :
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Cette erreur se produit, car le modèle est mis en cache sur le disque de démarrage du nœud, une forme de stockage éphémère. Le disque de démarrage est utilisé pour le stockage éphémère lorsque le fichier manifeste de déploiement ne définit pas la variable d'environnement HF_HOME sur un répertoire de la RAM du nœud.
- Par défaut, les nœuds GKE disposent d'un disque de démarrage de 100 Gio.
- GKE réserve 10 % du disque de démarrage pour les frais généraux du système, ce qui laisse 90 Gio pour vos charges de travail.
- Si la taille du modèle est de 90 Gio ou plus et qu'il est exécuté sur un disque de démarrage de taille par défaut, kubelet évince le pod pour libérer de l'espace de stockage éphémère.
Pour résoudre ce problème, choisissez l'une des options suivantes :
- Utiliser la RAM pour la mise en cache des modèles : dans votre fichier manifeste de déploiement, définissez la variable d'environnement
HF_HOMEsur/dev/shm/hf_cache. La RAM du nœud est utilisée pour mettre en cache le modèle au lieu du disque de démarrage. - Augmenter la taille du disque de démarrage :
- GKE Standard : augmentez la taille du disque de démarrage lorsque vous créez un cluster, créez un pool de nœuds ou mettez à jour un pool de nœuds.
- Autopilot : pour demander un disque de démarrage plus grand, créez une classe de calcul personnalisée et définissez le champ
bootDiskSizedans la règlemachineType.
Le pod entre dans une boucle de plantage lors du chargement de modèles depuis Cloud Storage
Après avoir déployé un fichier manifeste généré avec l'indicateur --model-bucket-uri, le déploiement peut se bloquer et le pod passe à l'état CrashLoopBackOff.
La vérification des journaux du conteneur inference-server peut afficher une erreur trompeuse, telle que huggingface_hub.errors.HFValidationError. Exemple :
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Cette erreur se produit généralement lorsque le chemin Cloud Storage fourni dans l'indicateur --model-bucket-uri est incorrect. Le serveur d'inférence, tel que vLLM, ne trouve pas les fichiers de modèle requis (comme config.json) au niveau du chemin d'accès installé.
S'il ne parvient pas à trouver les fichiers locaux, le serveur suppose que le chemin d'accès est un ID de dépôt Hugging Face Hub. Comme le chemin d'accès n'est pas un ID de dépôt valide, le serveur échoue avec une erreur de validation et entre dans une boucle de plantage.
Pour résoudre ce problème, vérifiez que le chemin d'accès que vous avez fourni à l'indicateur --model-bucket-uri pointe vers le répertoire exact de votre bucket Cloud Storage qui contient le fichier config.json du modèle et tous les poids de modèle associés.
Étapes suivantes
- Consultez le portail d'orchestration d'IA/ML sur GKE pour explorer nos guides officiels, nos tutoriels et nos cas d'utilisation pour exécuter des charges de travail d'IA/ML sur GKE.
- Pour en savoir plus sur l'optimisation de la diffusion de modèles, consultez Bonnes pratiques pour optimiser l'inférence de grands modèles de langage avec des GPU. Il couvre les bonnes pratiques pour la diffusion de LLM avec des GPU sur GKE, comme la quantification, le parallélisme de tenseur et la gestion de la mémoire.
- Pour en savoir plus sur les bonnes pratiques concernant l'autoscaling, consultez les guides suivants :
- Pour en savoir plus sur les bonnes pratiques de stockage, consultez Optimiser les performances du pilote CSI Cloud Storage FUSE pour GKE.
- Explorez des exemples expérimentaux pour exploiter GKE et accélérer vos initiatives d'IA/ML dans GKE AI Labs.