本頁面說明如何使用 GKE Inference Quickstart,簡化在 Google Kubernetes Engine (GKE) 上部署 AI/機器學習推論工作負載的程序。Inference Quickstart 是一項公用程式,可讓您指定推論業務需求,並根據最佳做法和 Google 的模型、模型伺服器、加速器 (GPU、TPU)、擴充和儲存空間基準,取得最佳化的 Kubernetes 設定。這有助於避免耗時的手動調整和測試設定程序。
本頁內容適用於機器學習 (ML) 工程師、平台管理員和營運人員,以及想要瞭解如何有效管理及最佳化 GKE,以進行 AI/ML 推論的資料和 AI 專家。如要進一步瞭解我們在內容中提及的常見角色和範例工作,請參閱「常見的 GKE 使用者角色和工作」。 Google Cloud
如要進一步瞭解模型服務概念和術語,以及 GKE Gen AI 功能如何提升及支援模型服務效能,請參閱「關於 GKE 的模型推論功能」。
閱讀本頁面之前,請先熟悉 Kubernetes、GKE 和模型服務。
使用推論快速入門導覽課程
您可以透過「推論快速入門」分析推論工作負載的效能和成本效益,並根據資料做出資源分配和模型部署策略的決策。
使用 Inference Quickstart 的高階步驟如下:
分析效能和成本:探索可用設定,並根據效能和成本需求使用
gcloud container ai profiles list指令篩選設定。如要查看特定設定的完整基準化資料集,請使用gcloud container ai profiles benchmarks list指令。這項指令可協助您根據特定效能需求,找出最具成本效益的硬體。部署資訊清單:分析完成後,您可以產生最佳化的 Kubernetes 資訊清單並加以部署。您可以選擇啟用儲存空間和自動調度資源最佳化功能。您可以從 Google Cloud 控制台部署,也可以使用
kubectl apply指令部署。部署前,請務必確認 Google Cloud 專案中,所選 GPU 或 TPU 的加速器配額充足。(選用) 執行自己的基準測試: 提供的設定和效能資料是以使用 ShareGPT 資料集的基準測試為依據。工作負載的效能可能與這個基準有所不同。如要評估模型在各種條件下的效能,可以使用實驗性推論基準測試工具。
優點
推論快速入門可提供最佳化設定,協助您節省時間和資源。這些最佳化措施可透過下列方式提升效能及降低基礎架構成本:
- 您會收到詳細的專屬最佳做法,瞭解如何設定加速器 (GPU 和 TPU)、模型伺服器和縮放設定。GKE 會定期更新 Inference Quickstart,提供最新的修正內容、映像檔和效能基準。
- 您可以使用Google Cloud 控制台 UI 或指令列介面,指定工作負載的延遲和輸送量需求,並取得詳細的量身打造最佳做法,做為 Kubernetes 部署資訊清單。
運作方式
推論快速入門指南會根據 Google 對模型、模型伺服器和加速器拓撲組合的單一副本效能進行的詳盡內部基準測試,提供量身打造的最佳做法。這些基準圖表會繪製延遲與輸送量,包括佇列大小和 KV 快取指標,並為每種組合繪製效能曲線。
如何產生專屬最佳做法
我們會讓加速器達到飽和,並以毫秒為單位,測量每個輸出權杖的正規化時間 (NTPOT) 和第一個權杖的生成時間 (TTFT),以及以每秒輸出權杖數為單位,測量處理量。如要進一步瞭解這些成效指標,請參閱「關於 GKE 上的模型推論」。
以下延遲設定檔範例說明瞭輸送量達到平穩狀態的轉折點 (綠色)、延遲惡化的轉折點後狀態 (紅色),以及在延遲目標下達到最佳輸送量的理想區域 (藍色)。推論快速入門指南會提供這個理想區域的效能資料和設定。
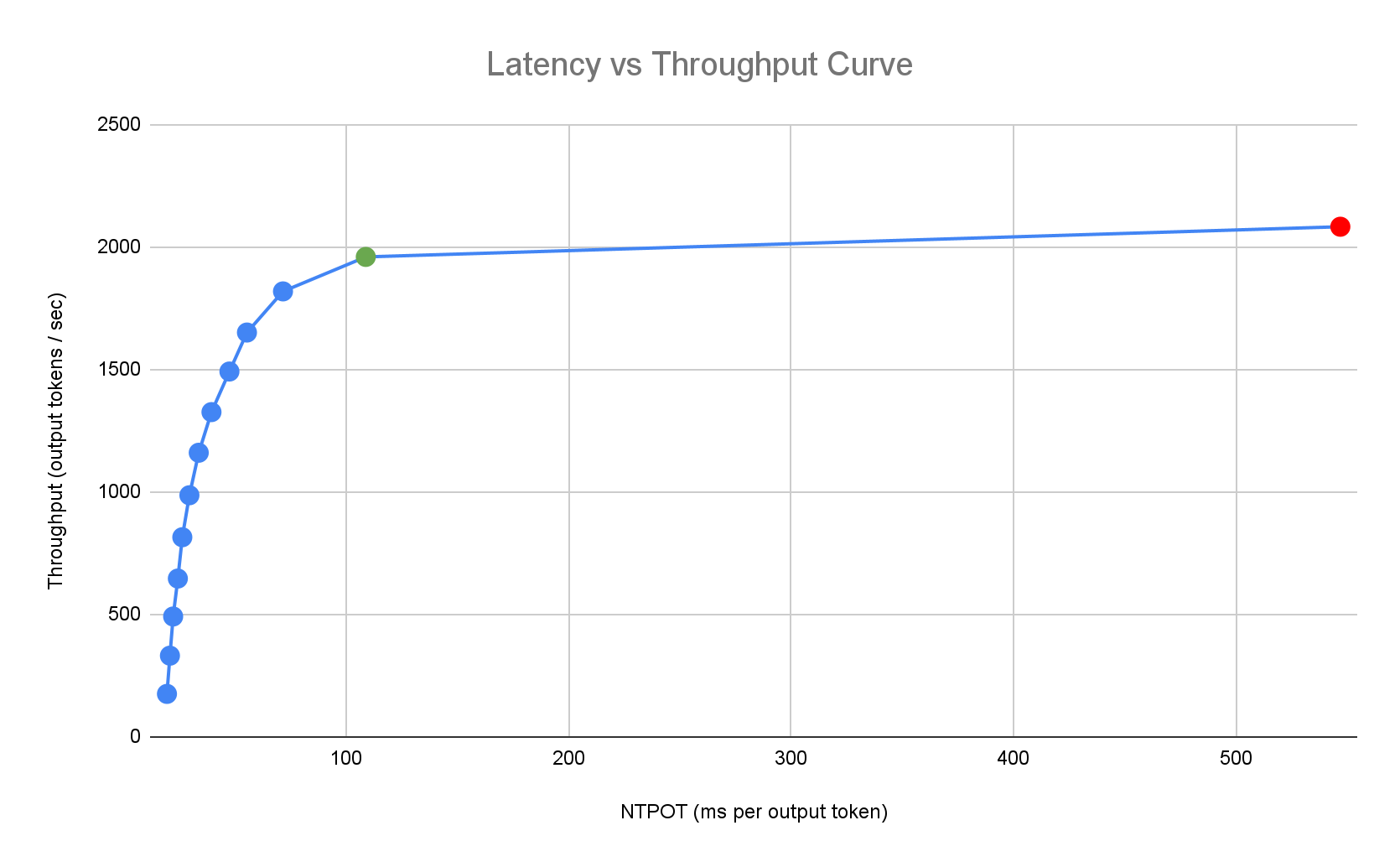
Inference Quickstart 會根據推論應用程式的延遲時間需求,找出合適的組合,並在延遲時間與處理量曲線中,找出最佳運作點。這個點會設定水平 Pod 自動配置器 (HPA) 門檻,並提供緩衝區來因應擴充延遲。整體閾值也會提供所需副本的初始數量,但 HPA 會根據工作負載動態調整這個數量。
費用計算
如要計算費用,Inference Quickstart 會使用可設定的輸出與輸入成本比率。舉例來說,如果將這個比率設為 4,系統會假設每個輸出權杖的費用是輸入權杖的四倍。下列方程式可用於計算每權杖成本指標:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
其中
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
基準化
提供的設定和成效資料是以基準為準,這些基準使用 ShareGPT 資料集傳送流量,並採用下列輸入和輸出分配方式。
| 輸入權杖 | 輸出權杖 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小值 | 中位數 | 平均值 | P90 | 第 99 個百分位數 | 最大值 | 最小值 | 中位數 | 平均值 | P90 | 第 99 個百分位數 | 最大值 |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
事前準備
開始之前,請確認您已完成下列工作:
- 啟用 Google Kubernetes Engine API。 啟用 Google Kubernetes Engine API
- 如要使用 Google Cloud CLI 執行這項工作,請安裝並初始化 gcloud CLI。如果您先前已安裝 gcloud CLI,請執行
gcloud components update指令,取得最新版本。較舊的 gcloud CLI 版本可能不支援執行本文件中的指令。
在 Google Cloud 控制台的專案選擇器頁面中,選取或建立 Google Cloud 專案。
請確認專案的加速器容量充足:
- 如果您使用 GPU:請查看「配額」頁面。
- 如果使用 TPU:請參閱「確保 TPU 和其他 GKE 資源的配額」。
準備使用 GKE AI/ML 使用者介面
如果您使用 Google Cloud 控制台,也需要建立 Autopilot 叢集 (如果專案中尚未建立)。按照「建立 Autopilot 叢集」一文中的指示操作。
準備使用指令列介面
如果您使用 gcloud CLI 執行 Inference Quickstart,也需要執行下列額外指令:
啟用
gkerecommender.googleapis.comAPI:gcloud services enable gkerecommender.googleapis.com設定用於 API 呼叫的帳單配額專案:
gcloud config set billing/quota_project PROJECT_ID確認 gcloud CLI 版本至少為 536.0.1。如果沒有,請執行下列指令:
gcloud components update
限制
開始使用 Inference Quickstart 之前,請注意下列限制:
- Google Cloud 控制台模型部署僅支援部署至 Autopilot 叢集。
- Inference Quickstart 不會為特定模型伺服器支援的所有模型提供設定檔。
- 如果您使用從 Hugging Face 產生的大型模型 (90 GiB 以上) 資訊清單,但未設定
HF_HOME環境變數,則必須使用開機磁碟大於預設值的叢集,或修改資訊清單將HF_HOME設為/dev/shm/hf_cache。這會使用 RAM 做為快取,而不是節點的開機磁碟。詳情請參閱「疑難排解」一節。 - 從 Cloud Storage 載入模型僅支援部署至已啟用 Cloud Storage FUSE CSI 驅動程式和 GKE 適用的 Workload Identity Federation 的叢集,這兩者在 Autopilot 叢集中預設都會啟用。詳情請參閱「為 GKE 設定 Cloud Storage FUSE CSI 驅動程式」。
分析及查看模型推論的最佳化設定
本節說明如何使用 Google Cloud CLI 探索及分析設定建議。
使用 gcloud container ai profiles 指令探索及分析最佳化設定檔 (模型、模型伺服器、模型伺服器版本和加速器的組合):
模型
如要探索及選取模型,請使用 models 選項。
gcloud container ai profiles models list
設定檔
使用 list 指令探索產生的設定檔,並根據成效和費用需求進行篩選。例如:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
輸出內容會顯示支援的設定檔,以及輸送量、延遲時間和每個百萬個權杖的費用等成效指標。類似以下範例:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
這些值代表在特定設定檔使用這類加速器時,輸送量停止增加,而延遲時間開始大幅增加 (即轉折點或飽和點) 時的觀察效能。如要進一步瞭解這些成效指標,請參閱「關於 GKE 的模型推論功能」。
如需可設定的完整旗標清單,請參閱 list 指令說明文件。
所有價格資訊僅以美元提供,且預設為 us-east5 區域,但使用 A3 機器時,預設為 us-central1 區域。
基準
如要取得特定設定檔的所有基準化資料,請使用 benchmarks list 指令。
例如:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
輸出內容包含在不同要求速率下執行的基準測試所產生的效能指標清單。
這個指令會以 CSV 格式顯示輸出內容。如要將輸出內容儲存為檔案,請使用輸出重新導向。例如 gcloud container ai profiles benchmarks list > profiles.csv。
如需可設定的完整旗標清單,請參閱 benchmarks list 指令說明文件。
選擇模型、模型伺服器、模型伺服器版本和加速器後,即可繼續建立部署資訊清單。
部署建議設定
本節說明如何使用 Google Cloud 主控台或指令列,產生及部署設定建議。
控制台
- 前往 Google Cloud 控制台的 GKE AI/ML 頁面。
- 按一下「Deploy Models」(部署模型)。
選取要部署的模型。Inference Quickstart 支援的模型會顯示「已最佳化」標記。
- 如果您選取基礎模型,系統會開啟模型頁面。按一下「Deploy」(部署)。 實際部署前,您仍可修改設定。
- 如果專案中沒有 Autopilot 叢集,系統會提示您建立一個。按照「建立 Autopilot 叢集」一文中的指示操作。 建立叢集後,返回 Google Cloud 控制台的 GKE AI/ML 頁面,選取模型。
模型部署頁面會預先填入您選取的模型,以及建議的模型伺服器和加速器。您也可以設定延遲時間上限和模型來源等設定。
(選用) 如要查看含有建議設定的資訊清單,請按一下「查看 YAML」。
如要部署採用建議設定的資訊清單,請按一下「部署」。 部署作業可能需要幾分鐘才能完成。
如要查看部署作業,請前往「Kubernetes Engine」>「工作負載」頁面。
gcloud
準備從模型登錄檔載入模型:推論快速入門支援從 Hugging Face 或 Cloud Storage 載入模型。
Hugging Face
如果沒有,請產生 Hugging Face 存取權杖和對應的 Kubernetes Secret。
如要建立包含 Hugging Face 權杖的 Kubernetes Secret,請執行下列指令:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACE替換下列值:
- HUGGING_FACE_TOKEN:先前建立的 Hugging Face 權杖。
- NAMESPACE:要部署模型伺服器的 Kubernetes 命名空間。
部分模型可能還會要求您接受並簽署同意授權協議。
Cloud Storage
您可以透過經過調整的 Cloud Storage FUSE 設定,從 Cloud Storage 載入支援的模型。如要這麼做,請先將 Hugging Face 的模型載入至 Cloud Storage 值區。
您可以部署這個 Kubernetes Job 來轉移模型,並將
MODEL_ID變更為 Inference Quickstart 支援的模型。產生資訊清單:您可以透過下列方式產生資訊清單:
- 基本設定:產生標準 Kubernetes Deployment、Service 和 PodMonitoring 資訊清單,用於部署單一副本推論伺服器。
- (選用) 儲存空間最佳化設定:產生資訊清單,並調整 Cloud Storage FUSE 設定,從 Cloud Storage 值區載入模型。使用
--model-bucket-uri旗標啟用這項設定。經過調整的 Cloud Storage FUSE 設定可將 LLM Pod 啟動時間縮短 7 倍以上。 (選用) 自動調度資源最佳化設定:產生含有水平 Pod 自動調度資源 (HPA) 的資訊清單,根據流量自動調整模型伺服器副本數量。如要啟用這項設定,請使用
--target-ntpot-milliseconds等旗標指定延遲目標。
基礎設定
在終端機中使用
manifests選項,產生 Deployment、Service 和 PodMonitoring 資訊清單:gcloud container ai profiles manifests create使用必要的
--model、--model-server和--accelerator-type參數自訂資訊清單。您也可以選擇設定下列參數:
--target-ntpot-milliseconds:設定這個參數可指定 HPA 門檻。這個參數可讓您定義縮放門檻,將以第 50 個百分位數測量的每個輸出權杖正規化時間 (NTPOT) P50 延遲時間維持在指定值以下。選擇的值必須高於加速器的最低延遲時間。如果指定的 NTPOT 值高於加速器的最長延遲時間,HPA 會設為最大輸送量。例如:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds:篩除超過 TTFT 延遲目標的設定檔。--output-path:如果指定這個參數,輸出內容會儲存到提供的路徑,而不是列印到終端機,因此您可以在部署前編輯輸出內容。舉例來說,如要將資訊清單儲存為 YAML 檔案,可以搭配使用這個選項和--output=manifest。例如:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
如需可設定的完整旗標清單,請參閱
manifests create指令說明文件。儲存空間最佳化
您可以透過經過調整的 Cloud Storage FUSE 設定,從 Cloud Storage 載入模型,縮短 Pod 啟動時間。從 Cloud Storage 載入資料時,需要使用 GKE 1.29.6-gke.1254000、1.30.2-gke.1394000 以上版本
詳細步驟如下:
- 將模型從 Hugging Face 存放區載入 Cloud Storage bucket。
產生資訊清單時,請設定
--model-bucket-uri標記。 這會設定模型,透過 Cloud Storage FUSE CSI 驅動程式從 Cloud Storage bucket 載入。URI 必須指向包含模型config.json檔案和權重的路徑。如要指定值區內的目錄路徑,請將該路徑附加至值區 URI。例如:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yaml請將
BUCKET_NAME改成您 Cloud Storage 值區的名稱。套用資訊清單前,請務必執行資訊清單註解中的
gcloud storage buckets add-iam-policy-binding指令。您必須執行這項指令,才能使用 GKE 適用的 Workload Identity Federation,授予 GKE 服務帳戶存取 Cloud Storage bucket 的權限。如果您打算將 Deployment 擴充至多個副本,請務必選擇下列其中一個選項,避免對 XLA 快取路徑 (
VLLM_XLA_CACHE_PATH) 發生並行寫入錯誤:- 方法 1 (建議):首先,將 Deployment 擴充至 1 個副本。等待 Pod 準備就緒,以便寫入 XLA 快取。然後將備用資源擴充至所需數量。後續副本會從已填入的快取讀取資料,不會發生寫入衝突。
- 方法 2:從資訊清單中完全移除
VLLM_XLA_CACHE_PATH環境變數。這種做法較簡單,但會停用所有副本的快取。
在 TPU 加速器類型上,這個快取路徑用於儲存 XLA 編譯快取,可加快模型準備速度,以利重複部署。
如需更多提升效能的提示,請參閱「針對 GKE 效能最佳化 Cloud Storage FUSE CSI 驅動程式」。
自動調度資源最佳化
您可以設定水平 Pod 自動調度器 (HPA),根據負載自動調整模型伺服器副本數量。這有助於模型伺服器視需要調度資源,有效處理不同負載。HPA 設定遵循 GPU 和 TPU 指南的自動調度資源最佳做法。
如要在產生資訊清單時加入 HPA 設定,請使用
--target-ntpot-milliseconds和--target-ttft-milliseconds旗標。這些參數會定義 HPA 的調整門檻,讓 NTPOT 或 TTFT 的 P50 延遲時間低於指定值。如果您只設定其中一個旗標,系統只會將該指標納入調度資源考量。選擇的值必須高於加速器的最低延遲時間。如果您指定的值高於加速器的最高延遲時間,HPA 會設定為最高輸送量。
例如:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250建立叢集:您可以在 GKE Autopilot 或標準叢集上提供模型服務。建議您使用 Autopilot 叢集,享有全代管 Kubernetes 體驗。如要選擇最適合工作負載的 GKE 作業模式,請參閱「選擇 GKE 作業模式」。
如果沒有現有叢集,請按照下列步驟操作:
Autopilot
請按照這些操作說明建立 Autopilot 叢集。如果專案有足夠的配額,GKE 會根據部署資訊清單,佈建具有 GPU 或 TPU 容量的節點。
標準
- 建立區域性或地區性叢集。
建立具有適當加速器的節點集區。請根據所選的加速器類型,按照下列步驟操作:
- GPU:首先,請查看 Google Cloud 控制台的「配額」頁面,確保您有足夠的 GPU 容量。然後按照「建立 GPU 節點集區」中的操作說明執行。
- TPU:首先,請按照「確保 TPU 和其他 GKE 資源的配額」一文中的操作說明,確認您有足夠的 TPU。然後繼續建立 TPU 節點集區。
(建議選用) 啟用可觀測性功能:在產生的資訊清單註解部分,系統會提供額外指令,啟用建議的可觀測性功能。啟用這些功能可提供更多洞察資料,協助您監控工作負載和基礎架構的效能與狀態。
以下是啟用可觀測性功能的指令範例:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALL詳情請參閱「監控推論工作負載」。
(僅限 HPA) 部署指標轉接器:如果部署資訊清單中產生了 HPA 資源,則必須使用指標轉接器,例如自訂指標 Stackdriver 轉接器。指標介面卡可讓 HPA 存取使用 kube 外部指標 API 的模型伺服器指標。如要部署轉接程式,請參閱 GitHub 上的轉接程式說明文件。
部署資訊清單:執行
kubectl apply指令,並傳遞資訊清單的 YAML 檔案。例如:kubectl apply -f ./manifests.yaml
測試部署端點
如果您已部署資訊清單,部署的服務會公開至下列端點:
http://model-model_server-service:8000/
模型伺服器 (例如 vLLM) 通常會監聽通訊埠 8000。
如要測試部署作業,請設定通訊埠轉送。在另一個終端機中執行下列指令:
kubectl port-forward service/model-model_server-service 8000:8000
如需瞭解如何建構及傳送端點要求,請參閱 vLLM 說明文件。
資訊清單版本管理
推論快速入門導覽課程提供最新資訊清單,這些資訊清單已在近期的 GKE 叢集版本上經過驗證。系統可能會隨時間變更設定檔傳回的資訊清單,確保您在部署時獲得最佳化設定。如需穩定版資訊清單,請另外儲存。
資訊清單包含註解和 recommender.ai.gke.io/version 註解,格式如下:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
先前的註解具有下列值:
- DATE:產生資訊清單的日期。
- CLUSTER_VERSION:用於驗證的 GKE 叢集版本。
- NODE_VERSION:用於驗證的 GKE 節點版本。
- GPU_DRIVER_VERSION:(僅限 GPU) 用於驗證的 GPU 驅動程式版本。
- MODEL_SERVER:資訊清單中使用的模型伺服器。
- MODEL_SERVER_VERSION:資訊清單中使用的模型伺服器版本。
監控推論工作負載
如要監控已部署的推論工作負載,請前往 Google Cloud 控制台的「指標探索器」。
啟用自動監控
GKE 包含自動監控功能,這是廣泛可觀測性功能的一部分。這項功能會掃描叢集,找出在支援的機型伺服器上執行的工作負載,並部署 PodMonitoring 資源,讓這些工作負載指標顯示在 Cloud Monitoring 中。如要進一步瞭解如何啟用及設定自動監控功能,請參閱「為工作負載設定自動應用程式監控功能」。
啟用這項功能後,GKE 會安裝預先建構的資訊主頁,用於監控支援的工作負載應用程式。
如果您從 Google Cloud 控制台的 GKE AI/ML 頁面部署,系統會使用 targetNtpot 設定,自動為您建立 PodMonitoring 和 HPA 資源。
疑難排解
- 如果延遲時間設得太短,Inference Quickstart 可能無法產生建議。 如要修正這個問題,請選取所選加速器觀察到的最低和最高延遲時間之間的延遲時間目標。
- 推論快速入門導覽課程獨立於 GKE 元件,因此叢集版本與使用這項服務沒有直接關係。不過,建議使用最新或最新的叢集,以免成效出現差異。
- 如果
gkerecommender.googleapis.com指令出現PERMISSION_DENIED錯誤,指出缺少配額專案,您必須手動設定。請執行gcloud config set billing/quota_project PROJECT_ID修正這個問題。
臨時儲存空間不足,因此 Pod 已遭驅逐
從 Hugging Face 部署大型模型 (90 GiB 以上) 時,Pod 可能會遭到逐出,並顯示類似以下的錯誤訊息:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
發生這個錯誤的原因是,模型會快取在節點的開機磁碟上,這是一種暫時性儲存空間。如果部署資訊清單未將 HF_HOME 環境變數設為節點 RAM 中的目錄,系統就會使用開機磁碟做為暫時性儲存空間。
- 根據預設,GKE 節點的開機磁碟為 100 GiB。
- GKE 會保留 10% 的開機磁碟空間做為系統負荷,因此工作負載可用的空間為 90 GiB。
- 如果模型大小為 90 GiB 以上,且在預設大小的開機磁碟上執行,kubelet 會撤銷 Pod,以釋出臨時儲存空間。
如要解決這個問題,請選擇下列任一做法:
- 使用 RAM 進行模型快取:在部署資訊清單中,將
HF_HOME環境變數設為/dev/shm/hf_cache。這會使用節點的 RAM 快取模型,而非開機磁碟。 - 增加開機磁碟大小:
- GKE Standard:在建立叢集、建立節點集區或更新節點集區時,增加開機磁碟大小。
- Autopilot:如要要求更大的開機磁碟,請建立自訂 Compute 類別,並在
machineType規則中設定bootDiskSize欄位。
從 Cloud Storage 載入模型時,Pod 進入當機迴圈
使用 --model-bucket-uri 旗標產生資訊清單並部署後,Deployment 可能會停滯,Pod 則會進入 CrashLoopBackOff 狀態。檢查 inference-server 容器的記錄時,可能會看到誤導性錯誤,例如 huggingface_hub.errors.HFValidationError。例如:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
如果 --model-bucket-uri 旗標中提供的 Cloud Storage 路徑有誤,通常就會發生這個錯誤。推論伺服器 (例如 vLLM) 無法在掛接路徑中找到必要模型檔案 (例如 config.json)。如果找不到本機檔案,伺服器會改為假設路徑是 Hugging Face Hub 存放區 ID。由於路徑不是有效的存放區 ID,伺服器會因驗證錯誤而失敗,並進入當機迴圈。
如要解決這個問題,請確認您提供給 --model-bucket-uri 旗標的路徑,指向 Cloud Storage bucket 中包含模型 config.json 檔案和所有相關模型權重的確切目錄。
後續步驟
- 請前往 GKE 中的 AI/機器學習自動化調度管理入口網站,查看在 GKE 上執行 AI/機器學習工作負載的官方指南、教學課程和用途。
- 如要進一步瞭解模型服務最佳化,請參閱使用 GPU 最佳化大型語言模型推論的最佳做法。內容涵蓋在 GKE 上使用 GPU 提供 LLM 服務的最佳做法,例如量化、張量平行處理和記憶體管理。
- 如要進一步瞭解自動調度資源的最佳做法,請參閱下列指南:
- 如需儲存空間最佳做法的相關資訊,請參閱「針對 GKE 效能最佳化 Cloud Storage FUSE CSI 驅動程式」。
- 在 GKE AI Labs 中探索實驗性範例,瞭解如何運用 GKE 加速 AI/機器學習計畫。