This page describes how you can use GKE Inference Quickstart to simplify the deployment of AI/ML inference workloads on Google Kubernetes Engine (GKE). Inference Quickstart is a utility that lets you specify your inference business requirements and get optimized Kubernetes configurations based on best practices and Google's benchmarks for models, model servers, accelerators (GPUs, TPUs), scaling, and storage. This helps you avoid the time-consuming process of manually adjusting and testing configurations.
This page is for Machine learning (ML) engineers, Platform admins and operators, and for Data and AI specialists who want to understand how to efficiently manage and optimize GKE for AI/ML inference. To learn more about common roles and example tasks that we reference in Google Cloud content, see Common GKE user roles and tasks.
To learn more about model serving concepts and terminology, and how GKE Gen AI capabilities can enhance and support your model serving performance, see About model inference on GKE.
Before reading this page, ensure you're familiar with Kubernetes, GKE, and model serving.
Using Inference Quickstart
Inference Quickstart lets you analyze the performance and cost-efficiency of your inference workloads, and make data-driven decisions about resource allocation and model deployment strategies.
The high-level steps to use Inference Quickstart are as follows:
Analyze performance and cost: explore available configurations and filter them based on your performance and cost requirements, by using the
gcloud container ai profiles listcommand. To view the complete set of benchmarking data for a specific configuration, use thegcloud container ai profiles benchmarks listcommand. This command lets you identify the most cost-effective hardware for your specific performance requirements.Deploy manifests: after your analysis, you can generate an optimized Kubernetes manifest and deploy it. You can optionally enable optimizations for storage and autoscaling. You can deploy from the Google Cloud console or by using the
kubectl applycommand. Before you deploy, you must ensure you have sufficient accelerator quota for the selected GPUs or TPUs in your Google Cloud project.(Optional) Run your own benchmarks: the provided configurations and performance data are based on benchmarks that use the ShareGPT dataset. Performance for your workloads might vary from this baseline. To measure your model's performance under various conditions, you can use the experimental inference-benchmark tool.
Benefits
Inference Quickstart helps you save time and resources by providing optimized configurations. These optimizations improve performance and reduce infrastructure costs, in the following ways:
- You receive detailed tailored best practices for setting the accelerator (GPU and TPU), model server, and scaling configurations. GKE routinely updates Inference Quickstart with the latest fixes, images, and performance benchmarks.
- You can specify your workload's latency and throughput requirements by using the Google Cloud console UI or a command-line interface, and get detailed tailored best practices as Kubernetes deployment manifests.
How it works
Inference Quickstart provides tailored best practices based on Google's exhaustive internal benchmarks of single-replica performance for model, model server, and accelerator topology combinations. These benchmarks graph latency versus throughput, including queue size and KV cache metrics, which map out performance curves for each combination.
How tailored best practices are generated
We measure latency in Normalized Time per Output Token (NTPOT) and Time to First Token (TTFT) in milliseconds, and throughput in output tokens per second, by saturating accelerators. To learn more about these performance metrics, see About model inference on GKE.
The following example latency profile illustrates the inflection point where throughput plateaus (green), the post-inflection point where latency worsens (red), and the ideal zone (blue) for optimal throughput at the latency target. Inference Quickstart provides performance data and configurations for this ideal zone.
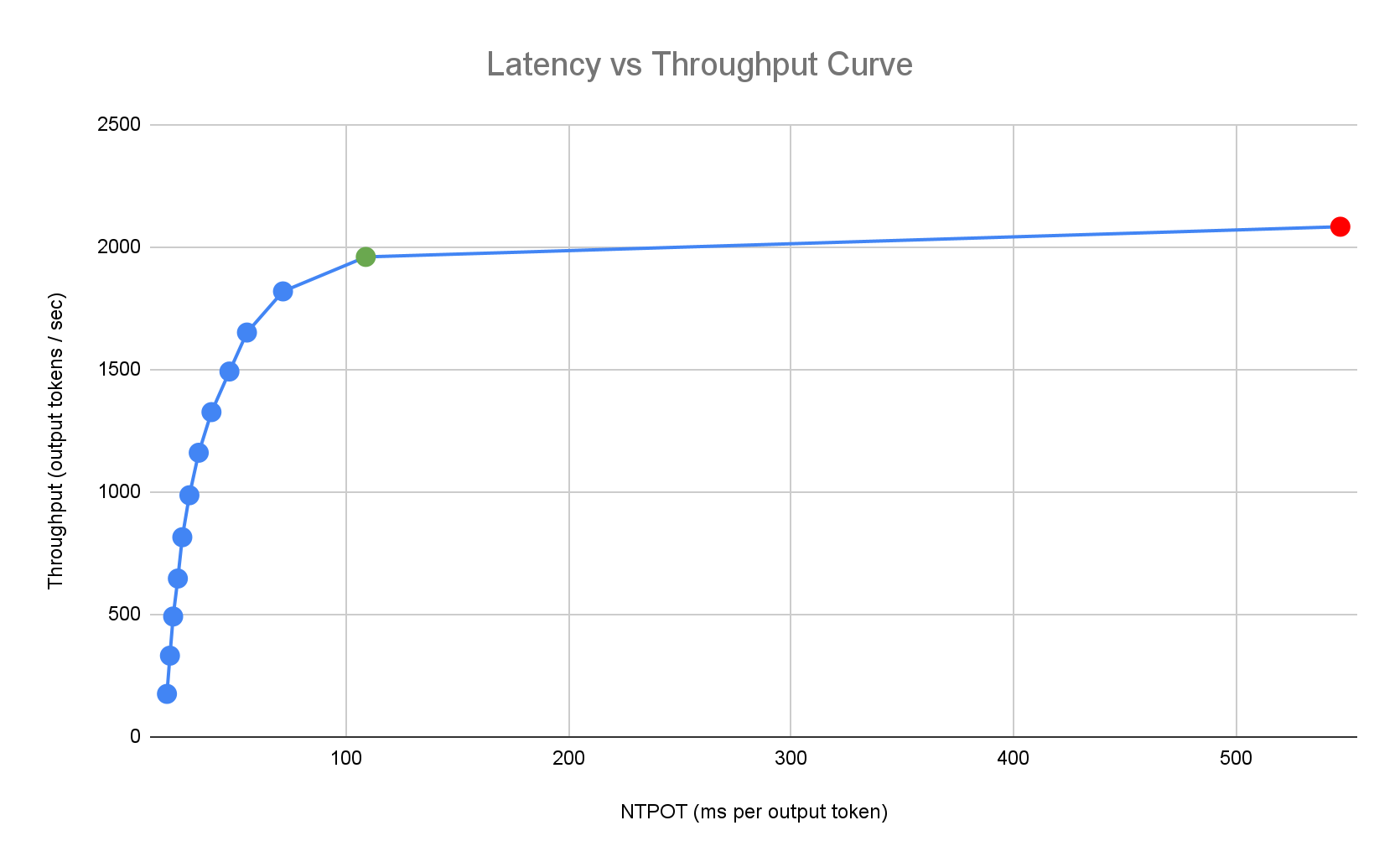
Based on an inference application's latency requirements, Inference Quickstart identifies suitable combinations and determines the optimal operating point on the latency-throughput curve. This point sets the Horizontal Pod Autoscaler (HPA) threshold, with a buffer to account for scale-up latency. The overall threshold also informs the initial number of replicas needed, though the HPA dynamically adjusts this number based on workload.
Cost calculation
To calculate cost, Inference Quickstart uses a configurable output-to-input cost ratio. For example, if this ratio is set to 4, it's assumed that each output token costs four times as much as an input token. The following equations are used to calculate the cost-per-token metrics:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
where
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Benchmarking
The provided configurations and performance data are based on benchmarks that use the ShareGPT dataset to send traffic with the following input and output distribution.
| Input Tokens | Output Tokens | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Median | Mean | P90 | P99 | Max | Min | Median | Mean | P90 | P99 | Max |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Before you begin
Before you start, make sure that you have performed the following tasks:
- Enable the Google Kubernetes Engine API. Enable Google Kubernetes Engine API
- If you want to use the Google Cloud CLI for this task,
install and then
initialize the
gcloud CLI. If you previously installed the gcloud CLI, get the latest
version by running the
gcloud components updatecommand. Earlier gcloud CLI versions might not support running the commands in this document.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Make sure that billing is enabled for your Google Cloud project.
Ensure you have sufficient accelerator capacity for your project:
- If you use GPUs: Check the Quotas page.
- If you use TPUs: Refer to Ensure quota for TPUs and other GKE resources.
Prepare to use the GKE AI/ML user interface
If you use the Google Cloud console, you also need to create an Autopilot cluster, if one is not already created in your project. Follow the instructions in Create an Autopilot cluster.
Prepare to use the command line interface
If you use the gcloud CLI to run Inference Quickstart, you also need to run these additional commands:
Enable the
gkerecommender.googleapis.comAPI:gcloud services enable gkerecommender.googleapis.comSet the billing quota project that you use for API calls:
gcloud config set billing/quota_project PROJECT_IDCheck that your gcloud CLI version is at least 536.0.1. If not, run the following:
gcloud components update
Limitations
Be aware of the following limitations before you start using Inference Quickstart:
- Google Cloud console model deployment supports deployment only to Autopilot clusters.
- Inference Quickstart does not provide profiles for all models supported by a given model server.
- If you don't set the
HF_HOMEenvironment variable when you use a generated manifest for a large model (90 GiB or greater) from Hugging Face, you must either use a cluster with larger-than-default boot disks or modify the manifest to setHF_HOMEto/dev/shm/hf_cache. This will use RAM for the cache instead of the node's boot disk. For more information, see the Troubleshooting section. - Loading models from Cloud Storage only supports deployment to clusters with the Cloud Storage FUSE CSI driver and Workload Identity Federation for GKE enabled, which are both enabled by default in Autopilot clusters. For more details, see Set up the Cloud Storage FUSE CSI driver for GKE.
Analyze and view optimized configurations for model inference
This section describes how to explore and analyze configuration recommendations by using Google Cloud CLI.
Use the gcloud container ai profiles
command to explore and analyze optimized profiles (combinations of model, model server,
model server version, and accelerators):
Models
To explore and select a model, use the models option.
gcloud container ai profiles models list
Profiles
Use the list
command to explore generated profiles and filter them based on your
performance and cost requirements. For example:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
The output shows supported profiles with performance metrics like throughput, latency, and cost per million tokens at the inflection point. It looks similar to the following:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
The values represent the performance observed at the point where throughput stops increasing and latency starts dramatically increasing (that is, the inflection or saturation point) for a given profile with this accelerator type. To learn more about these performance metrics, see About model inference on GKE.
For the full list of flags you can set, see the
list command documentation.
All pricing information is available in USD currency only and defaults to the
us-east5 region, except for configurations that use A3 machines, which
default to the us-central1 region.
Benchmarks
To get all benchmarking data for a specific profile, use the
benchmarks list command.
For example:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
The output contains a list of performance metrics from benchmarks run at different request rates.
The command displays the output in CSV format. To store the output as a
file, use output redirection. For example:
gcloud container ai profiles benchmarks list > profiles.csv.
For the full list of flags you can set, see the
benchmarks list command documentation.
After you choose a model, model server, model server version, and accelerator, you can proceed to create a deployment manifest.
Deploy recommended configurations
This section describes how to generate and deploy configuration recommendations by using either the Google Cloud console or the command line.
Console
- In the Google Cloud console, go to the GKE AI/ML page.
- Click Deploy Models.
Select a model you want to deploy. Models that are supported by Inference Quickstart are displayed with the Optimized tag.
- If you selected a foundation model, it opens a model page. Click Deploy. You can still modify the configuration before actual deployment.
- You are prompted to create an Autopilot cluster, if there isn't one in your project. Follow the instructions in Create an Autopilot cluster. After creating the cluster, return to the GKE AI/ML page in the Google Cloud console to select a model.
The model deployment page prepopulates with your selected model as well as the recommended model server and accelerator. You can also configure settings like maximum latency and model source.
(Optional) To view the manifest with the recommended configuration, click View YAML.
To deploy the manifest with the recommended configuration, click Deploy. It might take several minutes for the deployment operation to complete.
To view your deployment, go to the Kubernetes Engine > Workloads page.
gcloud
Prepare to load models from your model registry: Inference Quickstart supports loading models from Hugging Face or Cloud Storage.
Hugging Face
If you don't have one already, generate a Hugging Face access token and a corresponding Kubernetes Secret.
To create a Kubernetes Secret that contains the Hugging Face token, run the following command:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACEReplace the following values:
- HUGGING_FACE_TOKEN: the Hugging Face token you created earlier.
- NAMESPACE: the Kubernetes namespace where you want to deploy your model server.
Some models might also require you to accept and sign their consent license agreement.
Cloud Storage
You can load supported models from Cloud Storage with a tuned Cloud Storage FUSE setup. To do this, you first need to load the model from Hugging Face to your Cloud Storage bucket.
You can deploy this Kubernetes Job to transfer the model, changing
MODEL_IDto the Inference Quickstart supported model.Generate manifests: you have these options for generating manifests:
- Base configuration: generates the standard Kubernetes Deployment, Service, and PodMonitoring manifests for deploying a single-replica inference server.
- (Optional) Storage-optimized configuration: generates a manifest with a tuned Cloud Storage FUSE setup to load models from a Cloud Storage bucket. You enable this configuration by using the
--model-bucket-uriflag. A tuned Cloud Storage FUSE setup can improve LLM Pod startup time by more than 7x. (Optional) Autoscaling-optimized configuration: generates a manifest with a Horizontal Pod Autoscaler (HPA) to automatically adjust the number of model server replicas based on traffic. You enable this configuration by specifying a latency target with flags like
--target-ntpot-milliseconds.
Base configuration
In the terminal, use the
manifestsoption to generate Deployment, Service, and PodMonitoring manifests:gcloud container ai profiles manifests createUse the required
--model,--model-server, and--accelerator-typeparameters to customize your manifest.Optionally, you can set these parameters:
--target-ntpot-milliseconds: set this parameter to specify your HPA threshold. This parameter lets you define a scaling threshold to keep the Normalized Time Per Output Token (NTPOT) P50 latency, which is measured at the 50th percentile, below the specified value. Choose a value above the minimum latency of your accelerator. The HPA is configured for maximum throughput if you specify an NTPOT value above the maximum latency of your accelerator. For example:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: filters out profiles that exceed the TTFT latency target.--output-path: if specified, the output is saved to the provided path, rather than printed to the terminal so you can edit the output before deploying it. For example, you can use this with the--output=manifestoption if you want to save your manifest in a YAML file. For example:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
For the full list of flags you can set, see the
manifests createcommand documentation.Storage-optimized
You can improve Pod startup time by loading models from Cloud Storage using a tuned Cloud Storage FUSE configuration. Loading from Cloud Storage requires GKE versions 1.29.6-gke.1254000, 1.30.2-gke.1394000, or later
To do this, follow these steps:
- Load the model from the Hugging Face repository to your Cloud Storage bucket.
Set the
--model-bucket-uriflag when generating your manifest. This configures the model to load from a Cloud Storage bucket using the Cloud Storage FUSE CSI driver. The URI must point to the path containing the model'sconfig.jsonfile and weights. You can specify a path to a directory within the bucket by appending it to the bucket URI.For example:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlReplace
BUCKET_NAMEwith the name of your Cloud Storage bucket.Before applying the manifest, you must run the
gcloud storage buckets add-iam-policy-bindingcommand found in the manifest's comments. This command is required to grant the GKE service account permission to access the Cloud Storage bucket using Workload Identity Federation for GKE.If you intend to scale your Deployment to more than one replica, you must choose one of the following options to prevent concurrent write errors to the XLA cache path (
VLLM_XLA_CACHE_PATH):- Option 1 (Recommended): First, scale the Deployment to 1 replica. Wait for the Pod to become ready, which allows it to write to the XLA cache. Then, scale up to the number of replicas you want. The subsequent replicas will read from the populated cache without write conflicts.
- Option 2: Remove the
VLLM_XLA_CACHE_PATHenvironment variable from the manifest entirely. This approach is simpler but disables caching for all replicas.
On TPU accelerator types, this cache path is used to store the XLA compilation cache, which accelerates model preparation for repeated deployments.
For more tips about improving performance, see Optimize Cloud Storage FUSE CSI driver for GKE performance.
Autoscaling-optimized
You can configure the Horizontal Pod Autoscaler (HPA) to automatically adjust the number of model server replicas based on the load. This helps your model servers to efficiently handle varying loads by scaling up or down as needed. The HPA configuration follows the autoscaling best practices for GPUs and TPUs guides.
To include HPA configurations when generating manifests, use one or both of the
--target-ntpot-millisecondsand--target-ttft-millisecondsflags. These parameters define a scaling threshold for the HPA to keep the P50 latency for either NTPOT or TTFT below the specified value. If you set only one of these flags, only that metric will be taken into account for scaling.Choose a value above the minimum latency of your accelerator. The HPA is configured for maximum throughput if you specify a value above the maximum latency of your accelerator.
For example:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Create a cluster: You can serve your model on GKE Autopilot or Standard clusters. We recommend that you use an Autopilot cluster for a fully managed Kubernetes experience. To choose the GKE mode of operation that is the best fit for your workloads, see Choose a GKE mode of operation.
If you don't have an existing cluster, follow these steps:
Autopilot
Follow these instructions to create an Autopilot cluster. GKE handles provisioning the nodes with GPU or TPU capacity based on the deployment manifests, if you have the necessary quota in your project.
Standard
- Create a zonal or regional cluster.
Create a node pool with the appropriate accelerators. Follow these steps based on your chosen accelerator type:
- GPUs: First, check the Quotas page in the Google Cloud console to ensure you have sufficient GPU capacity. Then, follow the instructions in Create a GPU node pool.
- TPUs: First, ensure you have sufficient TPU by following the instructions in Ensure quota for TPUs and other GKE resources. Then, proceed to Create a TPU node pool.
(Optional, but recommended) Enable observability features: In the comments section of the generated manifest, additional commands are provided to enable suggested observability features. Enabling these features provides more insights to help you monitor the performance and status of workloads and the underlying infrastructure.
The following is an example of a command to enable observability features:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLFor more information, see Monitor your inference workloads.
(HPA only) Deploy a metrics adapter: A metrics adapter, such as the Custom Metrics Stackdriver Adapter, is necessary if HPA resources were generated in the deployment manifests. The metrics adapter enables the HPA to access model server metrics that use the kube external metrics API. To deploy the adapter, refer to the adapter documentation on GitHub.
Deploy the manifests: run the
kubectl applycommand and pass in the YAML file for your manifests. For example:kubectl apply -f ./manifests.yaml
Test your deployment endpoints
If you deployed the manifest, the deployed service is exposed at the following endpoint:
http://model-model_server-service:8000/
The model server, such as vLLM, typically listens on port 8000.
To test your deployment, you need to set up port forwarding. Run the following command in a separate terminal:
kubectl port-forward service/model-model_server-service 8000:8000
For examples of how to build and send a request to your endpoint, see the vLLM documentation.
Manifest versioning
Inference Quickstart provides the latest manifests that were validated on recent GKE cluster versions. The manifest returned for a profile might change over time so that you receive an optimized configuration at deployment. If you need a stable manifest, save and store it separately.
The manifest includes comments and a recommender.ai.gke.io/version annotation
in the following format:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
The previous annotation has the following values:
- DATE: the date the manifest was generated.
- CLUSTER_VERSION: the GKE cluster version used for validation.
- NODE_VERSION: the GKE node version used for validation.
- GPU_DRIVER_VERSION: (GPU only) the GPU driver version used for validation.
- MODEL_SERVER: the model server used in the manifest.
- MODEL_SERVER_VERSION: the model server version used in the manifest.
Monitor your inference workloads
To monitor your deployed inference workloads, go to the Metrics Explorer in the Google Cloud console.
Enable auto-monitoring
GKE includes an auto-monitoring feature that is part of the broader observability features. This feature scans the cluster for workloads that run on supported model servers and deploys the PodMonitoring resources that enable these workload metrics to be visible in Cloud Monitoring. For more information about enabling and configuring auto-monitoring, see Configure automatic application monitoring for workloads.
After enabling the feature, GKE installs prebuilt dashboards for monitoring applications for supported workloads.
If you deploy from the GKE AI/ML page in the Google Cloud console,
PodMonitoring and HPA resources are automatically created for you by using the
targetNtpot configuration.
Troubleshooting
- If you set the latency too low, Inference Quickstart might not generate a recommendation. To fix this issue, select a latency target between the minimum and maximum latency that was observed for your selected accelerators.
- Inference Quickstart exists independently of GKE components, so your cluster version is not directly relevant for using the service. However, we recommend using a fresh or up-to-date cluster to avoid any discrepancies in performance.
- If you get a
PERMISSION_DENIEDerror forgkerecommender.googleapis.comcommands that says a quota project is missing, you need to set it manually. Rungcloud config set billing/quota_project PROJECT_IDto fix this.
Pod evicted due to low ephemeral storage
When deploying a large model (90 GiB or more) from Hugging Face, your Pod might be evicted with an error message similar to this:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
This error occurs because the model is cached on the node's boot disk, a form of ephemeral storage. Boot disk is used for ephemeral storage when the deployment manifest does not set the HF_HOME environment variable to a directory in the node's RAM.
- By default, GKE nodes have a 100 GiB boot disk.
- GKE reserves 10% of the boot disk for system overhead, leaving 90 GiB for your workloads.
- If the model size is 90 GiB or larger, and run on a default sized boot disk, kubelet evicts the Pod to free up ephemeral storage.
To resolve this issue, choose one of the following options:
- Use RAM for model caching: In your deployment manifest, set the
HF_HOMEenvironment variable to/dev/shm/hf_cache. This uses the node's RAM to cache the model instead of the boot disk. - Increase the boot disk size:
- GKE Standard: Increase the boot disk size when you create a cluster, create a node pool, or update a node pool.
- Autopilot: To request a larger boot disk, create a Custom Compute class and set the
bootDiskSizefield in themachineTyperule.
Pod enters a crash loop when loading models from Cloud Storage
After you deploy a manifest that was generated with the --model-bucket-uri flag,
the Deployment may get stuck and the Pod enters a CrashLoopBackOff state.
Checking the logs for the inference-server container might show a misleading
error, such as huggingface_hub.errors.HFValidationError. For example:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
This error typically occurs when the Cloud Storage path provided in
the --model-bucket-uri flag is incorrect. The inference server, such as vLLM,
cannot find the required model files (like config.json) at the mounted path.
When it fails to find the local files, the server falls back to assuming the
path is a Hugging Face Hub repository ID. Because the path is not a valid
repository ID, the server fails with a validation error and enters a crash loop.
To resolve this issue, verify that the path you provided to the --model-bucket-uri
flag points to the exact directory in your Cloud Storage bucket that
contains the model's config.json file and all associated model weights.
What's next
- Visit the AI/ML orchestration on GKE portal to explore our official guides, tutorials, and use cases for running AI/ML workloads on GKE.
- For more information about model serving optimization, see Best practices for optimizing large language model inference with GPUs. It covers best practices for LLM serving with GPUs on GKE, like quantization, tensor parallelism, and memory management.
- For more information about best practices for autoscaling, see these guides:
- For information on storage best practices, see Optimize Cloud Storage FUSE CSI driver for GKE performance.
- Explore experimental samples for leveraging GKE to accelerate your AI/ML initiatives in GKE AI Labs.