Google Distributed Cloud (solo software) para bare metal admite varias opciones de registro y monitorización de clústeres, incluidos servicios gestionados basados en la nube, herramientas de software libre y compatibilidad validada con soluciones comerciales de terceros. En esta página se explican estas opciones y se ofrecen directrices básicas para seleccionar la solución adecuada para tu entorno.
Esta página está dirigida a administradores, arquitectos y operadores que quieran monitorizar el estado de las aplicaciones o los servicios implementados, por ejemplo, para comprobar si cumplen los objetivos de nivel de servicio (SLOs). Para obtener más información sobre los roles habituales y las tareas de ejemplo a las que se hace referencia en el contenido de Google Cloud , consulta Roles y tareas de usuario habituales de GKE.
Opciones de Google Distributed Cloud
Tienes varias opciones de registro y monitorización para tu clúster:
- Cloud Logging y Cloud Monitoring, habilitados de forma predeterminada en los componentes del sistema de hardware desnudo.
- Prometheus y Grafana están disponibles en Cloud Marketplace.
- Configuraciones validadas con soluciones de terceros.
Cloud Logging y Cloud Monitoring
Google Cloud Observability es la solución de observabilidad integrada deGoogle Cloud. Ofrece una solución de registro totalmente gestionada, recogida de métricas, monitorización, creación de paneles y alertas. Cloud Monitoring monitoriza los clústeres de Google Distributed Cloud de forma similar a los clústeres de GKE basados en la nube.
Cloud Logging y Cloud Monitoring están habilitados de forma predeterminada cuando creas clústeres con las cuentas de servicio y los roles de Gestión de Identidades y Accesos (IAM) necesarios. No puedes inhabilitar Cloud Logging ni Cloud Monitoring. Para obtener más información sobre las cuentas de servicio y los roles necesarios, consulta Configurar cuentas de servicio.
Los agentes se pueden configurar para cambiar lo siguiente:
- Ámbito del registro y la monitorización, que puede ser solo de los componentes del sistema (opción predeterminada) o de los componentes del sistema y las aplicaciones.
- Nivel de métricas recogidas, desde solo un conjunto optimizado de métricas (el valor predeterminado) hasta todas las métricas.
Para obtener más información, consulta el artículo Configurar agentes de Stackdriver para Google Distributed Cloud de este documento.
Logging y Monitoring ofrecen una solución de observabilidad basada en la nube única, potente y fácil de configurar. Recomendamos encarecidamente usar Logging y Monitoring al ejecutar cargas de trabajo en Google Distributed Cloud. En el caso de las aplicaciones con componentes que se ejecutan en Google Distributed Cloud y en la infraestructura estándar on-premise, puedes usar otras soluciones para obtener una vista integral de esas aplicaciones.
Para obtener información sobre la arquitectura, la configuración y los datos que se replican en tu proyecto de Google Cloud de forma predeterminada, consulta el artículo Cómo funcionan los registros y la monitorización de Google Distributed Cloud.
Para obtener más información sobre Logging, consulta la documentación de Cloud Logging.
Para obtener más información sobre Monitoring, consulta la documentación de Cloud Monitoring.
Para saber cómo ver y usar las métricas de utilización de recursos de Cloud Monitoring de Google Distributed Cloud a nivel de flota, consulta el artículo Usar la vista general de Google Kubernetes Engine.
Prometheus y Grafana
Prometheus y Grafana son dos productos de monitorización de código abierto populares que están disponibles en Cloud Marketplace:
Prometheus recoge métricas de aplicaciones y sistemas.
Alertmanager se encarga de enviar alertas con varios mecanismos diferentes.
Grafana es una herramienta para crear paneles de control.
Te recomendamos que uses Google Cloud Managed Service para Prometheus, que se basa en Cloud Monitoring, para todas tus necesidades de monitorización. Con Google Cloud Managed Service para Prometheus, puedes monitorizar componentes del sistema sin coste adicional. Google Cloud Managed Service para Prometheus también es compatible con Grafana. Sin embargo, si prefieres un sistema de monitorización local puro, puedes instalar Prometheus y Grafana en tus clústeres.
Si has instalado Prometheus de forma local y quieres recoger métricas de los componentes del sistema, debes dar permiso a tu instancia local de Prometheus para acceder a los endpoints de métricas de los componentes del sistema:
Vincula la cuenta de servicio de tu instancia de Prometheus al
gke-metrics-agentClusterRole predefinido y usa el token de la cuenta de servicio como credencial para extraer métricas de los siguientes componentes del sistema:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Usa la clave y el certificado de cliente almacenados en el secreto
kube-system/stackdriver-prometheus-etcd-scrapepara autenticar el raspado de métricas de etcd.Crea una NetworkPolicy para permitir el acceso desde tu espacio de nombres a kube-state-metrics.
Soluciones de terceros
Google ha colaborado con varios proveedores de soluciones de registro y monitorización de terceros para que sus productos funcionen correctamente con Google Distributed Cloud. Entre ellos se incluyen Datadog, Elastic y Splunk. En el futuro, se añadirán más terceros validados.
Las siguientes guías de soluciones están disponibles para usar soluciones de terceros con Google Distributed Cloud:
- Monitorizar Google Distributed Cloud con Elastic Stack
- Recopilar registros en Google Distributed Cloud con Splunk Connect
Cómo funcionan el registro y la monitorización de Google Distributed Cloud
Cloud Logging y Cloud Monitoring se instalan y activan en cada clúster cuando creas un clúster de administrador o de usuario.
Los agentes de Stackdriver incluyen varios componentes en cada clúster:
Operador de Stackdriver (
stackdriver-operator-*). Gestiona el ciclo de vida de todos los demás agentes de Stackdriver implementados en el clúster.Recurso personalizado de Stackdriver. Recurso que se crea automáticamente como parte del proceso de instalación de Google Distributed Cloud.
Agente de métricas de GKE (
gke-metrics-agent-*). Un DaemonSet basado en OpenTelemetry Collector que recoge métricas de cada nodo y las envía a Cloud Monitoring. También se incluyen unnode-exporterDaemonSet y unkube-state-metricsdeployment para proporcionar más métricas sobre el clúster.Stackdriver Log Forwarder (
stackdriver-log-forwarder-*). Un DaemonSet de Fluent Bit que reenvía los registros de cada máquina a Cloud Logging. El reenviador de registros almacena en búfer las entradas de registro en el nodo de forma local y las reenvía durante un máximo de 4 horas. Si el búfer se llena o si Log Forwarder no puede acceder a la API de Cloud Logging durante más de 4 horas, los registros se descartan.Agente de metadatos (
stackdriver-metadata-agent-). Un despliegue que envía metadatos de recursos de Kubernetes, como pods, despliegues o nodos, a la API Config Monitoring for Ops. Al añadir metadatos, puedes consultar los datos de métricas por nombre de implementación, nombre de nodo o incluso nombre de servicio de Kubernetes.
Para ver los agentes instalados por Stackdriver, ejecuta el siguiente comando:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
El resultado debe ser similar al siguiente:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Métricas de Cloud Monitoring
Para ver una lista de las métricas recogidas por Cloud Monitoring, consulta Ver métricas de Google Distributed Cloud.
Configurar agentes de Stackdriver para Google Distributed Cloud
Los agentes de Stackdriver instalados con Google Distributed Cloud recogen datos sobre los componentes del sistema para mantener y solucionar problemas con tus clústeres. En las siguientes secciones se describen la configuración y los modos de funcionamiento de Stackdriver.
Solo componentes del sistema (modo predeterminado)
Tras la instalación, los agentes de Stackdriver se configuran de forma predeterminada para recoger registros y métricas, incluidos detalles sobre el rendimiento (por ejemplo, el uso de la CPU y la memoria) y metadatos similares de los componentes del sistema proporcionados por Google. Esto incluye todas las cargas de trabajo del clúster de administrador y, en el caso de los clústeres de usuarios, las cargas de trabajo de los espacios de nombres kube-system, gke-system, gke-connect, istio-system y config-management-system.
Componentes y aplicaciones del sistema
Para habilitar el almacenamiento de registros y la monitorización de aplicaciones además del modo predeterminado, sigue los pasos que se indican en Habilitar el almacenamiento de registros y la monitorización de aplicaciones.
Métricas optimizadas (métricas predeterminadas)
De forma predeterminada, las implementaciones de kube-state-metrics que se ejecutan en el clúster recogen y registran un conjunto optimizado de métricas de kube en Google Cloud Observability (antes Stackdriver).
Se necesitan menos recursos para recoger este conjunto de métricas optimizado, lo que mejora el rendimiento y la escalabilidad generales.
Para inhabilitar las métricas optimizadas (no recomendado), anula el valor predeterminado en tu recurso personalizado de Stackdriver.
Usar Google Cloud Managed Service para Prometheus en componentes del sistema concretos
Google Cloud Managed Service para Prometheus forma parte de Cloud Monitoring y está disponible como opción para los componentes del sistema. Entre las ventajas de Google Cloud Managed Service para Prometheus, se incluyen las siguientes:
Puedes seguir usando tu monitorización basada en Prometheus sin modificar tus alertas ni tus paneles de control de Grafana.
Si usas tanto GKE como Google Distributed Cloud, puedes usar el mismo lenguaje de consulta de Prometheus (PromQL) para las métricas de todos tus clústeres. También puedes usar la pestaña PromQL del explorador de métricas de la Google Cloud consola.
Habilitar e inhabilitar Google Cloud Managed Service para Prometheus
A partir de la versión 1.30.0-gke.1930 de Google Distributed Cloud, Google Cloud Managed Service para Prometheus está siempre habilitado. En versiones anteriores, puedes editar el recurso de Stackdriver, stackdriver, para habilitar o inhabilitar Google Cloud Managed Service para Prometheus. Para inhabilitar Google Cloud Managed Service para Prometheus en versiones de clúster anteriores a la 1.30.0-gke.1930, asigna el valor false a spec.featureGates.enableGMPForSystemMetrics en el recurso stackdriver.
Ver datos de métricas
Cuando enableGMPForSystemMetrics se define como true, las métricas de los siguientes componentes tienen un formato diferente en cuanto a cómo se almacenan y se consultan en Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet y cadvisor
- kube-state-metrics
- node-exporter
Con el nuevo formato, puede consultar las métricas anteriores mediante el lenguaje de consulta de Prometheus (PromQL).
Ejemplo de consulta de PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Configurar paneles de control de Grafana con Google Cloud Managed Service para Prometheus
Para usar Grafana con datos de métricas de Google Cloud Managed Service para Prometheus, primero debes configurar y autenticar la fuente de datos de Grafana. Para configurar y autenticar la fuente de datos, utiliza el sincronizador de fuentes de datos (datasource-syncer) para generar credenciales de OAuth2 y sincronizarlas con Grafana a través de la API de fuentes de datos de Grafana. El sincronizador de fuentes de datos define la API de Cloud Monitoring como la URL del servidor de Prometheus (el valor de la URL empieza por https://monitoring.googleapis.com) en la fuente de datos de Grafana.
Sigue los pasos que se indican en Consultar con Grafana para autenticar y configurar una fuente de datos de Grafana con el fin de consultar datos de Google Cloud Managed Service para Prometheus.
En el repositorio anthos-samples de GitHub se proporciona un conjunto de paneles de Grafana de ejemplo. Para instalar los paneles de control de ejemplo, siga estos pasos:
Descarga los archivos JSON de ejemplo:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Si tu fuente de datos de Grafana se creó con un nombre diferente a
Managed Service for Prometheus, cambia el campodatasourceen todos los archivos JSON:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Sustituye [DATASOURCE_NAME] por el nombre de la fuente de datos de tu Grafana que apuntaba al servicio
frontendde Prometheus.Accede a la interfaz de usuario de Grafana desde tu navegador y selecciona + Import (Importar) en el menú Dashboards (Paneles de control).
Sube el archivo JSON o copia y pega el contenido del archivo y selecciona Cargar. Cuando el contenido del archivo se haya cargado correctamente, selecciona Importar. También puedes cambiar el nombre y el UID del panel de control antes de importarlo.
El panel de control importado debería cargarse correctamente si Google Distributed Cloud y la fuente de datos están configurados correctamente. Por ejemplo, en la siguiente captura de pantalla se muestra el panel de control configurado por
cluster-capacity.json.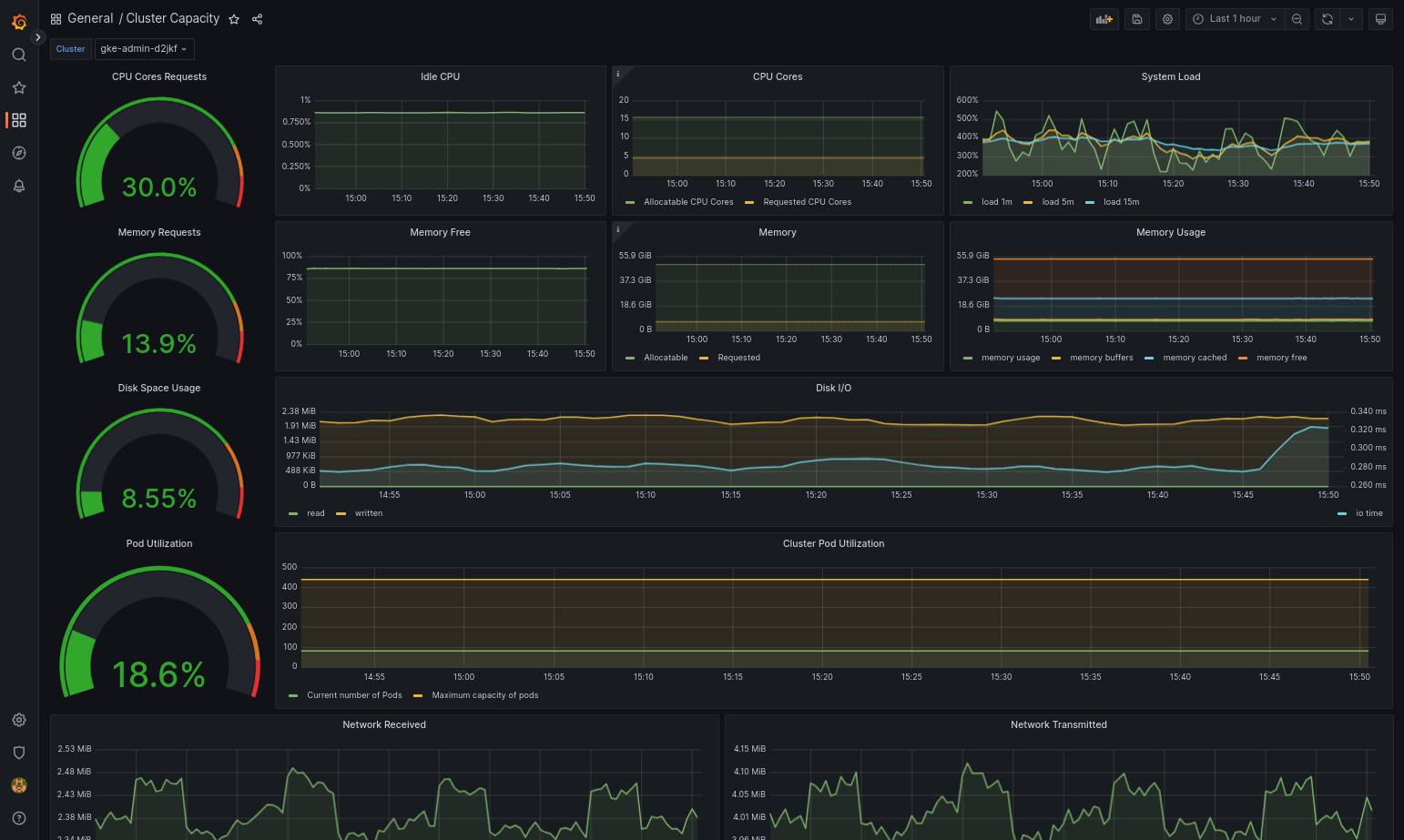
Recursos adicionales
Para obtener más información sobre Google Cloud Managed Service para Prometheus, consulta los siguientes recursos:
Configurar recursos de componentes de Stackdriver
Cuando creas un clúster, Google Distributed Cloud crea automáticamente un recurso personalizado de Stackdriver. Puede editar la especificación del recurso personalizado para anular los valores predeterminados de las solicitudes y los límites de CPU y memoria de un componente de Stackdriver, así como anular por separado el ajuste predeterminado de métricas optimizadas.
Anular las solicitudes y los límites predeterminados de CPU y memoria de un componente de Stackdriver
Los clústeres con una alta densidad de pods introducen una mayor sobrecarga de registro y monitorización. En casos extremos, los componentes de Stackdriver pueden informar de que se está cerca del límite de utilización de la CPU y la memoria, o incluso pueden estar sujetos a reinicios constantes debido a los límites de recursos. En este caso, para anular los valores predeterminados de las solicitudes y los límites de CPU y memoria de un componente de Stackdriver, sigue estos pasos:
Ejecuta el siguiente comando para abrir tu recurso personalizado de Stackdriver en un editor de línea de comandos:
kubectl -n kube-system edit stackdriver stackdriver
En el recurso personalizado de Stackdriver, añade la sección
resourceAttrOverrideen el campospec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYTen en cuenta que la sección
resourceAttrOverrideanula todos los límites y solicitudes predeterminados del componente que especifiques.resourceAttrOverrideadmite los siguientes componentes:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Un archivo de ejemplo tiene el siguiente aspecto:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiPara guardar los cambios en el recurso personalizado de Stackdriver, guarda y cierra el editor de línea de comandos.
Comprueba el estado de tu Pod:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
La respuesta de un pod en buen estado tiene el siguiente aspecto:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Comprueba la especificación del pod del componente para asegurarte de que los recursos estén configurados correctamente.
kubectl -n kube-system describe pod POD_NAME
Sustituye
POD_NAMEpor el nombre del pod que acabas de cambiar. Por ejemplo,gke-metrics-agent-4th8r.La respuesta tiene este aspecto:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Inhabilitar métricas optimizadas
De forma predeterminada, las implementaciones de kube-state-metrics que se ejecutan en el clúster recogen y envían un conjunto optimizado de métricas de kube a Stackdriver. Si necesitas métricas adicionales, te recomendamos que busques una alternativa en la lista de métricas de Google Distributed Cloud.
Estos son algunos ejemplos de sustituciones que puedes usar:
| Métrica inhabilitada | Sustituciones |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Para inhabilitar la configuración predeterminada de métricas optimizadas (no recomendado), siga estos pasos:
Abre tu recurso personalizado de Stackdriver en un editor de línea de comandos:
kubectl -n kube-system edit stackdriver stackdriver
Asigna el valor
falseal campooptimizedMetrics:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Guarda los cambios y cierra el editor de línea de comandos.
Servidor de métricas
Metrics Server es la fuente de las métricas de recursos de los contenedores de varias canalizaciones de autoescalado. Metrics Server obtiene métricas de los kubelets y las expone a través de la API Metrics de Kubernetes. A continuación, HPA y VPA usan estas métricas para determinar cuándo activar el autoescalado. El servidor de métricas se escala mediante addon-resizer.
En casos extremos en los que la alta densidad de pods crea una sobrecarga excesiva de registro y monitorización, es posible que Metrics Server se detenga y se reinicie debido a limitaciones de recursos. En este caso, puedes asignar más recursos al servidor de métricas editando el mapa de configuración metrics-server-config en el espacio de nombres gke-managed-metrics-server y cambiando los valores de cpuPerNode y memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
El contenido de ejemplo de ConfigMap es el siguiente:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Después de actualizar el ConfigMap, vuelve a crear los pods de metrics-server con el siguiente comando:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Enrutamiento de registros y métricas
El reenviador de registros de Stackdriver (stackdriver-log-forwarder) envía los registros de cada máquina de nodo a Cloud Logging. Del mismo modo, el agente de métricas de GKE (gke-metrics-agent) envía métricas de cada máquina de nodo a Cloud Monitoring. Antes de que se envíen los registros y las métricas, el operador de Stackdriver (stackdriver-operator) adjunta el valor del campo clusterLocation
del recurso personalizado stackdriver a cada entrada de registro y métrica antes de que se enruten a Google Cloud. Además, los registros y las métricas están asociados al Google Cloud proyectostackdriver especificado en la especificación de recursos personalizada spec.projectID.
El recurso stackdriver obtiene los valores de los campos clusterLocation y projectID de los campos location y projectID de la sección clusterOperations del recurso Cluster en el momento de la creación del clúster.
Todas las métricas y entradas de registro enviadas por los agentes de Stackdriver se dirigen a un endpoint de ingestión global. A partir de ahí, los datos se reenvían al endpoint regional Google Cloud más cercano para asegurar la fiabilidad de la transferencia de datos.
Una vez que el endpoint global recibe la métrica o la entrada de registro, lo que ocurre a continuación depende del servicio:
Cómo se configura el enrutamiento de registros: cuando el endpoint de registro recibe un mensaje de registro, Cloud Logging lo envía a través del enrutador de registros. Los sumideros y los filtros de la configuración del enrutador de registros determinan cómo se enruta el mensaje. Puedes enrutar entradas de registro a destinos como segmentos de Logging regionales, que almacenan la entrada de registro, o a Pub/Sub. Para obtener más información sobre cómo funciona el enrutamiento de registros y cómo configurarlo, consulta el resumen sobre el enrutamiento y el almacenamiento.
En este proceso de enrutamiento no se tienen en cuenta ni el campo
clusterLocationdel recurso personalizadostackdriverni el campoclusterOperations.locationde la especificación de clúster. En el caso de los registros,clusterLocationse usa para etiquetar solo las entradas de registro, lo que puede ser útil para filtrar en Explorador de registros.Cómo se configura el enrutamiento de métricas: cuando el endpoint de métricas recibe una entrada de métrica, esta se enruta automáticamente para almacenarse en la ubicación especificada por la métrica. La ubicación de la métrica procede del campo
clusterLocationdel recurso personalizadostackdriver.Planifica tu configuración: cuando configures Cloud Logging y Cloud Monitoring, configura el enrutador de registros y especifica un
clusterOperations.locationadecuado con las ubicaciones que mejor se adapten a tus necesidades. Por ejemplo, si quieres que los registros y las métricas vayan a la misma ubicación, asigna aclusterOperations.locationla misma región Google Cloud que usa el enrutador de registros para tu Google Cloud proyecto.Actualiza la configuración de los registros cuando sea necesario: puedes cambiar los ajustes de destino de los registros en cualquier momento debido a requisitos empresariales, como planes de recuperación ante desastres. Los cambios en la configuración de Log Router enGoogle Cloud se aplican rápidamente. Los campos
locationyprojectIDde la secciónclusterOperationsdel recurso Cluster son inmutables, por lo que no se pueden actualizar después de crear el clúster. No te recomendamos que cambies los valores del recursostackdriverdirectamente. Este recurso vuelve al estado de creación del clúster original cada vez que una operación del clúster, como una actualización, activa una conciliación.
Requisitos de configuración para el almacenamiento de registros y la monitorización
Para habilitar Cloud Logging y Cloud Monitoring con Google Distributed Cloud, debes cumplir varios requisitos de configuración. Estos pasos se incluyen en el artículo Configurar una cuenta de servicio para usarla con Logging y Monitoring de la página Habilitar servicios de Google, así como en la siguiente lista:
- Debes crear un espacio de trabajo de Cloud Monitoring en elGoogle Cloud proyecto. Para ello, haz clic en Monitorización en la consola deGoogle Cloud y sigue el flujo de trabajo.
Debes habilitar las siguientes APIs de Stackdriver:
Debe asignar los siguientes roles de gestión de identidades y accesos a la cuenta de servicio que usan los agentes de Stackdriver:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Etiquetas de registro
Muchos registros de Google Distributed Cloud tienen la etiqueta F:
logtag: "F"
Esta etiqueta significa que la entrada de registro está completa o llena. Para obtener más información sobre esta etiqueta, consulta Formato de registro en las propuestas de diseño de Kubernetes en GitHub.
Precios
En un clúster de Google Distributed Cloud, los registros y las métricas del sistema incluyen lo siguiente:
- Registros y métricas de todos los componentes de un clúster de administradores.
- Registros y métricas de componentes en estos espacios de nombres en un clúster de usuarios:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-systemycnrm-system.
Para obtener más información, consulta los precios de Google Cloud Observability.
Para obtener información sobre el crédito de las métricas de Cloud Logging, ponte en contacto con el equipo de Ventas para consultar los precios.