이 페이지에서는 Consent Management API로 사용자 데이터를 등록하는 방법을 설명합니다.
데이터 요소는 Consent Management API에 등록되며 사용자 데이터 매핑을 사용하여 동의에 연결됩니다. 사용자 데이터는 Consent Management API에 저장되지 않습니다.
UserDataMappings 리소스로 표시되는 사용자 데이터 매핑에는 다음 요소가 포함됩니다.
- 사용자를 식별하는 사용자 ID 이 ID는 동의를 등록할 때 애플리케이션이 Consent Management API를 제공한 ID와 일치합니다.
- Google Cloud 또는 온프레미스와 같이 다른 곳에 저장된 사용자 데이터를 식별하는 데이터 ID입니다. 데이터 ID는 비공개 ID, URL 또는 기타 식별자일 수 있습니다.
- 속성 정의를 사용하여 동의 저장소에 대해 구성된 리소스 속성 값으로 사용자 데이터 특성을 설명하는 리소스 속성 예를 들어 이 데이터에는
de-identified값이 있는attribute_definition_iddata_identifiable이 포함될 수 있습니다.
다음 다이어그램은 사용자 데이터 매핑을 만드는 데이터 흐름을 보여줍니다.
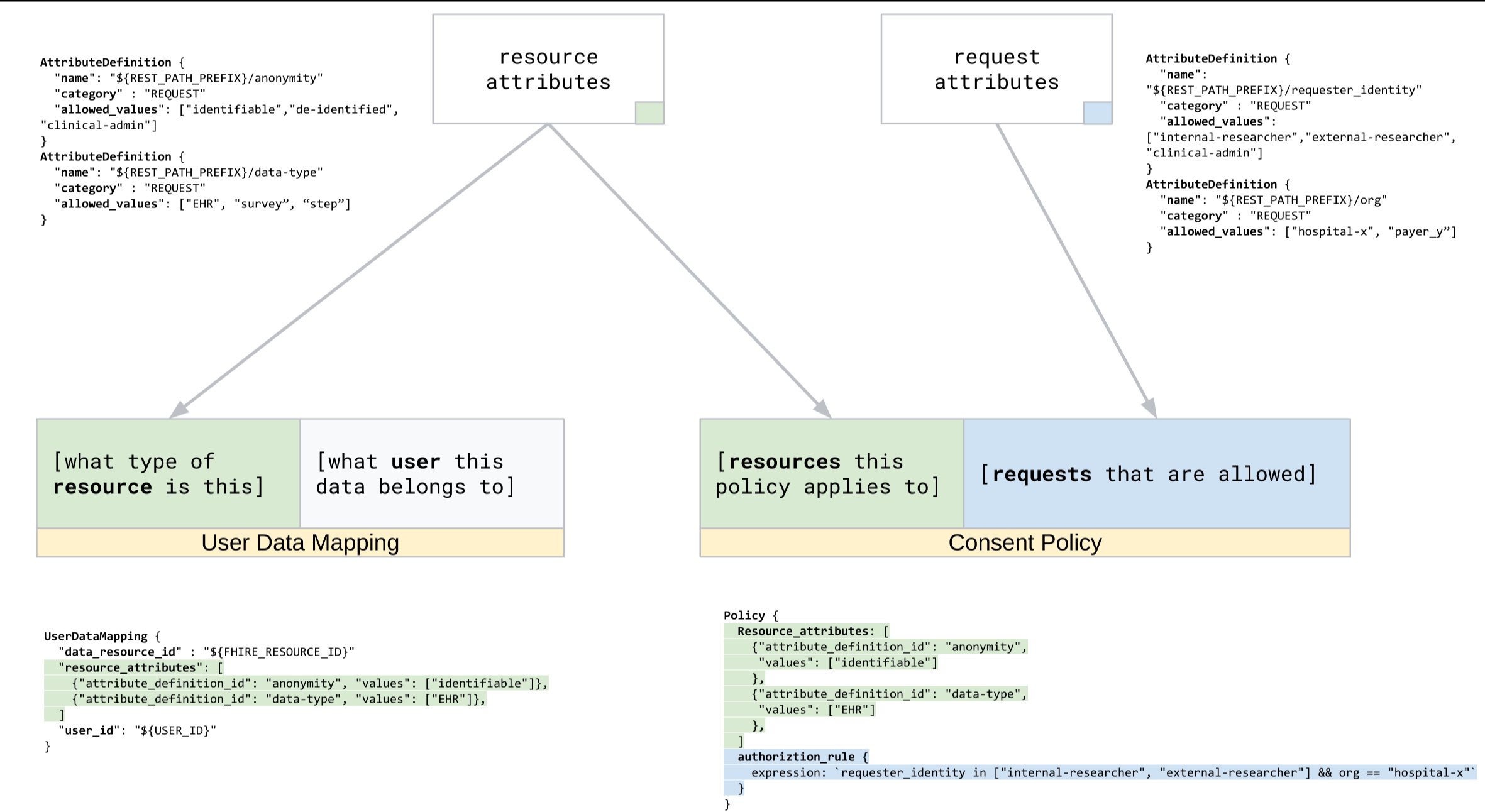
사용자 데이터 매핑 등록
사용자 데이터 매핑을 만들려면 projects.locations.datasets.consentStores.userDataMappings.create 메서드를 사용합니다. POST 요청을 수행하고 다음 정보를 요청에 지정합니다.
- 부모 동의 저장소 이름
- 데이터 요소와 연결된 사용자를 나타내는 고유 비공개
userID - 사용자 데이터 리소스의 식별자(예: 고유 리소스의 REST 경로)
- 데이터 요소를 설명하는
RESOURCE속성 세트 - 액세스 토큰
curl
다음 샘플은 curl을 사용하는 POST 요청을 보여줍니다.
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/consent+json; charset=utf-8" \ --data "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" \ "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings"
요청이 성공하면 서버는 다음 샘플과 비슷한 응답을 JSON 형식으로 반환합니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
PowerShell
다음 샘플은 Windows PowerShell을 사용한 POST 요청을 보여줍니다.
$cred = gcloud auth application-default print-access-token $headers = @{ Authorization = "Bearer $cred" } Invoke-WebRequest ` -Method Post ` -Headers $headers ` -ContentType: "application/consent+json; charset=utf-8" ` -Body "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" ` -Uri "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings" | Select-Object -Expand Content
요청이 성공하면 서버는 다음 샘플과 비슷한 응답을 JSON 형식으로 반환합니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
데이터 ID 구성
사용자 데이터 매핑 리소스의 data_id 필드에는 사용자 데이터 매핑 리소스에서 참조하는 데이터를 설명하는 고객 지정 문자열이 포함됩니다. 비공개 ID나 URI와 같은 모든 문자열이 허용됩니다.
데이터 ID는 애플리케이션에 필요한 만큼 세분화될 수 있습니다. 등록하는 데이터를 테이블 또는 버킷 수준에서 설명할 수 있는 경우 data_id를 해당 리소스의 REST 경로로 정의합니다.
등록하려는 데이터에 더 세분화된 설정이 필요한 경우 특정 행 또는 셀을 지정하는 것이 좋습니다. 애플리케이션이 허용되는 작업이나 데이터 클래스와 같은 개념적 리소스를 사용하는 경우 해당 사용 사례를 지원하는 규칙으로 data_id를 정의해야 합니다.
서로 다른 서비스에 저장되고 여러 수준으로 세분화된 데이터를 기술하는 data_id의 예시에는 다음을 비롯한 다양한 경우가 포함됩니다.
Google Cloud Storage 객체
'data_id' : 'gs://BUCKET_NAME/OBJECT_NAME'
Amazon S3 객체
'data_id' : 'https://BUCKET_NAME.s3.REGION.amazonaws.com/OBJECT_NAME'
BigQuery 테이블
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID'
BigQuery 행(BigQuery 행에 REST 경로가 없으므로 고유 식별자가 필요하며 가능한 방법은 아래와 같음)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID'
BigQuery 셀(BigQuery 셀에 REST 경로가 없으므로 고유 식별자가 필요하며 가능한 방법은 아래와 같음)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID/myColumns/COLUMN_ID'
FHIR 리소스
'data_id' : 'https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/fhirStores/FHIR_STORE_ID/fhir/Patient/PATIENT_ID'
개념적 표현
'data_id' : 'wearables/fitness/step_count/daily_sum'