Auf dieser Seite wird das Registrieren von Nutzerdaten über die Consent Management API beschrieben.
Datenelemente werden bei der Consent Management API registriert und mithilfe von Nutzerdatenzuordnungen mit Einwilligungen verbunden. Nutzerdaten werden nie in der Consent Management API gespeichert.
Die Nutzerdatenzuordnungen, dargestellt als UserDataMappings-Ressourcen, enthalten folgende Elemente:
- Eine Nutzer-ID, die den Nutzer identifiziert. Diese ID stimmt mit der ID überein, die von der Anwendung bei der Registrierung der Einwilligung der Consent Management API bereitgestellt wurde.
- Eine Daten-ID, die an anderer Stelle gespeicherte Nutzerdaten identifiziert, z. B. inGoogle Cloud oder lokal. Die Daten-ID kann eine intransparente ID, eine URL oder eine andere Kennung sein.
- Ressourcenattribute, die die Merkmale der Nutzerdaten über Ressourcenattributwerten beschreiben, die für den Einwilligungsspeicher mit Attributdefinitionen konfiguriert wurden. Beispielsweise können solche Daten den
attribute_definition_iddata_identifiablemit dem Wertde-identifiedenthalten.
Das folgende Diagramm zeigt den Datenfluss zum Erstellen von Nutzerdatenzuordnungen:
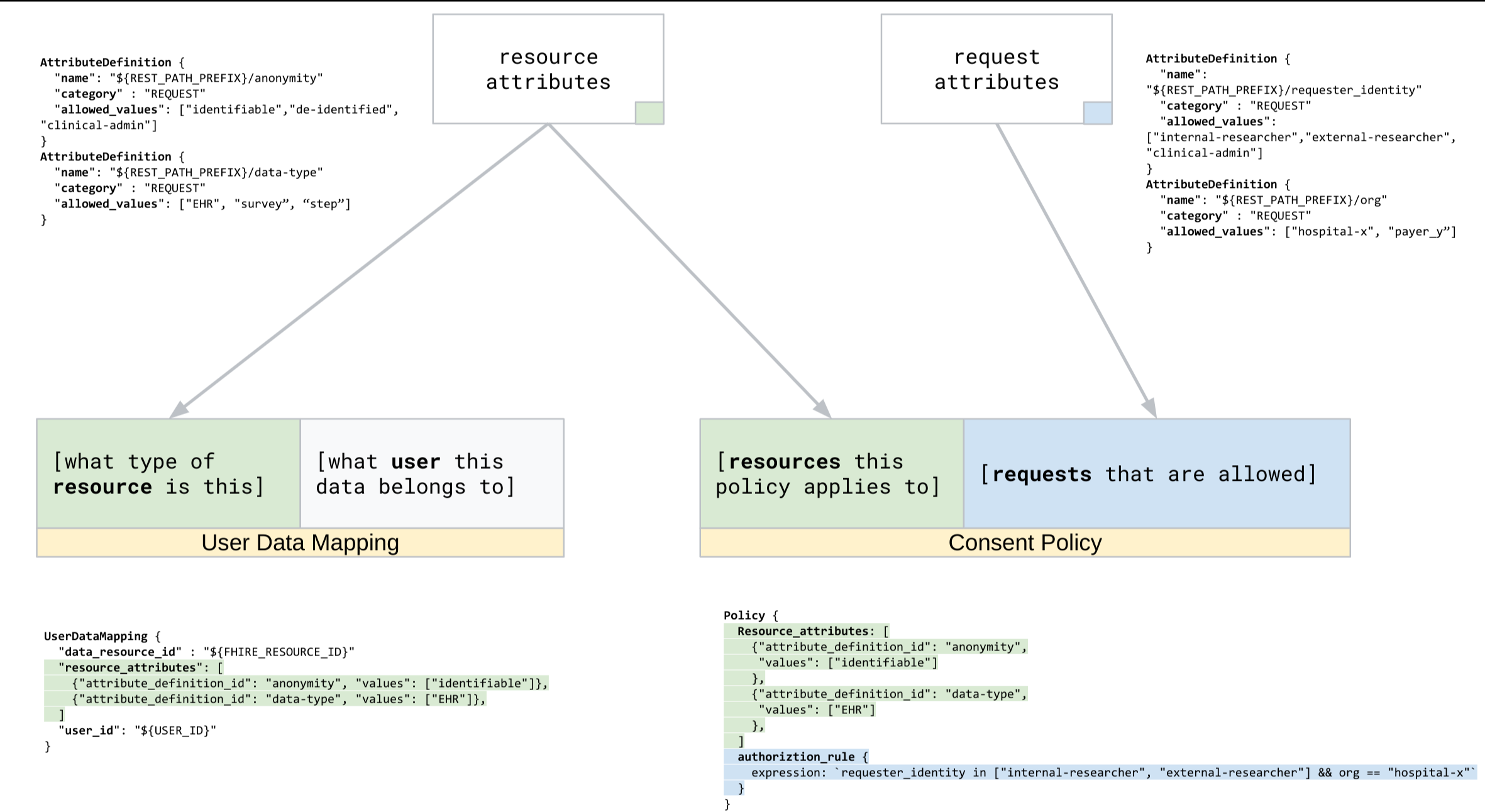
Nutzerdatenzuordnungen registrieren
Verwenden Sie die Methode projects.locations.datasets.consentStores.userDataMappings.create, um eine Nutzerdatenzuordnung zu erstellen. Stellen Sie eine POST-Anfrage und geben Sie die folgenden Informationen in der Anfrage an:
- Der Name des übergeordneten Einwilligungsspeichers
- Ein einmaliges und undurchsichtiges
userID-Element, das den Nutzer darstellt, mit dem das Datenelement verknüpft ist - Eine Kennung für die Nutzerdatenressource, z. B. der REST-Pfad zu einer eindeutigen Ressource
- Eine Reihe von
RESOURCE-Attributen, die das Datenelement beschreiben - Ein Zugriffstoken
curl
Das folgende Beispiel zeigt eine POST-Anfrage mit curl.
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/consent+json; charset=utf-8" \ --data "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" \ "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings"
Wenn die Anfrage erfolgreich ist, gibt der Server eine Antwort wie die folgende im JSON-Format zurück:
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
PowerShell
Das folgende Beispiel zeigt eine POST-Anfrage mit Windows PowerShell.
$cred = gcloud auth application-default print-access-token $headers = @{ Authorization = "Bearer $cred" } Invoke-WebRequest ` -Method Post ` -Headers $headers ` -ContentType: "application/consent+json; charset=utf-8" ` -Body "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" ` -Uri "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings" | Select-Object -Expand Content
Wenn die Anfrage erfolgreich ist, gibt der Server eine Antwort wie die folgende im JSON-Format zurück:
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
Daten-IDs konfigurieren
Das data_id-Feld der Nutzerdatenzuordnungsressource enthält einen vom Kunden angegebenen String, der die Daten beschreibt, auf die sich die Nutzerdatenzuordnungsressource bezieht. Jeder String ist zulässig, darunter auch intransparente IDs oder intransparente URIs.
Daten-IDs können so detailliert sein, wie es für Ihre Anwendung erforderlich ist. Können zu registrierende Daten auf Tabellen- oder Bucket-Ebene beschrieben werden, so definieren Sie data_id als REST-Pfad zu dieser Ressource.
Wenn die Daten, die Sie registrieren, eine höhere Granularität erfordern, können Sie bestimmte Zeilen oder Zellen angeben. Wenn Ihre Anwendung konzeptionelle Ressourcen wie zulässige Aktionen oder Datenklassen verwendet, sollten Sie data_id mit einer Konvention definieren, die diese Anwendungsfälle unterstützt.
Beispiele für ein data_id, das Daten beschreibt, die in verschiedenen Diensten und mit unterschiedlichem Detaillierungsgrad gespeichert sind, sind unter anderem:
Google Cloud Storage-Objekt
'data_id' : 'gs://BUCKET_NAME/OBJECT_NAME'
Amazon S3-Objekt
'data_id' : 'https://BUCKET_NAME.s3.REGION.amazonaws.com/OBJECT_NAME'
BigQuery-Tabelle
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID'
BigQuery-Zeile: Es gibt keinen REST-Pfad für eine BigQuery-Zeile. Daher ist Ihre eigene Kennzeichnung erforderlich. Ein möglicher Ansatz wird unten beschrieben.
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID'
BigQuery-Zelle: Es gibt keinen REST-Pfad für eine BigQuery-Zelle. Daher ist Ihre eigene Kennzeichnung erforderlich. Ein möglicher Ansatz wird unten beschrieben.
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID/myColumns/COLUMN_ID'
FHIR-Ressource
'data_id' : 'https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/fhirStores/FHIR_STORE_ID/fhir/Patient/PATIENT_ID'
Konzeptionelle Darstellung
'data_id' : 'wearables/fitness/step_count/daily_sum'