Premiers pas avec les recommandations de contenus multimédias
Vous pouvez rapidement créer une application de recommandation de contenus multimédias de pointe, capable de faire découvrir à vos audiences des contenus plus personnalisés, comme les vidéos à regarder ou à lire ensuite, avec des résultats de qualité Google, personnalisés selon des objectifs d'optimisation.
Pour en savoir plus sur Vertex AI Search pour les contenus multimédias, consultez la Présentation de la recherche et des recommandations multimédias.Dans ce tutoriel de démarrage, vous allez utiliser l'ensemble de données MovieLens pour montrer comment importer votre catalogue de contenus multimédias et vos événements utilisateur dans Vertex AI Search, et comment entraîner un modèle de recommandation de films personnalisés. L'ensemble de données MovieLens contient un catalogue de films (documents) et des notations de ces films par les utilisateurs (événements utilisateur).
Dans ce tutoriel, vous allez entraîner un modèle de recommandation de type "Autres susceptibles de vous plaire" optimisé pour le taux de clics (CTR). Après l'entraînement, le modèle peut recommander des films en fonction d'un ID utilisateur et d'un film source.
Afin de répondre aux exigences minimales en matière de données pour le modèle, chaque note positive de film (4 ou plus) est traitée comme un événement de type "vue".
Durée estimée pour réaliser ce tutoriel :
- Étapes initiales pour commencer à entraîner le modèle : environ 1 heure et 30 minutes.
- En attente de l'entraînement du modèle : environ 24 heures. (Entraîner le modèle)
- Évaluation des prédictions du modèle et nettoyage : environ 30 minutes. (Aperçu des recommandations)
Si vous avez suivi le tutoriel Premiers pas avec les recherches de contenus multimédias et que vous avez toujours le data store (nom suggéréquickstart-media-data-store), vous pouvez utiliser ce datastore au lieu d'en créer un autre. Dans ce cas, vous devez commencer le tutoriel à l'adresse
Créer une application de recommandations de contenus multimédias
Objectifs
- Découvrez comment importer des documents multimédias et des données d'événements utilisateur de BigQuery dans Vertex AI Search.
- Entraîner et évaluer des modèles de recommandation
Avant de suivre ce tutoriel, assurez-vous d'avoir effectué les étapes de la section Avant de commencer.
Pour obtenir des instructions détaillées sur cette tâche directement dans la console Google Cloud, cliquez sur Visite guidée :
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Agent Builder, Cloud Storage, BigQuery APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Agent Builder, Cloud Storage, BigQuery APIs.
Préparer l'ensemble de données
Vous allez utiliser Cloud Shell pour importer l'ensemble de données MovieLens et restructurer l'ensemble de données pour Vertex AI Search for Media.
Ouvrir Cloud Shell
- Ouvrez la console Google Cloud.
- Sélectionnez votre projet Google Cloud.
- Notez l'ID du projet dans la fiche Informations sur le projet de la page du tableau de bord. Vous aurez besoin de l'ID du projet pour les procédures suivantes.
Cliquez sur le bouton Activer Cloud Shell en haut de la console. Une session Cloud Shell s'ouvre dans un nouveau cadre en bas de la console Google Cloud et affiche une invite de ligne de commande.

Importer l'ensemble de données
Pour faciliter l'importation, l'ensemble de données MovieLens est disponible dans un bucket Cloud Storage public.
Exécutez la commande suivante en utilisant votre ID de projet pour définir le projet par défaut pour la ligne de commande.
gcloud config set project PROJECT_IDCréez un ensemble de données BigQuery :
bq mk movielensChargez
movies.csvdans une nouvelle table BigQuerymovies:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresChargez
ratings.csvdans une nouvelle table BigQueryratings:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp
Créer des vues BigQuery
Au cours de cette étape, vous allez restructurer l'ensemble de données MovieLens afin qu'il respecte le format attendu pour les recommandations de contenus multimédias.
Pour créer un modèle, les recommandations multimédias nécessitent des données sur les événements utilisateur.
Pour ce guide, vous allez créer de faux événements view-item au cours des 90 derniers jours à partir de notes positives (< 4).
Créez une vue qui convertit la table des films dans le schéma
Documentdéfini par Google :bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_viewLa nouvelle vue comporte maintenant le schéma attendu par l'API Vertex AI Agent Builder.
Accédez à la page BigQuery de la console Google Cloud.
Dans le volet Explorateur, développez le nom de votre projet, développez l'ensemble de données
movielens, puis cliquez surmovies_viewpour ouvrir la la page de requête pour cette vue.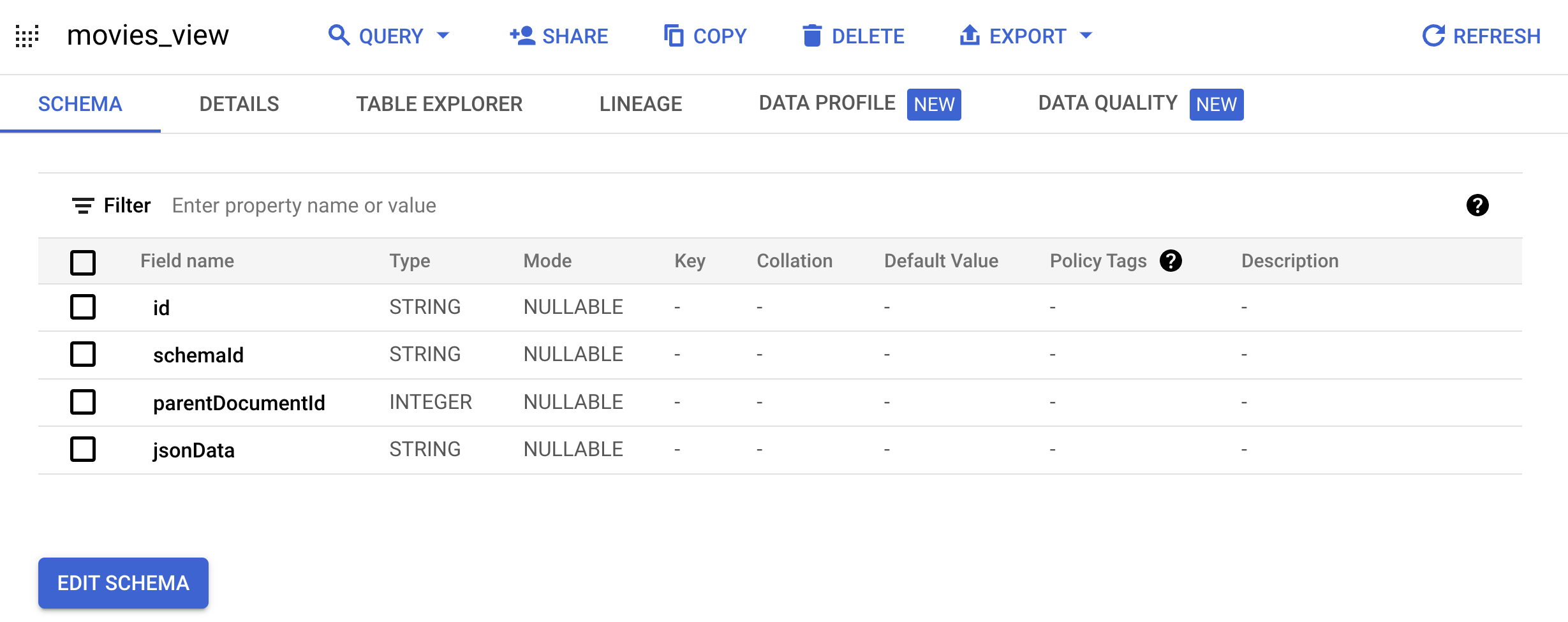
Accédez à l'onglet Explorateur de tables.
Dans le volet Requête générée, cliquez sur le bouton Copier dans la requête. L'éditeur de requête s'ouvre.
Cliquez sur Exécuter pour afficher les données du film dans la vue que vous avez créée.
Créez des événements utilisateur fictifs à partir des évaluations de films en exécutant la commande Cloud Shell suivante :
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_events
Activer Vertex AI Agent Builder
Dans la console Google Cloud, accédez à la page Agent Builder.
Lisez et acceptez les conditions d'utilisation, puis cliquez sur Continuer et activer l'API.
Créer une application pour les recommandations de contenus multimédias
Les procédures de cette section vous guident tout au long de la création et du déploiement d'une application de recommandations de contenus multimédias.
Dans la console Google Cloud, accédez à la page Agent Builder.
Cliquez sur
Créer l'application .Sur la page Créer une application, sélectionnez Recommandations.
Dans le champ Nom de l'application, saisissez le nom de votre application, par exemple
quickstart-media-recommendations. L'ID de votre application s'affiche sous le nom de l'application.Sous Contenu, sélectionnez Médias.
Sous Type de recommandations, assurez-vous que l'option Autres susceptibles de vous plaire est sélectionnée.
Sous Objectif d'entreprise, assurez-vous que l'option Taux de clics (CTR) est sélectionnée.
Cliquez sur Continuer.
Si vous avez terminé le tutoriel Premiers pas avec la recherche de médias et que vous disposez toujours du data store (nom suggéré :
quickstart-media-data-store), sélectionnez-le, cliquez sur Créer et passez à Entraîner le modèle de recommandation.Sur la page Datastores, cliquez sur Créer un data store.
Saisissez un nom à afficher pour votre datastore, tel que
quickstart-media-data-store, puis cliquez sur Créer.Sélectionnez le datastore que vous venez de créer, puis cliquez sur Créer pour créer votre application.
Importer des données
Importez ensuite les films et les données d'événements utilisateur qui ont été formatés précédemment.
Importer des documents
Ouvrez l'onglet Conditions requises.
Cliquez sur Importer des documents.
Sélectionnez BigQuery.
Saisissez le nom de la vue BigQuery
moviesque vous avez créée, puis cliquez sur Importer.PROJECT_ID.movielens.movies_viewAttendez que tous les documents aient été importés, ce qui devrait prendre environ 15 minutes. Il devrait y avoir 86 537 documents une fois l'opération terminée.
Vous pouvez consulter l'onglet Activité pour connaître l'état de l'opération d'importation. Une fois l'importation terminée, l'état de l'opération d'importation devient Terminée.
Importer des événements utilisateur
Ouvrez l'onglet Conditions requises.
Cliquez sur Importer des événements.
Sélectionnez BigQuery.
Saisissez le nom de la vue BigQuery
user_eventsque vous avez créée, puis cliquez sur Importer.PROJECT_ID.movielens.user_eventsAttendez qu'au moins un million d'événements aient été importés avant de passer à l'étape suivante, afin de satisfaire les exigences relatives aux données d'entraînement d'un nouveau modèle.
Vous pouvez consulter l'onglet Activité pour connaître l'état de l'opération. Le processus prend environ une heure, car vous importez des millions de lignes.
Il peut s'écouler un certain temps avant que l'onglet Conditions ne passe à l'état Exigences concernant les données remplies.
Entraîner le modèle de recommandation
Accédez à la page Configurations.
Cliquez sur l'onglet Traitement. Une configuration de diffusion a déjà été créée.
Si vous souhaitez ajuster les paramètres Rétrogradation des recommandations ou Diversification des résultats, vous pouvez ainsi sur cette page.
Cliquez sur l'onglet Entraînement.
Une fois les exigences en termes de données remplies, le modèle commence automatiquement l'entraînement. Vous pouvez consulter l'état de l'entraînement et du réglage sur cette page.
L'entraînement et la mise à disposition du modèle pour interrogation peuvent prendre quelques jours. Le champ Modèle prêt à interroger indique Oui lorsque le processus est terminé. Vous devrez actualiser la page pour que la valeur Non soit remplacée par Oui.
Prévisualiser les recommandations
Une fois le modèle prêt à être interrogé :
Dans le menu de navigation, cliquez sur
Aperçu .Cliquez sur le champ ID du document. La liste des ID des documents s'affiche.
Saisissez un ID de document (film) source, par exemple
4993pour "The Lord of the Rings: The Fellowship of the Ring (2001)".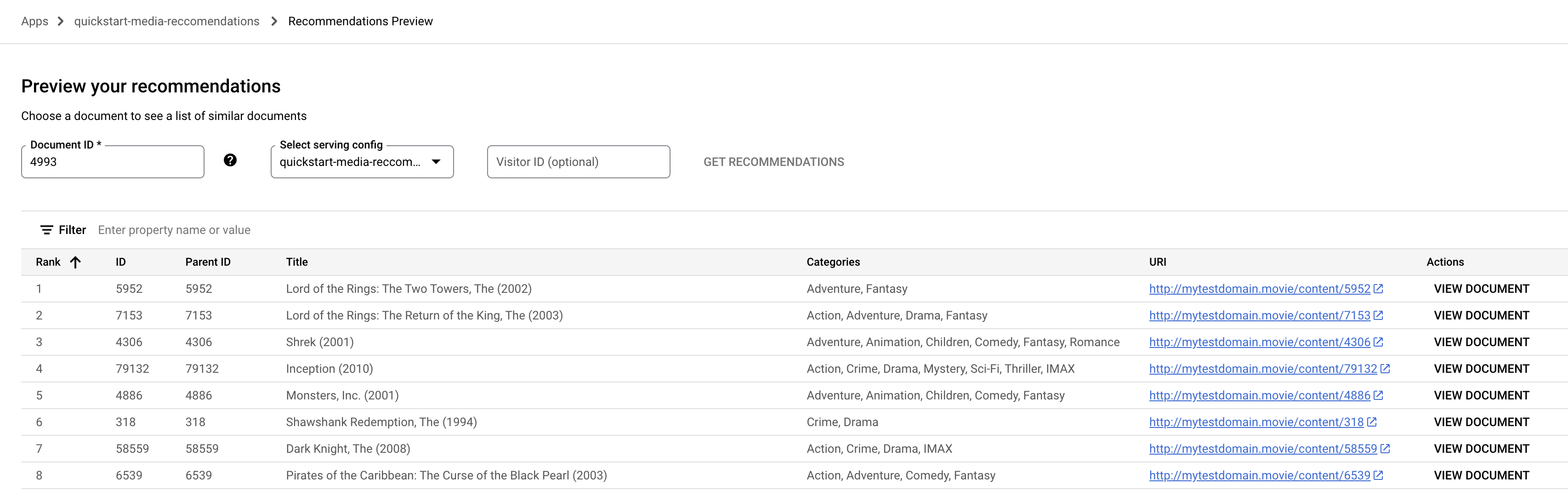
Sélectionnez le nom Configuration de diffusion dans le menu déroulant.
Cliquez sur Obtenir des recommandations. Une liste de documents recommandés s'affiche.
Déployer votre application pour les données structurées
Il n'existe aucun widget de recommandations pour le déploiement de votre application. Pour tester votre application avant le déploiement, procédez comme suit:
Accédez à la page Données, cliquez sur l'onglet Documents, puis copiez l'ID d'un document.
Accédez à la page Integration (Intégration). Cette page inclut un exemple de commande pour la méthode
servingConfigs.recommenddans l'API REST.Collez l'ID du document que vous avez copié précédemment dans le champ ID du document.
Laissez le champ Pseudo-ID utilisateur tel quel.
Copiez l'exemple de requête et exécutez-le dans Cloud Shell.
Pour découvrir comment intégrer l'application de recommandations à votre application Web, consultez les exemples de code sur la page Obtenir des recommandations multimédias.
Effectuer un nettoyage
Pour éviter que les ressources utilisées sur cette page soient facturées sur votre compte Google Cloud, procédez comme suit :
Vous pouvez réutiliser le data store que vous avez créé pour Media Search dans le Tutoriel Premiers pas avec la recherche de médias Suivez ce tutoriel avant d'effectuer cette procédure de nettoyage.
- Pour éviter des frais Google Cloud inutiles, supprimez votre projet à l'aide de la console Google Cloud si vous n'en avez plus besoin.
- Si vous avez créé un projet pour apprendre à utiliser les instances Vertex AI Agent Builder et que vous n'en avez plus besoin, supprimez-le.
- Si vous avez utilisé un projet Google Cloud existant, supprimez les ressources que vous avez créées pour éviter que des frais ne soient facturés sur votre compte. Pour en savoir plus, consultez la section Supprimer une application.
- Suivez la procédure décrite dans Désactiver Vertex AI Agent Builder.
Si vous avez créé un ensemble de données BigQuery, supprimez-le dans Cloud Shell :
bq rm --recursive --dataset movielens