Erste Schritte mit Medienempfehlungen
Erstellen Sie schnell eine hochmoderne App für Medienempfehlungen. Mit Medienempfehlungen können Ihre Zielgruppen personalisierte Inhalte entdecken, z. B. was sie als Nächstes ansehen oder lesen möchten. Die Ergebnisse haben dabei Google-Qualität und werden an die entsprechenden Optimierungsziele angepasst.
Allgemeine Informationen zu Vertex AI Search für Medien finden Sie unter Einführung in die Suche und Empfehlungen für Medien.In dieser Anleitung verwenden Sie das Dataset Movielens, um zu zeigen, wie Sie Ihren Medieninhaltskatalog und Ihre Nutzerereignisse in Vertex AI Search hochladen und einen personalisierten Film-Empfehlungsmodell trainieren. Das MovieLens-Dataset enthält einen Katalog an Filmen (Dokumenten) und Nutzer-Filmbewertungen (Nutzerereignisse).
In dieser Anleitung trainieren Sie ein Empfehlungsmodell des Typs „Was Ihnen sonst noch gefallen könnte“, das für die Klickrate (Click-through-Rate, CTR) optimiert ist. Nach dem Training kann das Modell Filme auf Basis einer Nutzer-ID und eines Seed-Films empfehlen.
Um die Mindestdatenanforderungen für das Modell zu erfüllen, wird jede positive Filmbewertung (4 oder höher) als Ereignis für die Wiedergabe eines Artikels behandelt.
Geschätzte Dauer, um dieses Tutorial abzuschließen:
- Erste Schritte für das Training des Modells: ca.1,5 Stunden.
- Warten auf das Modelltraining: ca. 24 Stunden. (Modell trainieren)
- Bewerten der Modellvorhersagen und Bereinigen: ca. 30 Minuten. (Empfehlungen in der Vorschau ansehen)
Wenn Sie die Anleitung Erste Schritte mit der Mediensuche abgeschlossen haben und den Datenspeicher noch haben (vorgeschlagener Name: quickstart-media-data-store), können Sie diesen Datenspeicher verwenden, anstatt einen weiteren zu erstellen. In diesem Fall sollten Sie die Anleitung mit dem Schritt App für Medienempfehlungen erstellen beginnen.
Ziele
- Hier erfahren Sie, wie Sie Mediendokumente und Nutzerereignisdaten aus BigQuery in Vertex AI Search importieren.
- Empfehlungsmodelle trainieren und bewerten
Bevor Sie mit dieser Anleitung beginnen, führen Sie die Schritte unter Bevor Sie beginnen aus.
Eine detaillierte Anleitung dazu finden Sie direkt in der Google Cloud Console. Klicken Sie dazu einfach auf Anleitung:
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Wählen Sie in der Liste Rolle auswählen eine Rolle aus.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Wählen Sie in der Liste Rolle auswählen eine Rolle aus.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
-
- Öffnen Sie die Google Cloud Konsole.
- Wählen Sie Ihr Google Cloud Projekt aus.
- Notieren Sie sich die Projekt-ID auf der Dashboard-Seite auf der Karte Projektinformationen. Sie benötigen die Projekt-ID für die folgenden Schritte.
Klicken Sie oben im Console-Fenster auf die Schaltfläche Cloud Shell aktivieren. Es öffnet sich eine Cloud Shell-Sitzung in einem neuen Rahmen im unteren Teil derGoogle Cloud -Console und zeigt eine Befehlszeilenaufforderung an. Weitere Möglichkeiten zum Starten von Cloud Shell finden Sie unter Cloud Shell starten.

Führen Sie die folgenden Elemente mit Ihrer Projekt-ID aus, um das Standardprojekt für die Befehlszeile festzulegen.
gcloud config set project PROJECT_IDErstellen Sie ein BigQuery-Dataset:
bq mk movielensLaden Sie
movies.csvin eine neuemovies-BigQuery-Tabelle:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresLaden Sie
ratings.csvin eine neueratings-BigQuery-Tabelle:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestampErstellen Sie eine Ansicht, die die Tabelle „Movies“ in das von Google definierte
Document-Schema konvertiert:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_viewDie neue Ansicht enthält jetzt das Schema, das von der AI Applications API erwartet wird.
Rufen Sie in der Google Cloud -Console die Seite BigQuery auf.
Maximieren Sie im Bereich Explorer den Projektnamen, maximieren Sie das Dataset
movielensund klicken Sie aufmovies_view, um das Abfrageseite für diese Ansicht aufrufen.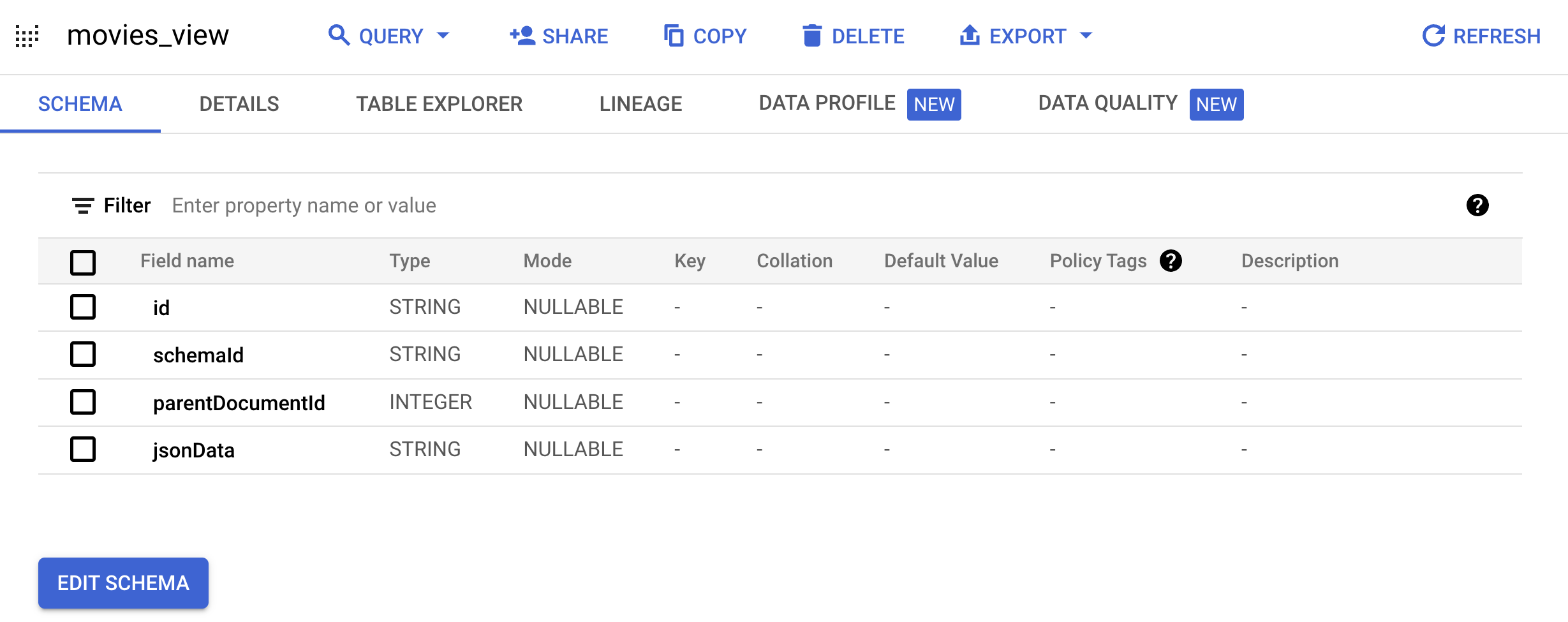
Rufen Sie den Tab Tabellen-Explorer auf.
Klicken Sie im Bereich Generierte Abfrage auf die Schaltfläche In Abfrage kopieren. Der Abfrageeditor wird geöffnet.
Klicken Sie auf Ausführen, um Filmdaten in der von Ihnen erstellten Ansicht anzuzeigen.
Erstellen Sie fiktive Nutzerereignisse aus Filmbewertungen mit dem folgenden Cloud Shell-Befehl:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsRufen Sie in der Google Cloud Console die Seite KI-Anwendungen auf.
Optional: Klicken Sie auf Google erlauben, selektiv Stichproben der Modelleingaben und ‑antworten zu erheben.
Klicken Sie auf Aktivieren und fortfahren.
Rufen Sie in der Google Cloud Console die Seite KI-Anwendungen auf.
Klicken Sie auf
App erstellen .Klicken Sie auf der Seite App erstellen unter Media-Empfehlungen auf Erstellen.
Geben Sie im Feld Anwendungsname
quickstart-media-recommendationseinen Namen für die Anwendung ein. Die Anwendungs-ID wird unter dem Namen der Anwendung angezeigt.Unter Art der Empfehlungen muss die Option Was Ihnen sonst noch gefallen könnte ausgewählt sein.
Unter Geschäftsziel muss die Option Klickrate (CTR, Click-through-Rate) ausgewählt sein.
Klicken Sie auf Weiter.
Datenspeicher erstellen.
Klicken Sie auf der Seite Datenspeicher auf Neuen Datenspeicher erstellen.
Geben Sie einen Anzeigenamen für den Datenspeicher ein, z. B.
quickstart-media-data-store, und klicken Sie dann auf Erstellen.
Wählen Sie den soeben erstellten Datenspeicher aus und klicken Sie auf Erstellen, um Ihre Anwendung zu erstellen.
Wählen Sie auf der Seite Dokumente importieren unter Native Quellen die Option BigQuery aus.
Geben Sie den Namen der von Ihnen erstellten BigQuery-Ansicht
moviesein und klicken Sie auf Importieren.PROJECT_ID.movielens.movies_viewWarten Sie, bis alle Dokumente importiert wurden. Dies dauert etwa 15 Minuten. Nach Abschluss sollten 86.537 Dokumente vorhanden sein.
Sie können den Status des Importvorgangs auf dem Tab Aktivität prüfen. Wenn der Import abgeschlossen ist, ändert sich der Status des Importvorgangs in Erfolgreich.
Klicken Sie im Tab Events auf Events importieren.
Wählen Sie auf der Seite „Dokumente importieren“ unter Native Quellen die Option BigQuery aus.
Geben Sie den Namen der von Ihnen erstellten BigQuery-Ansicht
user_eventsein und klicken Sie auf Importieren.PROJECT_ID.movielens.user_eventsWarten Sie, bis mindestens eine Million Ereignisse importiert wurden, bevor Sie mit dem nächsten Schritt fortfahren, um die Datenanforderungen für das Training eines neuen Modells zu erfüllen.
Sie können den Status des Vorgangs auf dem Tab Aktivität prüfen. Der Prozess dauert etwa eine Stunde, weil Sie Millionen von Zeilen importieren.
Auf dem Tab Datenqualität > Anforderungen können Sie prüfen, ob die Anforderungen erfüllt wurden. Auch nach dem Importieren der Nutzerereignisse kann es einige Zeit dauern, bis auf dem Tab Anforderungen der Status Datenanforderungen erfüllt angezeigt wird.
Rufen Sie die Seite Konfigurationen auf.
Klicken Sie auf den Tab Wird bereitgestellt. Es wurde bereits eine Bereitstellungskonfiguration erstellt.
Sie können die Einstellungen für die Herabstufung der Empfehlungen oder die Diversifizierung der Ergebnisse auf dieser Seite anpassen.
Klicken Sie auf den Tab Training.
Sobald die Datenanforderungen erfüllt sind, beginnt das Modell automatisch mit dem Training. Auf dieser Seite können Sie den Trainings- und Abstimmungsstatus ansehen.
Es kann einige Tage dauern, bis das Modell trainiert ist und bereit für Abfragen ist. Im Feld Bereit zum Abfragen des Modells wird Ja angezeigt, wenn der Vorgang abgeschlossen ist. Sie müssen die Seite aktualisieren, damit die Änderung von Nein zu Ja angezeigt wird.
Klicken Sie im Navigationsmenü auf
Vorschau .Klicken Sie auf das Feld Dokument-ID. Eine Liste der Dokument-IDs wird angezeigt.
Geben Sie eine Seed-Film-ID ein, z. B.
4993für „The Lord of the Rings: The Fellowship of the Ring (2001)“.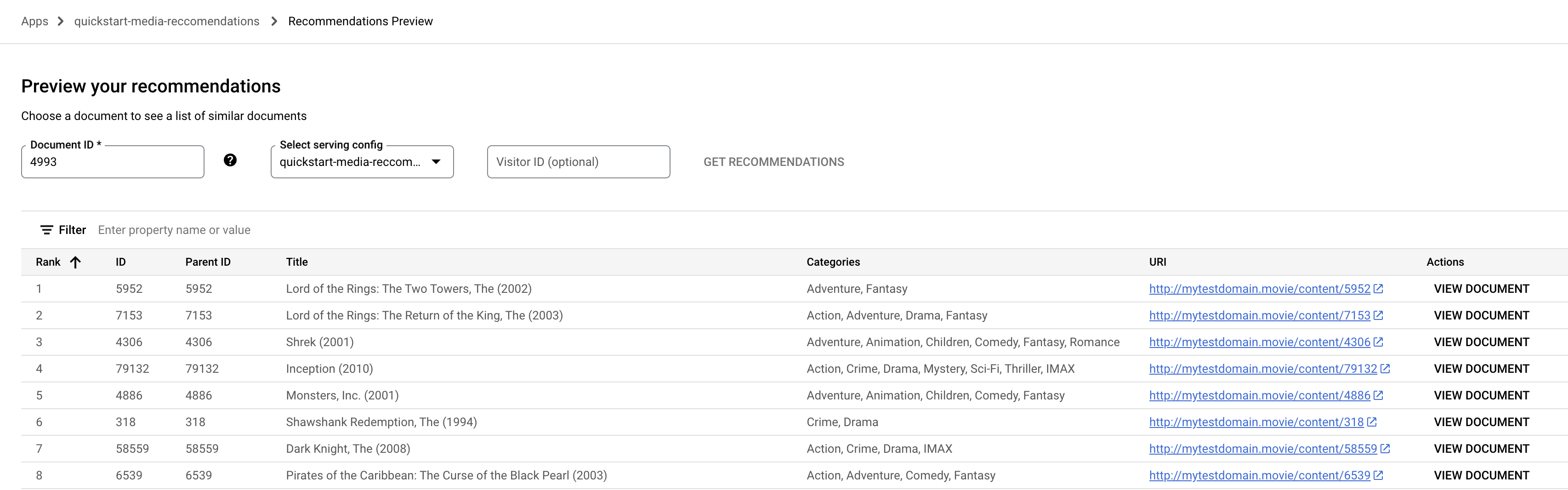
Wählen Sie im Drop-down-Menü den Namen Bereitstellungskonfiguration aus.
Klicken Sie auf Empfehlungen erhalten. Eine Liste mit empfohlenen Dokumenten wird angezeigt.
Rufen Sie die Seite Daten > Tab Dokumente auf und kopieren Sie die ID eines Dokuments.
Rufen Sie die Seite Einbindung auf. Diese Seite enthält einen Beispielbefehl für die Methode
servingConfigs.recommendin der REST API.Fügen Sie die zuvor kopierte Dokument-ID in das Feld Dokument-ID ein.
Lassen Sie das Feld Pseudo-ID des Nutzers unverändert.
Kopieren Sie die Beispielanfrage und führen Sie sie in Cloud Shell aus.
- Löschen Sie das Projekt mitGoogle Cloud console , wenn Sie es nicht benötigen, um unnötige Google Cloud -Kosten zu vermeiden.
- Wenn Sie ein neues Projekt erstellt haben, um mehr über die KI-Anwendungen zu erfahren, und dieses Projekt nicht mehr benötigen, löschen Sie das Projekt.
- Wenn Sie ein vorhandenes Google Cloud Projekt verwendet haben, löschen Sie die von Ihnen erstellten Ressourcen. So vermeiden Sie, dass Ihrem Konto Gebühren in Rechnung gestellt werden: Weitere Informationen finden Sie im Abschnitt Anwendung löschen.
- Folgen Sie der Anleitung unter Vertex AI Search deaktivieren.
Wenn Sie ein BigQuery-Dataset erstellt haben, löschen Sie es in Cloud Shell:
bq rm --recursive --dataset movielens
Dataset vorbereiten
Sie importieren das Movielens-Dataset mit Cloud Shell und strukturieren das Dataset für Vertex AI Search für Medien neu.
Cloud Shell öffnen
Dataset importieren
Das Movielens-Dataset ist in einem öffentlichen Cloud Storage-Bucket verfügbar, um den Import zu vereinfachen.
BigQuery-Ansichten erstellen
In diesem Schritt strukturieren Sie das Movielens-Dataset so um, dass es dem erwarteten Format für Medienempfehlungen entspricht.
Medienempfehlungen erfordern Nutzerereignisdaten, um ein Modell zu erstellen.
Für diesen Leitfaden erstellen Sie fiktive view-item-Ereignisse der letzten 90 Tagen aus positiven Bewertungen (>= 4).
KI-Anwendungen aktivieren
App für Medienempfehlungen erstellen
Die Verfahren in diesem Abschnitt führen Sie durch das Erstellen und Bereitstellen einer Anwendung für Medienempfehlungen.
Daten importieren
Importieren Sie als Nächstes die zuvor formatierten Filme und Nutzerereignisdaten.
Dokumente importieren
Importieren Sie das im Abschnitt BigQuery-Ansichten erstellen erzeigte movies_view-Dokument in Ihren quickstart-media-data-store-Datenspeicher.
Nutzerereignisse importieren
Importieren Sie die im Abschnitt BigQuery-Ansichten erstellen erzeugten user_events-Datensätze in Ihren Datenspeicher.
Empfehlungsmodell trainieren
Vorschau von Empfehlungen
Sobald das Modell zum Abfragen bereit ist:
App für strukturierte Daten bereitstellen
Es gibt kein Empfehlungs-Widget für die Bereitstellung Ihrer App. So testen Sie Ihre Anwendung vor der Bereitstellung:
Hilfe bei der Integration der Empfehlungs-App in Ihre Webanwendung erhalten Sie in den Codebeispielen unter Medienempfehlungen erhalten
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden:
Sie können den Datenspeicher, den Sie für die Mediensuche in der Anleitung Erste Schritte mit der Mediensuche erstellt haben, wiederverwenden. Arbeiten Sie diese Anleitung durch, bevor Sie diesen Bereinigungsvorgang ausführen.