Inizia a usare suggerimenti sui contenuti multimediali
Puoi creare rapidamente un'app di suggerimenti sui contenuti multimediali all'avanguardia. I suggerimenti sui contenuti multimediali consentono ai tuoi segmenti di pubblico di scoprire contenuti più personalizzati, ad esempio cosa guardare o leggere in seguito, con risultati di qualità Google personalizzati in base agli obiettivi di ottimizzazione.
Per informazioni generali su Vertex AI Search per i contenuti multimediali, consulta Introduzione alla ricerca e ai suggerimenti di contenuti multimediali.In questo tutorial introduttivo, utilizzerai il set di dati Movielens per scoprire come caricare il tuo catalogo di contenuti multimediali e gli eventi utente in Vertex AI Search, nonché come addestrare un modello personalizzato che suggerisce film. Il set di dati Movielens contiene un catalogo di film (documenti) e le valutazioni dei film da parte degli utenti (eventi utente).
In questo tutorial, imparerai ad addestrare un modello di suggerimenti di tipo "Altri che ti potrebbero piacere", ottimizzato per la percentuale di clic (CTR). Dopo l'addestramento, il modello può suggerire i film in base a un ID utente e a un film di riferimento.
Per soddisfare i requisiti minimi dei dati per il modello, ogni valutazione positiva di un film (4 o superiore) viene considerata come evento "view-item", ovvero di visualizzazione dell'elemento.
Tempo stimato per completare questo tutorial:
- Primi passaggi per iniziare l'addestramento del modello: circa 1,5 ore.
- Attesa dell'addestramento del modello: circa 24 ore. (Addestra il modello)
- Valutazione delle previsioni del modello e pulizia: circa 30 minuti. (Anteprima dei consigli)
Se hai completato il tutorial Inizia a usare la ricerca di contenuti multimediali e hai ancora il datastore (nome suggerito quickstart-media-data-store), puoi utilizzarlo invece di crearne un altro. In questo caso, dovresti iniziare il tutorial dal
passaggio Crea un'app per i suggerimenti di contenuti multimediali.
Obiettivi
- Scopri come importare documenti multimediali e dati di eventi utente da BigQuery a Vertex AI Search.
- Addestra e valuta i modelli di suggerimenti.
Prima di seguire questo tutorial, assicurati di aver svolto i passaggi descritti in Prima di iniziare.
Per seguire le indicazioni dettagliate per questa attività direttamente nella Google Cloud console, fai clic su Procedura guidata:
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Nell'elenco Seleziona un ruolo, seleziona un ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo aggiuntivo.
- Fai clic su Salva.
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Nell'elenco Seleziona un ruolo, seleziona un ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo aggiuntivo.
- Fai clic su Salva.
-
- Apri Google Cloud console.
- Selezionare il tuo progetto Google Cloud .
- Prendi nota dell'ID progetto nella scheda Informazioni sul progetto nella pagina della dashboard. Avrai bisogno dell'ID progetto per le procedure seguenti.
Fai clic sul pulsante Attiva Cloud Shell nella parte superiore della console. All'interno di un nuovo frame nella parte inferiore della consoleGoogle Cloud si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando. Per altri modi per avviare Cloud Shell, consulta Avviare Cloud Shell.

Esegui il comando seguente utilizzando l'ID progetto in modo da impostare il progetto predefinito per la riga di comando.
gcloud config set project PROJECT_IDCrea un set di dati BigQuery:
bq mk movielensCarica
movies.csvin una nuova tabella BigQuerymovies:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresCarica
ratings.csvin una nuova tabella BigQueryratings:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestampCrea una visualizzazione che converte la tabella dei film nel formato Schema
Documentdefinito da Google:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_viewOra la nuova vista ha lo schema previsto dall'API AI Applications.
Vai alla pagina BigQuery nella Google Cloud console.
Nel riquadro Explorer espandi il nome del progetto, quindi il set di dati
movielense fai clic sumovies_viewper aprire la pagina di query per questa vista.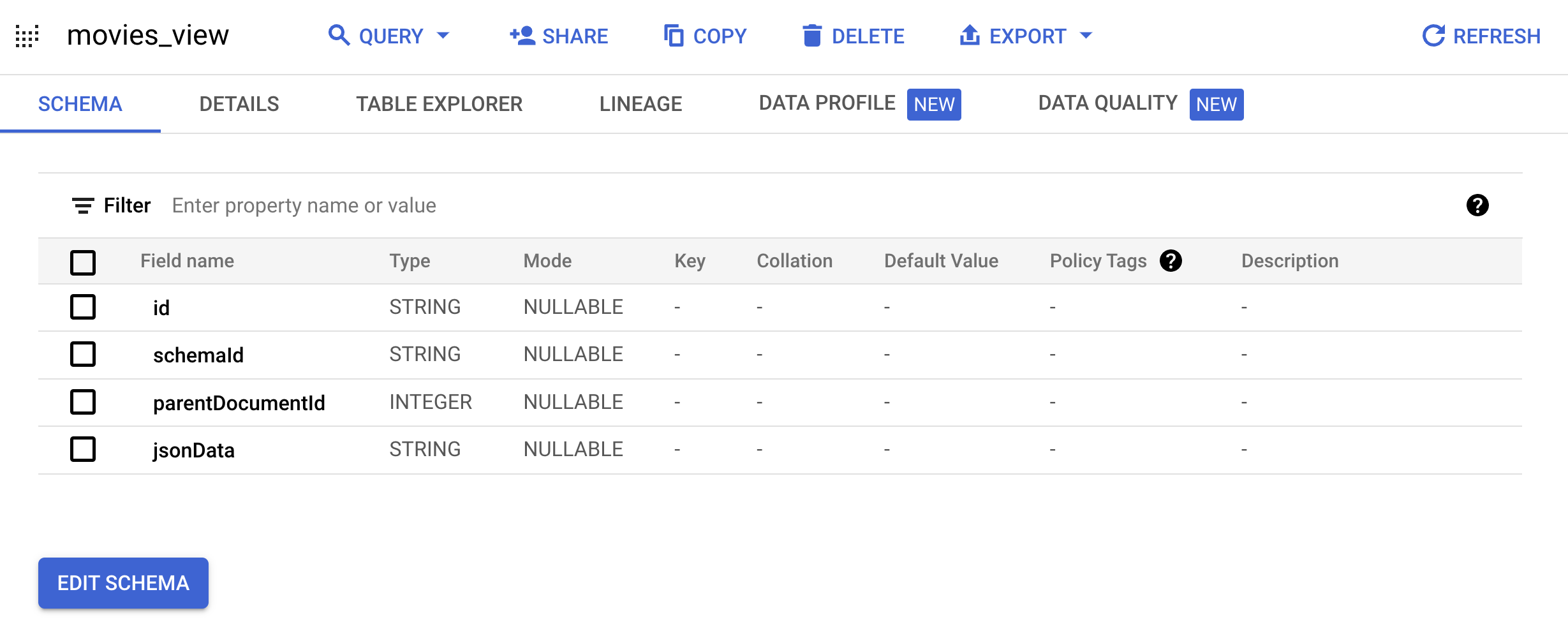
Vai alla scheda Esplora tabelle.
Nel riquadro Query generata, fai clic sul pulsante Copia nella query. Si apre l'editor di query.
Fai clic su Esegui per vedere i dati dei film nella vista che hai creato.
Per creare eventi utente fittizi partendo dalle valutazioni dei film, esegui questo comando Cloud Shell:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsNella Google Cloud console, vai alla pagina AI Applications.
(Facoltativo) Fai clic su Consenti a Google di campionare selettivamente gli input e le risposte del modello.
Fai clic su Continua e attiva l'API.
Nella Google Cloud console, vai alla pagina AI Applications.
Fai clic su
Crea app .Nella pagina Crea app, fai clic su Crea in Suggerimenti sui contenuti multimediali.
Nel campo Nome app, inserisci un nome per l'app, ad esempio
quickstart-media-recommendations. L'ID dell'app è riportato sotto il nome dell'app.In Tipo di suggerimenti, assicurati che sia selezionata l'opzione Altri che ti potrebbero piacere.
In Obiettivo commerciale, assicurati che sia selezionata l'opzione Percentuale di clic (CTR).
Fai clic su Continua.
Crea un datastore.
Nella pagina Datastore, fai clic su Crea datastore.
Inserisci un nome visualizzato per il datastore, ad esempio
quickstart-media-data-store, poi fai clic su Crea.
Seleziona il datastore appena creato, poi fai clic su Crea per creare la tua app.
In Origini native nella pagina Importa documenti, seleziona BigQuery.
Inserisci il nome della vista BigQuery
moviesche hai creato e fai clic su Importa.PROJECT_ID.movielens.movies_viewAttendi che siano stati importati tutti i documenti. L'operazione dovrebbe richiedere circa 15 minuti. Al termine, dovrebbero essere presenti 86.537 documenti.
Puoi controllare lo stato dell'operazione di importazione nella scheda Attività. Quando l'importazione viene completata, lo stato dell'operazione diventa Completato.
Nella scheda Eventi, fai clic su Importa eventi.
In Origini native nella pagina Importa documenti, seleziona BigQuery.
Inserisci il nome della vista BigQuery
user_eventsche hai creato e fai clic su Importa.PROJECT_ID.movielens.user_eventsAttendi che sia stato importato almeno un milione di eventi prima di andare al passaggio successivo, in modo da soddisfare i requisiti dei dati per l'addestramento di un nuovo modello.
Puoi controllare lo stato dell'operazione nella scheda Attività. Il completamento del processo richiede circa un'ora, dato che è in corso l'importazione di milioni di righe.
Per verificare se i requisiti sono stati soddisfatti, vai alla scheda Qualità dei dati > Requisiti. Anche dopo l'importazione degli eventi utente, può essere necessario un po' di tempo prima che lo stato della scheda Requisiti venga aggiornato in Requisiti dei dati soddisfatti.
Vai alla pagina Configurazioni.
Fai clic sulla scheda Pubblicazione. È già stata creata una configurazione di pubblicazione.
Se vuoi modificare le impostazioni Retrocessione dei suggerimenti o Diversificazione dei risultati, puoi farlo in questa pagina.
Fai clic sulla scheda Addestramento.
Una volta soddisfatti i requisiti dei dati, inizia l'addestramento del modello automaticamente. In questa pagina puoi visualizzare lo stato dell'addestramento e dell'ottimizzazione.
Potrebbero essere necessari un paio di giorni prima che il modello venga addestrato e preparato alle query. Il campo Pronto per ricevere query indica Sì al termine del processo. Occorre aggiornare la pagina per vedere che No diventa Sì.
Nel menu di navigazione, fai clic su
Anteprima .Fai clic sul campo ID documento. Viene visualizzato un elenco di ID documento.
Inserisci un ID documento di riferimento (film), ad esempio
4993per "Il Signore degli Anelli: La Compagnia dell'Anello (2001)".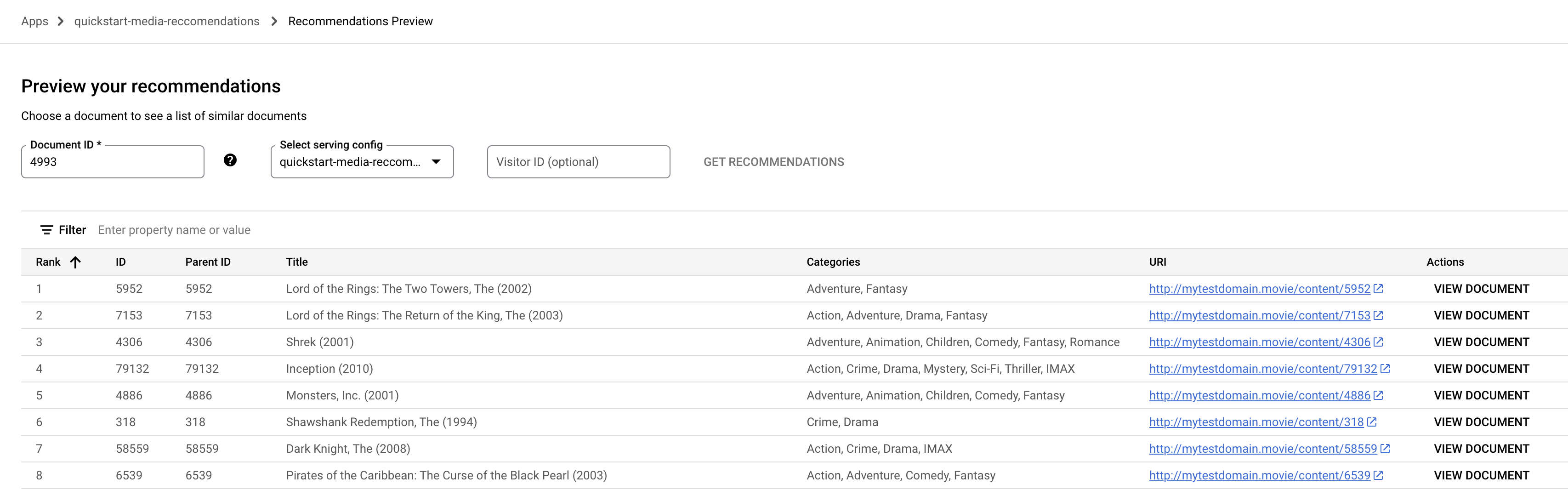
Seleziona il nome della Configurazione di pubblicazione dal menu a discesa.
Fai clic su Ricevi suggerimenti. Viene visualizzato un elenco di documenti suggeriti.
Vai alla scheda Documenti nella pagina Dati e copia un ID documento.
Vai alla pagina Integrazione. Questa pagina include un comando di esempio per il metodo
servingConfigs.recommendnell'API REST.Incolla l'ID documento che hai copiato in precedenza nel campo ID documento.
Lascia invariato il campo Pseudo ID utente.
Copia la richiesta di esempio ed eseguila in Cloud Shell.
- Per evitare addebiti non necessari di Google Cloud , utilizzaGoogle Cloud console per eliminare il progetto se non ti serve.
- Se hai creato un nuovo progetto per prendere dimestichezza con AI Applications, ma non ne hai più bisogno, elimina il progetto.
- Se hai utilizzato un progetto Google Cloud esistente, elimina le risorse che hai creato per evitare addebiti sul tuo account. Per ulteriori informazioni, vedi Elimina un'app.
- Segui i passaggi descritti in Disattiva Vertex AI Search.
Se hai creato un set di dati BigQuery, eliminalo in Cloud Shell:
bq rm --recursive --dataset movielens
Prepara il set di dati
Puoi utilizzare Cloud Shell per importare il set di dati Movielens e ristrutturarlo per usarlo in Vertex AI Search per i contenuti multimediali.
Apri Cloud Shell
Importa il set di dati
Il set di dati Movielens è disponibile in un bucket Cloud Storage pubblico per semplificarne l'importazione.
Crea le viste BigQuery
In questo passaggio ristrutturerai il set di dati Movielens in modo che rispetti il formato previsto per i suggerimenti sui contenuti multimediali.
Per creare un modello, i suggerimenti sui contenuti multimediali richiedono dati di eventi utente.
Per questa guida, creerai eventi view-item fittizi negli ultimi 90 giorni
a partire da valutazioni positive (>= 4).
Attivare AI Applications
Crea un'app di suggerimenti sui contenuti multimediali
Le procedure descritte in questa sezione ti guideranno attraverso la creazione e il deployment di un'app di suggerimenti sui contenuti multimediali.
Importa dati
Devi quindi importare i dati sui film e sugli eventi utente formattati in precedenza.
Importa documenti
Importa il documento movies_view creato nella sezione
Creare viste BigQuery nel tuo
quickstart-media-data-store datastore.
Importa gli eventi utente
Importa i record user_events creati nella sezione Creare viste BigQuery nel tuo datastore.
Addestrare il modello di suggerimenti
Visualizza un'anteprima dei suggerimenti
Quando il modello è pronto per ricevere query:
Esegui il deployment dell'app per i dati strutturati
Non esiste un widget dei suggerimenti per il deployment della tua app. Per eseguire il test dell'app prima del deployment:
Per assistenza nell'integrazione dell'app di suggerimenti nella tua app web, consulta gli esempi di codice in Ricevere suggerimenti sui contenuti multimediali.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa pagina, segui questi passaggi.
Puoi riutilizzare il datastore creato per la ricerca di contenuti multimediali nel tutorial Inizia a usare la ricerca di contenuti multimediali. Prova questo tutorial prima di eseguire la procedura di pulizia.