Mulai menggunakan rekomendasi media
Anda dapat dengan cepat membangun aplikasi rekomendasi media canggih. Rekomendasi media memungkinkan audiens Anda menemukan konten yang lebih dipersonalisasi, seperti hal untuk ditonton atau dibaca berikutnya, dengan hasil berkualitas Google yang disesuaikan dengan tujuan pengoptimalan.
Untuk mengetahui informasi umum tentang Vertex AI Search untuk media, lihat Pengantar penelusuran dan rekomendasi media.Dalam tutorial memulai ini, Anda akan menggunakan set data Movielens untuk mendemonstrasikan cara mengupload katalog konten media dan peristiwa pengguna ke Vertex AI Search serta melatih model rekomendasi film yang dipersonalisasi. Set data Movielens berisi katalog film (dokumen) dan rating film pengguna (peristiwa pengguna).
Dalam tutorial ini, Anda akan melatih model rekomendasi berjenis Lainnya yang Mungkin Anda Sukai yang dioptimalkan untuk rasio klik-tayang (CTR). Setelah pelatihan, model dapat merekomendasikan film berdasarkan ID pengguna dan film awal.
Untuk memenuhi persyaratan data minimum model, setiap rating film positif (4 atau lebih tinggi) diperlakukan sebagai peristiwa lihat item.
Perkiraan waktu untuk menyelesaikan tutorial ini:
- Langkah-langkah awal untuk mulai melatih model: ~1,5 jam.
- Menunggu model dilatih: ~24 jam. (Melatih model)
- Mengevaluasi prediksi model dan membersihkan: ~30 menit. (Pratinjau rekomendasi)
Jika Anda telah menyelesaikan tutorial Mulai menggunakan penelusuran media dan masih memiliki penyimpanan data (nama yang disarankan quickstart-media-data-store), Anda dapat menggunakan penyimpanan data tersebut, bukan
membuat penyimpanan data lain. Dalam hal ini, Anda harus memulai tutorial di
Membuat aplikasi untuk rekomendasi media.
Tujuan
- Pelajari cara mengimpor data dokumen media dan peristiwa pengguna dari BigQuery ke Vertex AI Search.
- Latih dan evaluasi model rekomendasi.
Sebelum mengikuti tutorial ini, pastikan Anda telah melakukan langkah-langkah di bagian Sebelum Anda memulai.
Untuk mengikuti panduan langkah demi langkah tugas ini langsung di Google Cloud konsol, klik Pandu saya:
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Buka IAM - Pilih project.
- Klik Grant access.
-
Di kolom New principals, masukkan ID pengguna Anda. Biasanya berupa alamat email untuk Akun Google.
- Di daftar Select a role, pilih peran.
- Untuk memberikan peran tambahan, klik Tambahkan peran lain, lalu tambahkan setiap peran tambahan.
- Klik Simpan.
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the AI Applications, Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Buka IAM - Pilih project.
- Klik Grant access.
-
Di kolom New principals, masukkan ID pengguna Anda. Biasanya berupa alamat email untuk Akun Google.
- Di daftar Select a role, pilih peran.
- Untuk memberikan peran tambahan, klik Tambahkan peran lain, lalu tambahkan setiap peran tambahan.
- Klik Simpan.
-
- Buka Google Cloud console.
- Pilih project Google Cloud Anda.
- Catat ID project di kartu Project info di halaman dasbor. Anda akan memerlukan project ID untuk prosedur berikut.
Klik tombol Activate Cloud Shell di bagian atas konsol. Sesi Cloud Shell akan terbuka di dalam frame baru di bagian bawah konsolGoogle Cloud dan menampilkan perintah command line. Untuk cara lain meluncurkan Cloud Shell, lihat Meluncurkan Cloud Shell.

Jalankan perintah berikut menggunakan project ID Anda untuk menetapkan project default untuk command line.
gcloud config set project PROJECT_IDBuat set data BigQuery:
bq mk movielensMuat
movies.csvke dalam tabel BigQuerymoviesbaru:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genresMuat
ratings.csvke dalam tabel BigQueryratingsbaru:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestampBuat tampilan yang mengonversi tabel film menjadi skema
Documentyang ditentukan Google:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_viewSekarang, tampilan baru memiliki skema yang diharapkan oleh AI Applications API.
Buka halaman BigQuery di konsol Google Cloud .
Di panel Explorer, luaskan nama project Anda, luaskan set data
movielens, lalu klikmovies_viewuntuk membuka halaman kueri untuk tampilan ini.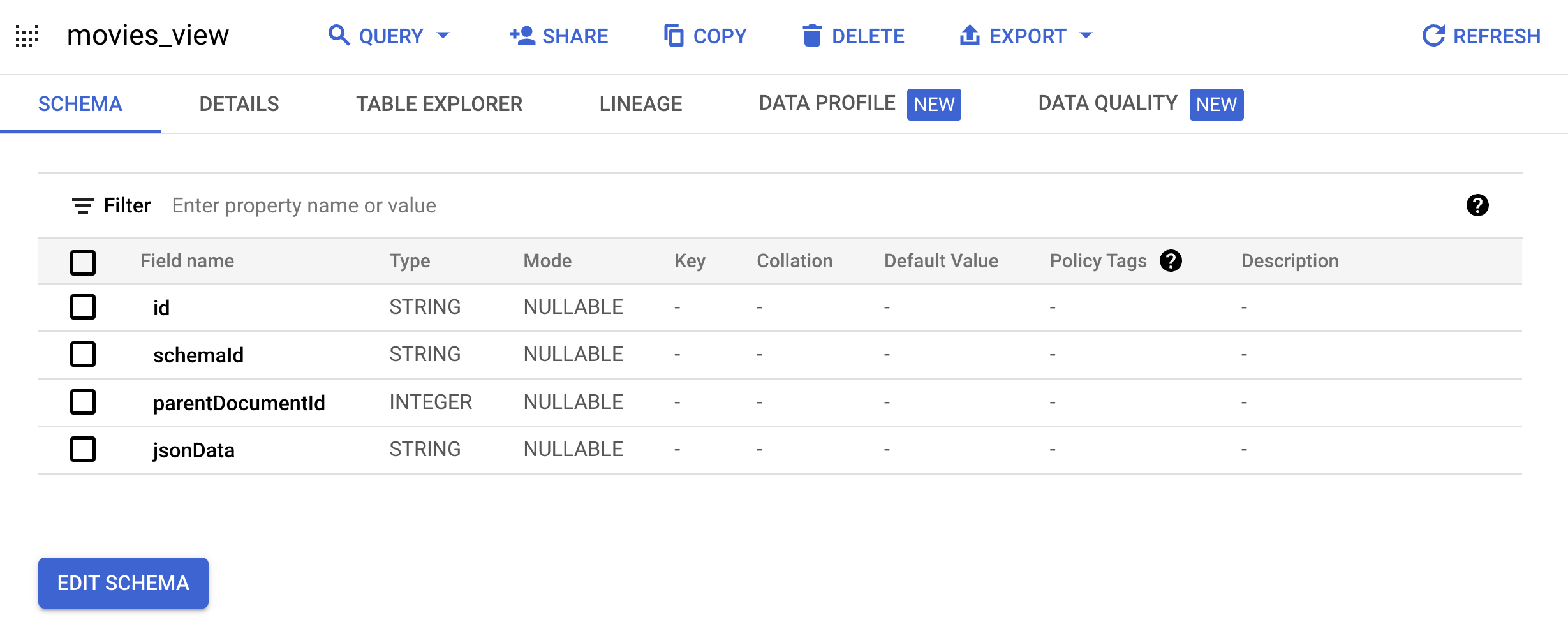
Buka tab Table explorer.
Di panel Kueri yang dihasilkan, klik tombol Salin ke kueri. Editor kueri akan terbuka.
Klik Run untuk melihat data film dalam tampilan yang Anda buat.
Buat peristiwa pengguna fiktif dari rating film dengan menjalankan perintah Cloud Shell berikut:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_eventsDi konsol Google Cloud , buka halaman AI Applications.
Opsional: Klik Izinkan Google mengambil sampel input dan respons model secara selektif.
Klik Continue and activate the API.
Di konsol Google Cloud , buka halaman AI Applications.
Klik
Buat aplikasi .Di halaman Create app, pada bagian Media recommendations, klik Create.
Di kolom Nama aplikasi, masukkan nama untuk aplikasi Anda, seperti
quickstart-media-recommendations. ID aplikasi Anda akan muncul di bawah nama aplikasi.Di bagian Jenis rekomendasi, pastikan Lainnya yang mungkin Anda sukai dipilih.
Di bagian Tujuan Bisnis, pastikan Rasio klik-tayang (CTR) dipilih.
Klik Lanjutkan.
Buat penyimpanan data.
Di halaman Data Stores, klik Create data store.
Masukkan nama tampilan untuk penyimpanan data Anda, seperti
quickstart-media-data-store, lalu klik Buat.
Pilih penyimpanan data yang baru saja Anda buat, lalu klik Buat untuk membuat aplikasi Anda.
Di bagian Sumber native di halaman Impor dokumen, pilih BigQuery.
Masukkan nama tampilan BigQuery yang Anda buat, lalu klik Impor.
moviesPROJECT_ID.movielens.movies_viewTunggu hingga semua dokumen selesai diimpor, yang akan memakan waktu sekitar 15 menit. Setelah selesai, akan ada 86537 dokumen.
Anda dapat memeriksa tab Aktivitas untuk mengetahui status operasi impor. Setelah impor selesai, status operasi impor akan berubah menjadi Selesai.
Di tab Acara, klik Impor Acara.
Di bagian Sumber asli di halaman Impor dokumen, pilih BigQuery.
Masukkan nama tampilan BigQuery
user_eventsyang Anda buat, lalu klik Impor.PROJECT_ID.movielens.user_eventsTunggu hingga minimal satu juta peristiwa diimpor sebelum melanjutkan ke langkah berikutnya, untuk memenuhi persyaratan data guna melatih model baru.
Anda dapat memeriksa tab Aktivitas untuk mengetahui status operasi. Proses ini memerlukan waktu sekitar satu jam karena Anda mengimpor jutaan baris.
Untuk melihat apakah persyaratan telah dipenuhi, buka tab Kualitas data > Persyaratan. Bahkan setelah peristiwa pengguna diimpor, perlu waktu beberapa saat agar tab Persyaratan memperbarui statusnya menjadi Persyaratan data terpenuhi.
Buka halaman Konfigurasi.
Klik tab Penayangan. Konfigurasi inferensi telah dibuat.
Jika ingin menyesuaikan setelan Penurunan rekomendasi atau Diversifikasi hasil, Anda dapat melakukannya di halaman ini.
Klik tab Training.
Setelah persyaratan data terpenuhi, model akan mulai dilatih secara otomatis. Anda dapat melihat status pelatihan dan penyesuaian di halaman ini.
Mungkin perlu waktu beberapa hari agar model dilatih dan siap untuk dikueri. Kolom Siap dikueri menunjukkan Ya saat proses selesai. Anda perlu memuat ulang halaman untuk melihat perubahan Tidak menjadi Ya.
Di menu navigasi, klik
Pratinjau .Klik kolom ID Dokumen. Daftar ID dokumen akan muncul.
Masukkan ID dokumen awal (film), seperti
4993untuk "The Lord of the Rings: The Fellowship of the Ring (2001)".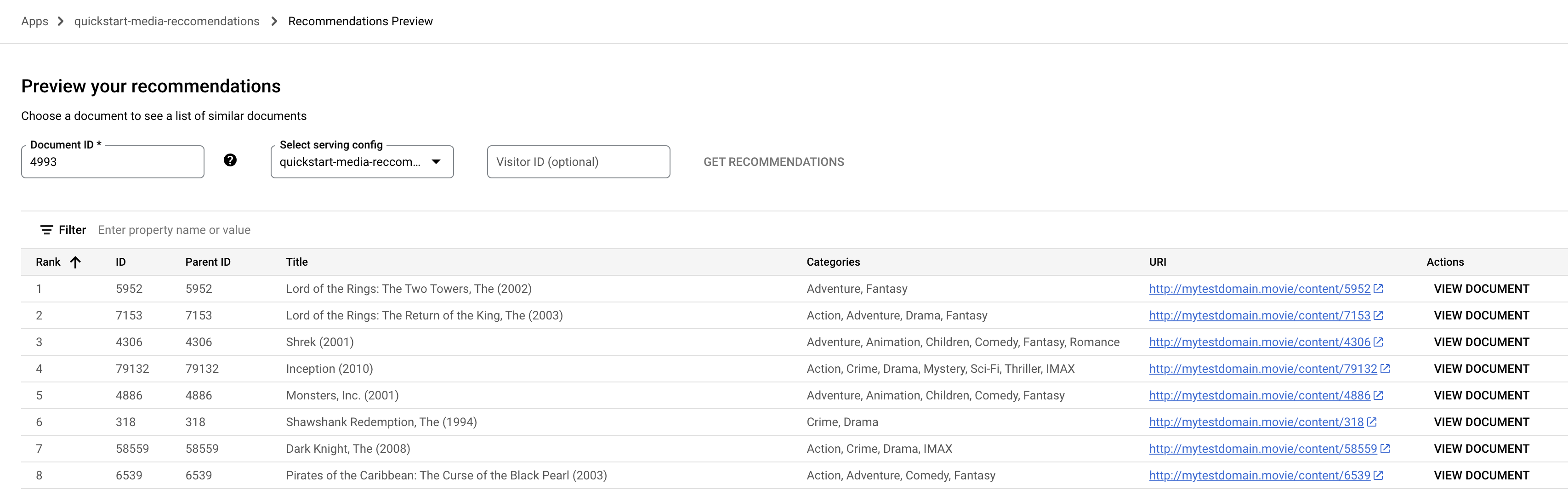
Pilih nama Konfigurasi penayangan dari menu drop-down.
Klik Dapatkan rekomendasi. Daftar dokumen yang direkomendasikan akan muncul.
Buka halaman Data, tab Dokumen, dan salin ID dokumen.
Buka halaman Integrasi. Halaman ini menyertakan contoh perintah untuk metode
servingConfigs.recommenddi REST API.Tempelkan ID dokumen yang Anda salin sebelumnya ke kolom Document ID.
Biarkan kolom ID Pseudo Pengguna apa adanya.
Salin contoh permintaan dan jalankan di Cloud Shell.
- Untuk menghindari biaya yang tidak perlu, gunakan Google Cloud console untuk menghapus project Anda jika tidak lagi diperlukan. Google Cloud
- Jika Anda membuat project baru untuk mempelajari Aplikasi AI dan Anda tidak lagi memerlukan project tersebut, hapus project tersebut.
- Jika Anda menggunakan project Google Cloud yang sudah ada, hapus resource yang Anda buat untuk menghindari tagihan pada akun Anda. Untuk mengetahui informasi selengkapnya, lihat Menghapus aplikasi.
- Ikuti langkah-langkah di Menonaktifkan Vertex AI Search.
Jika Anda membuat set data BigQuery, hapus set data tersebut di Cloud Shell:
bq rm --recursive --dataset movielens
Menyiapkan set data
Anda menggunakan Cloud Shell untuk mengimpor set data Movielens dan menyusun ulang set data untuk Vertex AI Search for Media.
Buka Cloud Shell
Mengimpor set data
Set data Movielens tersedia di bucket Cloud Storage publik untuk mempermudah pengimporan.
Membuat tampilan BigQuery
Pada langkah ini, Anda akan menyusun ulang set data Movielens agar mengikuti format yang diharapkan untuk rekomendasi media.
Rekomendasi media memerlukan data peristiwa pengguna untuk membuat model.
Untuk panduan ini, Anda membuat peristiwa view-item palsu selama 90 hari terakhir dari rating positif (>= 4).
Mengaktifkan Aplikasi AI
Membuat aplikasi untuk rekomendasi media
Prosedur di bagian ini memandu Anda dalam membuat dan men-deploy aplikasi rekomendasi media.
Mengimpor data
Selanjutnya, impor data film dan peristiwa pengguna yang telah diformat sebelumnya.
Mengimpor dokumen
Impor dokumen movies_view yang dibuat di bagian
Buat tampilan BigQuery ke penyimpanan data
quickstart-media-data-store Anda.
Mengimpor peristiwa pengguna
Impor user_events catatan yang dibuat di bagian
Buat tampilan BigQuery ke penyimpanan data Anda.
Melatih model rekomendasi
Pratinjau rekomendasi
Setelah model siap untuk dikueri:
Men-deploy aplikasi Anda untuk data terstruktur
Tidak ada widget rekomendasi untuk men-deploy aplikasi Anda. Untuk menguji aplikasi Anda sebelum deployment:
Untuk mendapatkan bantuan dalam mengintegrasikan aplikasi rekomendasi ke dalam aplikasi web Anda, lihat contoh kode di Mendapatkan rekomendasi media.
Pembersihan
Agar akun Google Cloud Anda tidak dikenai biaya untuk resource yang digunakan pada halaman ini, ikuti langkah-langkah berikut.
Anda dapat menggunakan kembali penyimpanan data yang Anda buat untuk penelusuran media dalam tutorial Mulai menggunakan penelusuran media. Coba tutorial tersebut sebelum melakukan prosedur pembersihan ini.