Questa pagina mostra come utilizzare l'API per ottenere riepiloghi della ricerca con i risultati di ricerca. Spiega anche le opzioni disponibili con i riepiloghi della ricerca. Solo per dati non strutturati e di siti web.
Per informazioni su come ottenere risposte di AI generativa per le query sui dati sanitari, consulta Ricerca utilizzando query in linguaggio naturale con risposta di AI generativa.
Prima di iniziare
A seconda del tipo di app, soddisfa i seguenti requisiti:
Per un'app di ricerca non strutturata: attiva l'opzione Funzionalità LLM avanzate.
Per un'app di ricerca di siti web, attiva le seguenti funzionalità:
Indicizzazione avanzata dei siti web. Richiede la verifica del dominio.
Ottenere un riepilogo della ricerca
Un riepilogo della ricerca è un breve riassunto dei primi uno o più risultati di ricerca restituiti in una risposta di ricerca. Il riepilogo stesso viene estratto dalle risposte estrattive restituite nella risposta. Pertanto, per ottenere un riepilogo, devi anche ottenere risposte estrattive con i risultati di ricerca. Per ulteriori informazioni, vedi Ottenere risposte estrattive (anteprima).
L'immagine seguente mostra il riepilogo quando i PDF in un datastore vengono interrogati con
summaryResultCount impostato su 5. I contenuti del riepilogo possono variare a seconda
delle configurazioni dell'app.
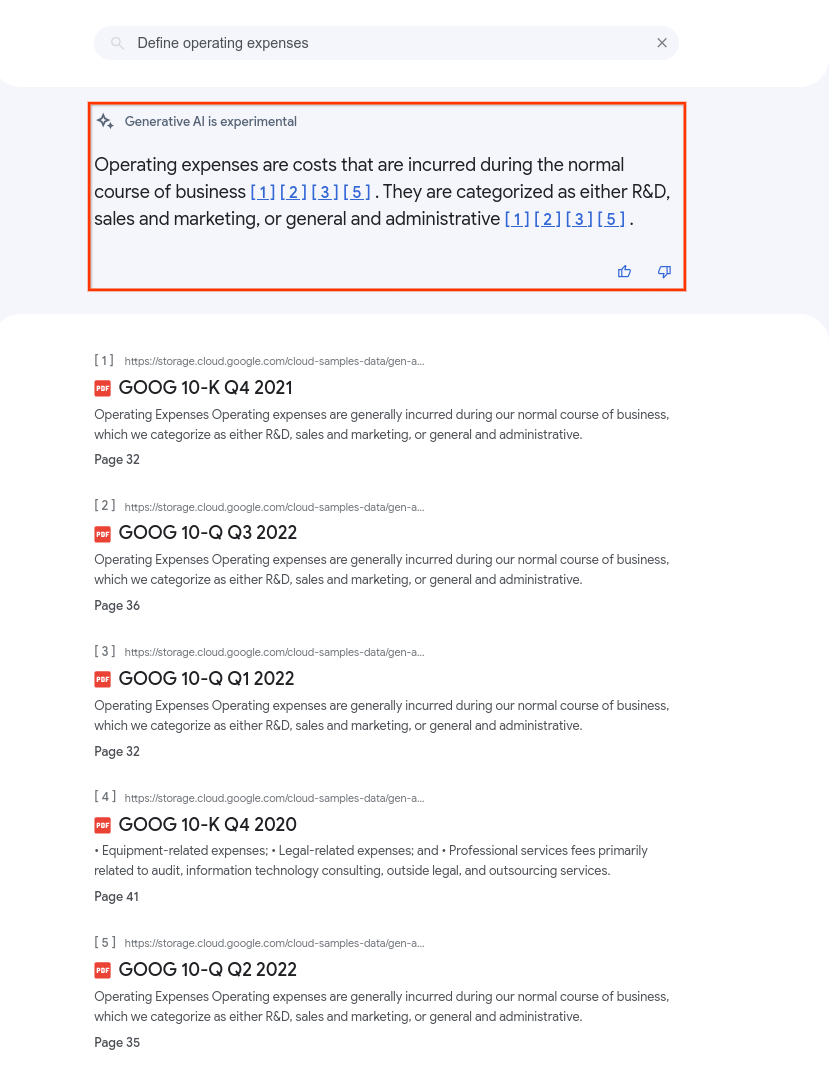
I riepiloghi della ricerca possono includere testo formattato in Markdown e semplici tag HTML comunemente compresi dai parser Markdown. Per questo motivo, valuta la possibilità di utilizzare un parser Markdown nella tua applicazione per eseguire il rendering del testo Markdown.
Per ottenere un riepilogo della ricerca:
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifica i valori persummaryResultCountemaxExtractiveAnswerCount. Per ulteriori informazioni sull'invio di una richiesta di ricerca, vedi Ottenere i risultati di ricerca.Nel seguente esempio,
summarySpecindica che vuoi un riepilogo della ricerca e che questo deve essere generato dai primi tre risultati di ricerca."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Il numero di risultati principali da cui generare il riepilogo della ricerca. Se il numero di risultati restituiti è inferiore asummaryResultCount, il riepilogo viene generato da tutti i risultati.maxExtractiveAnswerCount: Il numero di risposte estrattive da restituire per ogni risultato di ricerca. Il valore predefinito è 0 e il valore massimo è 1.
Ottieni il riepilogo dalla risposta della ricerca. In ogni risposta viene restituita una proprietà
summary.Ecco un esempio di riepilogo restituito alla fine di una risposta di ricerca:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
Generare riepiloghi da blocchi semantici
Puoi attivare use_semantic_chunks per generare riepiloghi dai blocchi di documenti più pertinenti. L'utilizzo di blocchi semantici per la generazione di riepiloghi aumenta
il richiamo e il recupero rispetto al comportamento predefinito dell'utilizzo di risposte estrattive.
Quando la suddivisione semantica è attivata per i riepiloghi, la risposta restituisce il riepilogo e i contenuti di ogni blocco utilizzato.
Per utilizzare i segmenti semantici per la generazione di riepiloghi:
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifichi"use_semantic_chunks": true. Per ulteriori informazioni sull'invio di una richiesta di ricerca, vedi Ottenere i risultati di ricerca.Il seguente esempio di
summarySpecindica che vuoi un riepilogo della ricerca che utilizzi blocchi semantici, quanti risultati includere e se includere le citazioni."contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN: Un valore booleano che specifica se utilizzare i chunk semantici per generare il riepilogo della ricerca. Se impostato sutrue, vengono utilizzati i segmenti semantici.SUMMARY_RESULT_COUNT: Il numero di risultati principali da cui generare il riepilogo della ricerca. Il valore massimo è10.CITATIONS_BOOLEAN: un valore booleano che specifica se vengono restituite le citazioni. Se hai attivato la modalità chunk quando hai creato il datastore, le citazioni si riferiscono ai chunk. In caso contrario, le citazioni si riferiscono ai documenti di origine. Per saperne di più sulla modalità di suddivisione, vedi Analizzare e suddividere i documenti.
Ottieni il riepilogo dalla risposta della ricerca.
Ecco un esempio di risposta di ricerca che include un riepilogo generato da blocchi e che include citazioni. La parte
referencesdella risposta contiene i contenuti dei chunk da cui viene generato il riepilogo.Risposta
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
Ottenere citazioni
Le citazioni, se specificate, sono numeri inseriti in linea in un riepilogo della ricerca. Questi numeri indicano da quali risultati di ricerca sono tratte le frasi specifiche del riepilogo.
Per ottenere le citazioni, segui questi passaggi:
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifichi"includeCitations": true. Per ulteriori informazioni sull'invio di una richiesta di ricerca, vedi Ottenere i risultati di ricerca.Nell'esempio seguente,
summarySpecindica che vuoi un riepilogo della ricerca, che il riepilogo deve essere generato dai primi tre risultati di ricerca e che le citazioni devono essere incluse nel riepilogo."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Il numero di risultati principali da cui generare il riepilogo della ricerca. Se il numero di risultati restituiti è inferiore asummaryResultCount, il riepilogo viene generato da tutti i risultati. Il valore massimo è5.includeCitations: un valore booleano che specifica se vengono restituite le citazioni.maxExtractiveAnswerCount: Il numero di risposte estrattive da restituire per ogni risultato di ricerca. Il valore predefinito è 0 e il valore massimo è 1.
Ottieni il riepilogo, con le citazioni, dalla risposta della ricerca. In ogni risposta viene restituita una proprietà
summary.Ecco un esempio di riepilogo, con citazioni e metadati delle citazioni, restituiti alla fine di una risposta di ricerca:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText: Il riepilogo della ricerca, con i numeri delle citazioni. I numeri delle citazioni si riferiscono ai risultati di ricerca restituiti e sono indicizzati a partire da 1. Ad esempio,[1]significa che la frase è attribuita al primo risultato di ricerca.[2, 3]significa che la frase è attribuita sia al secondo che al terzo risultato di ricerca.citations: Per ogni frase del riepilogo che contiene una citazione, elenca i metadati della citazione.startIndex: Indica l'inizio della frase, misurato in byte Unicode.endIndex: indica la fine della frase, misurata in byte Unicode.sources: elencareferenceIndexper ogni fonte inclusa nella citazione della frase.referenceIndexè il numero di indice assegnato a un'origine. IlreferenceIndexdella prima origine non viene sempre restituito in modo esplicito nella risposta. PoichéreferenceIndexè indicizzato a 0, la prima origine ha sempre unreferenceIndexpari a 0.references: Elenca i metadati per ogni riferimento citato nel riepilogo. I metadati includonotitle,docNameeuri.
Ignora query contraddittorie
Le query ostili includono commenti negativi o sono progettate per generare
output non sicuri e in violazione delle norme. Puoi specificare che non devono essere restituiti riepiloghi della ricerca per le query ostili. Quando una query ostile viene ignorata, la proprietà
summaryText contiene un testo standard che indica che non viene restituito alcun riepilogo
della ricerca. I documenti di ricerca vengono restituiti per le query ostili anche
se i riepiloghi della ricerca non lo sono.
Per specificare che non devono essere restituiti riepiloghi della ricerca per le query ostili, segui questi passaggi:
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifichi"ignoreAdversarialQuery": true. Per ulteriori informazioni sull'invio di una richiesta di ricerca, vedi Ottenere i risultati di ricerca.Nel seguente esempio,
summarySpecindica che vuoi un riepilogo della ricerca, che il riepilogo deve essere generato dai primi tre risultati di ricerca, ma che non deve essere restituito alcun riepilogo per le query ostili."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Il numero di risultati principali da cui generare il riepilogo della ricerca. Se il numero di risultati restituiti è inferiore asummaryResultCount, il riepilogo viene generato da tutti i risultati. Il valore massimo è5.ignoreAdversarialQuery: un valore booleano che specifica che non devono essere restituiti riepiloghi di ricerca per le query avversative.maxExtractiveAnswerCount: Il numero di risposte estrattive da restituire per ogni risultato di ricerca. Il valore predefinito è 0 e il valore massimo è 1.
Visualizza la proprietà
summaryrestituita per una richiesta di ricerca avversariale.Ecco un esempio:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText: Testo boilerplate che indica che non viene restituito alcun riepilogo della ricerca.summarySkippedReasons: Un'enumerazione con valori per i motivi per cui il riepilogo è stato ignorato.
Ignora le query che non cercano riepiloghi
Le query che non cercano riepiloghi restituiscono risultati non adatti alla riepilogazione. Ad esempio, "perché il cielo è blu" e "chi è il miglior calciatore del mondo?" sono query che cercano riepiloghi, mentre "aeroporto SFO" e "mondiali 2026" non lo sono. Si tratta molto probabilmente di query di navigazione. Puoi specificare che non vengano restituiti riepiloghi di ricerca per le query che non cercano riepiloghi. I documenti di ricerca vengono restituiti per le query che non cercano riepiloghi, anche se i riepiloghi della ricerca non vengono restituiti.
Per specificare che non devono essere restituiti riepiloghi della ricerca per le query che non cercano riepiloghi:
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifichi"ignoreNonSummarySeekingQuery": true. Per ulteriori informazioni sull'invio di una richiesta di ricerca, consulta Ottenere i risultati di ricerca.Nell'esempio seguente,
summarySpecindica che vuoi un riepilogo della ricerca, che deve essere generato dai primi tre risultati di ricerca, ma che non deve essere restituito alcun riepilogo per le query che non lo richiedono."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: Il numero di risultati principali da cui generare il riepilogo della ricerca. Se il numero di risultati restituiti è inferiore asummaryResultCount, il riepilogo viene generato da tutti i risultati. Il valore massimo è5.ignoreNonSummarySeekingQuery: un valore booleano che specifica che non devono essere restituiti riepiloghi di ricerca per le query che non cercano riepiloghi.maxExtractiveAnswerCount: Il numero di risposte estrattive da restituire per ogni risultato di ricerca. Il valore predefinito è 0 e il valore massimo è 1.
Visualizza la proprietà
summaryrestituita per una richiesta di ricerca non riepilogativa.Ecco un esempio:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText: Testo boilerplate che indica che non viene restituito alcun riepilogo della ricerca.summarySkippedReasons: Un'enumerazione con valori per i motivi per cui il riepilogo è stato ignorato.
Ottenere riepiloghi personalizzati
Puoi ottenere riepiloghi personalizzati fornendo istruzioni in linguaggio naturale.
Questa funzionalità è disponibile per il widget di ricerca utilizzando la console e per
l'API inserendo le istruzioni nel campo modelPromptSpec.preamble.
Puoi richiedere personalizzazioni come lunghezza, livello di dettaglio, stile dell'output (ad esempio "semplice"), lingua dell'output, focus della risposta e formato (ad esempio tabelle, elenchi puntati e XML).
Ad esempio, per la query What are the benefits of bigquery?, puoi
inserire istruzioni di personalizzazione come negli esempi seguenti:
Esempio di istruzione:
please show the answer format in an ordered listRisposta di esempio:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are freeEsempio di istruzione:
give a very detailed answerRisposta di esempio:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
Best practice per i riepiloghi personalizzati
Se prevedi di utilizzare questa funzionalità:
- Richiedi una sola personalizzazione alla volta. Non combinare personalizzazioni, ad esempio richiedere una tabella HTML in francese.
- Google consiglia di imporre limiti alle personalizzazioni che gli utenti finali possono richiedere, ad esempio offrendo un selettore con un insieme di personalizzazioni predefinite.
Personalizzare i riepiloghi
Puoi ottenere riepiloghi personalizzati solo per il widget di ricerca utilizzando la console o, per qualsiasi richiesta di ricerca, utilizzando l'API.
Per ottenere un riepilogo personalizzato:
Console
Nella Google Cloud console, vai alla pagina AI Applications.
Fai clic sul nome dell'app da modificare.
Vai a Configurazioni > UI.
Assicurati che il Tipo di ricerca del widget di ricerca sia impostato su Cerca con una risposta o Cerca con domande successive. Questa funzionalità non è disponibile se è selezionata l'opzione Ricerca.
Attiva l'opzione Abilita personalizzazione del riassunto.
Per inserire le istruzioni di riepilogo, esegui una delle seguenti operazioni:
- Inserisci istruzioni in formato libero: inserisci le tue istruzioni in linguaggio naturale nel campo Preambolo.
- Utilizza le istruzioni del modello: fai clic su Sostituisci con un modello e seleziona una delle istruzioni del modello predefinite. Il modello predefinito viene visualizzato nel campo Preambolo dopo la selezione.
Prova la generazione di riepiloghi personalizzati per la tua app eseguendo una ricerca nel riquadro Anteprima.
Per ripristinare l'ultimo insieme di istruzioni salvato, fai clic su Reimposta preambolo.
Per salvare le impostazioni nel widget, fai clic su Salva e pubblica.
REST
Invia una richiesta di ricerca che includa
contentSearchSpec.summarySpece specifica l'istruzione di personalizzazione inmodelPromptSpec.preamble. Per ulteriori informazioni sull'invio di una richiesta di ricerca, vedi Ottenere i risultati di ricerca.Nell'esempio seguente,
summarySpecindica che vuoi un riepilogo della ricerca, che deve essere generato dai primi tre risultati di ricerca e personalizzato come se fosse spiegato a un bambino di 10 anni."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount: Il numero di risultati principali da cui generare il riepilogo della ricerca. Se il numero di risultati restituiti è inferiore asummaryResultCount, il riepilogo viene generato da tutti i risultati. Il valore massimo è5.preamble: L'istruzione per la personalizzazione.
Ottieni il riepilogo personalizzato dalla risposta della ricerca.
Ecco un esempio di riepilogo personalizzato restituito:
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText: il riepilogo della ricerca personalizzata.
Specifica il modello di riepilogo
Puoi specificare il modello che vuoi utilizzare per generare i riepiloghi.
Puoi specificare stable, preview o una versione specifica del modello per nome.
Per le versioni del modello disponibili, vedi Versioni e ciclo di vita del modello di generazione di risposte.
Per modificare la versione del modello:
Invia una richiesta di ricerca che includa
ContentSearchSpec.SummarySpec.ModelSpecper specificare la versione del modello."contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION: specifica il modello da utilizzare per generare i riepiloghi. I valori supportati sono:
stable: stringa. Specifica predefinita quando non viene specificato alcun valore.stableindica una versione del modello GA ottimizzata per la generazione di risposte. Il modello a cuistablepunta cambia man mano che vengono rilasciate nuove versioni del modello GA e le versioni precedenti vengono ritirate. Per la versione aggiornata a cui fa riferimentostable, vedi Versioni e ciclo di vita del modello di generazione delle risposte.preview: stringa.previewindica l'ultimo modello Gemini per le domande e le risposte. Per ulteriori informazioni su Gemini, consulta la panoramica dei modelli.- Per specificare una determinata versione del modello, inserisci il nome della versione, ad esempio
gemini-1.5-flash-002/answer_gen/v1. Per le versioni supportate, vedi Versioni e ciclo di vita del modello di generazione delle risposte.
Ad esempio, la seguente richiesta di ricerca specifica preview come versione del modello:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
Limitazioni delle sintesi delle ricerche
Quando utilizzi i riepiloghi della ricerca, potresti riscontrare le seguenti limitazioni:
Poiché gli LLM vengono utilizzati per generare riepiloghi e citazioni della ricerca, anche le limitazioni degli LLM si applicano ai riepiloghi di Vertex AI Search.
Per informazioni generali su queste limitazioni degli LLM, consulta Limitazioni dell'API PaLM nella documentazione di Vertex AI.
Le query di ricerca che richiedono un ragionamento logico o analitico complesso o la comprensione del mondo possono portare a riepiloghi della ricerca che contengono informazioni errate (allucinazioni) o informazioni non presenti nei dati non strutturati o del sito web.
Alcune affermazioni nel riepilogo della ricerca potrebbero non contenere una citazione:
Se il sistema determina che un'affermazione non richiede una base, non includerà una citazione. Frasi come "Ecco cosa ho trovato" o "Esistono molti metodi che puoi seguire" non includono citazioni.
Le citazioni mancanti possono anche indicare che non è stato trovato un riferimento valido. I fatti senza citazioni potrebbero non essere affidabili.
In rari casi, le citazioni potrebbero essere attribuite in modo errato a un'affermazione.
I documenti complessi potrebbero essere analizzati in modo errato dal modello linguistico di grandi dimensioni. In questo caso, il riepilogo potrebbe essere incompleto o errato.
Poiché le istruzioni di personalizzazione sono in linguaggio naturale, l'aderenza alle istruzioni non può essere garantita per tutte le richieste.