이 페이지에서는 API를 사용하여 검색 결과와 함께 검색 요약을 가져오는 방법을 보여줍니다. 또한 검색 요약에서 사용할 수 있는 옵션도 설명합니다. 비정형 데이터 및 웹사이트 데이터에만 적용됩니다.
의료 데이터 쿼리에 대한 생성형 AI 답변을 가져오는 방법에 대한 자세한 내용은 생성형 AI 답변이 포함된 자연어 쿼리를 사용하여 검색을 참조하세요.
시작하기 전에
사용 중인 앱 유형에 따라 다음 요구사항을 완료합니다.
비정형 검색 앱의 경우 고급 LLM 기능을 사용 설정합니다.
웹사이트 검색 앱의 경우 다음 기능을 사용 설정합니다.
고급 웹사이트 색인 생성. 도메인 확인이 필요합니다.
검색 요약 가져오기
검색 요약은 검색 응답에 반환된 상위 하나 이상의 검색 결과에 대한 짧은 요약입니다. 요약 자체는 응답에 반환된 추출 답변에서 가져옵니다. 따라서 요약을 가져오려면 검색 결과와 함께 추출 답변도 가져와야 합니다. 자세한 내용은 추출 답변 가져오기(미리보기)를 참조하세요.
다음 이미지는 데이터 스토어의 PDF를 summaryResultCount를 5로 설정하여 쿼리할 때의 요약을 보여줍니다. 요약 콘텐츠는 앱 구성에 따라 다를 수 있습니다.
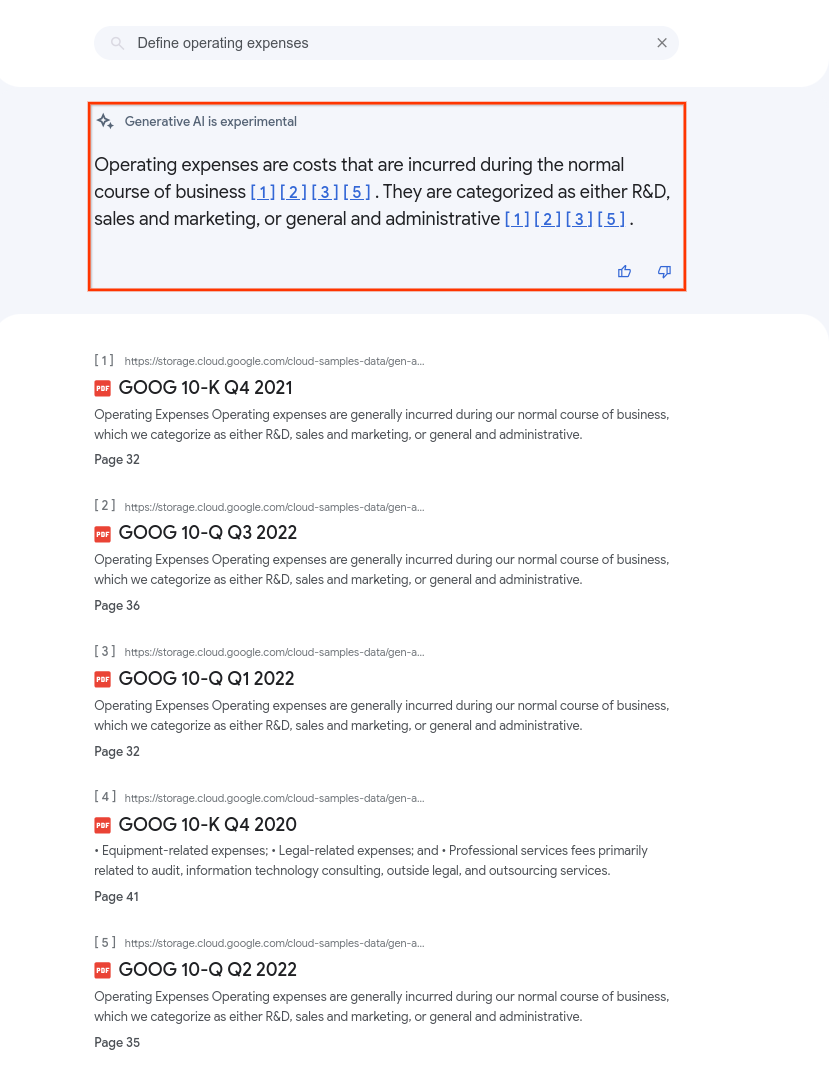
검색 요약에는 마크다운 형식의 텍스트와 마크다운 파서가 일반적으로 이해하는 간단한 HTML 태그가 포함될 수 있습니다. 따라서 애플리케이션에서 마크다운 파서를 사용하여 마크다운 텍스트를 렌더링하는 것이 좋습니다.
검색 요약을 가져오려면 다음 단계를 따르세요.
contentSearchSpec.summarySpec이 포함되고summaryResultCount및maxExtractiveAnswerCount의 값을 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음 예시에서
summarySpec은 검색 요약이 필요하다는 것과 요약은 상위 3개 검색 결과에서 생성되어야 한다는 것을 나타냅니다."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: 검색 요약을 생성할 최상위 결과의 수입니다. 반환된 결과 수가summaryResultCount보다 적으면 모든 결과로부터 요약이 생성됩니다.maxExtractiveAnswerCount: 각 검색 결과에 대해 반환할 추출 답변의 수입니다. 기본값은 0이고 최댓값은 1입니다.
검색 응답에서 요약을 가져옵니다. 각 응답에서 하나의
summary속성이 반환됩니다.검색 응답 끝에 반환되는 요약의 예시는 다음과 같습니다.
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
시맨틱 청크에서 요약 생성
use_semantic_chunks를 사용 설정하면 가장 관련성이 높은 문서 청크에서 요약을 생성할 수 있습니다. 요약 생성에 시맨틱 청크를 사용하면 추출 답변을 사용하는 기본 동작에 비해 재현율 및 검색이 향상됩니다.
요약에 시맨틱 청크 처리가 사용 설정된 경우 응답은 요약과 요약에 사용된 각 청크의 콘텐츠를 반환합니다.
요약 생성에 시맨틱 청크를 사용하려면 다음 단계를 따르세요.
contentSearchSpec.summarySpec이 포함되고"use_semantic_chunks": true를 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음
summarySpec예시는 시맨틱 청크를 사용하는 검색 요약이 필요하다는 것과 포함할 결과 수, 인용을 포함할지 여부를 나타냅니다."contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN: 검색 요약을 생성하는 데 시맨틱 청크를 사용할지 여부를 지정하는 불리언입니다.true로 설정하면 시맨틱 청크가 사용됩니다.SUMMARY_RESULT_COUNT: 검색 요약을 생성할 최상위 결과의 수입니다. 최댓값은10입니다.CITATIONS_BOOLEAN: 인용이 반환되는지 여부를 지정하는 불리언입니다. 데이터 스토어를 만들 때 청크 모드를 사용 설정한 경우 인용은 청크를 참조합니다. 그렇지 않으면 인용은 소스 문서를 참조합니다. 청크 모드에 대한 자세한 내용은 문서 파싱 및 청크 처리를 참조하세요.
검색 응답에서 요약을 가져옵니다.
청크에서 생성되고 인용을 포함하는 요약이 포함된 검색 응답의 예시는 다음과 같습니다. 응답의
references부분에는 요약이 생성된 청크의 콘텐츠가 포함됩니다.응답
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
인용 가져오기
인용은 지정된 경우 검색 요약에서 인라인으로 배치되는 숫자입니다. 이러한 숫자는 요약에서 특정 문장을 가져온 검색 결과를 나타냅니다.
인용을 가져오려면 다음 단계를 따르세요.
contentSearchSpec.summarySpec이 포함되고"includeCitations": true를 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음 예시에서
summarySpec은 검색 요약이 필요하다는 것과 요약은 상위 3개 검색 결과에서 생성되어야 하고 인용은 요약에 포함되어야 한다는 것을 나타냅니다."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: 검색 요약을 생성할 최상위 결과의 수입니다. 반환된 결과 수가summaryResultCount보다 적으면 모든 결과로부터 요약이 생성됩니다. 최댓값은5입니다.includeCitations: 인용이 반환되는지 여부를 지정하는 불리언입니다.maxExtractiveAnswerCount: 각 검색 결과에 대해 반환할 추출 답변의 수입니다. 기본값은 0이고 최댓값은 1입니다.
검색 응답에서 인용이 포함된 요약을 가져옵니다. 각 응답에서 하나의
summary속성이 반환됩니다.검색 응답 끝에 반환되는 인용 및 인용 메타데이터가 포함된 요약의 예시는 다음과 같습니다.
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText: 인용 번호가 포함된 검색 요약입니다. 인용 번호는 반환된 검색 결과를 나타내며 1부터 색인이 생성됩니다. 예를 들어[1]은 해당 문장이 첫 번째 검색 결과에 속함을 나타냅니다.[2, 3]은 해당 문장이 두 번째 및 세 번째 검색 결과에 모두 속함을 의미합니다.citations: 인용이 있는 요약의 각 문장에 대해 해당 인용의 메타데이터를 나열합니다.startIndex: 유니코드 바이트로 측정된 문장의 시작을 나타냅니다.endIndex: 유니코드 바이트로 측정된 문장의 끝을 나타냅니다.sources: 문장의 인용에 포함된 각 소스의referenceIndex를 나열합니다.referenceIndex는 소스에 할당된 색인 번호입니다. 첫 번째 소스의referenceIndex는 항상 응답에서 명시적으로 반환되지는 않습니다.referenceIndex는 0으로 색인이 생성되므로 첫 번째 소스의referenceIndex는 항상 0입니다.references: 요약에 인용된 각 참조의 메타데이터를 나열합니다. 메타데이터에는title,docName,uri가 포함됩니다.
악의적인 쿼리 무시
악의적인 쿼리는 부정적인 표현을 포함하거나 안전하지 않은 정책 위반 출력을 생성하도록 의도된 것입니다. 악의적인 쿼리에 대해서는 검색 요약을 반환하지 않도록 지정할 수 있습니다. 악의적인 쿼리가 무시될 경우 summaryText 속성에는 검색 요약이 반환되지 않음을 나타내는 상용구 텍스트가 포함됩니다. 악의적인 쿼리에 대해 검색 요약은 반환되지 않더라도 검색 문서는 반환됩니다.
악의적인 쿼리에 대해 검색 요약을 반환하지 않도록 지정하려면 다음 단계를 따르세요.
contentSearchSpec.summarySpec이 포함되고"ignoreAdversarialQuery": true를 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음 예시에서
summarySpec은 검색 요약이 필요하다는 것과 요약은 상위 3개 검색 결과에서 생성되어야 하고 악의적인 쿼리에 대해서는 요약이 반환되어서는 안 된다는 것을 나타냅니다."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: 검색 요약을 생성할 최상위 결과의 수입니다. 반환된 결과 수가summaryResultCount보다 적으면 모든 결과로부터 요약이 생성됩니다. 최댓값은5입니다.ignoreAdversarialQuery: 악의적인 쿼리에 대해 검색 요약을 반환하지 않도록 지정하는 불리언입니다.maxExtractiveAnswerCount: 각 검색 결과에 대해 반환할 추출 답변의 수입니다. 기본값은 0이고 최댓값은 1입니다.
악의적인 검색 요청에 대해 반환되는
summary속성을 참조하세요.예를 들면 다음과 같습니다.
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText: 검색 요약이 반환되지 않음을 나타내는 상용구 텍스트입니다.summarySkippedReasons: 요약을 건너뛴 이유의 값이 포함된 열거입니다.
요약을 원하지 않는 쿼리 무시
요약을 원하지 않는 쿼리는 요약에 적합하지 않은 결과를 반환합니다. 예를 들어 "하늘이 왜 파란색인가요?" 및 "세계에서 가장 뛰어난 축구 선수는 누구인가요?"는 요약을 원하는 쿼리에 해당하지만 "SFO 공항" 및 "월드컵 2026"은 그렇지 않습니다. 이러한 쿼리는 탐색적인 쿼리일 가능성이 더 높습니다. 요약을 원하지 않는 쿼리에 대해서는 검색 요약이 반환되지 않도록 지정할 수 있습니다. 요약을 원하지 않는 쿼리에 대해 검색 요약은 반환되지 않더라도 검색 문서는 반환됩니다.
요약을 원하지 않는 쿼리에 대해 검색 요약을 반환하지 않도록 지정하려면 다음 안내를 따르세요.
contentSearchSpec.summarySpec이 포함되고"ignoreNonSummarySeekingQuery": true를 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음 예시에서
summarySpec은 검색 요약이 필요하다는 것과 요약은 상위 3개 검색 결과에서 생성되어야 하고 요약을 찾지 않는 쿼리에 대해서는 요약이 반환되어서는 안 된다는 것을 나타냅니다."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: 검색 요약을 생성할 최상위 결과의 수입니다. 반환된 결과 수가summaryResultCount보다 적으면 모든 결과로부터 요약이 생성됩니다. 최댓값은5입니다.ignoreNonSummarySeekingQuery: 요약을 원하지 않는 쿼리에 대해 검색 요약을 반환하지 않도록 지정하는 불리언입니다.maxExtractiveAnswerCount: 각 검색 결과에 대해 반환할 추출 답변의 수입니다. 기본값은 0이고 최댓값은 1입니다.
요약을 원하지 않는 검색 요청에 대해 반환되는
summary속성을 참조하세요.예를 들면 다음과 같습니다.
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText: 검색 요약이 반환되지 않음을 나타내는 상용구 텍스트입니다.summarySkippedReasons: 요약을 건너뛴 이유의 값이 포함된 열거입니다.
맞춤설정된 요약 가져오기
자연어 안내를 제공하여 맞춤설정된 요약을 가져올 수 있습니다.
이 기능은 콘솔을 사용하여 검색 위젯에 사용할 수 있으며, modelPromptSpec.preamble 필드에 안내를 입력하여 API에 사용할 수 있습니다.
길이, 세부정보 수준, 출력 스타일(예: '간단'), 출력 언어, 답변의 포커스, 형식(예: 테이블, 글머리기호, XML)과 같은 맞춤설정을 요청할 수 있습니다.
예를 들어 What are the benefits of bigquery? 쿼리에 대해서는 다음 예시와 같이 맞춤설정 안내를 입력할 수 있습니다.
안내 예시:
please show the answer format in an ordered list응답 예시:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are free안내 예시:
give a very detailed answer응답 예시:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
맞춤설정된 요약 권장사항
이 기능을 사용하려면 다음을 수행하세요.
- 한 번에 하나의 맞춤설정만 요청합니다. 프랑스어로 된 HTML 테이블을 요청하는 등 맞춤설정을 결합하지 않습니다.
- 사전 정의된 맞춤설정이 포함된 선택기를 제공하는 등 최종 사용자가 요청할 수 있는 맞춤설정에 한도를 적용하는 것이 좋습니다.
요약 맞춤설정
콘솔을 사용하여 검색 위젯에 대해서만 맞춤설정된 요약을 가져오거나 API를 사용하여 모든 검색 요청에 대해 맞춤설정된 요약을 가져올 수 있습니다.
맞춤설정된 요약을 가져오려면 다음 단계를 따르세요.
콘솔
Google Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
수정하려는 앱의 이름을 클릭합니다.
구성 > UI로 이동합니다.
검색 위젯의 검색 유형이 답변으로 검색 또는 질문으로 검색으로 설정되어 있는지 확인합니다. 검색이 선택된 경우에는 이 기능을 사용할 수 없습니다.
요약 맞춤설정 사용 설정을 사용 설정합니다.
요약 안내를 입력하려면 다음 중 하나를 수행합니다.
- 자유 형식 안내 입력: 전문 필드에 자연어로 된 안내를 입력합니다.
- 템플릿 안내 사용: 템플릿으로 바꾸기를 클릭하고 사전 정의된 템플릿 안내 중 하나를 선택합니다. 사전 정의된 템플릿을 선택하면 전문 필드에 표시됩니다.
미리보기 창에서 검색하여 앱의 맞춤설정된 요약 생성을 테스트합니다.
마지막으로 저장된 안내로 재설정하려면 전문 재설정을 클릭합니다.
설정을 위젯에 저장하려면 저장 및 게시를 클릭합니다.
REST
contentSearchSpec.summarySpec이 포함되고modelPromptSpec.preamble에서 맞춤설정 안내를 지정하는 검색 요청을 제출합니다. 검색 요청 제출에 대한 자세한 내용은 검색 결과 가져오기를 참조하세요.다음 예시에서
summarySpec은 검색 요약이 필요하다는 것과 요약은 상위 3개 검색 결과에서 생성되어야 하고 10세 아이에게 설명하는 것처럼 맞춤설정되어야 한다는 것을 나타냅니다."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount: 검색 요약을 생성할 최상위 결과의 수입니다. 반환된 결과 수가summaryResultCount보다 적으면 모든 결과로부터 요약이 생성됩니다. 최댓값은5입니다.preamble: 맞춤설정 안내입니다.
검색 응답에서 맞춤설정된 요약을 가져옵니다.
반환되는 맞춤설정된 요약의 예시는 다음과 같습니다.
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText: 맞춤설정된 검색 요약입니다.
요약 모델 지정
요약을 생성하는 데 사용할 모델을 지정할 수 있습니다.
이름으로 stable, preview 또는 특정 모델 버전을 지정할 수 있습니다.
사용 가능한 모델 버전은 답변 생성 모델 버전 및 수명 주기를 참조하세요.
모델 버전을 변경하려면 다음 단계를 따르세요.
ContentSearchSpec.SummarySpec.ModelSpec이 포함된 검색 요청을 제출하여 모델 버전을 지정합니다."contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION: 요약을 생성하는 데 사용할 모델을 지정합니다. 지원되는 값은 다음과 같습니다.
stable: 문자열입니다. 값이 지정되지 않은 경우 기본 사양입니다.stable은 대답 생성을 위해 미세 조정된 GA 모델 버전을 가리킵니다. 새 GA 모델 버전이 출시되고 이전 모델 버전이 지원 중단되면stable이 가리키는 모델이 변경됩니다.stable이 가리키는 최신 버전은 답변 생성 모델 버전 및 수명 주기를 참조하세요.preview: 문자열입니다.preview는 질문 및 답변을 위한 최신 Gemini 모델을 가리킵니다. Gemini에 대한 자세한 내용은 모델 개요를 참고하세요.- 특정 모델 버전을 지정하려면 버전 이름(예:
gemini-1.5-flash-002/answer_gen/v1)을 입력합니다. 지원되는 버전은 답변 생성 모델 버전 및 수명 주기를 참고하세요.
예를 들어 다음 검색 요청은 preview를 모델 버전으로 지정합니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
검색 요약 제한사항
검색 요약을 사용할 때 다음과 같은 제한사항이 발생할 수 있습니다.
LLM은 검색 요약 및 인용 생성에 사용되므로 LLM의 제한사항이 Vertex AI Search 요약에도 적용됩니다.
이러한 LLM 제한사항에 대한 일반적인 정보는 Vertex AI 문서의 PaLM API 제한사항을 참조하세요.
복잡한 논리적 또는 분석적 추론이나 세상에 대한 이해가 필요한 검색어는 잘못된 정보(할루시네이션) 또는 구조화되지 않은 또는 웹사이트 데이터에 없는 정보가 포함된 검색 요약을 초래할 수 있습니다.
검색 요약의 일부 문구에는 인용이 포함되지 않을 수 있습니다.
시스템에서 근거가 필요하지 않은 것으로 판단하는 문장에는 인용이 포함되지 않습니다. "찾은 내용은 다음과 같습니다" 또는 "다양한 방법을 따를 수 있습니다"와 같은 문장에는 인용이 없습니다.
인용이 누락된 것은 유효한 참조를 찾지 못했음을 나타낼 수도 있습니다. 인용 없이 팩트만 제시하는 경우 신뢰하지 못할 수 있습니다.
드물지만 인용이 문구에 잘못 표시될 수 있습니다.
복잡한 문서는 LLM에 의해 잘못 파싱될 수 있습니다. 이 경우 요약이 불완전하거나 잘못되었을 수 있습니다.
맞춤설정 안내는 자연어로 되어 있으므로 모든 요청에 대해 안내를 준수할 수 있는 것은 아닙니다.