This document describes how to update existing documents with newly processed results from another Document AI processor.
Current limitations
The ProcessWithDocAi pipeline can only work with documents that have been processed during the ingestion. Future versions of the pipeline will expand this pipeline to documents that are not processed yet. Please stay tuned for updates in our release notes.
Configure schema mapping in document schema (admin only)
The Set schemas with mapping document describes how to configure new or existing properties of a Document AI Warehouse schema to be mapped with extracted entities from Document AI. We demonstrate how to do this in the Document AI Warehouse admin console.
Go to the Document AI Warehouse admin console
Ensure that you have admin access. Then you can go to the admin console.
Create a new schema with schema mapping
You can create a new schema with schema mapping, and the same steps can apply to existing schemas by updating schemas in the schema details view. Just note that schema-update functionalities are currently limited. We do not support removing or modifying existing properties.
Click Add new in the Schema manager tab:

Enter a display name and description.
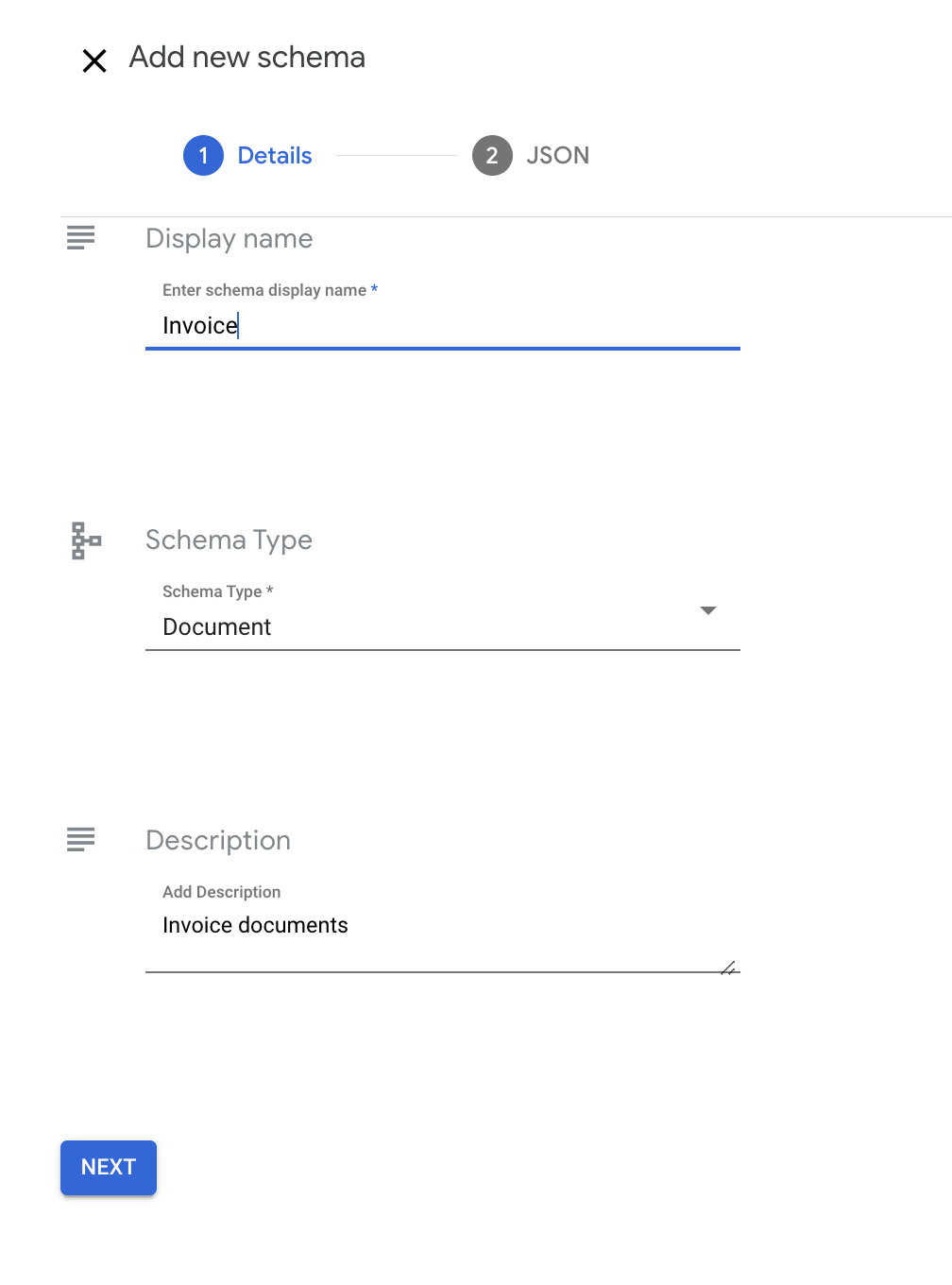
Note that you cannot modify display name after creation. Description is optional and can be updated after creation.
Click Next. The JSON editor of the schema appears, including the display name and description entered in the previous step.
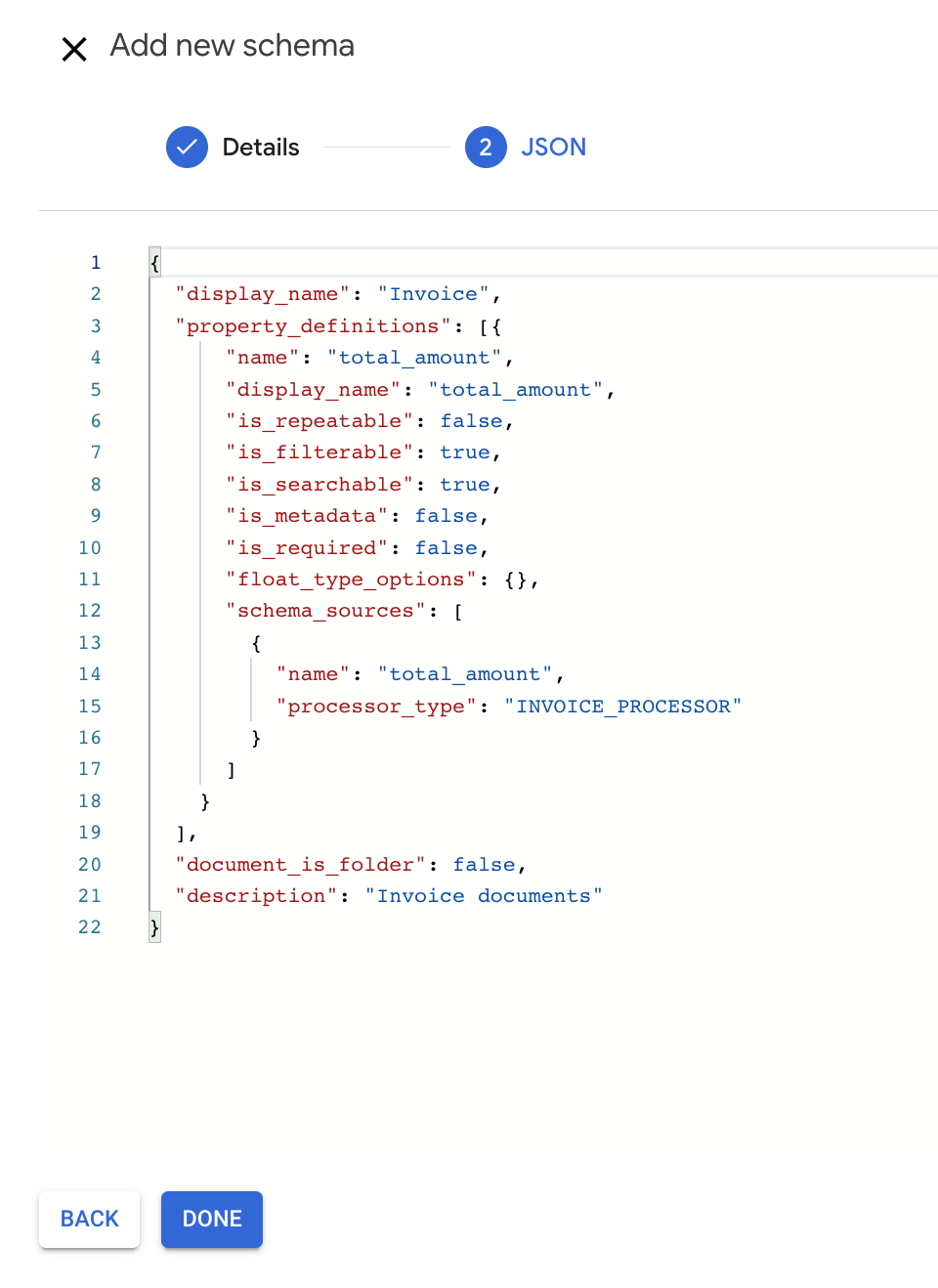
In this example, add a total_amount property to property_definitions list:
{ "name": "total_amount", "display_name": "Total Amount", "is_repeatable": false, "is_filterable": true, "is_searchable": true, "is_metadata": false, "is_required": false, "float_type_options": {}, "schema_sources": [ { "name": "total_amount", "processor_type": "INVOICE_PROCESSOR" } ] }The property is configured to be mapped to the
total_amountfield extracted byINVOICE_PROCESSOR. To get the full list of processor types, you can use the fetchProcessorTypes API.To create a schema, click Done. A confirmation message shows up after completion:
You can view the schema in detail.
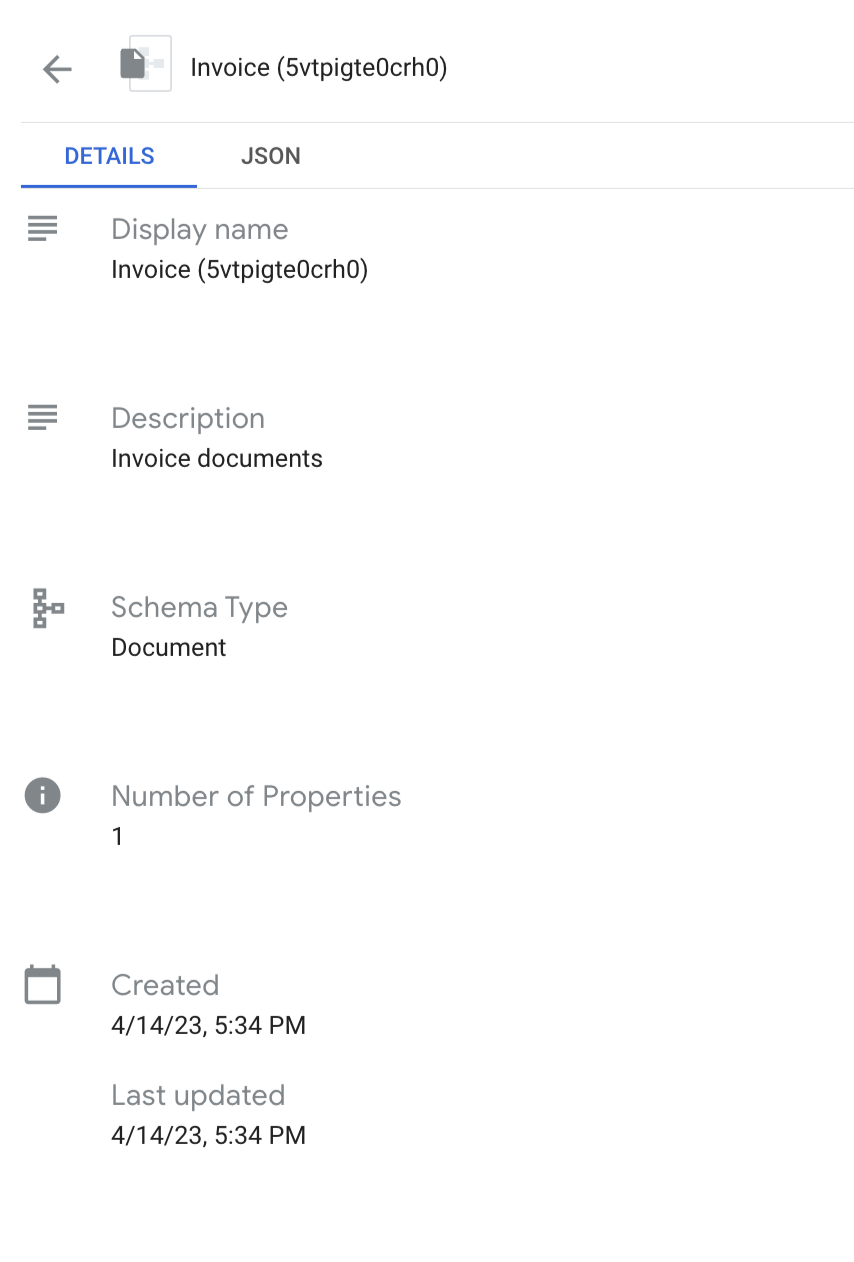
Example: Use an invoice processor for the OCR-processed documents
With the property mapping defined in the schema, you can reprocess the
OCR-processed documents with an invoice processor, which has the total_amount
property mapped from parsed results.
Select documents to reprocess.
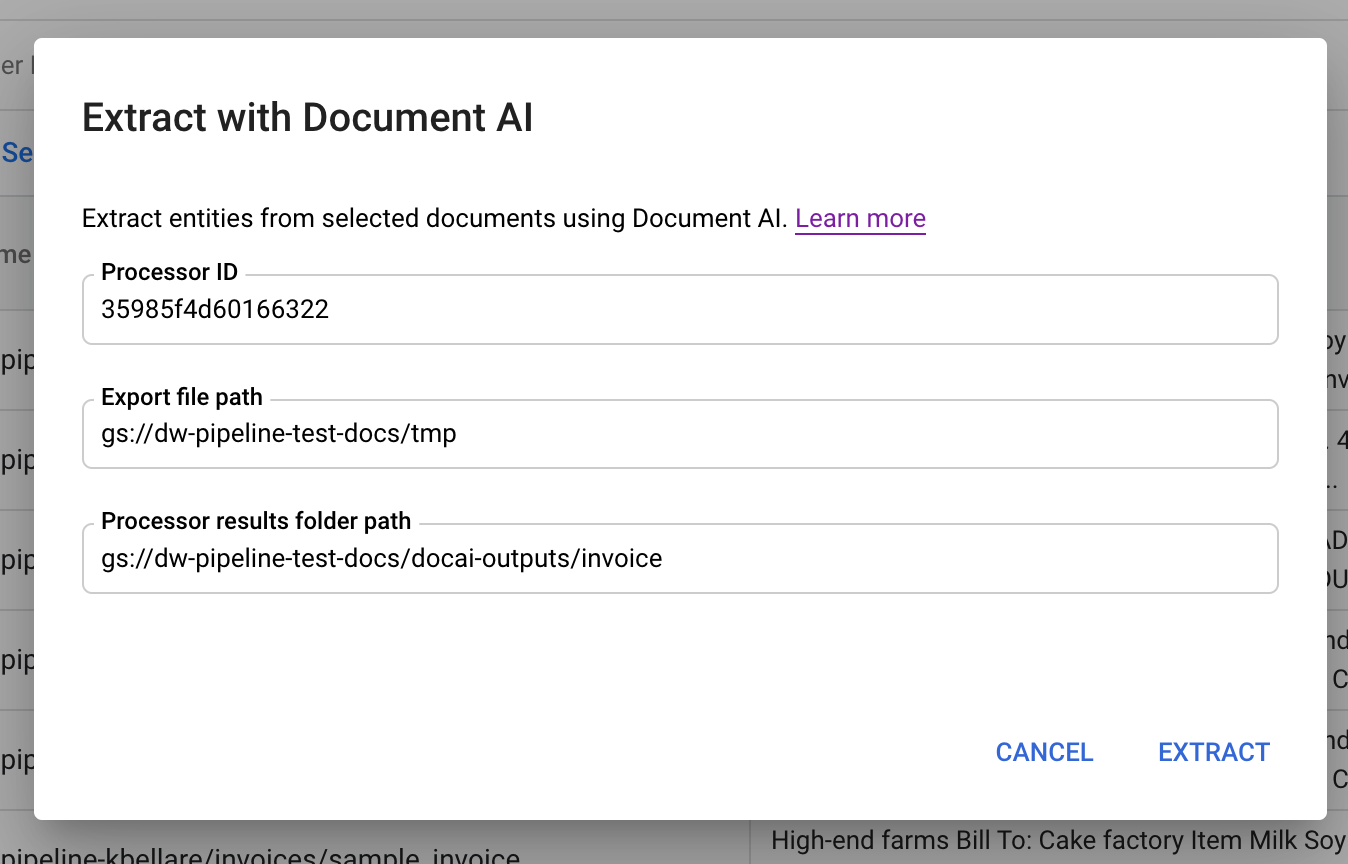
Select documents that you want to apply another processor to. Then click Extract with Document AI on the action bar.
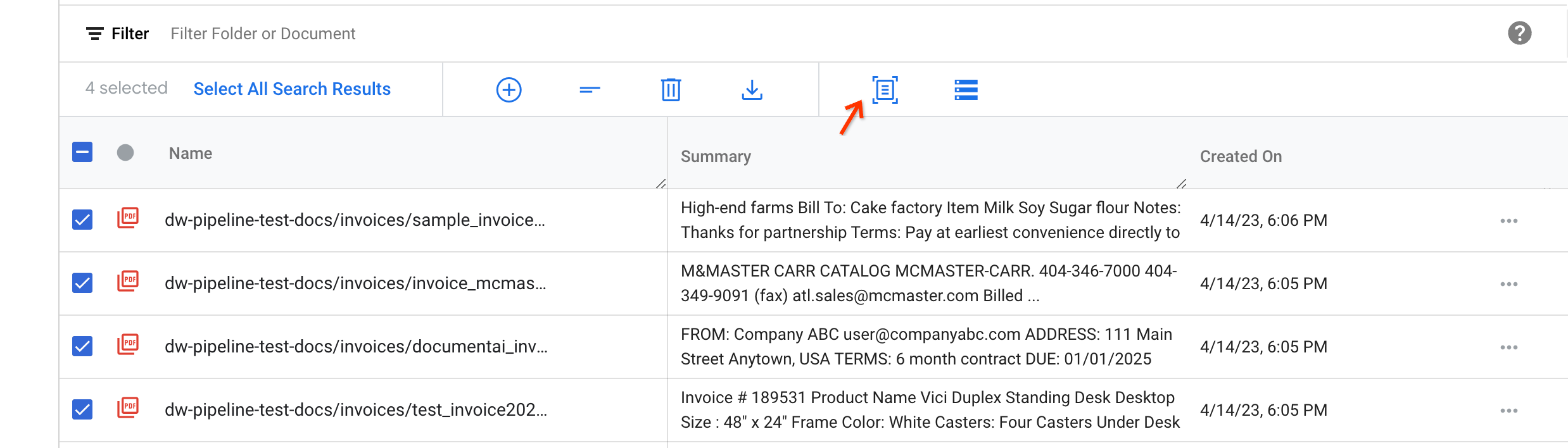
The pop-up dialog box has three input fields:
Processor ID: processor ID that you want to use to process the documents.
Export file path: a staging bucket path to temporary store the documents.
Processor results folder path: a bucket path to store the processor parsed documents.
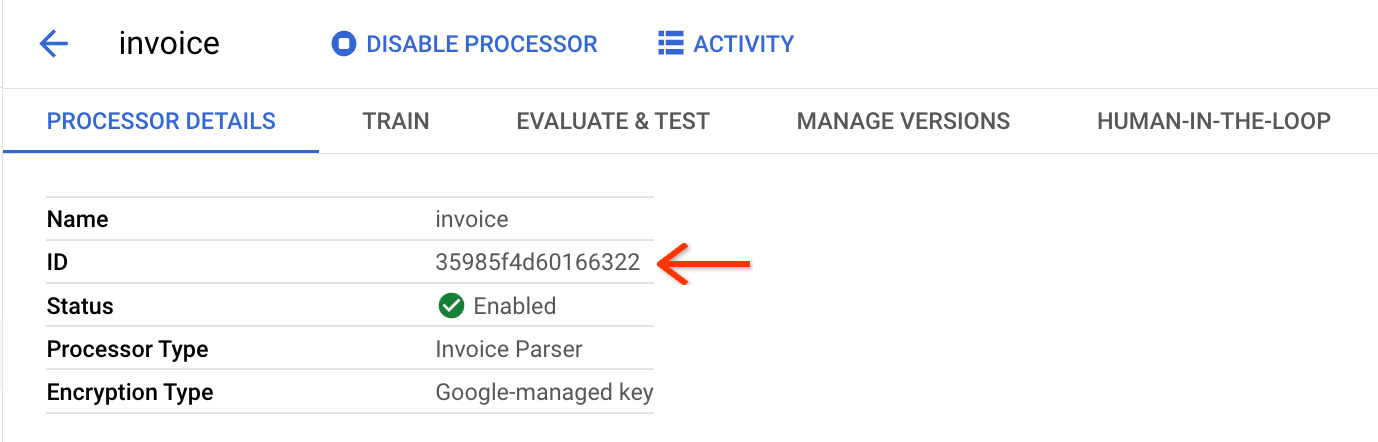
Get the invoice processor ID.
Similar to creating the OCR parser in the bulk upload guide, you can create an invoice processor from the processor gallery.
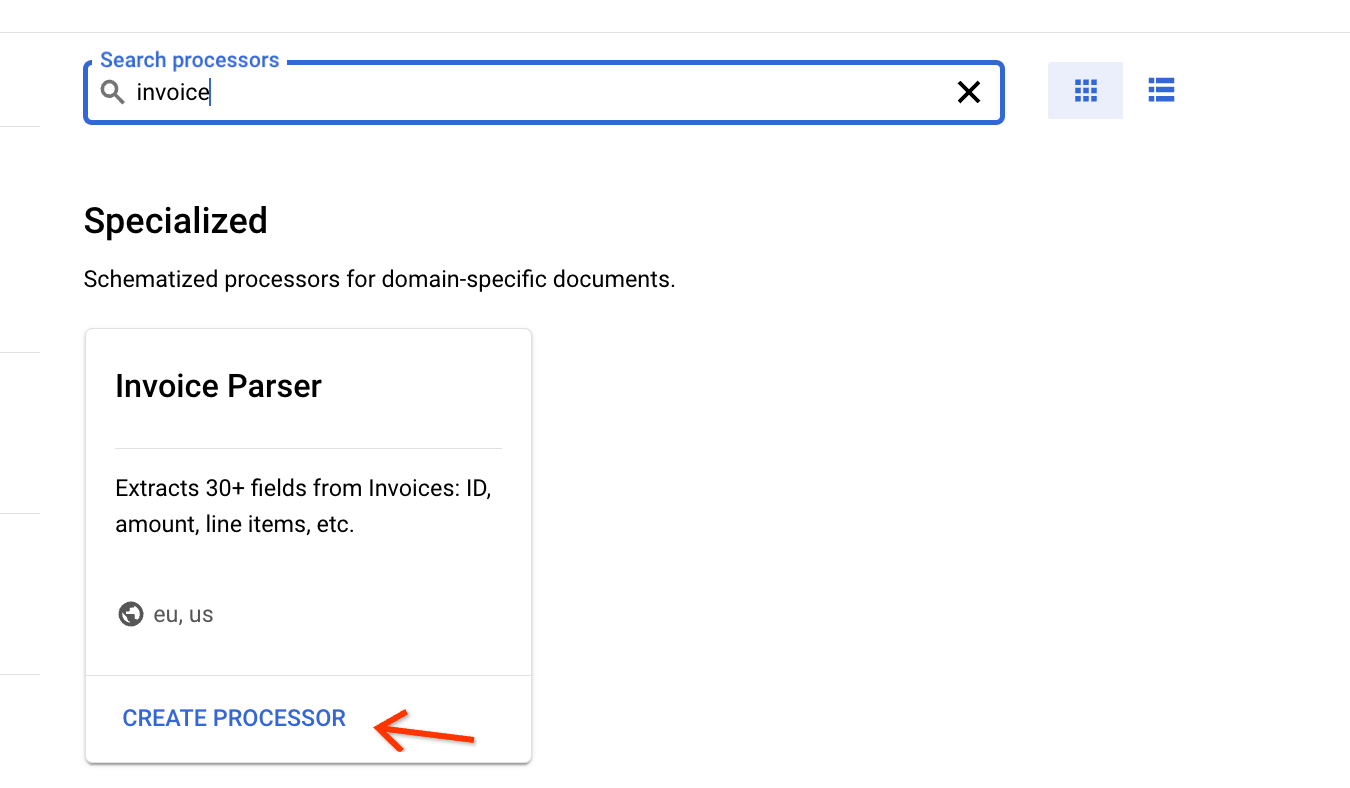
Find the ID on the Processor Details page:
Trigger the pipeline and track the status.
After putting the ID and two bucket paths in the dialog, you can click Extract to trigger the pipeline:
After triggering the pipeline, a status tracking page appears:
Currently, the page does not have in-progress tracking. The status page shows pending until the job is complete.
Examine the updated results.
Once the job is completed, you can click the document to examine whether the extraction results have been updated correctly.
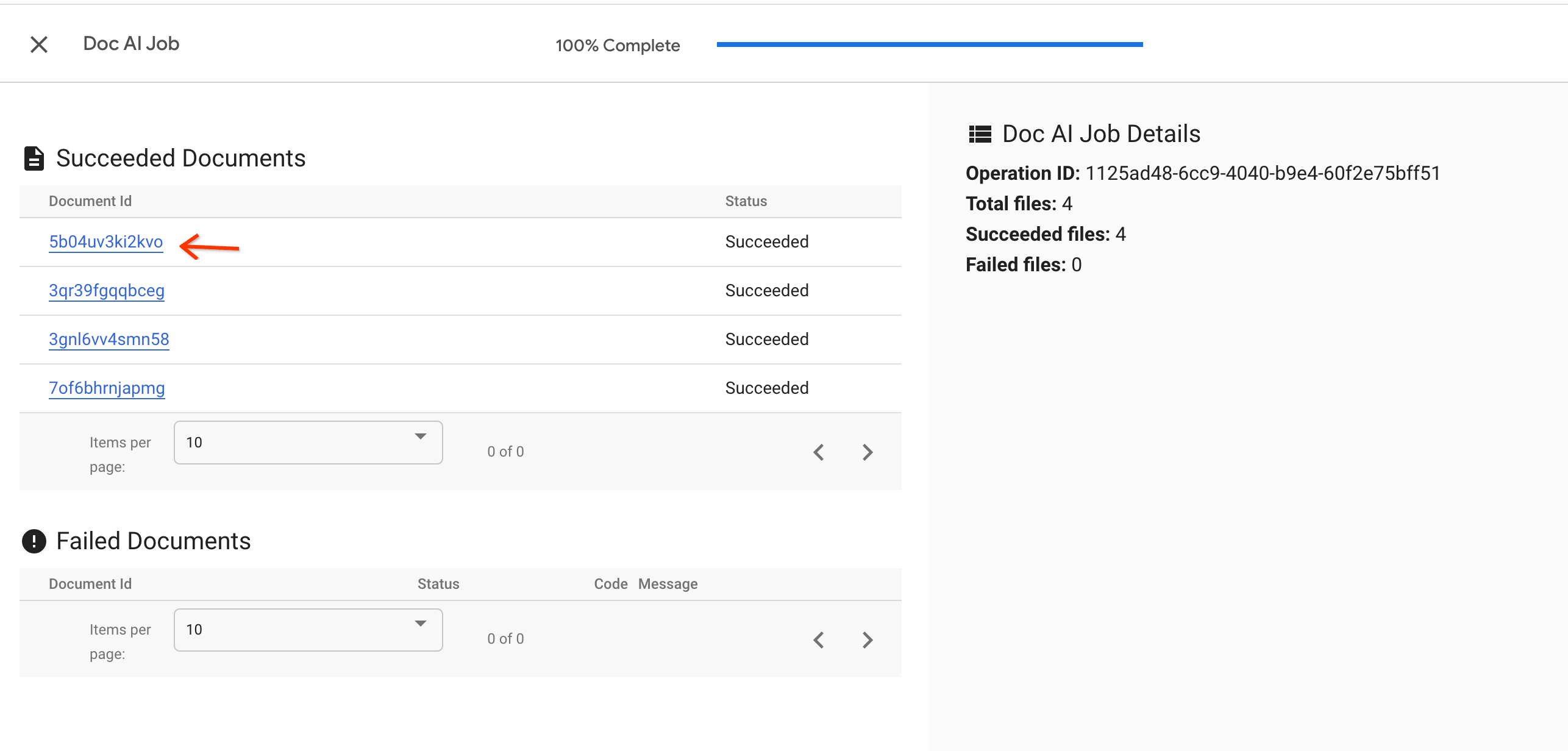
You can see the
total_amountproperty has been mapped from parsed results.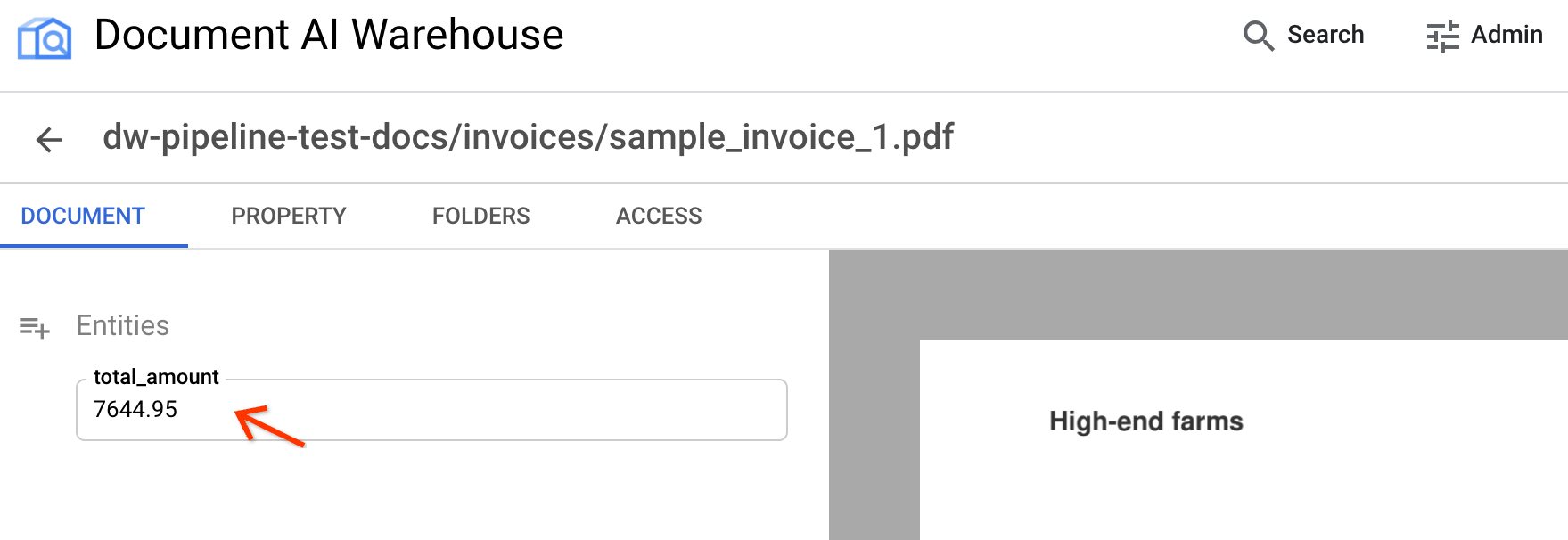
In the AI view, you can find the complete list of extracted entities:

Next step
Follow the next guide to export the documents to a Custom Document Extractor in Document AI workbench.