This document describes how to export documents from Document AI Warehouse to the dataset of a custom document extractor (CDE) in Document AI Workbench.
CDE lets users create document extractors. They import documents into the processor dataset, then label them before training the model. When users export selected documents to a CDE's dataset, they can build up the dataset by managing or searching the documents in Document AI Warehouse.
Create a CDE in Document AI Workbench
You can find complete instructions on how to create a CDE in this official guide. We highlight some key steps in this guide.
Create a CDE from the processor list
Go to the My processors page, and click Create Custom Processor:
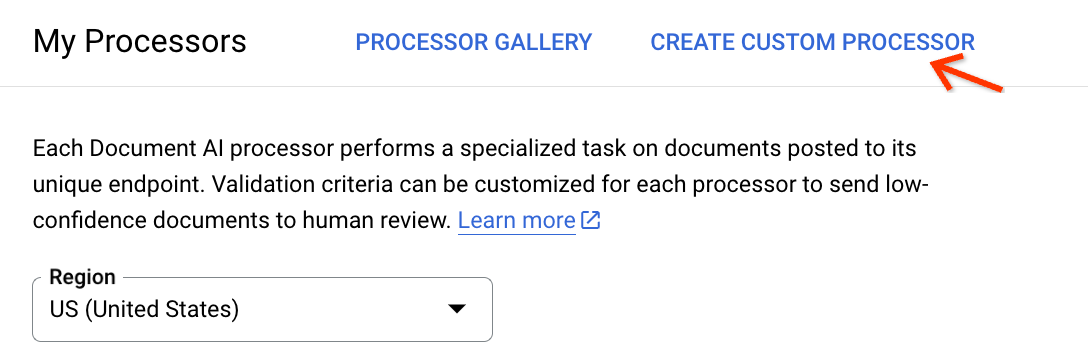
Choose Create Processor on the Custom Document Extractor card:
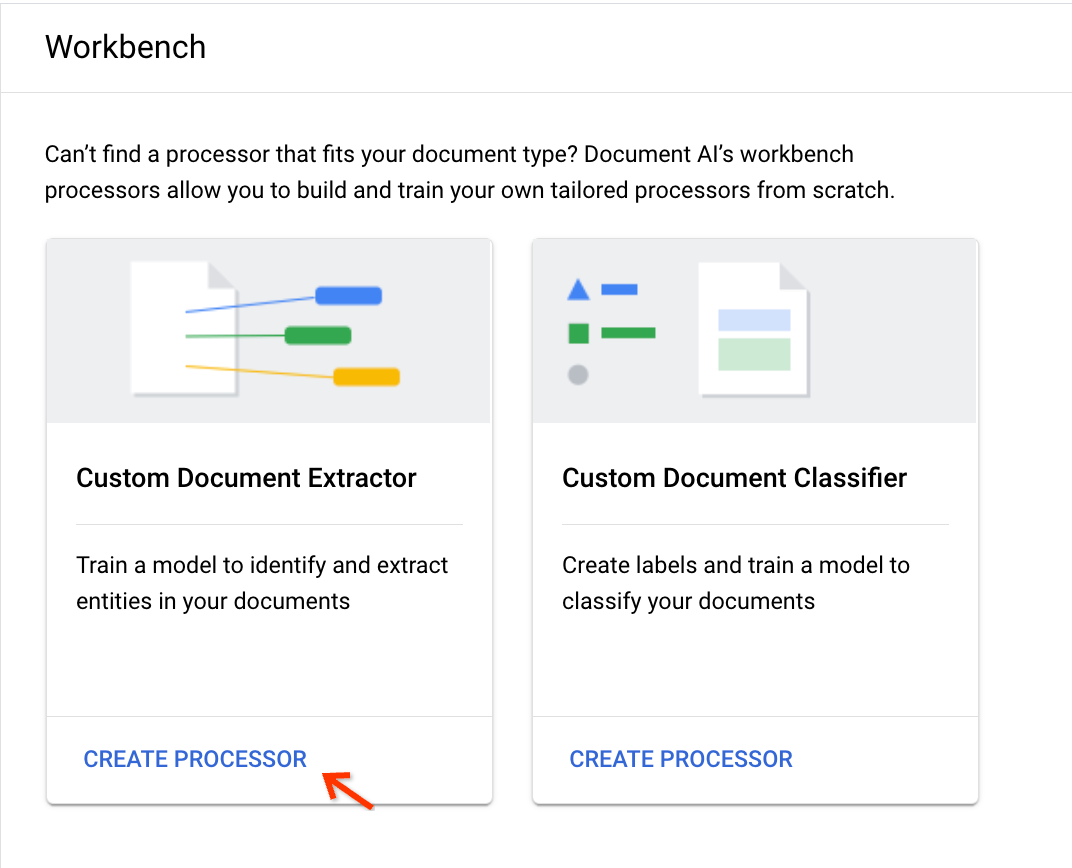
Enter a display name and click Create:
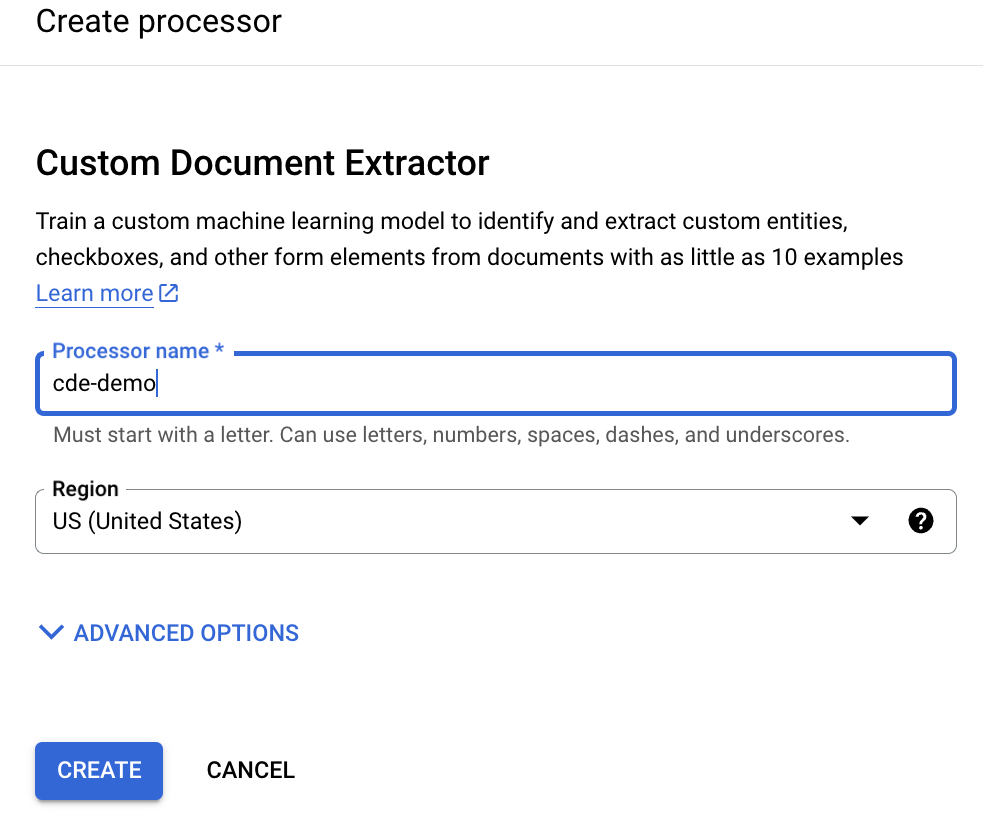
The CDE should be created quickly.
Set up the dataset of the CDE
On the processor details page, click Set Dataset Location:
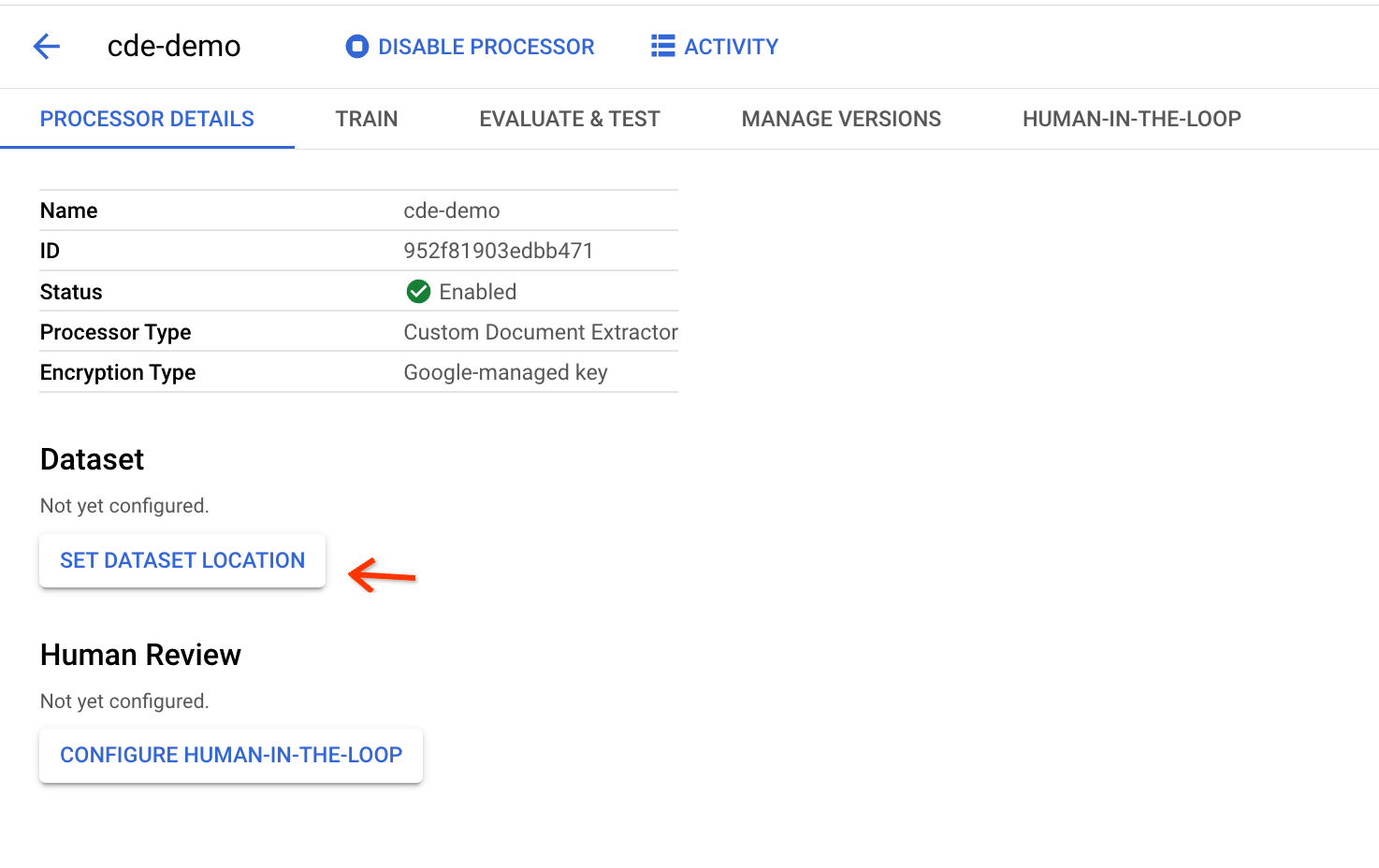
Specify a bucket path to use to store the documents in the dataset:
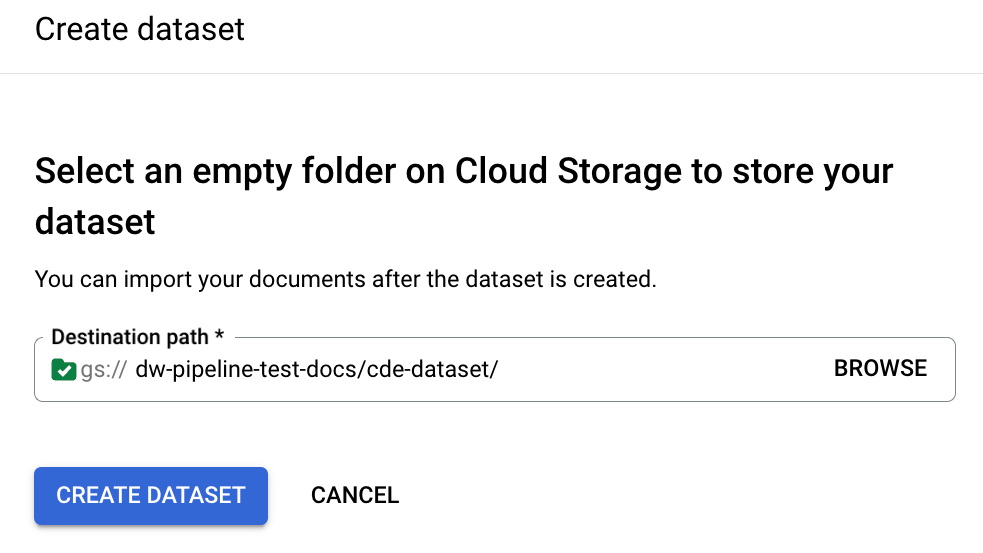
It takes a few minutes to finish configuration. Afterward, you can see the bucket path and count in the details page:
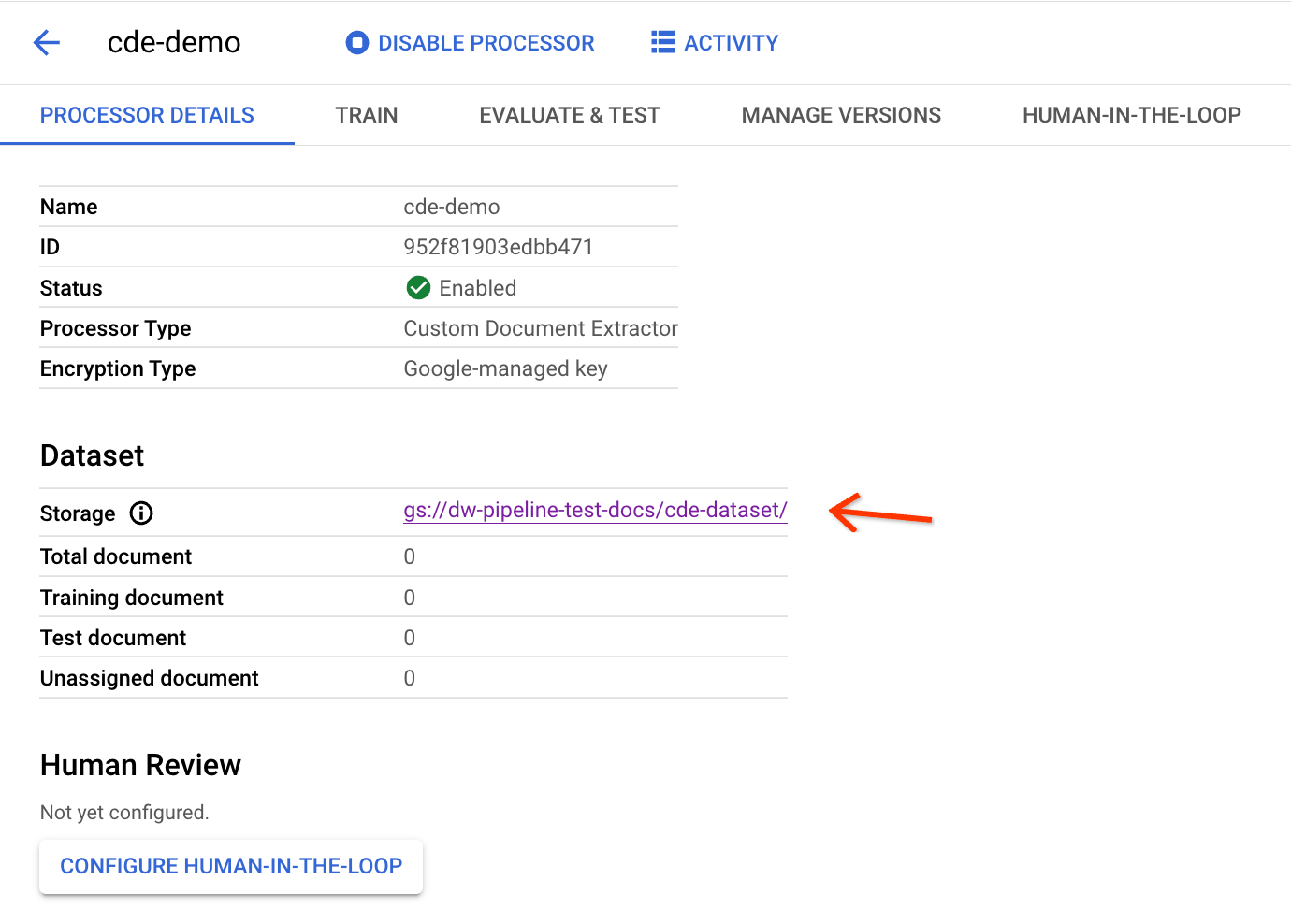
You need the processor ID above to trigger the export-to- Workbench pipeline.
Trigger the export-to-Workbench pipeline
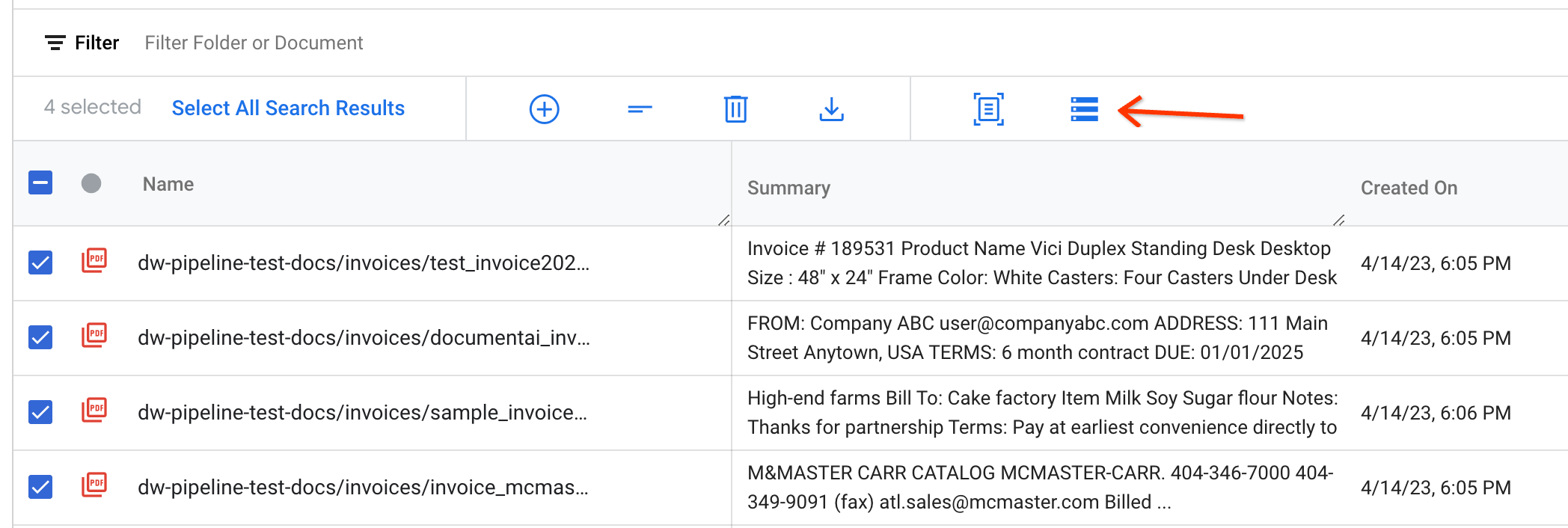
Select documents to export and click Export to Document AI Workbench on the action bar:
Enter input parameters and trigger the pipeline by copying the processor ID from the CDE and pasting it in the dialog.
You need a staging bucket path to temporarily store the documents before exporting them. Data split lets users randomly put the document into a training or test set. The ratio of the splits is based on this value.
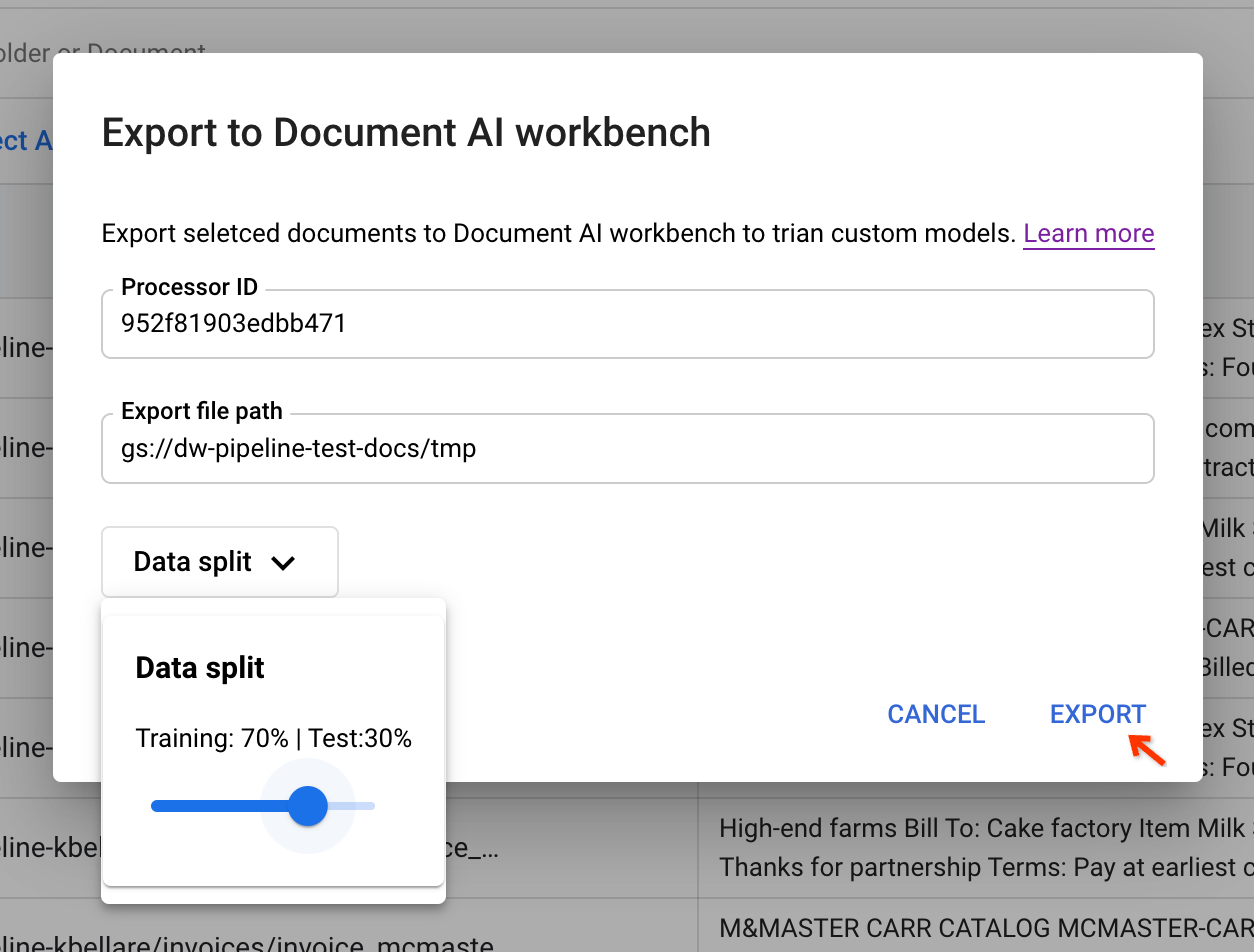
By clicking Export, the pipeline job is triggered.
Track status.
After triggering the pipeline, a status tracking page appears. Currently, the page does not have in-progress tracking. The status page shows pending until the job is complete.
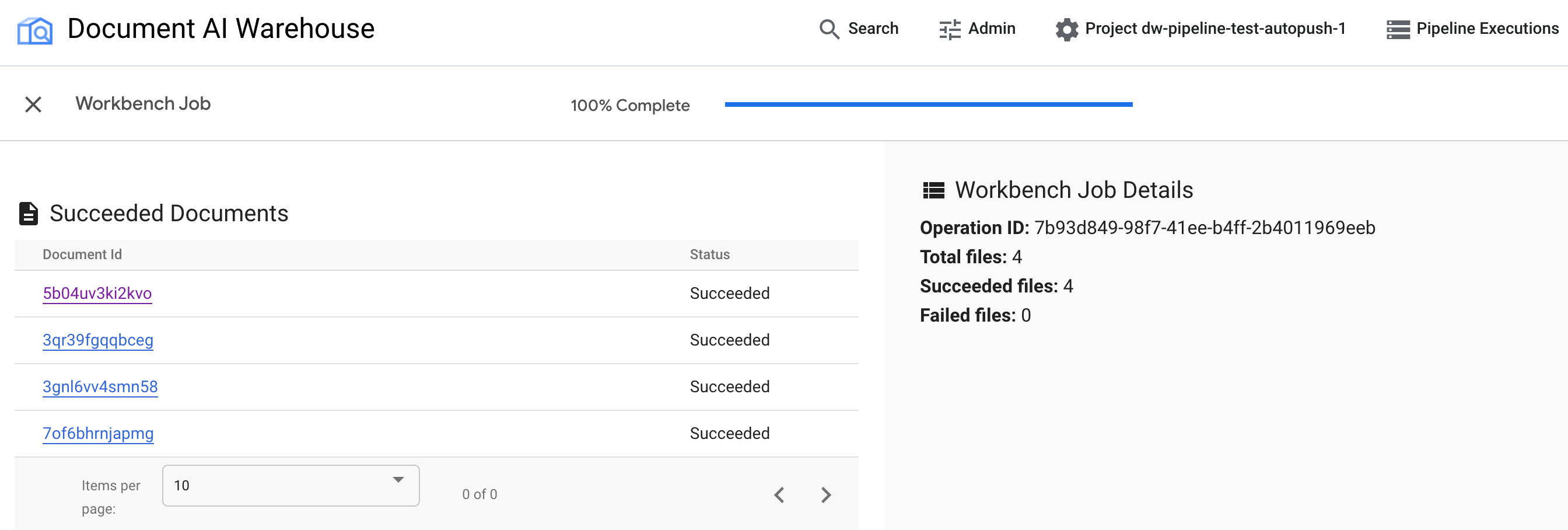
Examine results.
After the job is completed, you can see the successful documents and failed documents.
To check if the documents are exported correctly, go back to the CDE's details page:
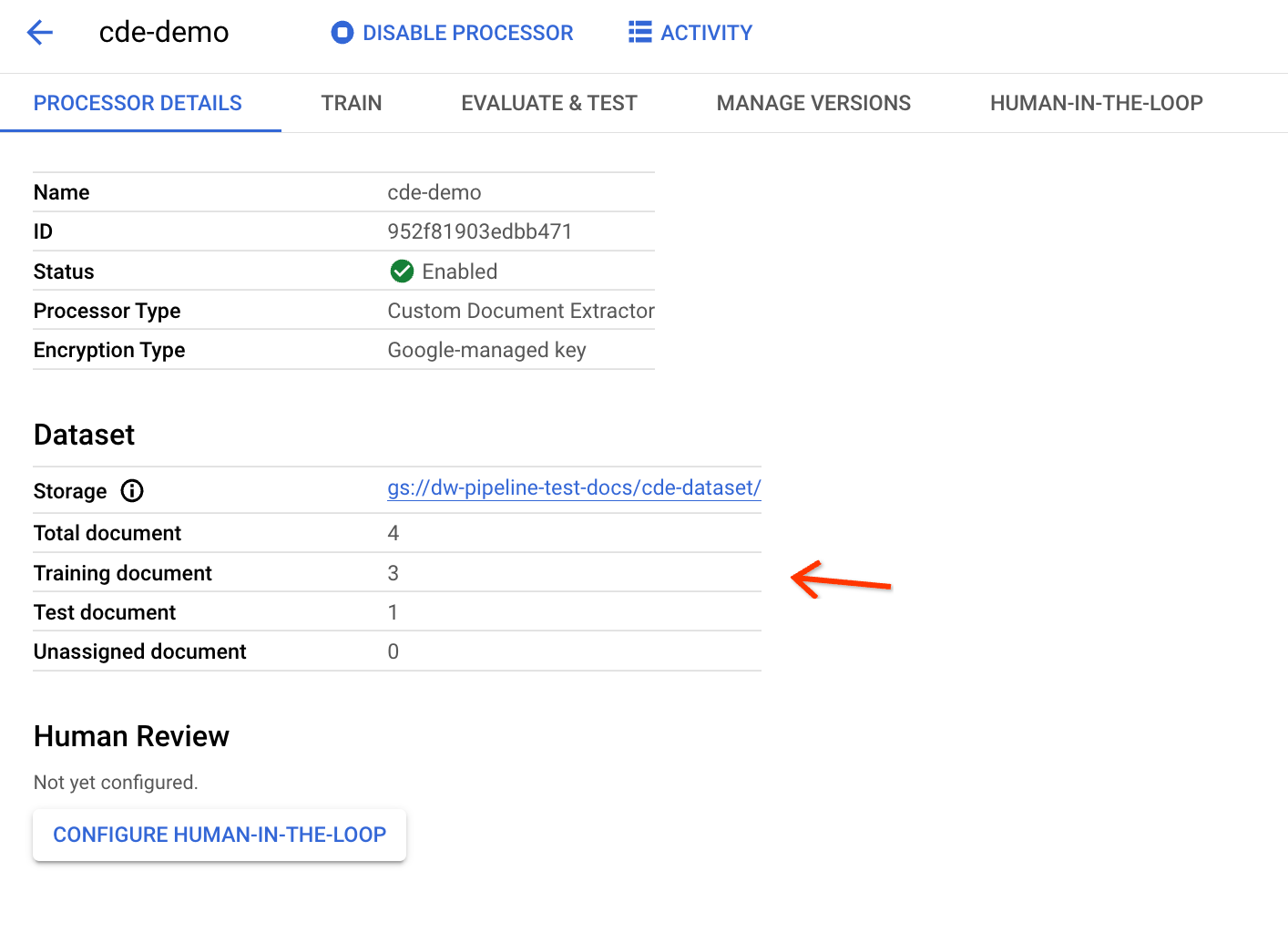
If you have the page open before the pipeline execution, refresh it to find the updated statistics. The training and test set distributions are based on the data-split ratio.
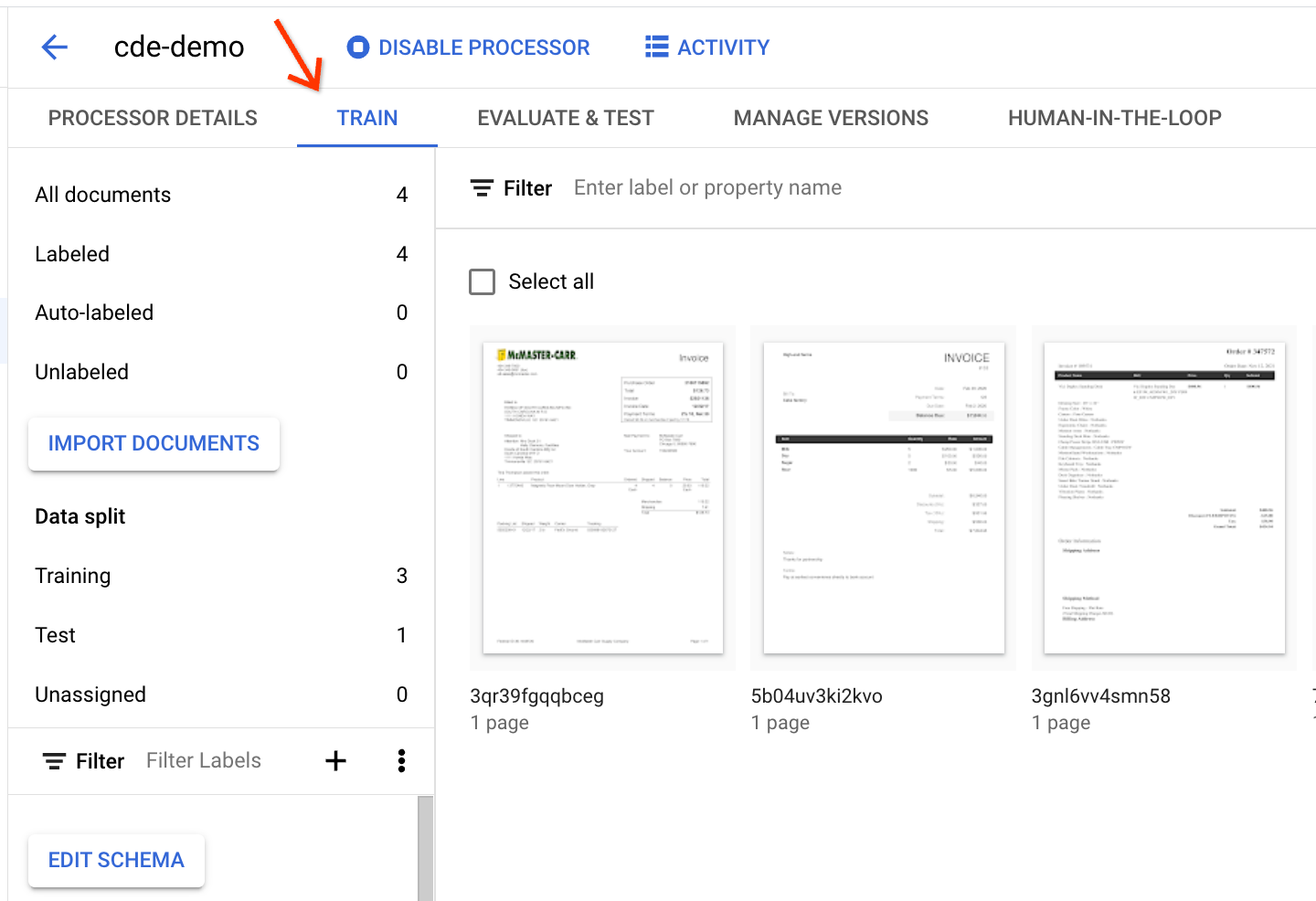
To see the documents in detail, go to the Train tab:
Next step
Check out more information about the runPipeline API.