Per addestrare, eseguire l'ottimizzazione dell'addestramento o valutare una versione del processore è necessario un set di dati etichettato dei documenti.
Questa pagina descrive come applicare le etichette dello schema del processore ai documenti importati nel set di dati.
Questa pagina presuppone che tu abbia già creato un processore che supporti l'addestramento, l'ottimizzazione dell'addestramento o la valutazione. Se il processore è supportato, ora vedrai la scheda Addestra nella console Google Cloud . Inoltre, presuppone che tu abbia creato un set di dati, importato documenti e definito uno schema del processore.
Campi dei nomi per l'estrazione con AI generativa
Il modo in cui vengono denominati i campi influisce sull'accuratezza dell'estrazione dei campi utilizzando l'AI generativa. Consigliamo le seguenti best practice per la denominazione dei campi:
Assegna al campo lo stesso nome utilizzato per descriverlo nel documento: ad esempio, se un documento ha un campo descritto come
Employer Address, assegna al campo il nomeemployer_address. Non utilizzare abbreviazioni comeemplr_addr.Gli spazi non sono attualmente supportati nei nomi dei campi: invece di utilizzare spazi, utilizza
_. Ad esempio,First Nameverrà chiamatofirst_name.Itera sui nomi per migliorare l'accuratezza: Document AI ha una limitazione che non consente di modificare i nomi dei campi. Per testare nomi diversi, utilizza lo strumento di ridenominazione dei nomi delle entità per aggiornare il nome della vecchia entità con uno più recente nel set di dati, importa il set di dati, attiva le nuove entità nel processore e disattiva o elimina i campi esistenti.
Apprendimento zero-shot e few-shot
I modelli con Gemini hanno un apprendimento zero-shot e few-shot, che può creare modelli ad alto rendimento con pochi o nessun dato di addestramento.
L'apprendimento zero-shot è un esempio di machine learning in cui un modello preaddestrato senza alcun addestramento aggiuntivo impara a riconoscere e classificare classi ed entità che non ha mai incontrato prima durante i test.
L'apprendimento few-shot è un metodo in cui un modello impara a riconoscere e classificare nuove classi ed entità con solo pochi esempi di addestramento per classe. Sfrutta le conoscenze dei modelli preaddestrati su set di dati di grandi dimensioni e ben etichettati per migliorare il rendimento delle attività few-shot.
Il few-shot diventa più efficace quando il set di dati di addestramento è ordinato e etichettato con cura. In genere, ciò significa disporre di almeno 10 esempi di test e 10 di addestramento da cui il modello possa apprendere.
Opzioni di etichettatura
Di seguito sono riportate le opzioni per l'etichettatura dei documenti:
Manuale: etichetta manualmente i documenti nella Google Cloud console
Etichettatura automatica: utilizza una versione del processore esistente per generare etichette
Importa documenti preetichettati: risparmia tempo se hai già documenti etichettati
Etichettare manualmente nella console Google Cloud
Nella scheda Addestra, seleziona un documento per aprire lo strumento di etichettatura.
Dall'elenco delle etichette dello schema sul lato sinistro dello strumento di etichettatura, seleziona il simbolo "Aggiungi" per selezionare lo strumento Riquadro di selezione per evidenziare le entità nel documento e assegnarle a un'etichetta.
Nello screenshot seguente, ai campi EMPL_SSN EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS,
FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES e WAGES_TIPS_OTHER_COMP
del documento sono state assegnate etichette.
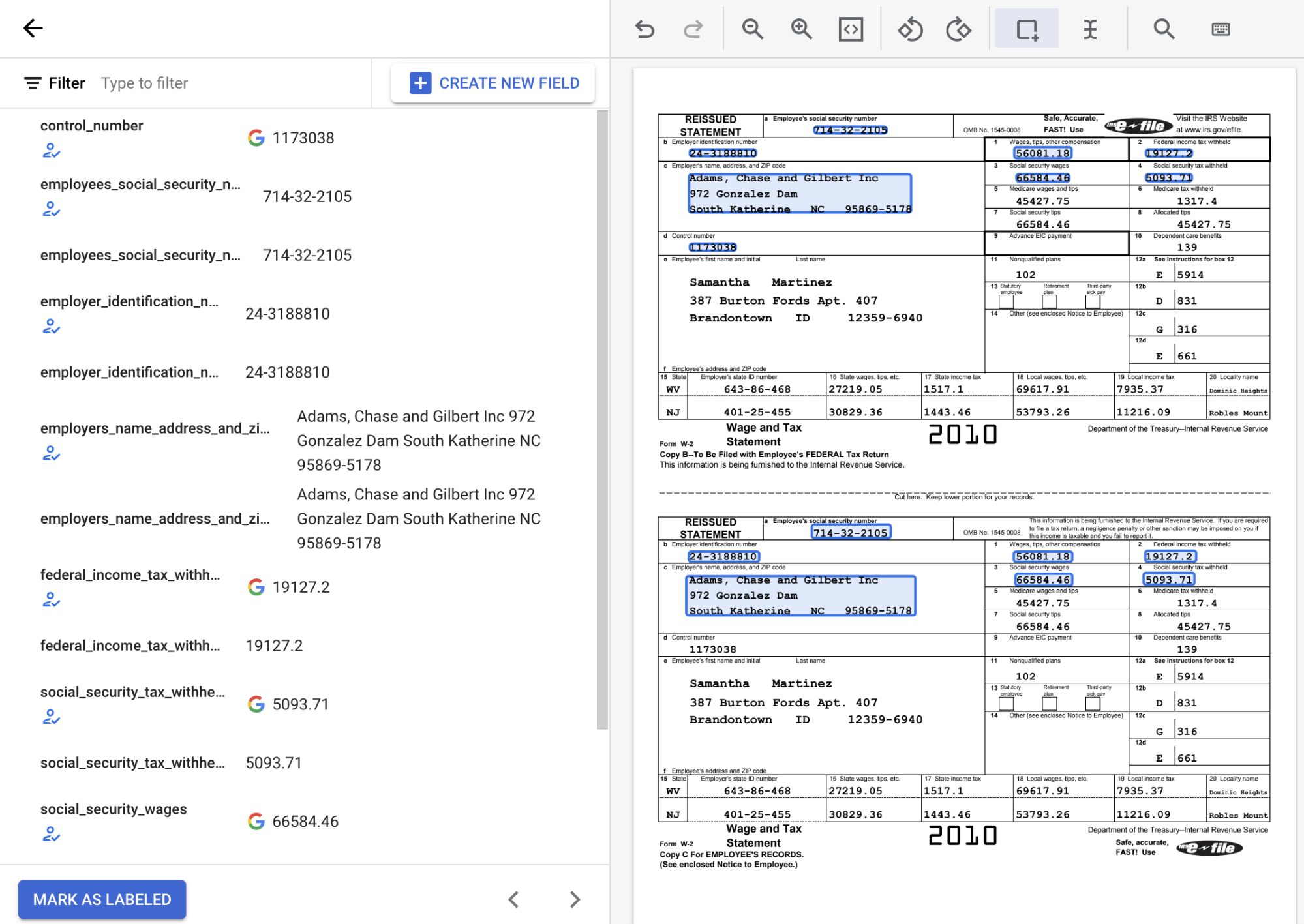
Quando selezioni un'entità casella di controllo con lo strumento Riquadro di delimitazione, seleziona solo la casella di controllo e non il testo associato. Assicurati che la casella di controllo dell'entità mostrata a sinistra sia selezionata o deselezionata in modo che corrisponda a quanto riportato nel documento.

Quando etichetti le entità padre-figlio, non etichettare le entità padre. Le entità principali sono solo contenitori delle entità secondarie. Etichetta solo le entità secondarie. Le entità principali vengono aggiornate automaticamente.
Quando etichetti le entità secondarie, etichetta la prima entità secondaria e poi associa le entità secondarie correlate a quella riga. Lo noti nella seconda entità secondaria la prima volta che etichetti queste entità. Ad esempio, con una fattura, se etichetti descrizione, sembra un'altra entità. Tuttavia, se etichetti quantità, ti viene chiesto di scegliere il genitore.
Ripeti questo passaggio per ogni elemento pubblicitario selezionando Nuova entità principale per ogni nuovo elemento pubblicitario.
Le entità padre-figlio sono supportate per le tabelle con un massimo di tre livelli di nidificazione. I modelli di base supportano tre livelli di campi (nonno, genitore, figlio), quindi le entità secondarie possono avere un solo livello di figli. Per scoprire di più sull'annidamento, consulta Annidamento a tre livelli.
Tabelle rapide
Quando etichetti una tabella, potrebbe essere noioso etichettare ogni riga più e più volte. Esiste uno strumento molto pratico che può replicare la struttura di un'entità riga. Tieni presente che questa funzionalità funziona solo sulle righe allineate orizzontalmente.
- Innanzitutto, etichetta la prima riga come di consueto.
Poi, tieni il puntatore sopra l'entità padre che rappresenta la riga. Seleziona Aggiungi altre righe. La riga diventa un modello per creare altre righe.
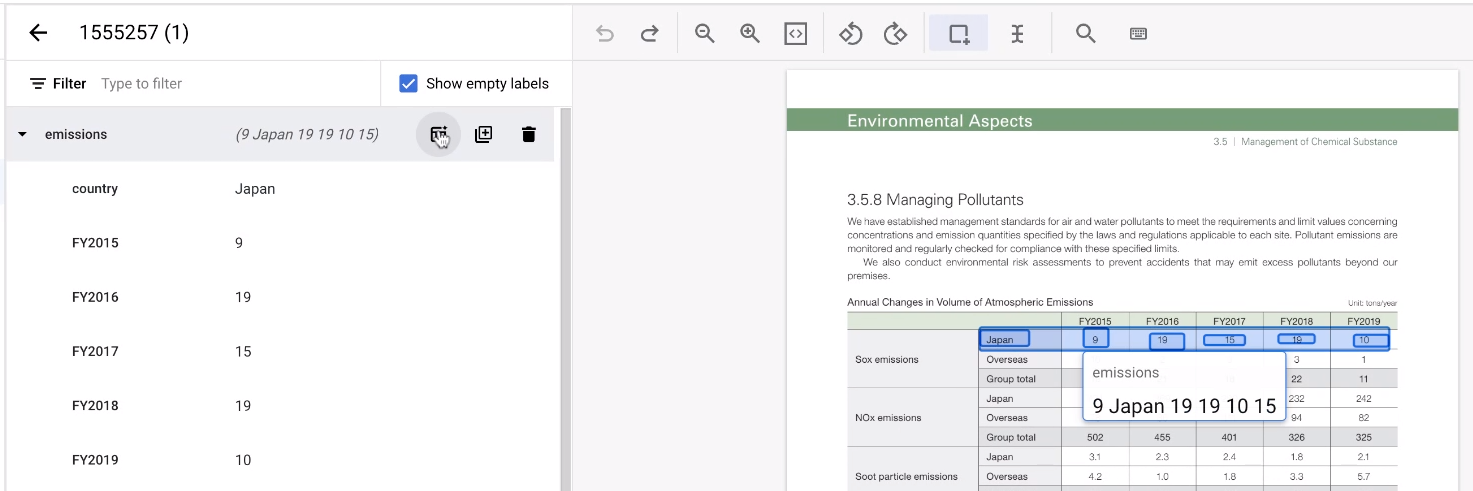
Seleziona il resto dell'area della tabella.
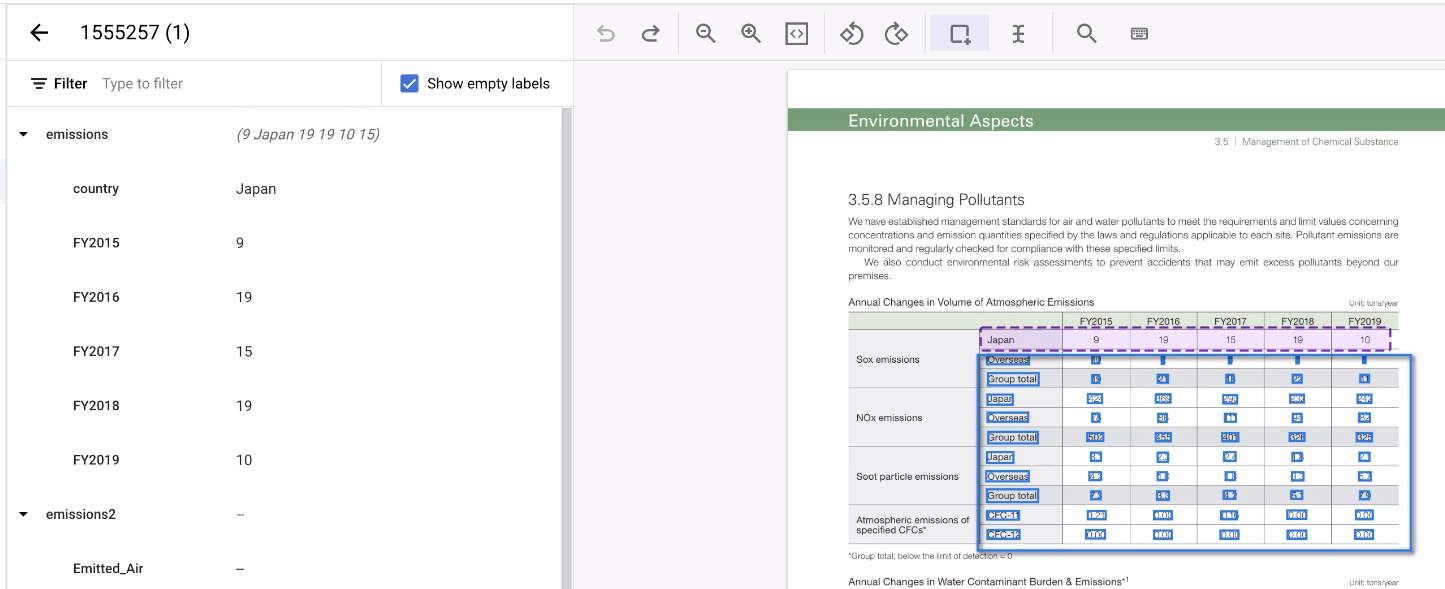
Lo strumento indovina le annotazioni e di solito funziona. Per le tabelle che non riesce a gestire, annotale manualmente.
Utilizzare le scorciatoie da tastiera nella console
Per visualizzare le scorciatoie da tastiera disponibili, seleziona il menu in alto a destra nella console di etichettatura. Visualizza un elenco di scorciatoie da tastiera, come mostrato nella tabella seguente.
| Azione | Scorciatoia |
|---|---|
| Aumenta lo zoom | Alt + = (Opzione + = su macOS) |
| Diminuisci lo zoom | Alt + - (Opzione + - su macOS) |
| Adatta alla finestra | Alt + 0 (Opzione + 0 su macOS) |
| Scorri per eseguire lo zoom | Alt + Scorrimento (Opzione + Scorrimento su macOS) |
| Panoramica | Scorrimento |
| Panoramica invertita | Maiusc + scorrimento |
| Trascina per eseguire la panoramica | Barra spaziatrice + trascinamento del mouse |
| Annulla | Ctrl + Z (Control + Z su macOS) |
| Ripeti | Ctrl + Shift + Z (Control + Shift + Z su macOS) |
Etichetta automaticamente
Se disponibile, puoi utilizzare una versione esistente del processore per iniziare a etichettare.
L'etichettatura automatica può essere avviata durante l'importazione. Tutti i documenti sono annotati utilizzando la versione del processore specificata.
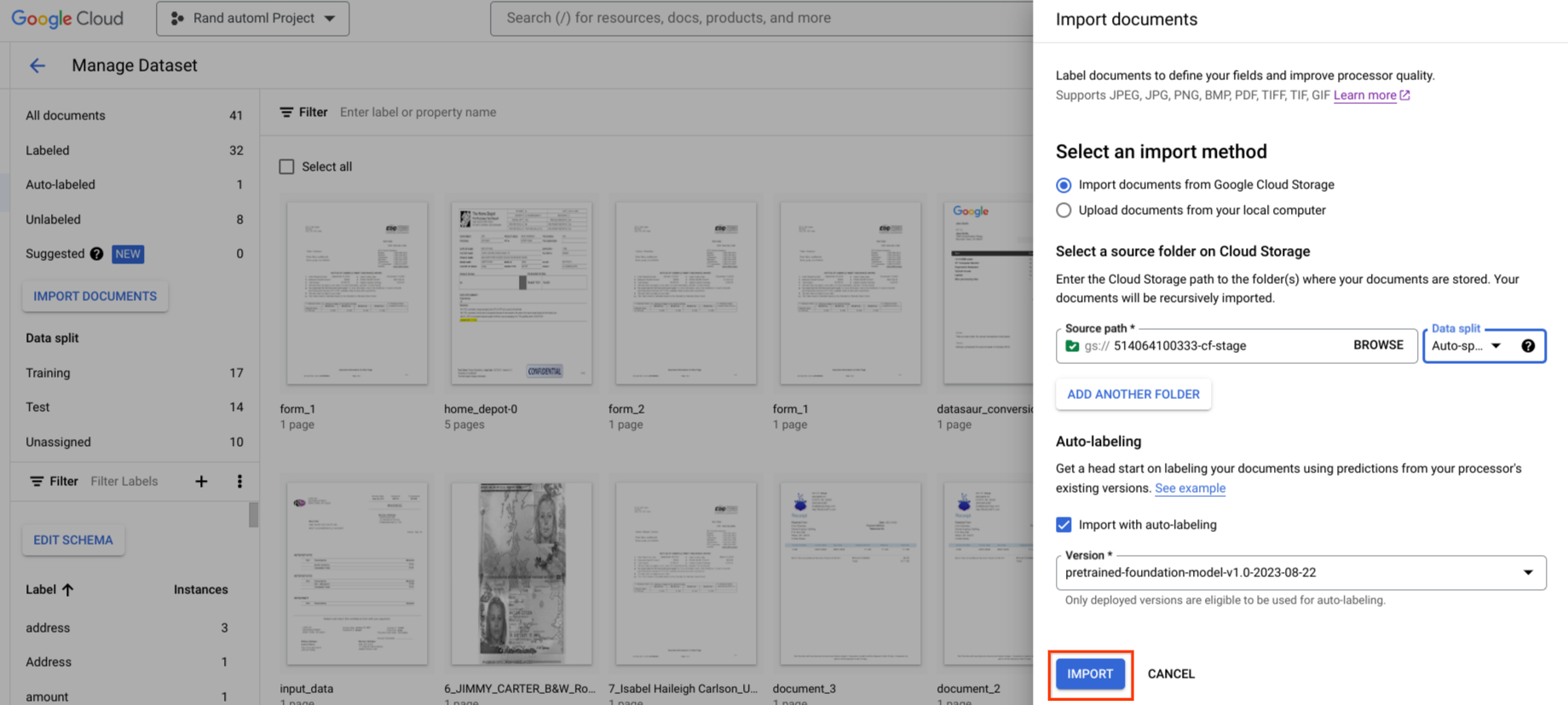
L'etichettatura automatica può essere avviata dopo l'importazione per i documenti nella categoria senza etichetta o etichettati automaticamente. Tutti i documenti selezionati vengono annotati utilizzando la versione del processore specificata.
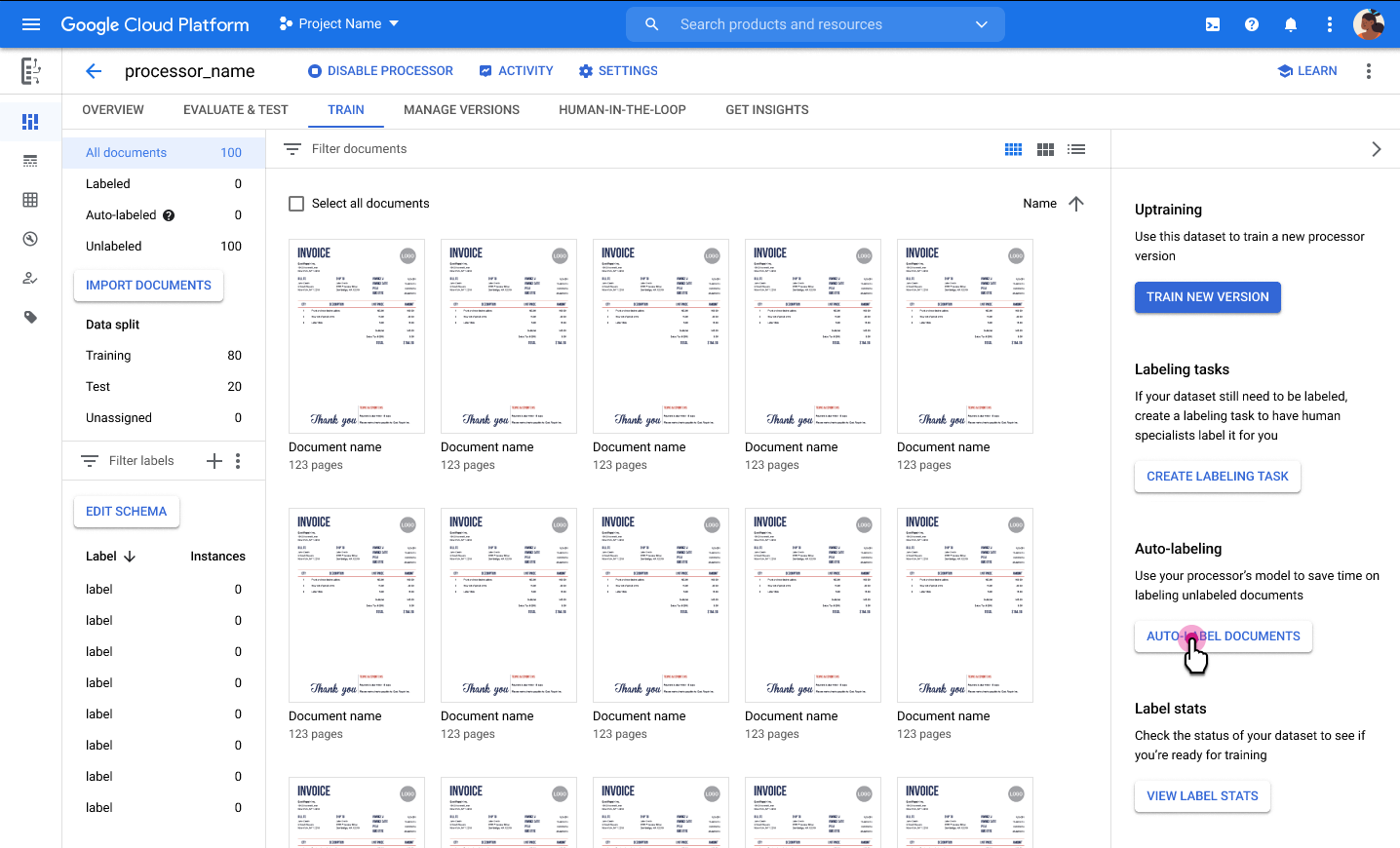
Non puoi addestrare o addestrare sulla base di un modello predefinito i documenti con etichetta automatica né utilizzarli nel set di test senza contrassegnarli come etichettati. Rivedi e correggi manualmente le annotazioni con etichette automatiche, poi seleziona Contrassegna come etichettato per salvare le correzioni. Puoi quindi assegnare i documenti in modo appropriato.
Importare documenti preetichettati
Puoi importare file JSON Document. Se entity nel documento corrisponde all'etichetta nello schema del processore, entity viene convertito in un'istanza di etichetta dall'importatore. Esistono
diversi modi per ottenere file di documenti JSON:
Esportazione di un set di dati da un altro responsabile del trattamento. Vedi Esportare un set di dati.
Invio di una richiesta di elaborazione a un processore esistente.
Utilizza il toolkit di importazione per convertire le etichette esistenti da un altro sistema, ad esempio l'etichetta in formato CSV in documenti JSON.
Best practice per l'etichettatura dei documenti
Per addestrare un processore di alta qualità è necessaria un'etichettatura coerente. Ti consigliamo di:
Crea istruzioni di etichettatura: le istruzioni devono includere esempi per i casi comuni e limite. Alcuni suggerimenti:
- Spiega quali campi devono essere annotati e come rendere l'etichettatura coerente. Ad esempio, quando etichetti "importo", specifica se il simbolo di valuta deve essere etichettato. Se le etichette non sono coerenti, la qualità del processore viene ridotta.
- Etichetta tutte le occorrenze di un'entità, anche se il tipo di etichetta è
REQUIRED_ONCEoOPTIONAL_ONCE. Ad esempio, seinvoice_idcompare due volte nel documento, etichetta tutte le occorrenze. - In genere è preferibile etichettare prima con lo strumento riquadro di delimitazione predefinito. Se non funziona, utilizza lo strumento di selezione del testo.
- Se il valore dell'etichetta non viene rilevato correttamente dalla tecnologia OCR, non correggere manualmente il valore. In questo modo, non sarebbe utilizzabile per scopi di addestramento.
Ecco alcune istruzioni di etichettatura di esempio:
- Analizzatore estratto conto bancario
- Analizzatore sintattico delle utenze
- Analizzatore busta paga
- Analizzatore sintattico delle spese
- Analizzatore sintattico delle fatture
- Addestra gli annotatori: assicurati che comprendano e possano seguire le linee guida senza errori sistematici. Un modo per raggiungere questo obiettivo è chiedere a diversi tirocinanti di annotare lo stesso insieme di documenti. L'addestratore può quindi controllare la qualità del lavoro di annotazione di ciascun tirocinante. Potresti dover ripetere questa procedura finché i tirocinanti non raggiungono un livello di precisione di riferimento.
- Revisioni iniziali: i primi documenti (circa 10) etichettati per un caso d'uso da un nuovo etichettatore devono essere rivisti prima che venga etichettato un numero elevato di documenti per evitare un gran numero di errori da correggere.
- Revisioni della qualità delle annotazioni: data la natura laboriosa delle annotazioni, anche gli annotatori addestrati possono commettere errori. Ti consigliamo di far controllare le annotazioni da almeno un altro annotatore esperto.
Aggiungere un prompt di descrizione
Quando aggiungi etichette allo schema nell'estrattore personalizzato e nel classificatore personalizzato, puoi aggiungere una descrizione per l'etichetta. In questo modo, il processore viene addestrato fornendo un prompt con cui identificare l'etichetta. Puoi provare delle leggere variazioni per testare la qualità della risposta. Ad esempio, "importo totale", "importo totale fattura" o "importo totale della fattura".
Sincronizza di nuovo il set di dati
La risincronizzazione mantiene la cartella Cloud Storage del set di dati coerente con l'indice interno dei metadati di Document AI. Questa operazione è utile se hai apportato modifiche accidentali alla cartella Cloud Storage e vuoi sincronizzare i dati.
Per risincronizzare:
Nella scheda Dettagli processore, accanto alla riga Posizione di archiviazione, seleziona e poi Sincronizza di nuovo il set di dati.
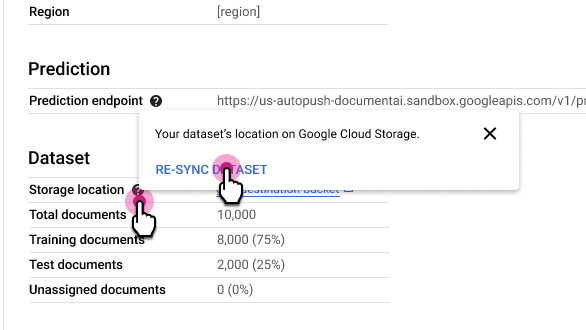
Note sull'utilizzo:
- Se elimini un documento dalla cartella Cloud Storage, la sincronizzazione lo rimuove dal set di dati.
- Se aggiungi un documento alla cartella Cloud Storage, la risincronizzazione non lo aggiunge al set di dati. Per aggiungere documenti, importali.
- Se modifichi le etichette dei documenti nella cartella Cloud Storage, la sincronizzazione aggiorna le etichette dei documenti nel set di dati.
Esegui la migrazione del set di dati
L'importazione e l'esportazione ti consentono di spostare tutti i documenti di un set di dati da un processore a un altro. Ciò può essere utile se hai processori in regioni o Google Cloud progetti diversi, se hai processori diversi per staging e produzione o per il consumo offline generale.
Tieni presente che vengono esportati solo i documenti e le relative etichette. I metadati del set di dati, come lo schema del processore, le assegnazioni dei documenti (addestramento/test/non assegnati) e lo stato di etichettatura dei documenti (etichettati, non etichettati, etichettati automaticamente) non vengono esportati.
La copia e l'importazione del set di dati e l'addestramento del processore di destinazione non sono
esattamente uguali all'addestramento del processore di origine. Questo perché all'inizio del processo di addestramento vengono utilizzati valori casuali. Utilizza la chiamata API importProcessorVersion per importare e migrare lo stesso modello tra i progetti. Questa è la best practice per la migrazione dei processori a ambienti di livello superiore (ad esempio sviluppo, staging e produzione) se i criteri lo consentono.
Esporta set di dati
Per esportare tutti i documenti come file JSON
Document in una cartella Cloud Storage,
seleziona Esporta set di dati.
Alcuni aspetti importanti da tenere a mente:
Durante l'esportazione, vengono create tre sottocartelle: Test, Train e Unassigned. I tuoi documenti vengono inseriti di conseguenza in queste sottocartelle.
Lo stato dell'etichettatura di un documento non viene esportato. Se in un secondo momento importi i documenti, questi non verranno contrassegnati come etichettati automaticamente.
Se Cloud Storage si trova in un progetto diverso, assicurati di concedere l'accesso in modo che Document AI possa scrivere file in quella posizione. Google Cloud In particolare, devi concedere il ruolo Storage Object Creator all'agente di servizio principale di Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Per maggiori informazioni, consulta la pagina Agenti di servizio.
Importa set di dati
La procedura è la stessa di Importa documenti.
Guida utente all'etichettatura selettiva
L'etichettatura selettiva fornisce suggerimenti su quali documenti etichettare. Puoi creare set di dati di addestramento e test diversi per addestrare modelli rappresentativi. Ogni volta che viene eseguita l'etichettatura selettiva, vengono selezionati i documenti più diversi (fino a 30) del set di dati.
Visualizzare i documenti suggeriti
Crea un processore CDE e importa i documenti.
- Per l'addestramento sono necessari almeno 100 esempi (25 per il test).
- Una volta importati documenti sufficienti e dopo l'etichettatura selettiva, dovrebbe essere visualizzata la barra delle informazioni.
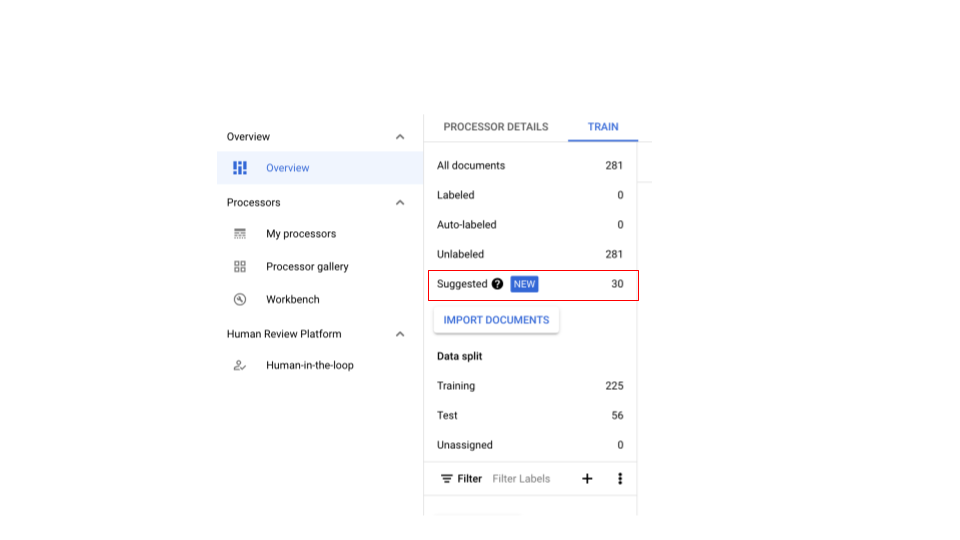
Nel caso di un processore CDE con zero documenti suggeriti, importane altri per avere documenti sufficienti in entrambe le suddivisioni per il campionamento.
- In questo modo dovrebbero essere attivati i documenti suggeriti nella categoria Suggeriti. Dovresti essere in grado di richiedere manualmente i documenti suggeriti.
- Nella parte superiore è presente un nuovo filtro per escludere i documenti suggeriti.
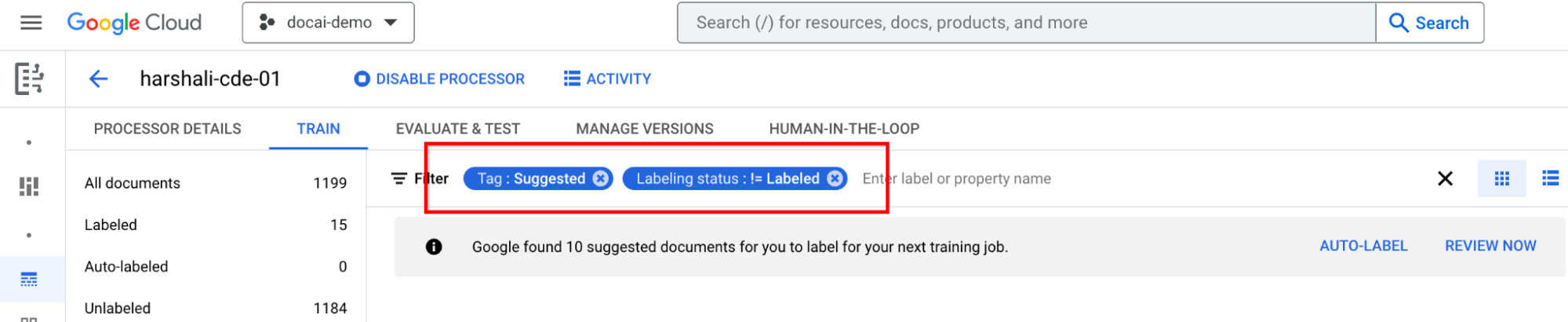
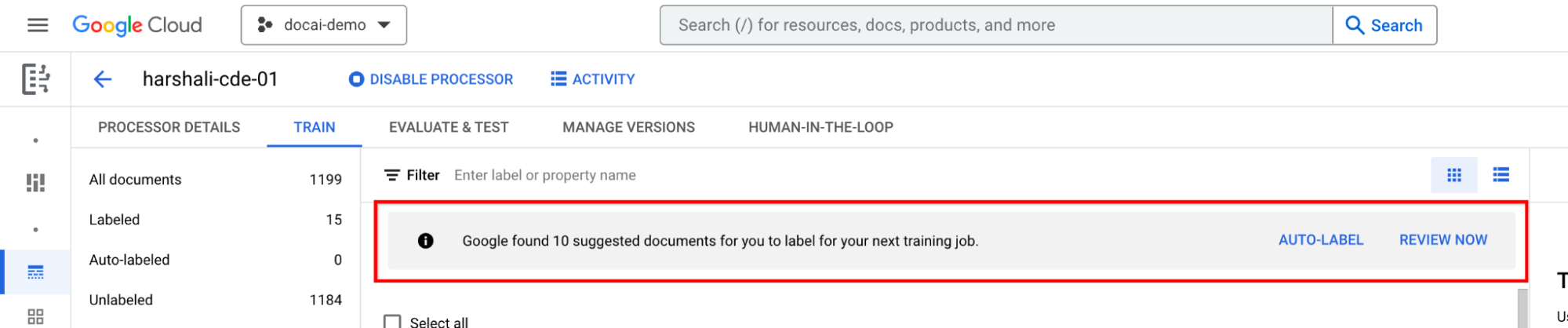
Etichettare i documenti suggeriti
Vai a Categoria suggerita nel riquadro dell'elenco delle etichette a sinistra. Inizia a etichettare questi documenti.
Seleziona Etichettatura automatica nella barra delle informazioni se il processore è addestrato. Etichetta i documenti suggeriti.
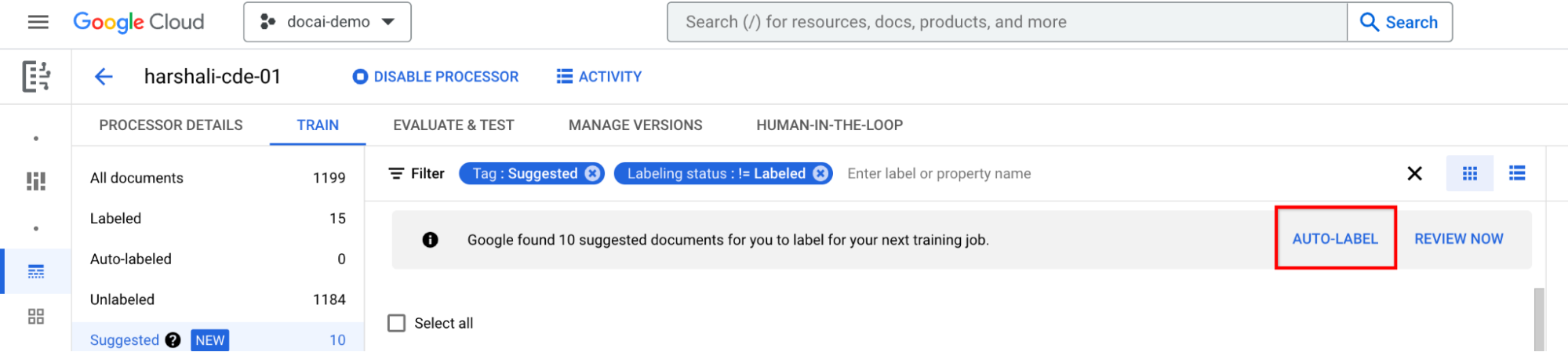
Puoi quindi selezionare Rivedi ora sulla barra quando hai documenti suggeriti nel processore a cui passare. Tutti i documenti etichettati automaticamente devono essere esaminati per verificarne l'accuratezza. Inizia la revisione.
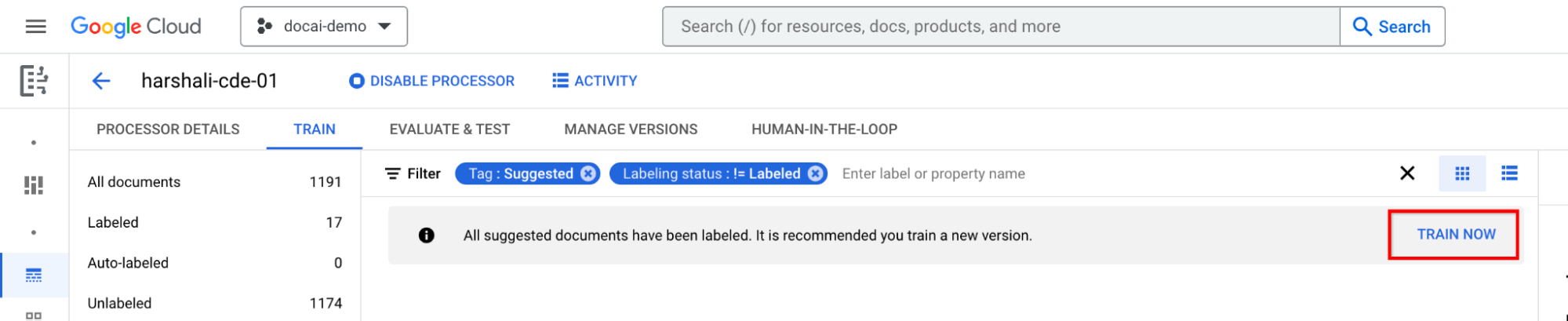
Esegui l'addestramento dopo aver etichettato tutti i documenti suggeriti
Vai a Allenati ora nella barra delle informazioni. Quando i documenti suggeriti sono etichettati, dovresti visualizzare la seguente barra informativa che consiglia l'addestramento.
Funzionalità supportate e limitazioni
| Funzionalità | Descrizione | Supportato |
|---|---|---|
| Supporto per i vecchi processori | Potrebbe non funzionare bene con i vecchi processori con il set di dati importato in precedenza |