Document AI genera métricas de evaluación, como la precisión y el recuerdo, que te ayudan a determinar el rendimiento predictivo de tus procesadores.
Estas métricas de evaluación se generan comparando las entidades que devuelve el procesador (las predicciones) con las anotaciones que hay en los documentos de prueba. Si tu procesador no tiene un conjunto de pruebas, primero debes crear un conjunto de datos y etiquetar los documentos de prueba.
Haz una evaluación
Cada evaluación se ejecuta automáticamente cada vez que entrenas o mejoras una versión de un procesador.
También puedes ejecutar una evaluación manualmente. Es obligatorio para generar métricas actualizadas después de modificar el conjunto de pruebas o si estás evaluando una versión de procesador preentrenada.
UI web
En la Google Cloud consola, ve a la página Procesadores y elige el procesador.
En la pestaña Evaluar y probar, seleccione la versión del procesador que quiera evaluar y, a continuación, haga clic en Ejecutar nueva evaluación.
Una vez completado el proceso, la página contiene métricas de evaluación de todas las etiquetas y de cada etiqueta individual.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Obtener los resultados de una evaluación
UI web
En la Google Cloud consola, ve a la página Procesadores y elige el procesador.
En la pestaña Evaluar y probar, seleccione la versión del procesador para ver la evaluación.
Una vez completado el proceso, la página contiene métricas de evaluación de todas las etiquetas y de cada etiqueta individual.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Mostrar todas las evaluaciones de una versión de un procesador
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Métricas de evaluación de todas las etiquetas
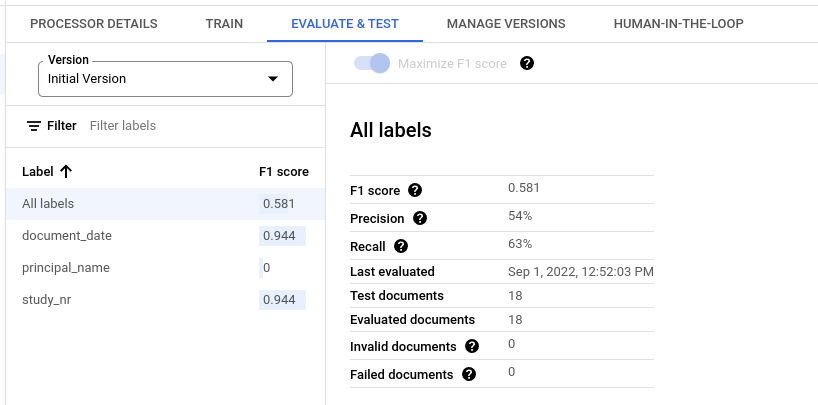
Las métricas de Todas las etiquetas se calculan en función del número de verdaderos positivos, falsos positivos y falsos negativos del conjunto de datos en todas las etiquetas. Por lo tanto, se ponderan según el número de veces que aparece cada etiqueta en el conjunto de datos. Para ver las definiciones de estos términos, consulta Métricas de evaluación de etiquetas individuales.
Precisión: proporción de predicciones que coinciden con las anotaciones del conjunto de prueba. Definido como
True Positives / (True Positives + False Positives)Recuerdo: proporción de anotaciones del conjunto de prueba que se han predicho correctamente. Definido como
True Positives / (True Positives + False Negatives)Puntuación F1: media armónica de la precisión y la recuperación, que combina ambas métricas en una sola y les da la misma importancia. Definido como
2 * (Precision * Recall) / (Precision + Recall)
Métricas de evaluación de etiquetas concretas
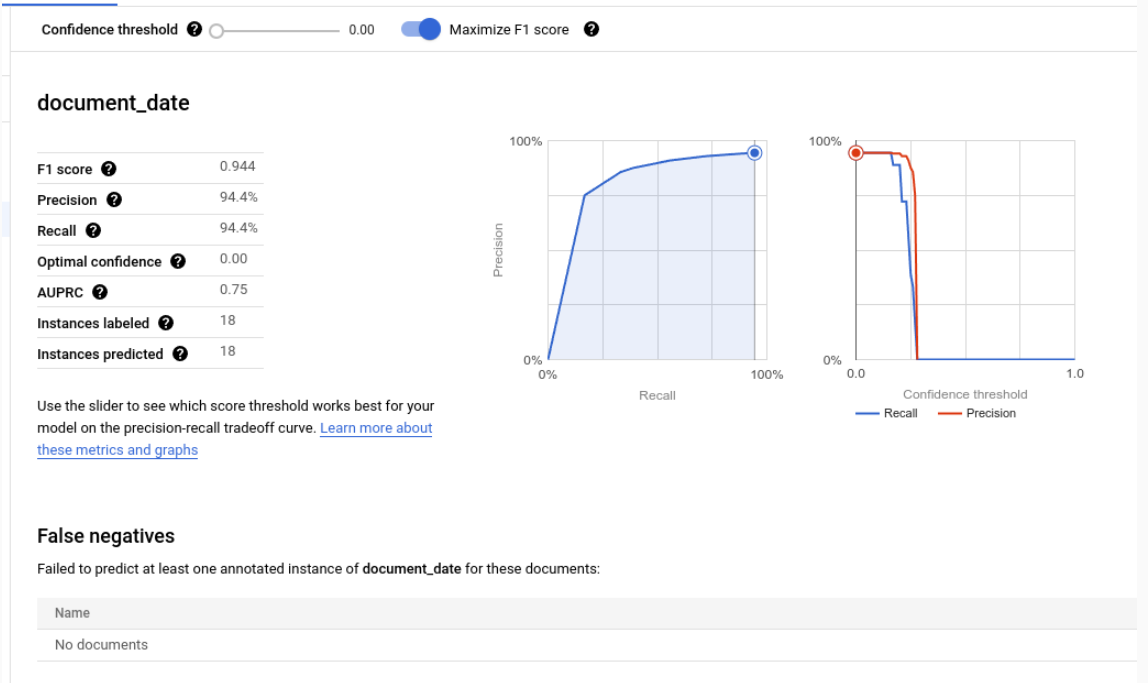
Verdaderos positivos: las entidades predichas que coinciden con una anotación del documento de prueba. Para obtener más información, consulta el comportamiento de las coincidencias.
Falsos positivos: las entidades predichas que no coinciden con ninguna anotación del documento de prueba.
Falsos negativos: las anotaciones del documento de prueba que no coinciden con ninguna de las entidades predichas.
- Falsos negativos (por debajo del umbral): las anotaciones del documento de prueba que habrían coincidido con una entidad predicha, pero el valor de confianza de la entidad predicha está por debajo del umbral de confianza especificado.
Umbral de confianza
La lógica de evaluación ignora las predicciones con una confianza inferior al umbral de confianza especificado, aunque la predicción sea correcta. Document AI proporciona una lista de falsos negativos (por debajo del umbral), que son las anotaciones que tendrían una coincidencia si el umbral de confianza fuera más bajo.
Document AI calcula automáticamente el umbral óptimo, que maximiza la puntuación F1, y, de forma predeterminada, define el umbral de confianza en este valor óptimo.
Puedes elegir el umbral de confianza que quieras moviendo la barra deslizante. En general, un umbral de confianza más alto da como resultado lo siguiente:
- una mayor precisión, ya que es más probable que las predicciones sean correctas.
- una recuperación menor, ya que hay menos predicciones.
Entidades tabulares
Las métricas de una etiqueta superior no se calculan haciendo la media directamente de las métricas secundarias, sino aplicando el umbral de confianza de la etiqueta superior a todas sus etiquetas secundarias y agregando los resultados.
El umbral óptimo del elemento superior es el valor del umbral de confianza que, cuando se aplica a todos los elementos secundarios, da como resultado la puntuación F1 máxima del elemento superior.
Comportamiento de la coincidencia
Una entidad predicha coincide con una anotación si:
- El tipo de la entidad predicha
(
entity.type) coincide con el nombre de la etiqueta de la anotación. - El valor de la entidad predicha (
entity.mention_textoentity.normalized_value.text) coincide con el valor de texto de la anotación, sujeto a la coincidencia aproximada si está habilitada.
Ten en cuenta que solo se usan el tipo y el valor de texto para las coincidencias. No se usa otra información, como anclas de texto y cuadros delimitadores (excepto las entidades tabulares descritas más abajo).
Etiquetas de una o varias ocurrencias
Las etiquetas de una sola aparición tienen un valor por documento (por ejemplo, el ID de factura), aunque ese valor se anote varias veces en el mismo documento (por ejemplo, el ID de factura aparece en todas las páginas del mismo documento). Aunque las anotaciones tengan textos diferentes, se consideran iguales. Es decir, si una entidad predicha coincide con alguna de las anotaciones, se considera una coincidencia. Las anotaciones adicionales se consideran menciones duplicadas y no contribuyen a los recuentos de verdaderos positivos, falsos positivos o falsos negativos.
Las etiquetas de varias ocurrencias pueden tener varios valores diferentes. Por lo tanto, cada entidad y anotación predichas se consideran y se emparejan por separado. Si un documento contiene N anotaciones para una etiqueta de varias ocurrencias, puede haber N coincidencias con las entidades predichas. Cada entidad y anotación predichas se contabilizan de forma independiente como un positivo verdadero, un falso positivo o un falso negativo.
Coincidencia parcial
El interruptor Coincidencia aproximada te permite ajustar o relajar algunas de las reglas de coincidencia para aumentar o reducir el número de coincidencias.
Por ejemplo, sin la coincidencia aproximada, la cadena ABC no coincide con abc debido a las mayúsculas. Sin embargo, con la coincidencia parcial, sí coinciden.
Si la coincidencia aproximada está habilitada, las reglas cambian de la siguiente manera:
Normalización de espacios en blanco: elimina los espacios en blanco iniciales y finales, y condensa los espacios en blanco intermedios consecutivos (incluidos los saltos de línea) en espacios únicos.
Eliminación de signos de puntuación iniciales o finales: elimina los siguientes signos de puntuación iniciales o finales:
!,.:;-"?|.Búsqueda que no distingue entre mayúsculas y minúsculas: convierte todos los caracteres a minúsculas.
Normalización de dinero: en las etiquetas con el tipo de datos
money, elimina los símbolos de moneda iniciales y finales.
Entidades tabulares
Las entidades y las anotaciones principales no tienen valores de texto y se emparejan en función de los cuadros delimitadores combinados de sus elementos secundarios. Si solo hay un elemento superior predicho y un elemento superior anotado, se emparejan automáticamente, independientemente de los cuadros delimitadores.
Una vez que se emparejan los padres, sus hijos se emparejan como si fueran entidades no tabulares. Si no se encuentran coincidencias con los padres, Document AI no intentará encontrar coincidencias con sus hijos. Esto significa que las entidades secundarias se pueden considerar incorrectas, aunque tengan el mismo contenido de texto, si sus entidades principales no coinciden.
Las entidades principales y secundarias son una función de vista previa y solo se admiten en tablas con una capa de anidación.
Exportar métricas de evaluación
En la Google Cloud consola, ve a la página Procesadores y elige el procesador.
En la pestaña Evaluar y probar, haz clic en Descargar métricas para descargar las métricas de evaluación como un archivo JSON.