La formación y la extracción de IA generativa te permiten hacer lo siguiente:
- Usa la tecnología zero-shot y few-shot para obtener un modelo de alto rendimiento con pocos o ningún dato de entrenamiento mediante el modelo fundacional.
- Usa el ajuste fino para aumentar aún más la precisión a medida que proporciones más datos de entrenamiento.
Métodos de entrenamiento de IA generativa
El método de entrenamiento que elijas dependerá de la cantidad de documentos que tengas disponibles y del esfuerzo que puedas dedicar a entrenar tu modelo. Hay tres formas de entrenar un modelo de IA generativa:
| Método de entrenamiento | Sin ejemplos | Aprendizaje con pocos ejemplos | Afinamiento |
|---|---|---|---|
| Precisión | Medio | Media-alta | Alta |
| Esfuerzo | Bajo | Bajo | Medio |
| Número recomendado de documentos de entrenamiento | 0 | Entre 5 y 10 | De 10 a 50 o más |
Versiones de modelos de extractores personalizados
Los siguientes modelos están disponibles para el extractor personalizado. Para cambiar las versiones del modelo, consulta Gestionar versiones de procesadores.
Las versiones 1.3, 1.4, 1.5 y 1.5 Pro admiten puntuaciones de confianza, mientras que la versión 1.2 no.
| Versión del modelo | Descripción | Canal de lanzamiento | Procesamiento de aprendizaje automático en EE. UU. y la UE | Afinamiento en EE. UU. y la UE | Fecha de lanzamiento |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Modelo GA que usa el LLM Gemini 2.0 Flash. También incluye funciones avanzadas de OCR, como la detección de casillas de verificación. | Estable | Sí | EE. UU. y UE | 5 de febrero del 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Candidato listo para producción basado en el LLM Gemini 2.5 Flash. Recomendado para quienes quieran experimentar con modelos más recientes. | Estable | Sí | EE. UU. y UE (vista previa) | 5 de mayo del 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Modelo listo para producción que usa el LLM Gemini 2.5 Pro. Admite una cuota de hasta 30 páginas por minuto para las solicitudes de proceso online. Este modelo tiene una calidad mejorada en comparación con la versión 1.5 y puede tener una latencia mayor. | Estable | Sí | No | 20 de junio del 2025 |
Para cambiar la versión del procesador de tu proyecto, consulta Gestionar versiones de procesadores.
Para enviar una solicitud de aumento de cuota (QIR) para la cuota predeterminada del procesador, sigue los pasos que se indican en Gestionar tu cuota.
Configuración inicial
Si aún no lo has hecho, habilita la facturación y las APIs de Document AI.
Crear y evaluar un modelo de IA generativa
Crea un procesador y define los campos que quieras extraer siguiendo las prácticas recomendadas, ya que esto influye en la calidad de la extracción.
- Ve a Espacio de trabajo > Extractor personalizado > Crear procesador > Asignar un nombre.
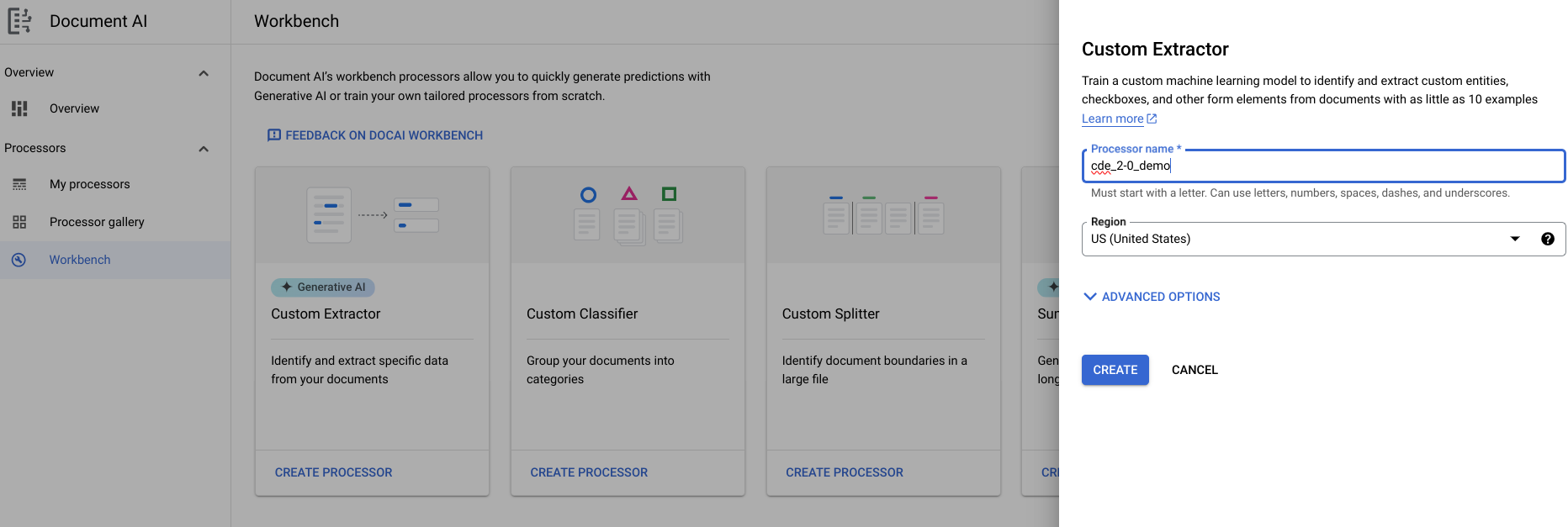
- Ve a Empezar > Crear campo.
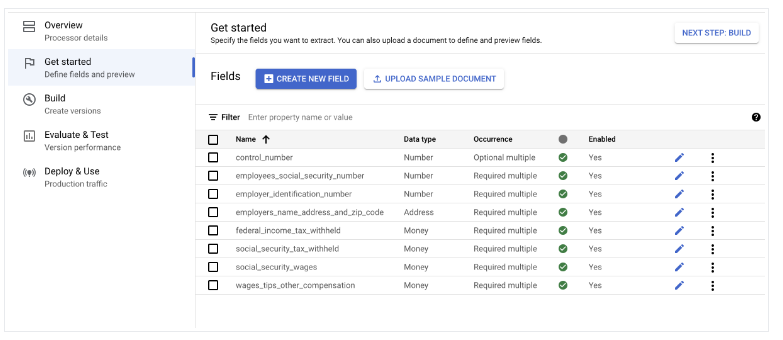
Importar documentos
- Importa documentos con etiquetado automático y asigna documentos a los conjuntos de entrenamiento y de prueba.
- En el caso de la clasificación sin ejemplos, solo se necesita el esquema. Para evaluar la precisión del modelo, solo se necesita un conjunto de prueba.
- En el caso de few-shot, recomendamos cinco documentos de entrenamiento.
- El número de documentos de prueba necesarios depende del caso práctico. Por lo general, cuantos más documentos de prueba haya, mejor.
- Confirma o edita las etiquetas del documento.
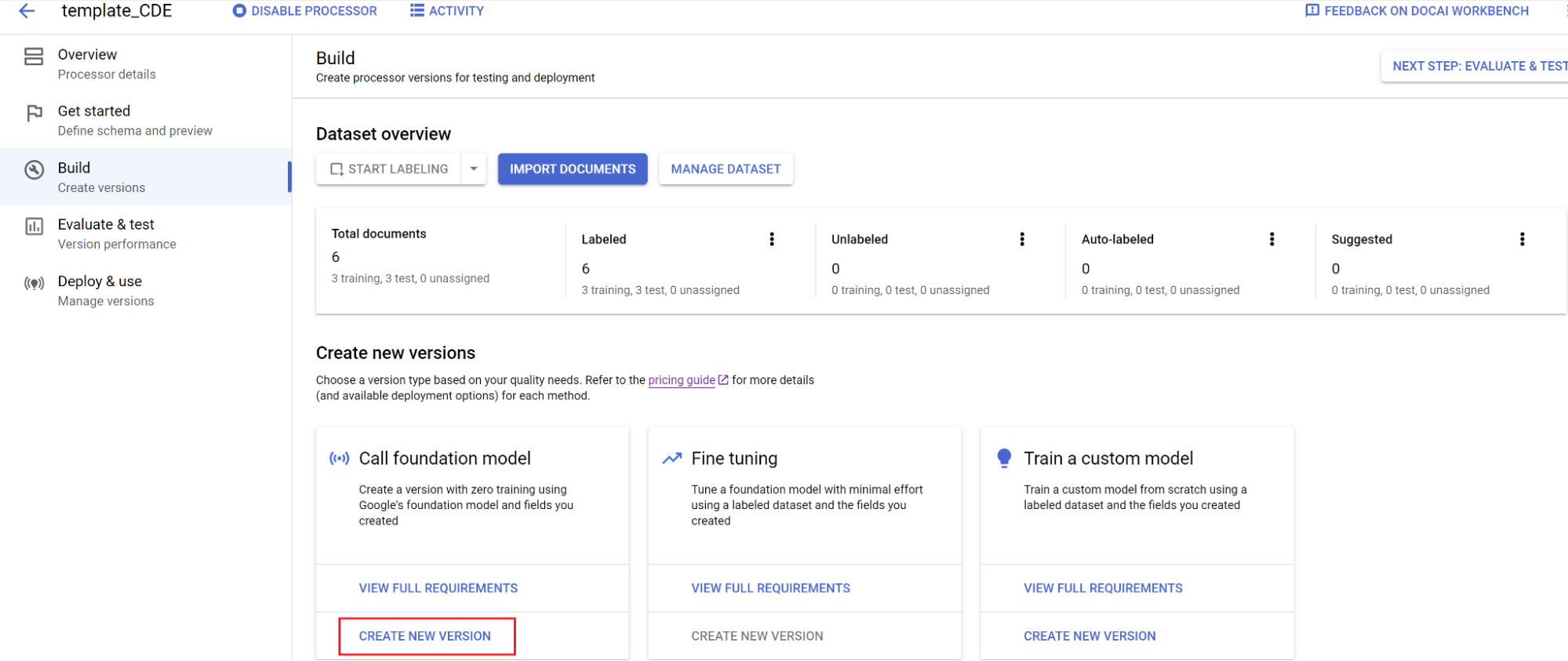
Entrenar modelo:
- Selecciona Compilación y, a continuación, Crear nueva versión.
- Escribe un nombre y selecciona Crear.
Evaluación:
- Ve a Evaluar y probar, selecciona la versión que acabas de entrenar y, a continuación, Ver evaluación completa.
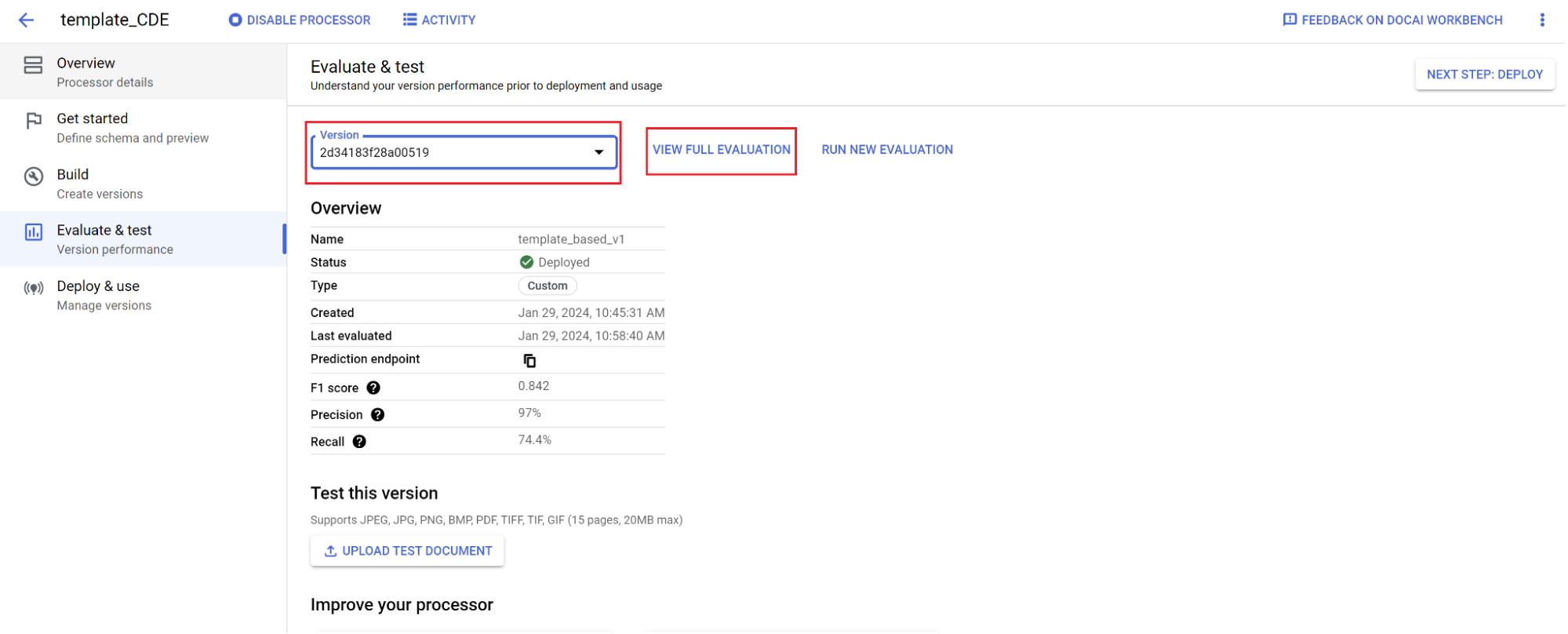
- Ahora puede ver métricas como f1, precisión y recuperación de todo el documento y de cada campo.
- Decide si el rendimiento cumple tus objetivos de producción. Si no es así, vuelve a evaluar los conjuntos de entrenamiento y de prueba.
Para definir una nueva versión como predeterminada, sigue estos pasos:
- Vaya a Gestionar versiones.
- Selecciona para desplegar las opciones y, a continuación, selecciona Establecer como predeterminado.
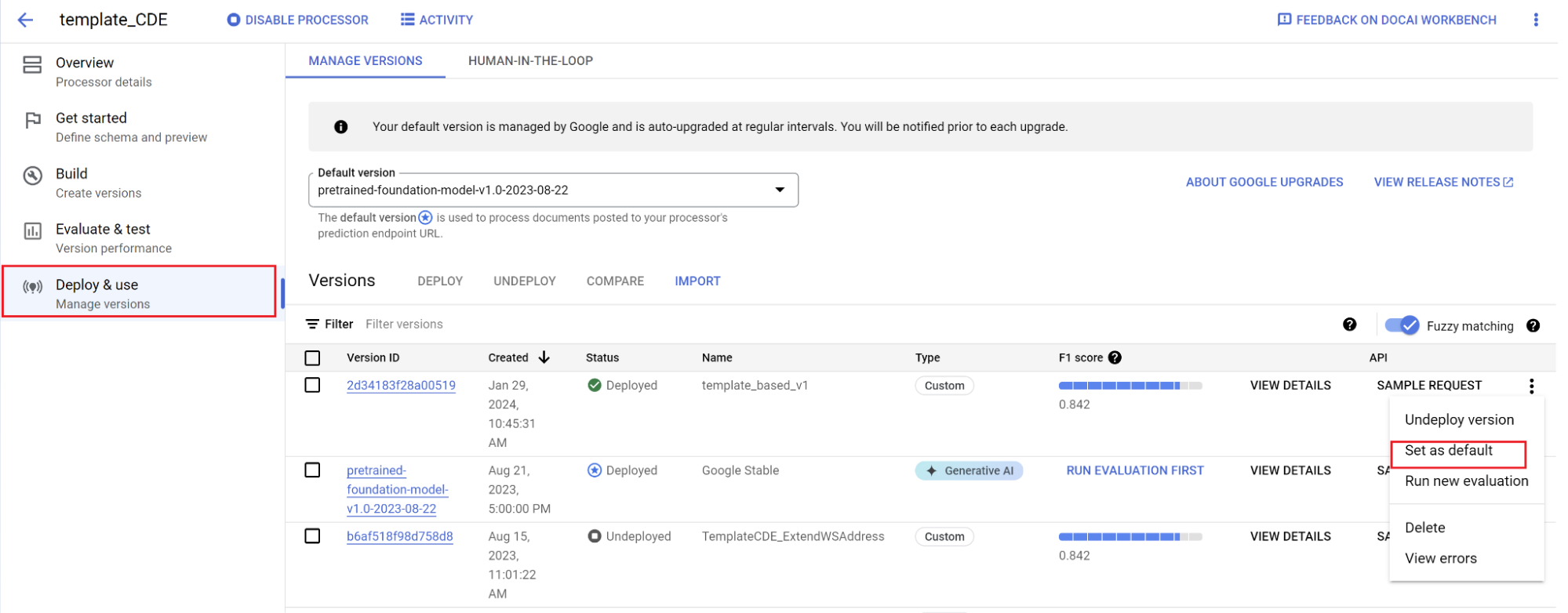
Tu modelo ya está desplegado. Los documentos enviados a este procesador usan tu versión personalizada. Puedes evaluar el rendimiento del modelo para comprobar si necesita más entrenamiento.
Referencia de evaluación
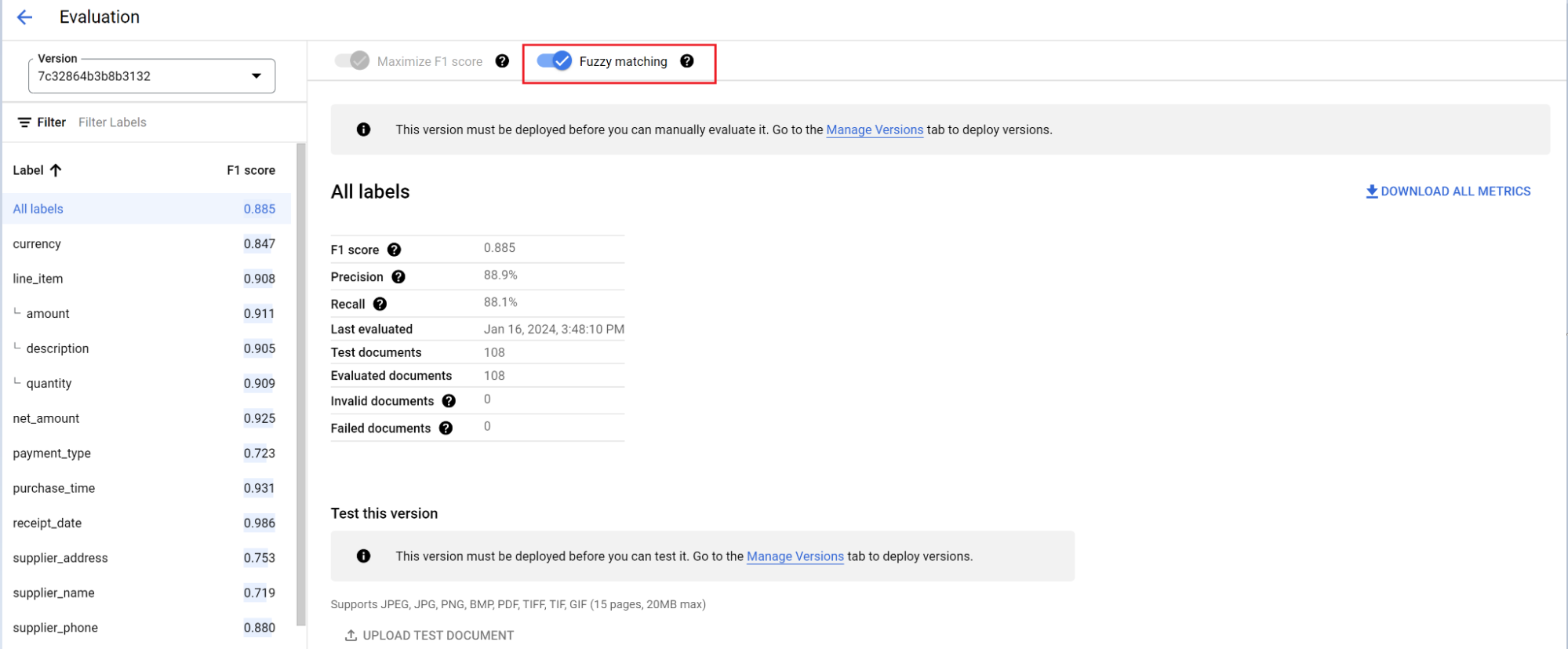
El motor de evaluación puede realizar tanto la concordancia exacta como la concordancia aproximada. Para que haya una coincidencia exacta, el valor extraído debe coincidir exactamente con el valor de referencia o se contabiliza como un error.
Las extracciones de coincidencias aproximadas que tenían pequeñas diferencias, como diferencias en el uso de mayúsculas y minúsculas, siguen contando como coincidencias. Puedes cambiarlo en la pantalla Evaluación.
Afinamiento
Con el ajuste fino, se usan cientos o miles de documentos para el entrenamiento.
Crea un procesador y define los campos que quieras extraer siguiendo las prácticas recomendadas, ya que esto influye en la calidad de la extracción.
Importa documentos con etiquetado automático y asigna documentos a los conjuntos de entrenamiento y de prueba.
Confirma o edita las etiquetas del documento.
Entrena el modelo.
- Selecciona la pestaña Compilación y, en el cuadro Ajuste fino, selecciona Crear nueva versión.
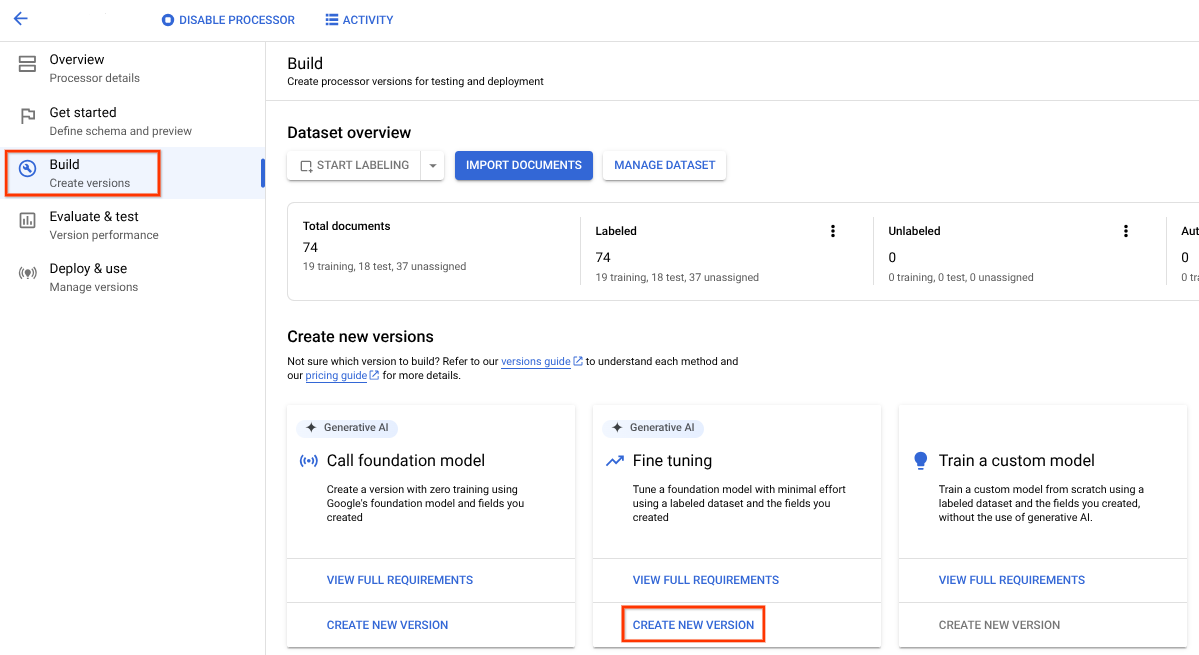
Prueba los parámetros de entrenamiento predeterminados o los valores proporcionados. Si los resultados no son satisfactorios, prueba estas opciones avanzadas:
Pasos de entrenamiento (entre 100 y 400): controla la frecuencia con la que se optimizan los pesos en un lote de datos durante la optimización.
- Si es demasiado bajo, indica que el entrenamiento puede terminar antes de la convergencia (ajuste insuficiente).
- Si es demasiado alto, el modelo puede ver el mismo lote de datos varias veces durante el entrenamiento, lo que puede provocar un sobreajuste.
- Cuantos menos pasos haya, más rápido será el entrenamiento. Un número más alto puede ser útil en documentos con poca variación en la plantilla (y un número más bajo en aquellos con más variación).
Multiplicador de la tasa de aprendizaje (entre 0,1 y 10): controla la rapidez con la que se optimizan los parámetros del modelo en los datos de entrenamiento. Se corresponde aproximadamente con el tamaño de cada paso del entrenamiento.
- Las tasas bajas implican pequeños cambios en los pesos del modelo en cada paso de entrenamiento. Si es demasiado bajo, es posible que el modelo no converja en una solución estable.
- Las tasas altas indican grandes cambios, y si son demasiado altas, el modelo puede saltarse la solución óptima y converger en una solución subóptima.
- El tiempo de entrenamiento no se ve afectado por la elección de la tasa de aprendizaje.
Asigna un nombre, selecciona la versión del procesador base que necesites y haz clic en Crear.
Evaluación: ve a Evaluar y probar, selecciona la versión que acabas de entrenar y, a continuación, Ver evaluación completa.
- Ahora puede ver métricas como f1, precisión y recuperación de todo el documento y de cada campo.
- Decide si el rendimiento cumple tus objetivos de producción. Si no es así, es posible que necesites más documentos de formación.
Para definir una nueva versión como predeterminada, sigue estos pasos:
- Vaya a Gestionar versiones.
- Selecciona para ver las opciones y, a continuación, Establecer como predeterminado.
Tu modelo ya está desplegado y los documentos que se envíen a este procesador usarán tu versión personalizada. Quieres evaluar el rendimiento del modelo para comprobar si necesita más entrenamiento.
Etiquetado automático con el modelo fundacional
El modelo base puede extraer campos de forma precisa para varios tipos de documentos, pero también puedes proporcionar datos de entrenamiento adicionales para mejorar la precisión del modelo en estructuras de documentos específicas.
Document AI usa los nombres de las etiquetas que definas y las anotaciones anteriores para que sea más rápido y fácil etiquetar documentos a gran escala con el etiquetado automático.
- Cuando hayas creado un procesador personalizado, ve a la pestaña Empezar.
- Selecciona Crear campo.
Asigna a la etiqueta un nombre descriptivo y distinto. Elige Extraer para obtener los valores directamente del documento o Derivar para obtener los valores inferidos por el sistema. De esta forma, se mejora la precisión y el rendimiento del modelo base.
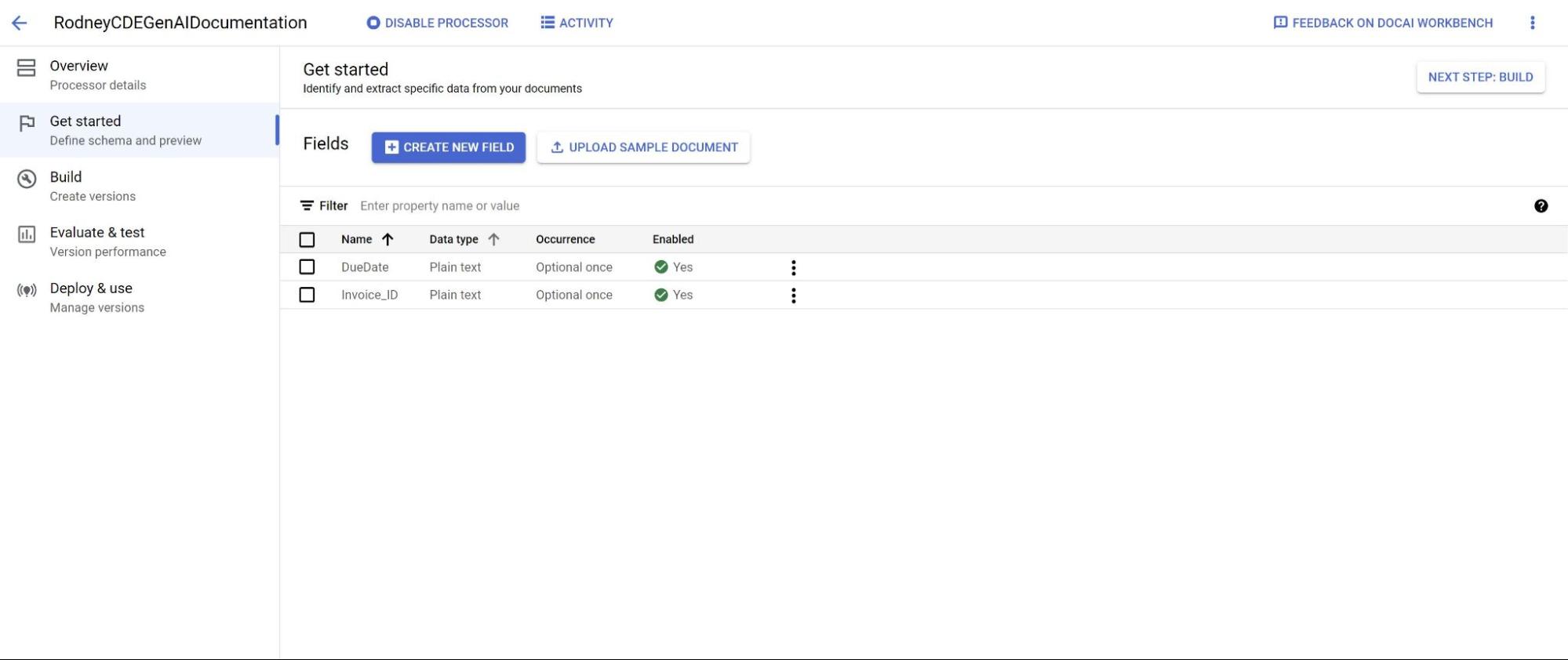
Para mejorar la precisión y el rendimiento de la extracción, añade una descripción (como contexto, estadísticas y conocimientos previos de cada entidad) de los tipos de entidades que debería detectar.
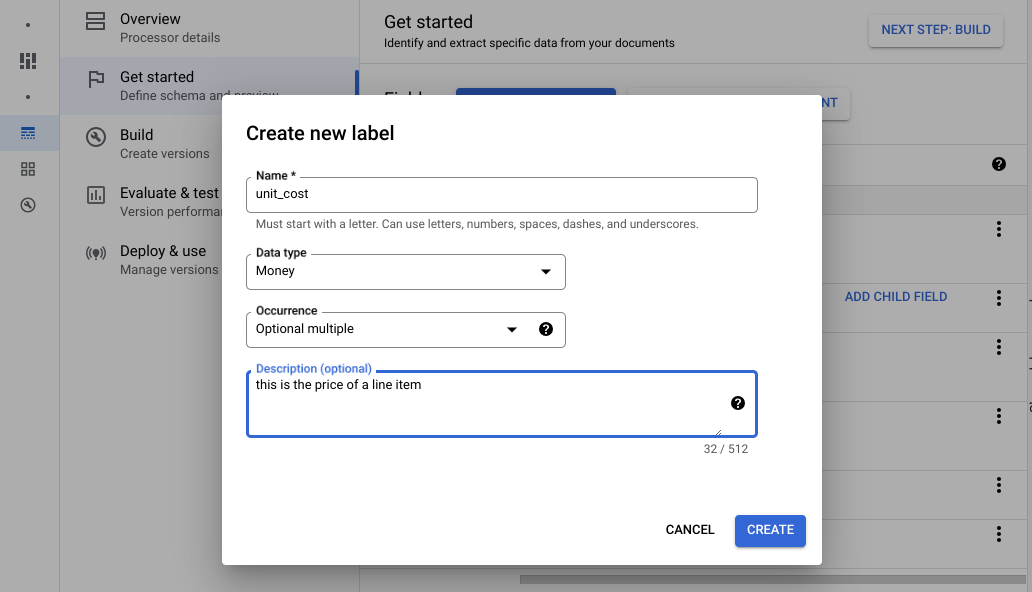
Ve a la pestaña Compilación y selecciona Importar documentos.
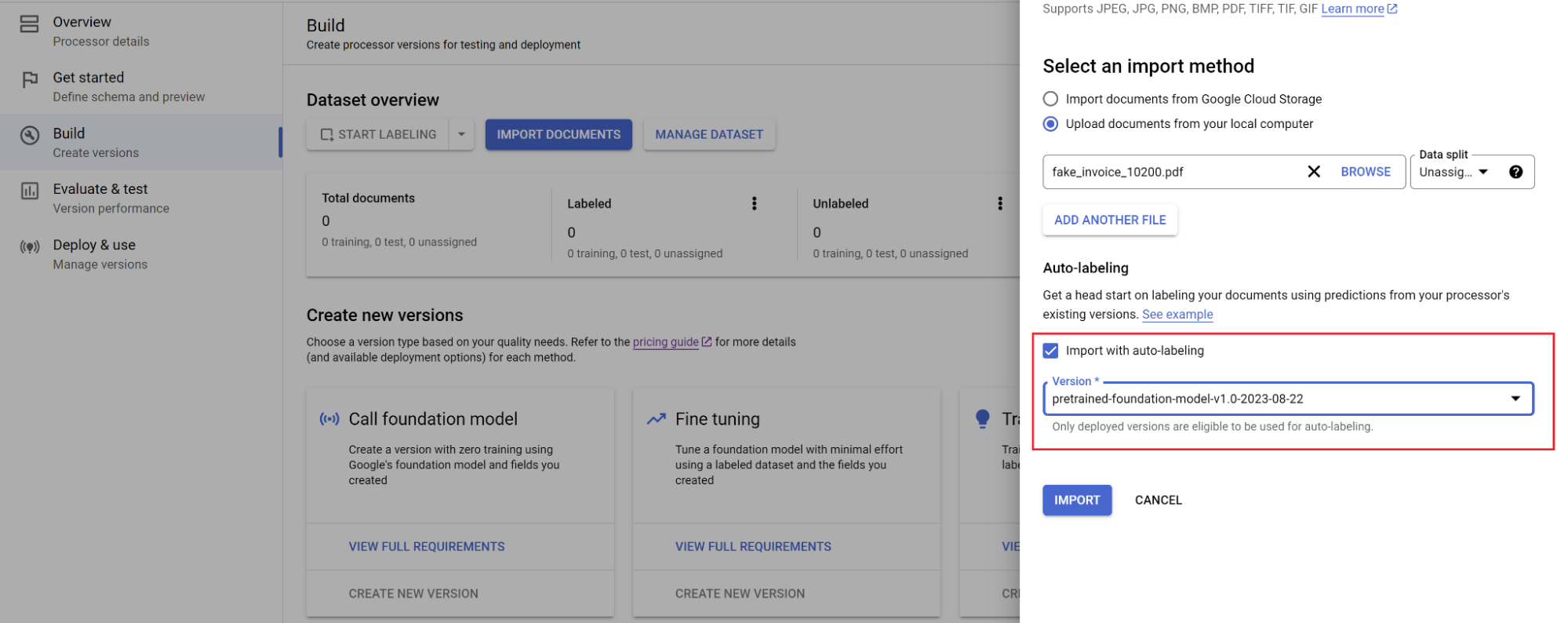
Selecciona la ruta de los documentos y el conjunto en el que se deben importar. Marca la opción de etiquetado automático y selecciona el modelo base.
En la pestaña Crear, selecciona Gestionar conjunto de datos.
Cuando veas los documentos importados, selecciona uno.
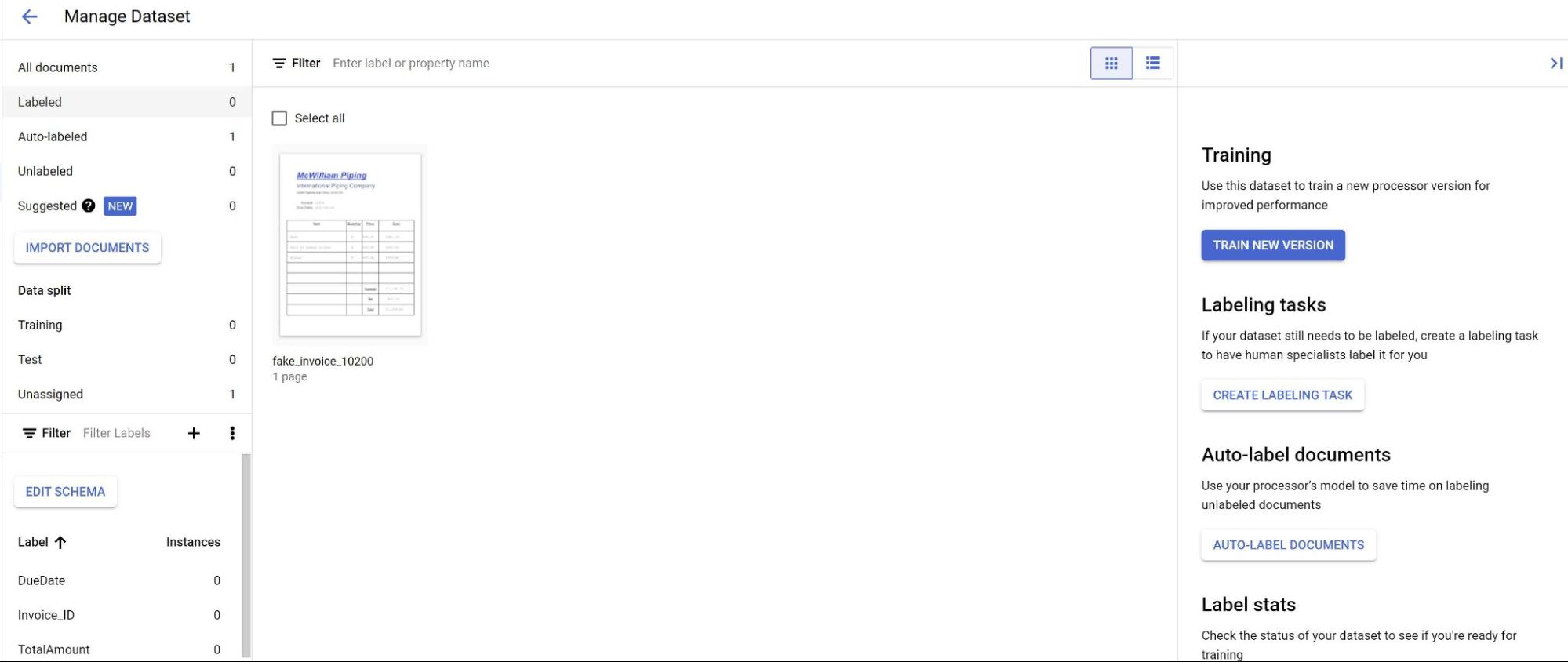
Las predicciones del modelo ahora se muestran resaltadas en morado.
- Revisa cada etiqueta predicha por el modelo y comprueba que sea correcta.
Si faltan campos, añádelos también.
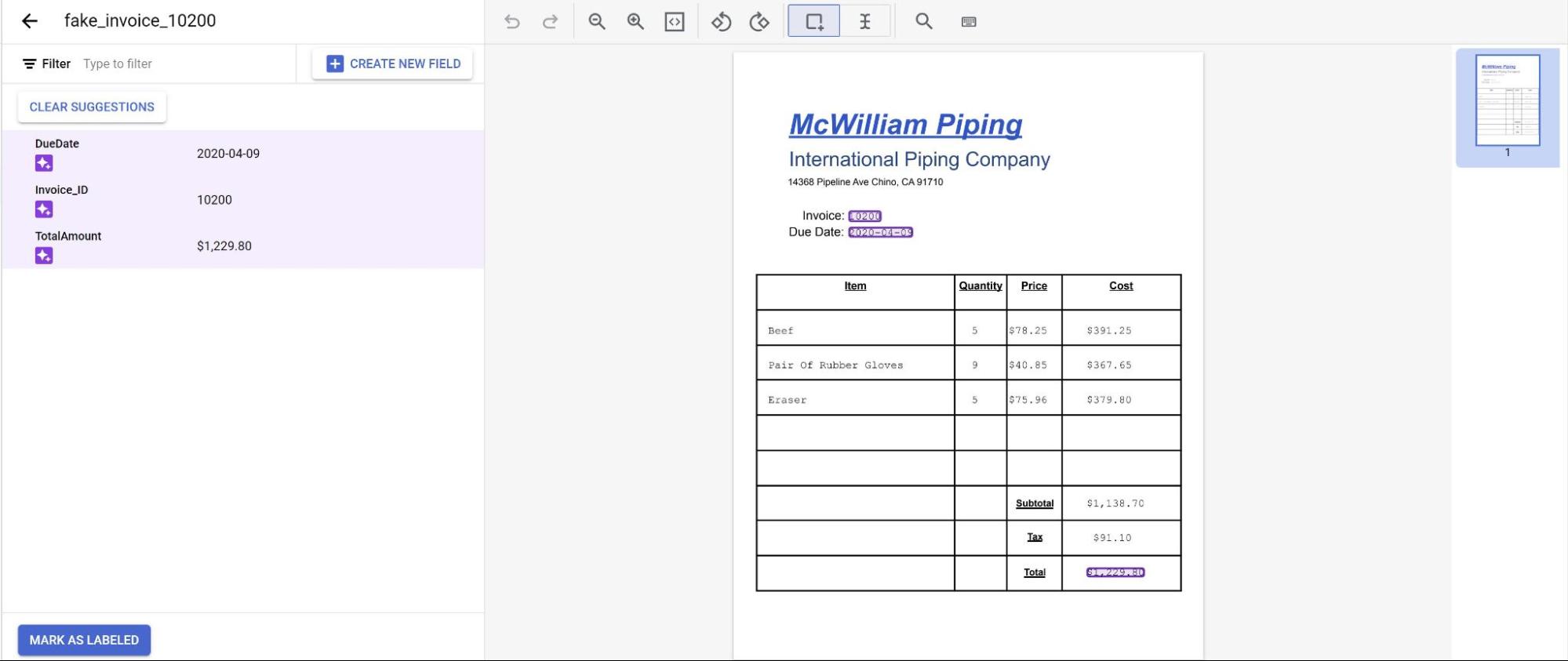
Cuando se haya revisado el documento, selecciona Marcar como etiquetado. El documento ya está listo para que lo use el modelo.
Asegúrate de que el documento esté en el conjunto de prueba o de entrenamiento.
Anidación de tres niveles
Ahora, Extractor personalizado ofrece tres niveles de anidación. Esta función ofrece una mejor extracción de tablas complejas.
Puede determinar el tipo de modelo mediante las siguientes llamadas a la API:
La respuesta es un ProcessorVersion, que contiene el campo modelType en la vista previa de la versión 1 beta 3.
Procedimiento y ejemplo
Usamos este ejemplo:
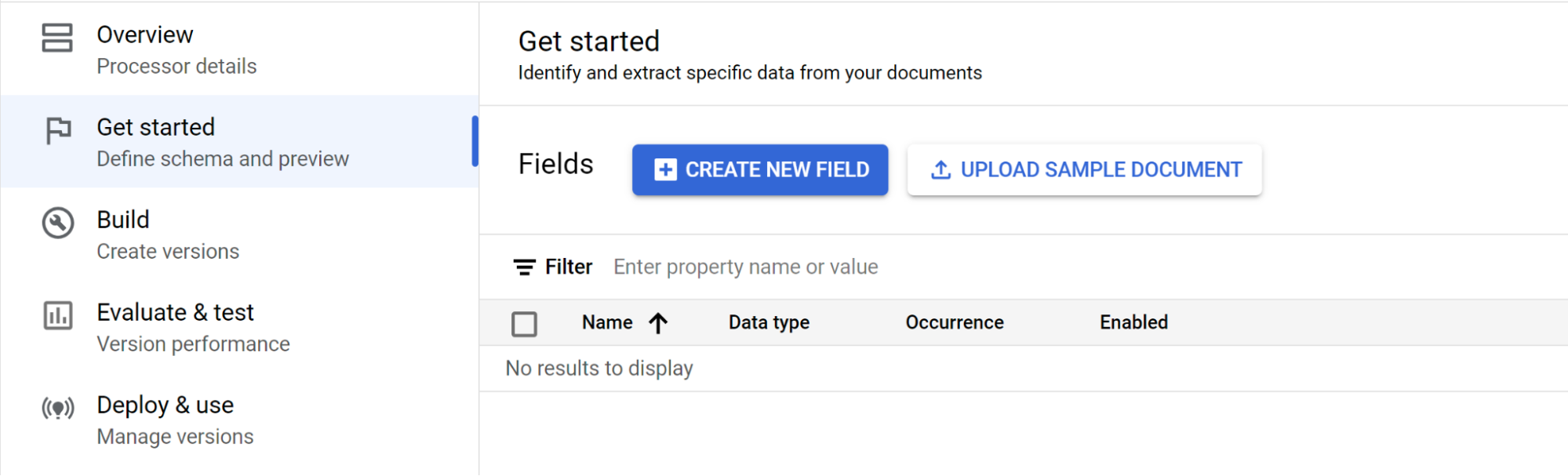
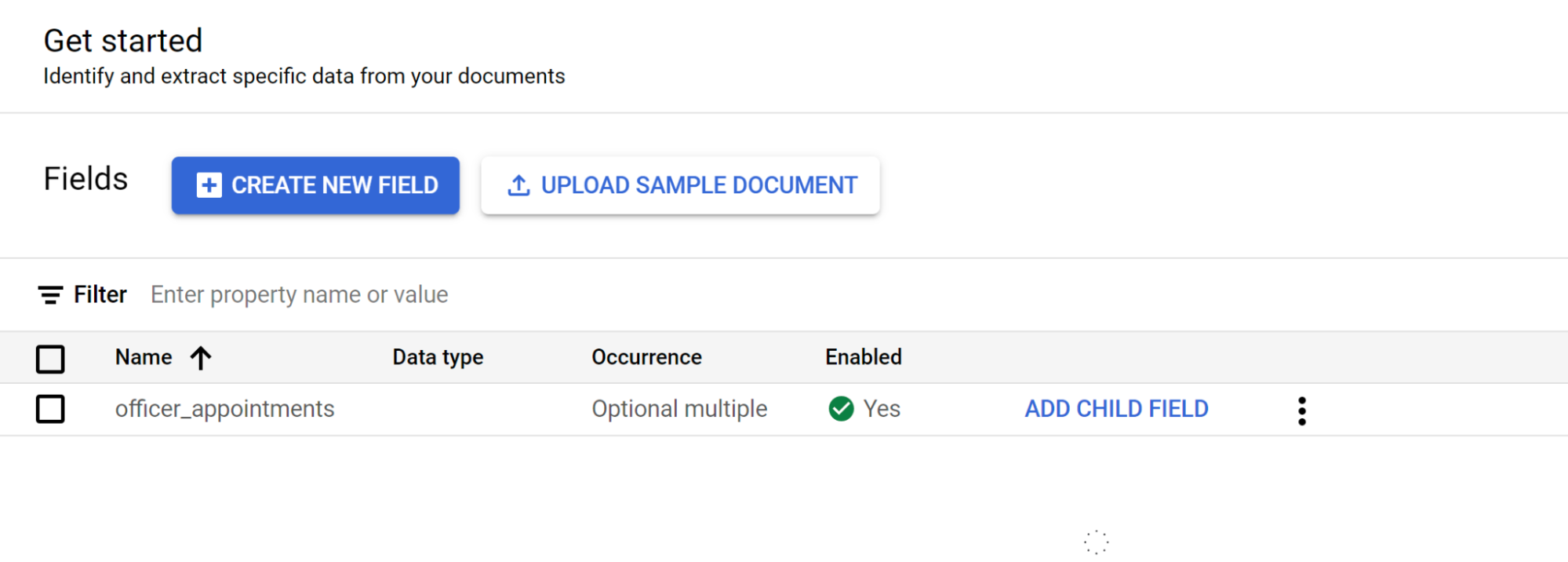
Selecciona Empezar y, a continuación, crea un campo:
- Crea el nivel superior.
- En este ejemplo, se usa
officer_appointments. - Selecciona Esta es una etiqueta principal.
- Selecciona Ocurrencia:
Optional multiple.
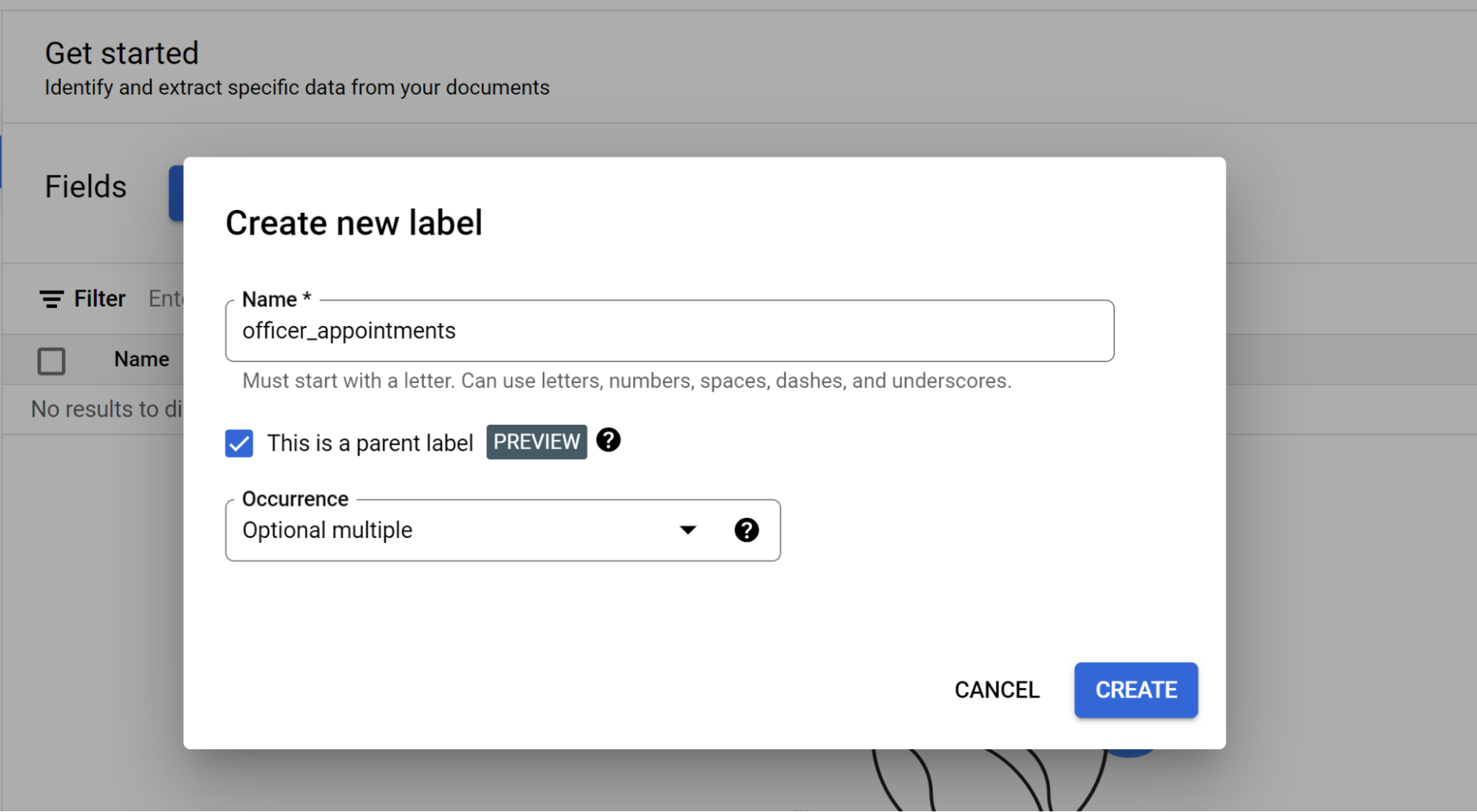
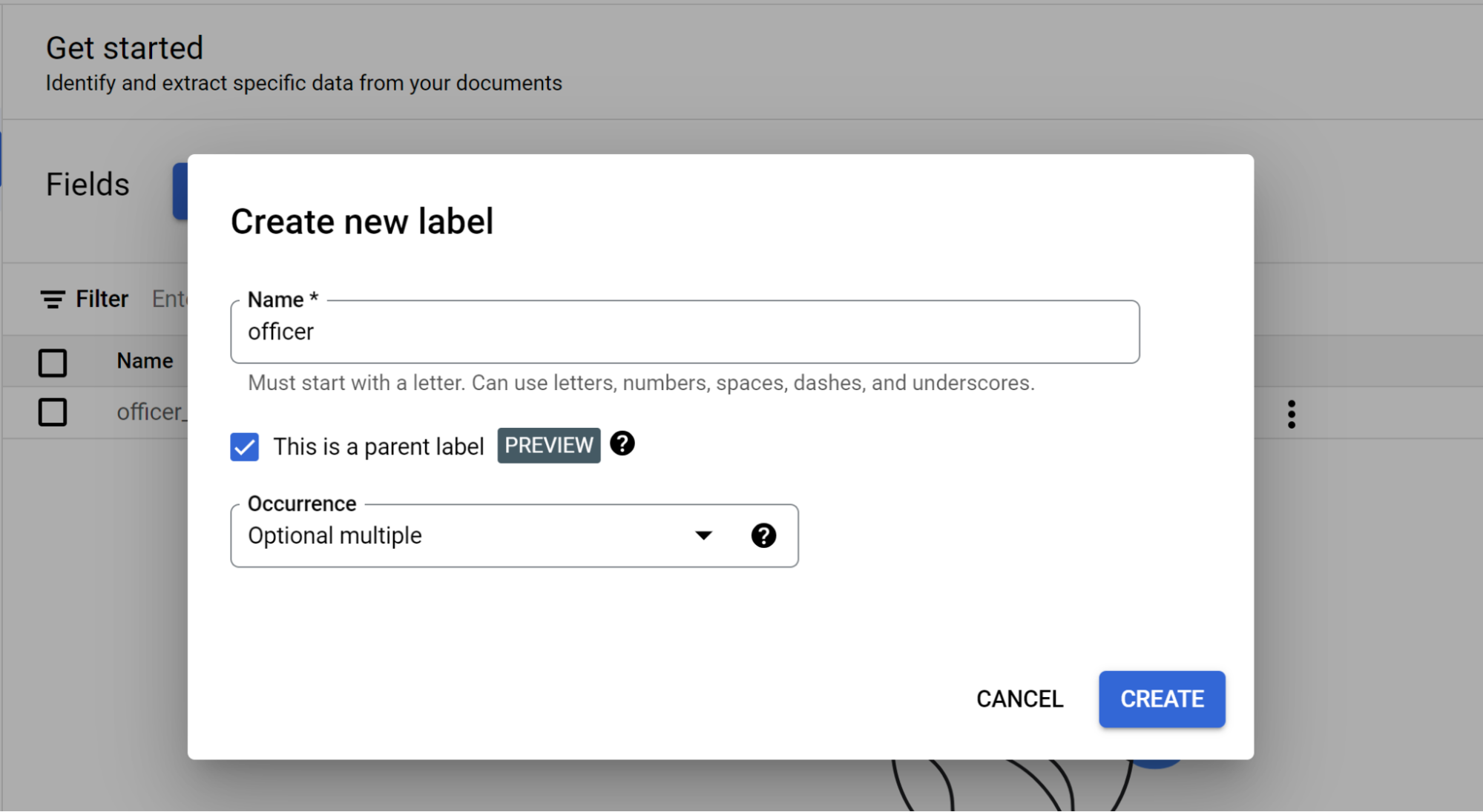
Selecciona Añadir campo secundario. Ahora se puede crear la etiqueta de segundo nivel:
- Crea la etiqueta
officerpara este nivel. - Selecciona Esta es una etiqueta principal.
- Selecciona Ocurrencia:
Optional multiple.
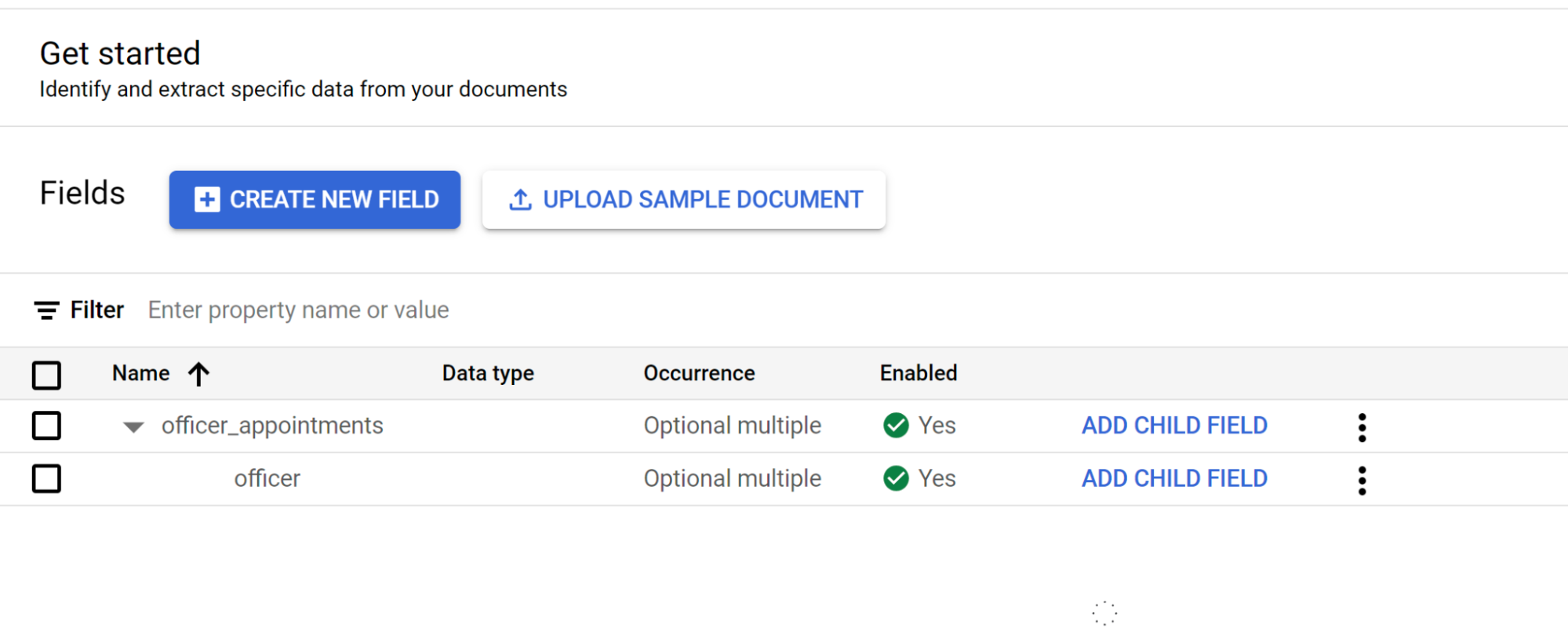
- Crea la etiqueta
Selecciona Añadir campo secundario en el segundo nivel
officer. Crea etiquetas secundarias para el tercer nivel de anidación.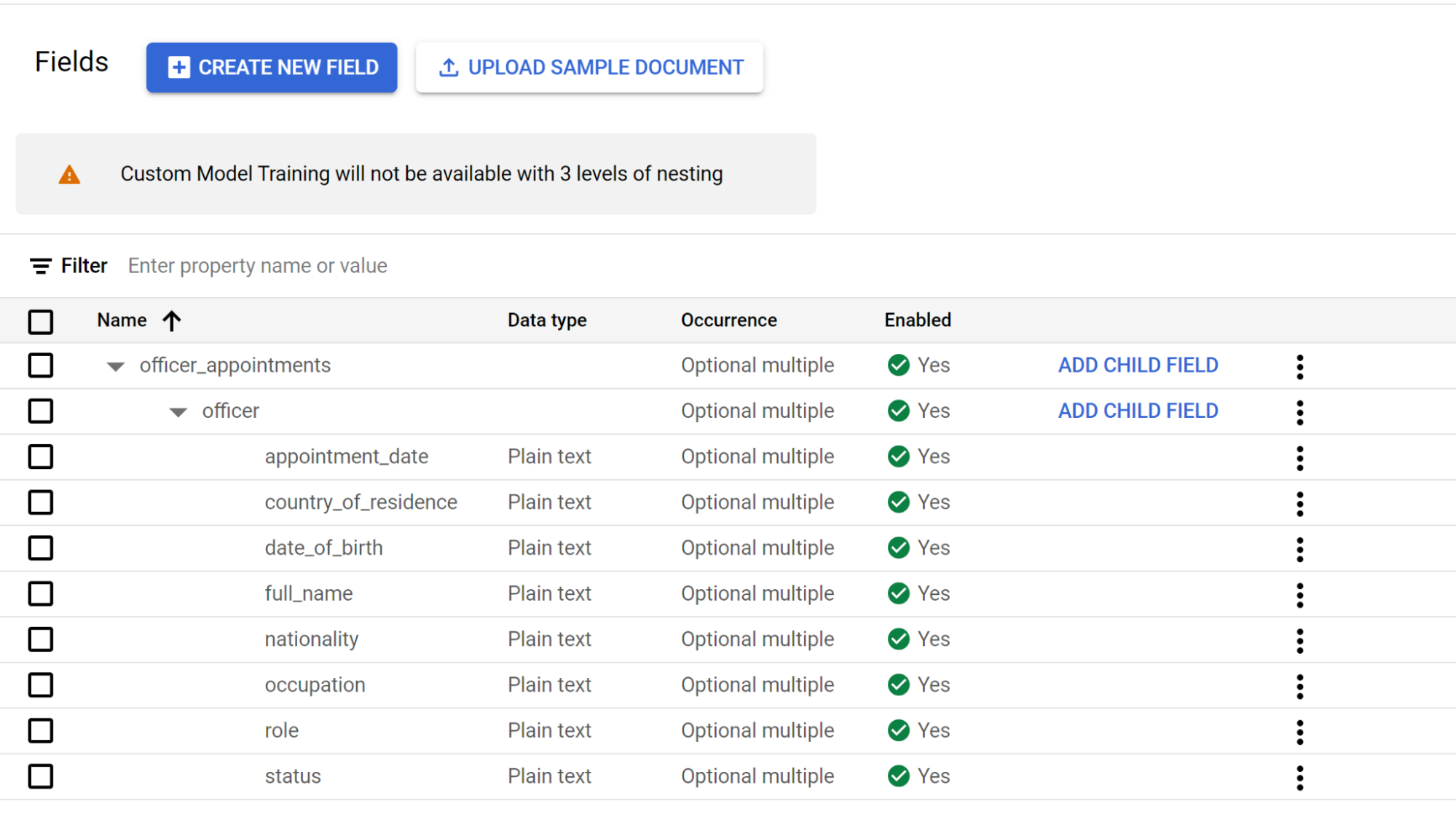
Cuando hayas definido el esquema, podrás obtener predicciones de documentos con tres niveles de anidación mediante el etiquetado automático.
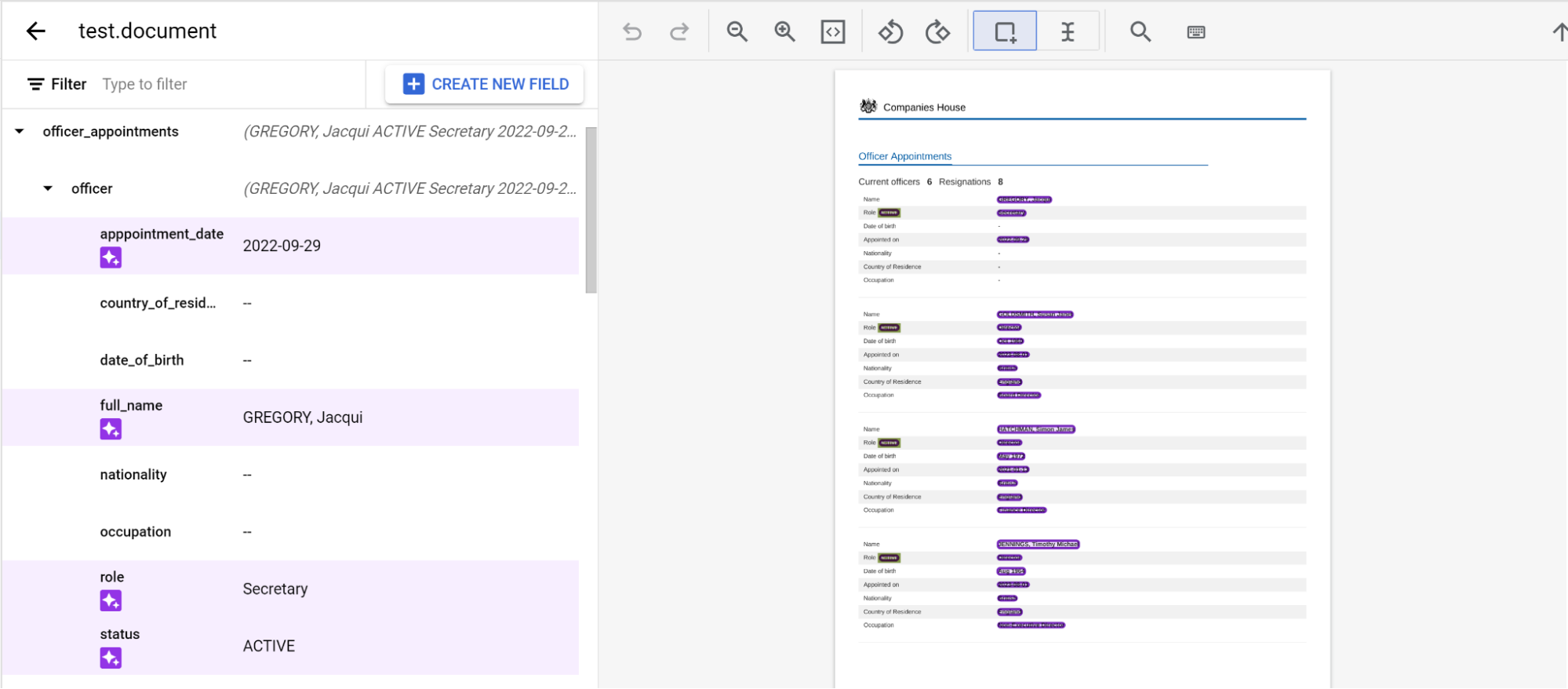
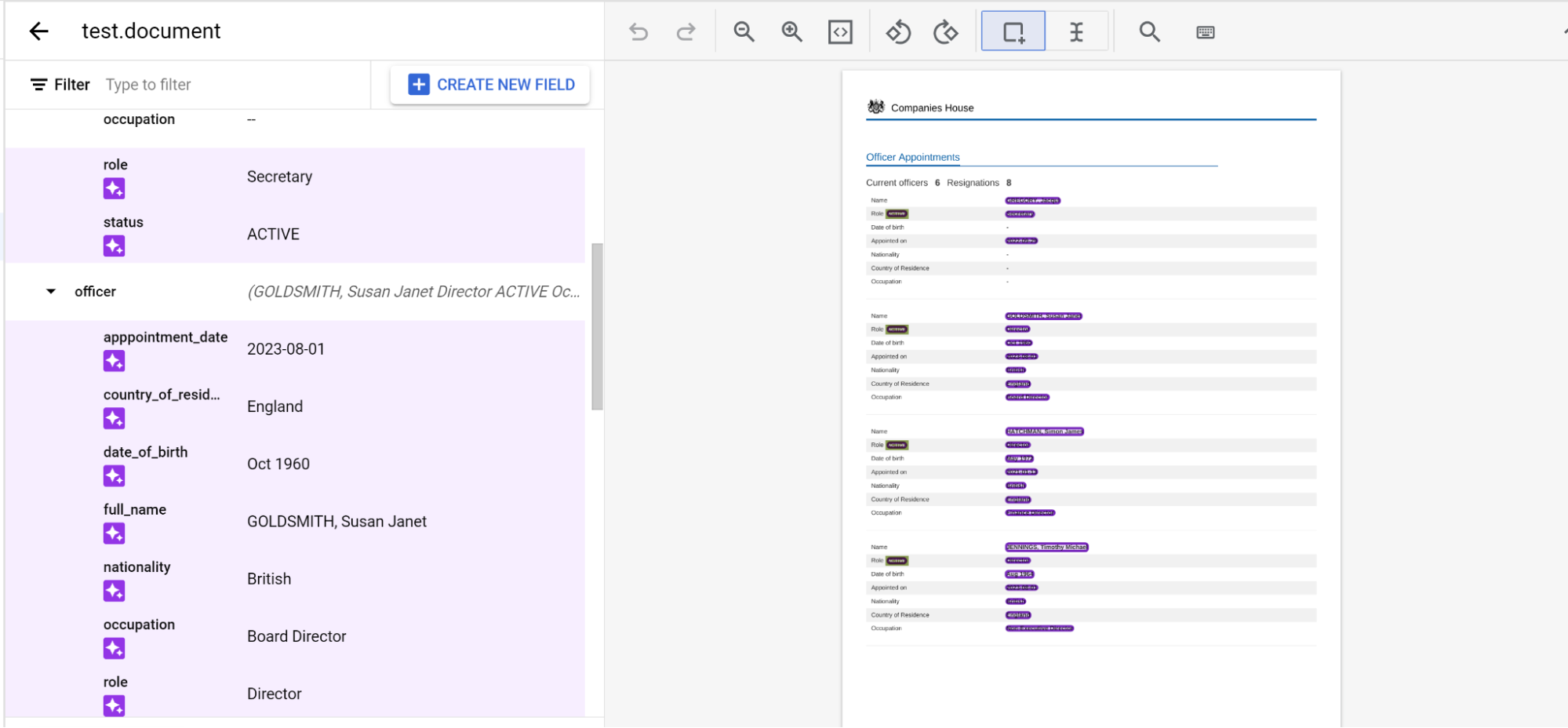
Etiquetar entidades anidadas en varias páginas
El procesador pretrained-foundation-model-v1.5-2025-05-05 admite la anidación de tres niveles en las páginas.
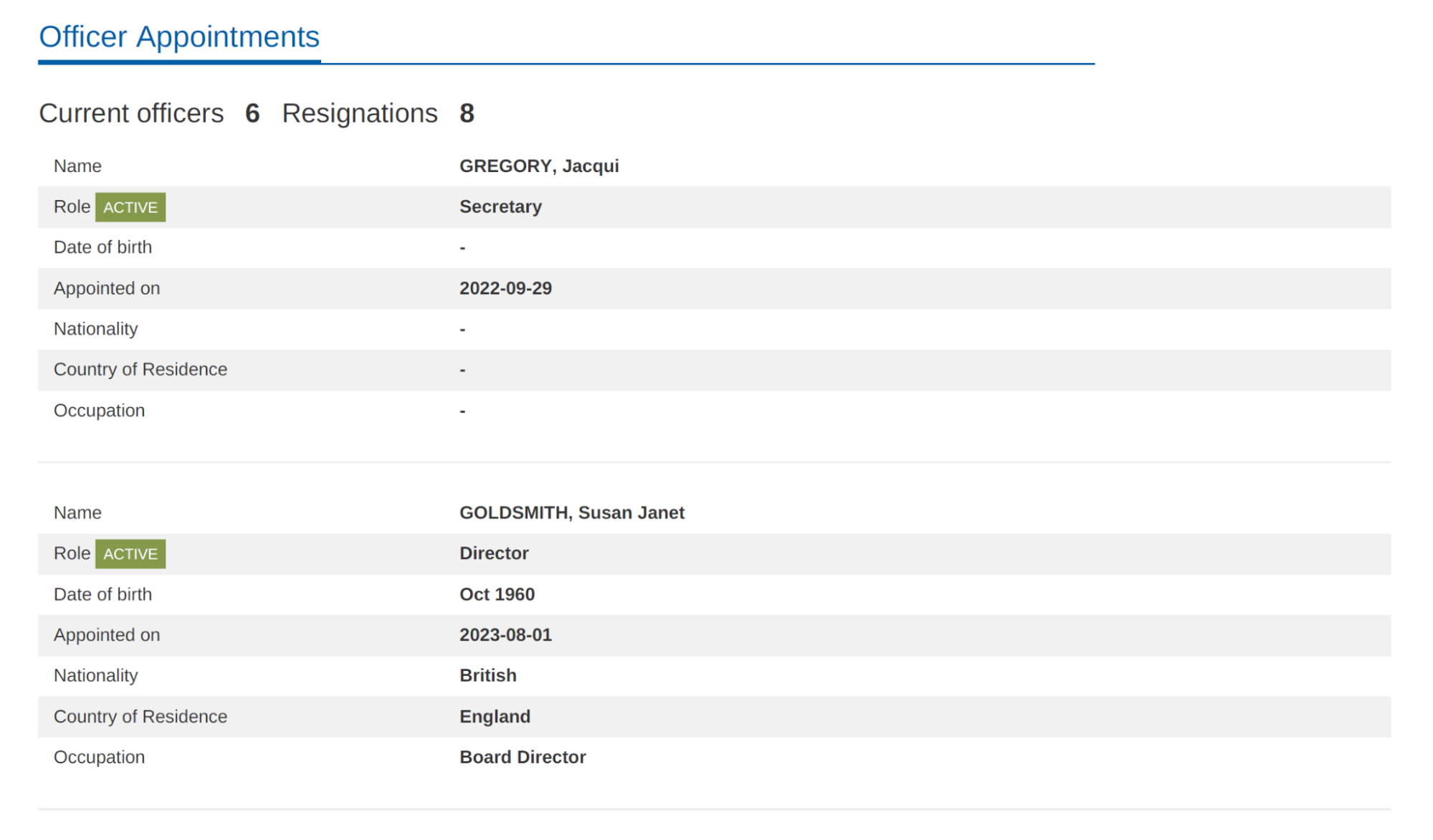
Etiqueta una entidad normalmente en una página. Nota: La entidad etiquetada solo se mostrará en la página en la que se haya etiquetado, y la barra de navegación cambiará de una página a otra. Si fijas la entidad superior, esta barra de navegación se mantendrá.
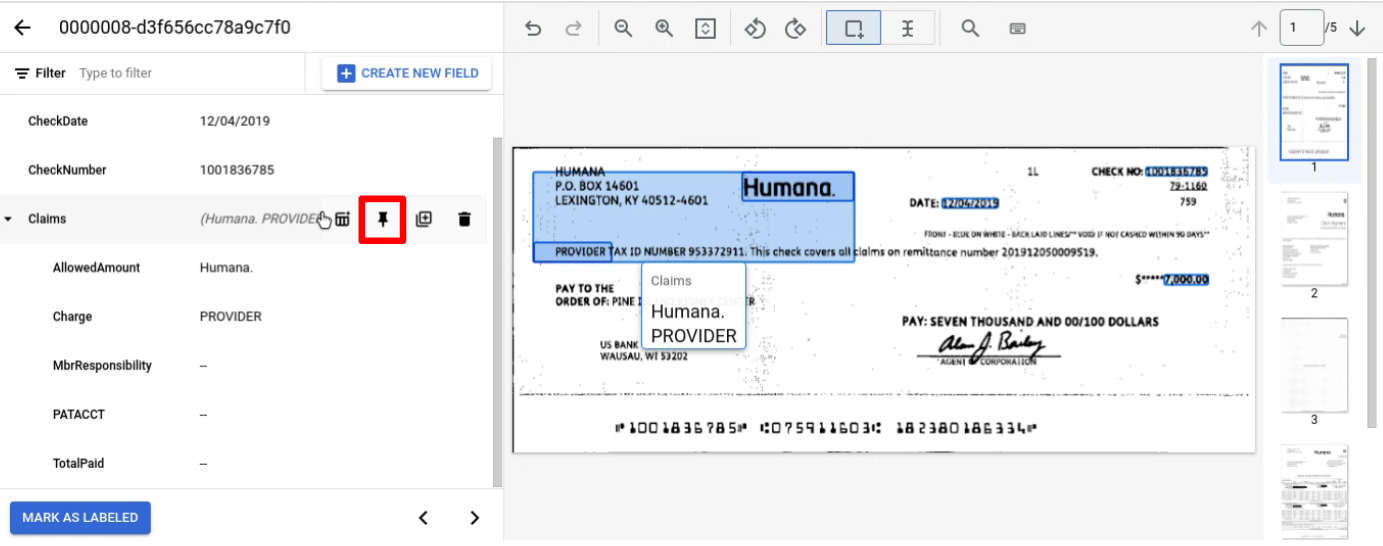
Fija la entidad superior con los elementos secundarios que quieras etiquetar en todas las páginas.
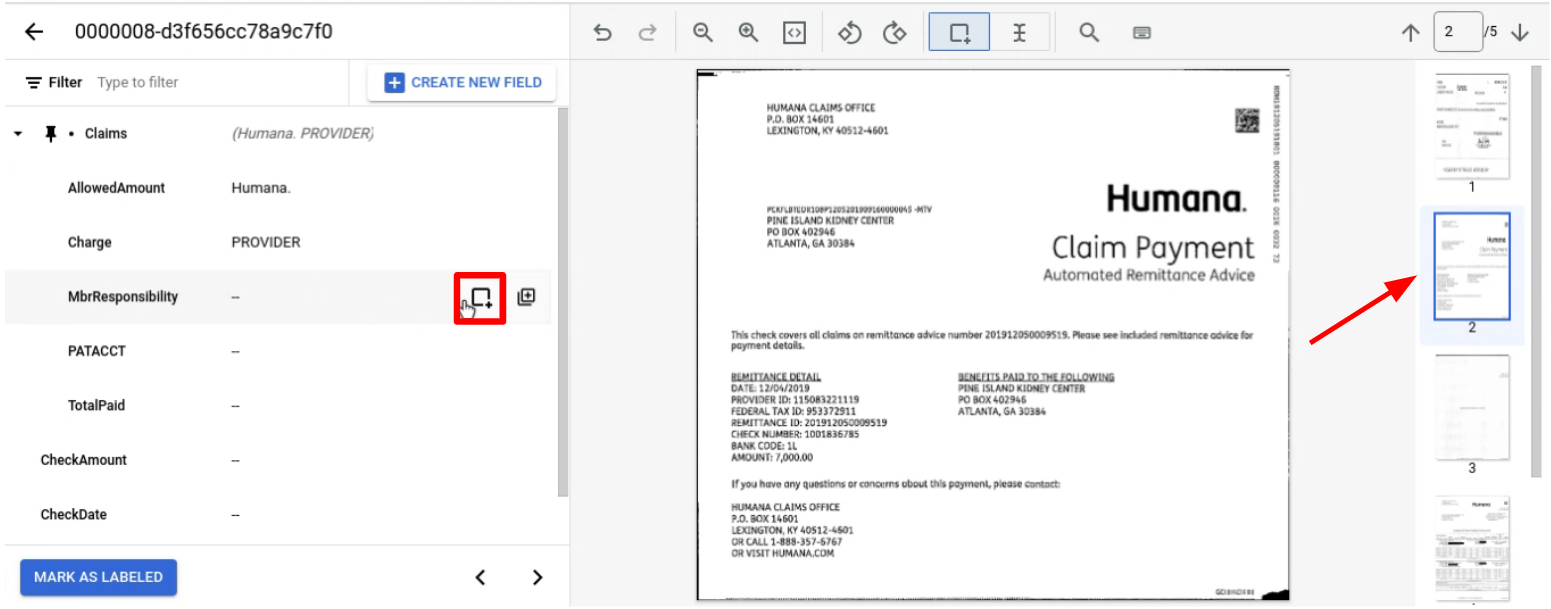
Vaya a la página que contenga la entidad o las entidades secundarias que quiera etiquetar.
Configuración del conjunto de datos
Se necesita un conjunto de datos de documentos para entrenar, volver a entrenar o evaluar una versión de un procesador. Los procesadores de Document AI aprenden de ejemplos, al igual que los humanos. El conjunto de datos alimenta la estabilidad del procesador en términos de rendimiento.Conjunto de datos de entrenamiento
Para mejorar el modelo y su precisión, entrena un conjunto de datos con tus documentos. El modelo se compone de documentos con información verificada.- Para el ajuste fino, necesitas un mínimo de 1 documento para entrenar un nuevo modelo con la versión
pretrained-foundation-model-v1.2-2024-05-10ypretrained-foundation-model-v1.3-2024-08-31. - Para el aprendizaje con pocos ejemplos, se recomiendan cinco documentos.
- En el caso de la clasificación sin ejemplos, solo se necesita un esquema.
Conjunto de datos de prueba
El conjunto de datos de prueba es el que usa el modelo para generar una puntuación F1 (precisión). Se compone de documentos con datos verificados. Para ver con qué frecuencia acierta el modelo, se usa la verdad fundamental para comparar las predicciones del modelo (campos extraídos del modelo) con las respuestas correctas. El conjunto de datos de prueba debe tener al menos un documento parapretrained-foundation-model-v1.2-2024-05-10 y pretrained-foundation-model-v1.3-2024-08-31.
Extractor personalizado con descripciones de propiedades
Con las descripciones de propiedades, puedes entrenar un modelo describiendo cómo son los campos etiquetados. Puedes proporcionar contexto e información adicionales sobre cada entidad. De esta forma, el modelo puede entrenarse emparejando los campos que se ajusten a la descripción que proporciones y mejorar la precisión de la extracción. Las descripciones de las propiedades se pueden especificar tanto para las entidades principales como para las secundarias.
Algunos buenos ejemplos de descripciones de propiedades son la información de ubicación y los patrones de texto de los valores de las propiedades, que ayudan a aclarar posibles fuentes de confusión en el documento. Las descripciones de propiedades claras y precisas guían al modelo con reglas que fomentan extracciones más fiables y coherentes, independientemente de la estructura específica del documento o de las variaciones del contenido.
Actualizar el esquema de documento de un procesador
Para saber cómo definir las descripciones de las propiedades, consulta el artículo Actualizar el esquema del documento.
Enviar una solicitud de procesamiento con descripciones de propiedades
Si el esquema del documento ya tiene descripciones definidas, puedes enviar una solicitud de proceso con las instrucciones que se indican en Enviar una solicitud de proceso.
Ajustar un procesador con descripciones de propiedades
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- LOCATION: la ubicación de tu procesador, por ejemplo:
us- Estados Unidoseu- Unión Europea
- PROJECT_ID: tu ID de proyecto Google Cloud .
- PROCESSOR_ID: el ID de tu procesador personalizado.
- DISPLAY_NAME: nombre visible del procesador.
- PRETRAINED_PROCESSOR_VERSION: identificador de la versión del procesador. Consulta Seleccionar una versión del procesador para obtener más información. Por ejemplo:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: pasos para entrenar el modelo.
- LEARN_RATE_MULTIPLIER: multiplicador de la tasa de aprendizaje para el ajuste fino del modelo.
- DOCUMENT_SCHEMA: Esquema del procesador. Consulta la representación de DocumentSchema.
Método HTTP y URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Cuerpo JSON de la solicitud:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Extractor personalizado con detección de firmas
(Vista previa pública) El extractor personalizado admite la detección de firmas. Esta función te permite detectar la presencia de firmas en los documentos. La detección de firmas solo está disponible mediante el tipo de método derived. Puedes especificar un esquema con el tipo de entidad signature
para estas entidades. Las entidades de firma se derivan mediante señales visuales del documento.
Para ver ejemplos e instrucciones de configuración, haga clic en Extractor personalizado con campo derivado y detección de firmas.
Extractor personalizado con campos derivados
El extractor personalizado admite campos derivados. Te permite configurar un campo para que se rellene mediante inferencia o generación inteligentes basadas en el contexto del documento, en lugar de extraer el texto directamente. Puedes usarla en casos prácticos como deducir el país a partir de una dirección, resumir un documento, contar los elementos de una tabla o detectar si un documento de identificación es auténtico, sin necesidad de que el valor esté presente de forma explícita en el texto.
Para ver ejemplos e instrucciones de configuración, haga clic en Extractor personalizado con campo derivado y detección de firmas.
Siguientes pasos
Consulta información sobre el extractor personalizado con campo derivado y detección de firmas.