Divisor personalizado
El separador personalizado se ha diseñado para dividir documentos compuestos (documentos formados por varias clases) en documentos de una sola clase identificando cada documento lógico. Por ejemplo, un paquete hipotecario contiene varias clases, como la solicitud, la verificación de ingresos y la identificación con foto. Los procesadores de divisores personalizados se entrenan desde cero con tus propios documentos y clases personalizadas para poder usarlos.
Descripción y uso de Splitter
Crea divisores personalizados que se adapten específicamente a tus documentos y que se entrenen y evalúen con tus datos. Este procesador identifica clases de documentos de un conjunto de clases definido por el usuario. Después, puede usar este procesador entrenado en documentos de producción. Normalmente, se usa un separador personalizado en archivos que se componen de diferentes tipos de documentos lógicos. Después, se usa la identificación de clase de cada uno para enviar los documentos a un procesador de extracción adecuado y extraer las entidades.
Como los modelos de aprendizaje automático no son perfectos y tienen un cierto margen de error, y como los errores en la división suelen ser muy problemáticos (una división incorrecta hace que dos documentos sean incorrectos y provoca errores de extracción), una práctica recomendada es incluir siempre un paso de revisión humana después de la predicción de la división, pero antes de la división real del archivo. En función de los requisitos de la empresa, hay alternativas a la revisión humana:
- Usa las puntuaciones de confianza de la predicción para decidir si se debe omitir la revisión humana (si son lo suficientemente altas). El umbral de puntuación de confianza debe determinarse en función del historial de datos sobre las tasas de error en las puntuaciones de confianza dadas. Esta decisión debe tomarse en función de la tolerancia de los procesos empresariales a los errores y del requisito de omitir la revisión humana.
- En algunos casos prácticos, los documentos divididos se pueden dirigir directamente al extractor adecuado según la clase prevista. Después, si la extracción está incompleta o tiene puntuaciones de confianza bajas, aísla los documentos divididos y activa el documento compuesto original y la decisión de división para que se revisen. Esto tiene requisitos de flujo de trabajo bastante complejos.
Crear un divisor personalizado en la consola Google Cloud
En esta guía de inicio rápido se describe cómo usar Document AI para crear y entrenar un divisor personalizado que divida y clasifique documentos de aprovisionamiento. La mayor parte de la preparación del documento ya está hecha, por lo que puedes centrarte en crear un divisor personalizado.
El flujo de trabajo habitual para crear y usar un divisor personalizado es el siguiente:
- Crea un divisor personalizado en Document AI.
- Crea un conjunto de datos con un segmento de Cloud Storage vacío.
- Defina y cree el esquema del procesador (clases).
- Importa documentos.
- Asigna documentos a los conjuntos de entrenamiento y de prueba.
- Anota documentos manualmente en Document AI o con tareas de etiquetado.
- Entrena al procesador.
- Evalúa el procesador.
- Implementa el procesador.
- Prueba el procesador.
- Usar el procesador en tus documentos.
Si tienes los documentos en carpetas separadas por clase, puedes saltarte el paso 6 especificando la clase al importar.
Para seguir las instrucciones paso a paso de esta tarea directamente en la Google Cloud consola, haga clic en Ayúdame:
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. En la Google Cloud consola, en la sección Document AI, ve a la página Workbench.
En Divisor de documentos personalizado, seleccione
Crear procesador .
En el menú Crear procesador, escribe el nombre del procesador, como
my-custom-document-splitter.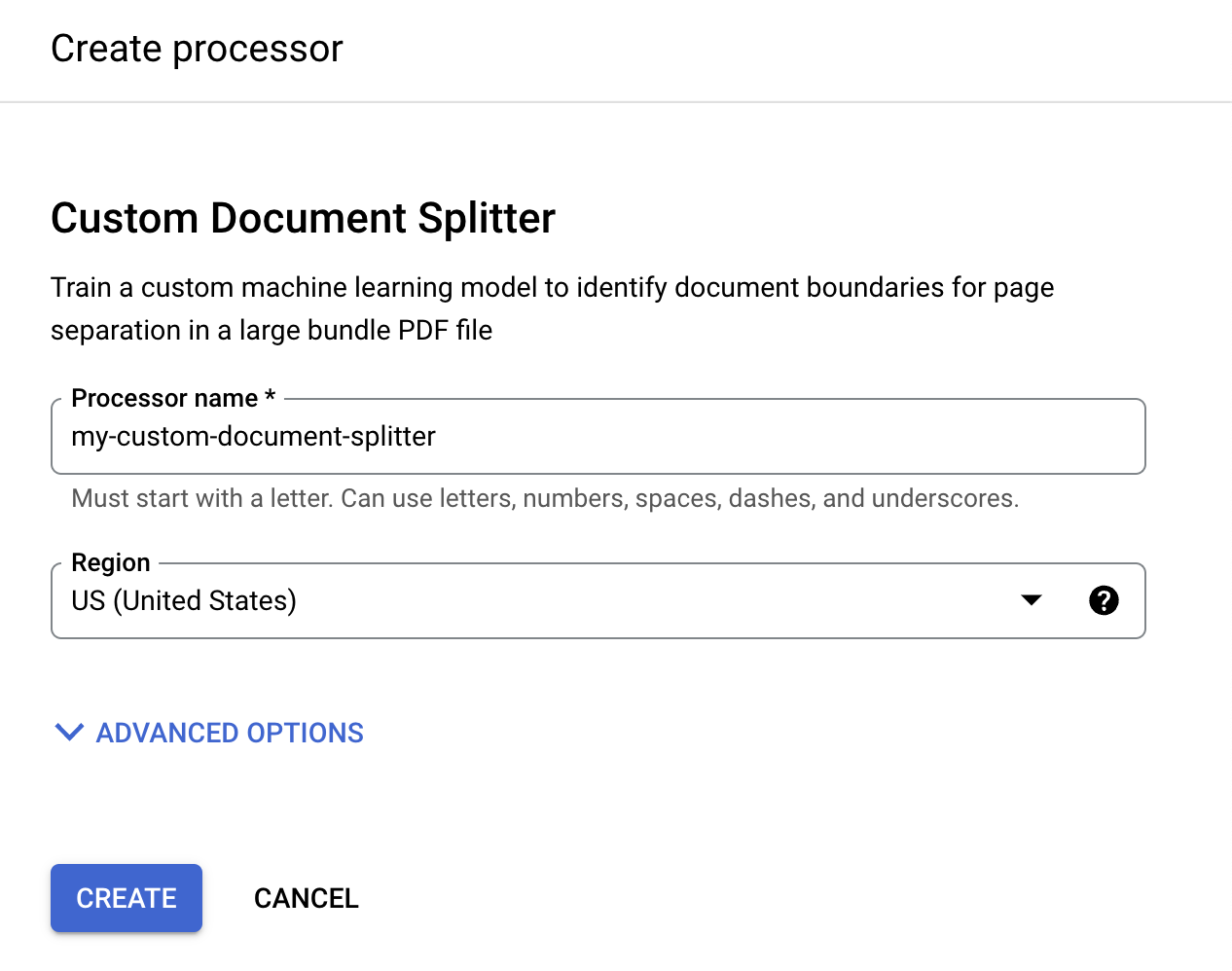
Selecciona la región más cercana.
Selecciona Crear. Aparecerá la pestaña Detalles del procesador.
- Si quieres almacenamiento gestionado por Google, selecciona esa opción.
- Si quieres usar tu propio almacenamiento para usar claves de cifrado gestionadas por el cliente (CMEK), selecciona Especificaré mi propia ubicación de almacenamiento y sigue el procedimiento que se indica más adelante.
Ve a la pestaña
Entrenar de tu procesador.Seleccione Definir ubicación del conjunto de datos. Se te pedirá que selecciones o crees un segmento o una carpeta de Cloud Storage vacíos.
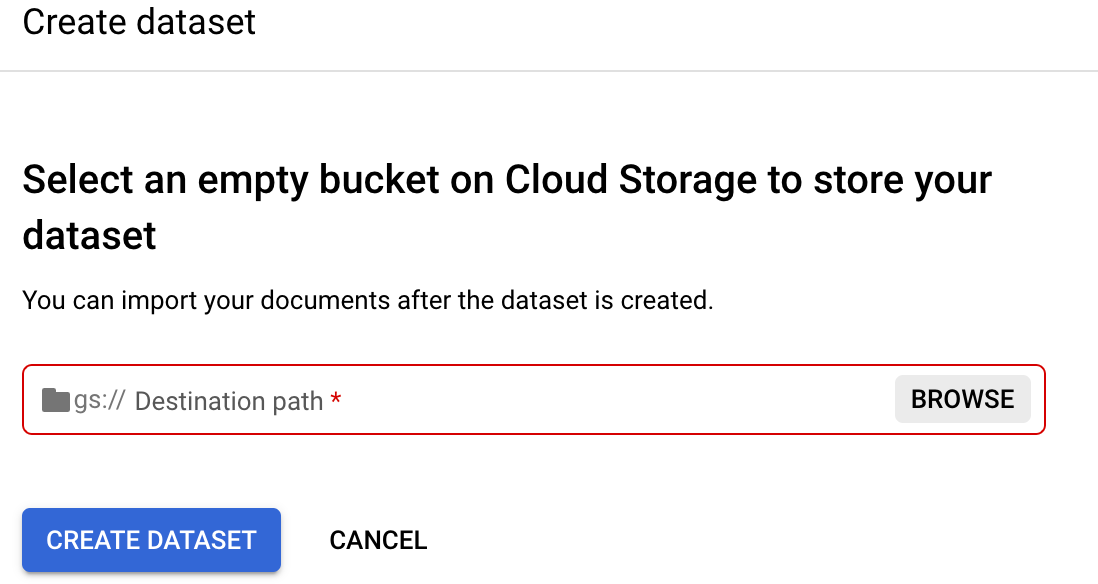
Selecciona Buscar para abrir Seleccionar carpeta.
Selecciona el icono Crear un nuevo contenedor y sigue las instrucciones para crear un contenedor. Después de crear el segmento, se mostrará la página Seleccionar carpeta. Para obtener más información sobre cómo crear un segmento de Cloud Storage, consulta Segmentos de Cloud Storage.
En la página Seleccionar carpeta de tu contenedor, elige el botón Seleccionar situado en la parte inferior del cuadro de diálogo.
En la pestaña Entrenar, selecciona
Editar esquema en la parte inferior izquierda. Se abrirá la página Gestionar etiquetas.Selecciona
Crear etiqueta .Escribe el nombre de la etiqueta. Selecciona Crear. Consulta Definir el esquema del procesador para obtener instrucciones detalladas sobre cómo crear y editar un esquema.
Crea cada una de las siguientes etiquetas para el esquema del procesador.
bank_statementform_1040form_w2form_w9paystub
Cuando haya terminado de añadir las etiquetas, seleccione
Guardar .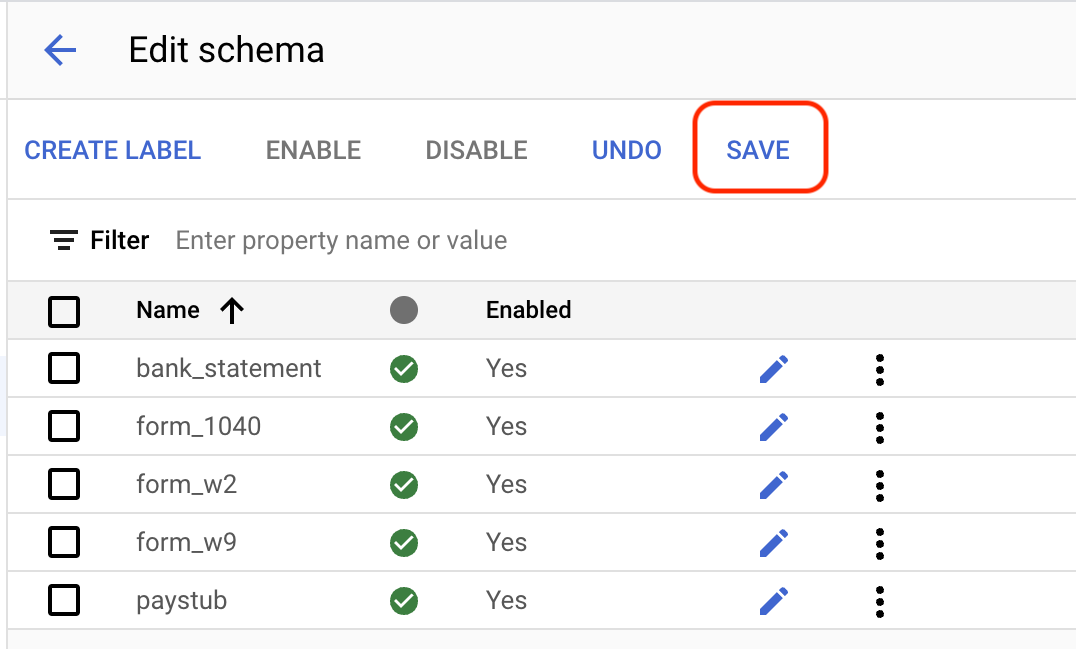
En la pestaña Entrenar, selecciona
Importar documentos .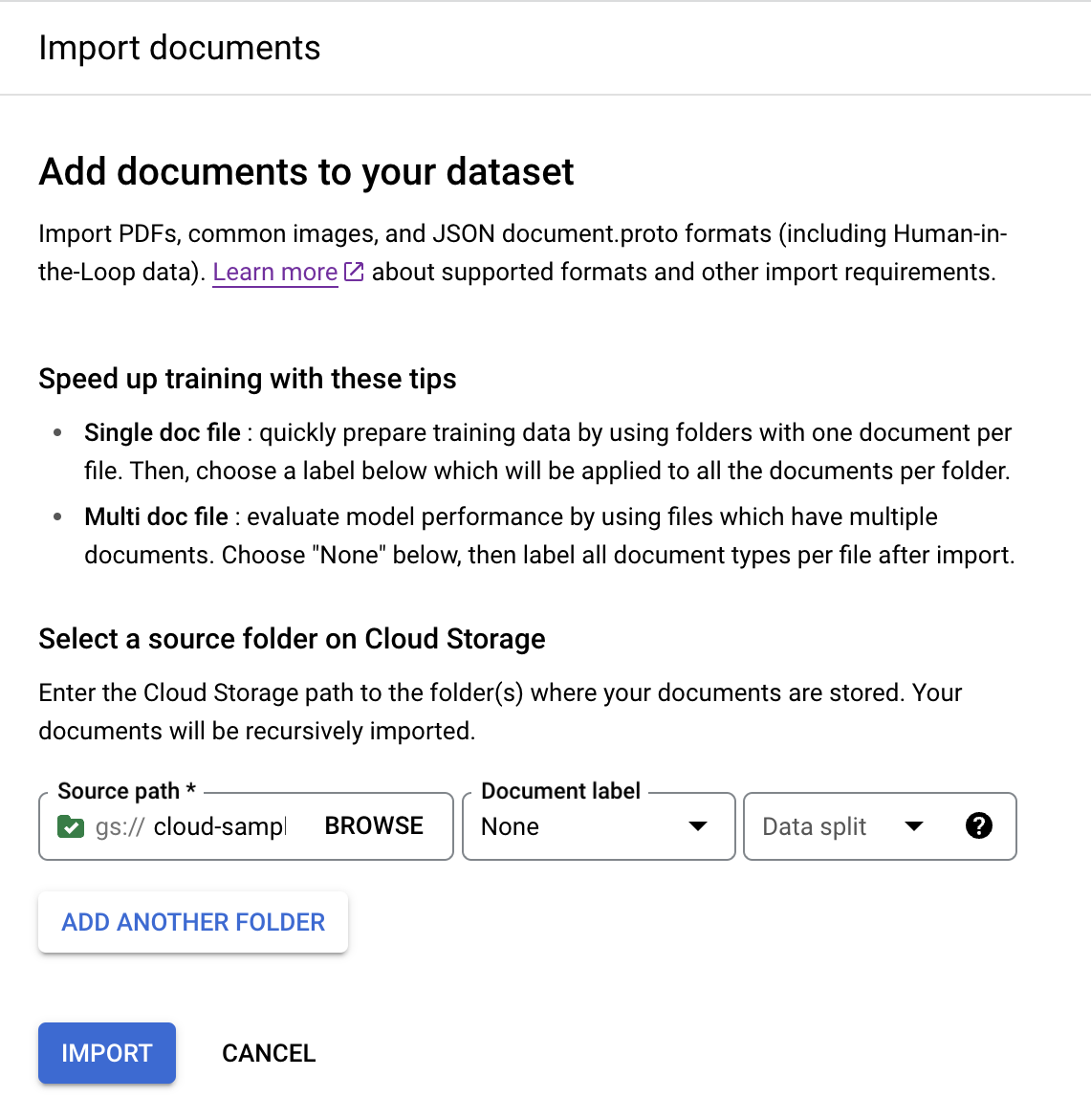
En este ejemplo, introduce esta ruta en
Ruta de origen . Contiene un PDF de un documento.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-UnlabeledEn
Etiqueta del documento , selecciona Ninguna.En el menú desplegable
División del conjunto de datos , selecciona Sin asignar.De forma predeterminada, el documento de esta carpeta no tiene ninguna etiqueta ni se asigna al conjunto de prueba o de entrenamiento.
Selecciona
Importar . Document AI lee los documentos del segmento y los añade al conjunto de datos. No modifica el contenedor de importación ni lee del contenedor una vez completada la importación.- Haz clic en Importar documentos.
Introduce la siguiente ruta en Ruta de origen. Este contenedor contiene documentos sin etiquetar en formato PDF.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelEn la lista División de datos, seleccione División automática. De esta forma, los documentos se dividen automáticamente en un 80% para el conjunto de entrenamiento y un 20% para el conjunto de prueba.
En la sección Aplicar etiquetas, selecciona Elegir etiqueta.
En el caso de estos documentos de muestra, selecciona Otro.
Haz clic en Importar y espera a que se importen los documentos. Puedes salir de esta página y volver más tarde.
Vuelve a la pestaña Entrenar y selecciona
un documento para abrir la consola Gestión de etiquetas.Este documento contiene varios grupos de páginas que deben identificarse y etiquetarse. Primero, debes identificar los puntos de división. Mueve el ratón entre las páginas 1 y 2 de la vista de imagen y selecciona el símbolo
+ .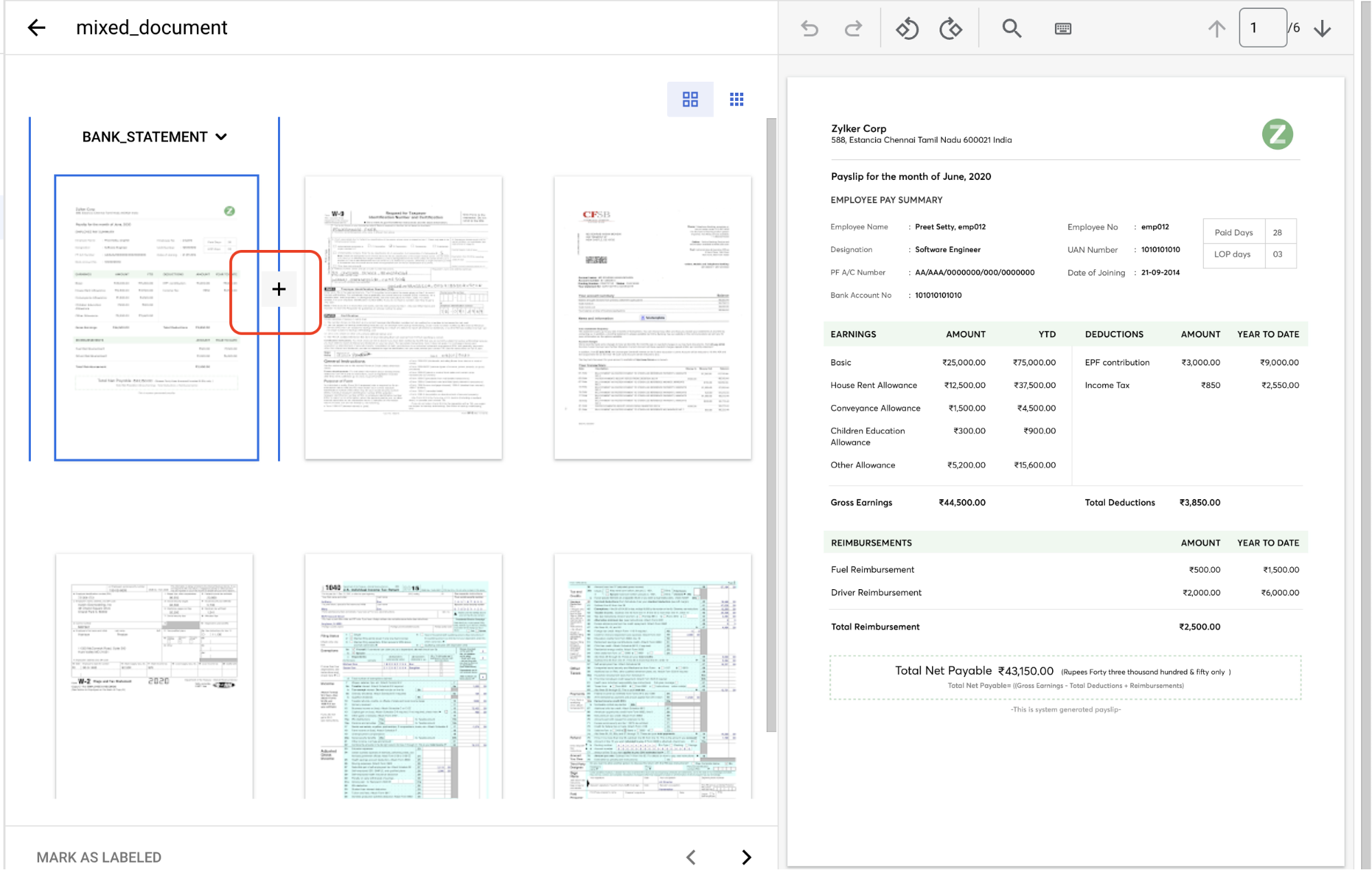
Crea puntos de división antes de los siguientes números de página: 2, 3, 4 y 5.
Cuando haya terminado, la consola debería tener este aspecto.
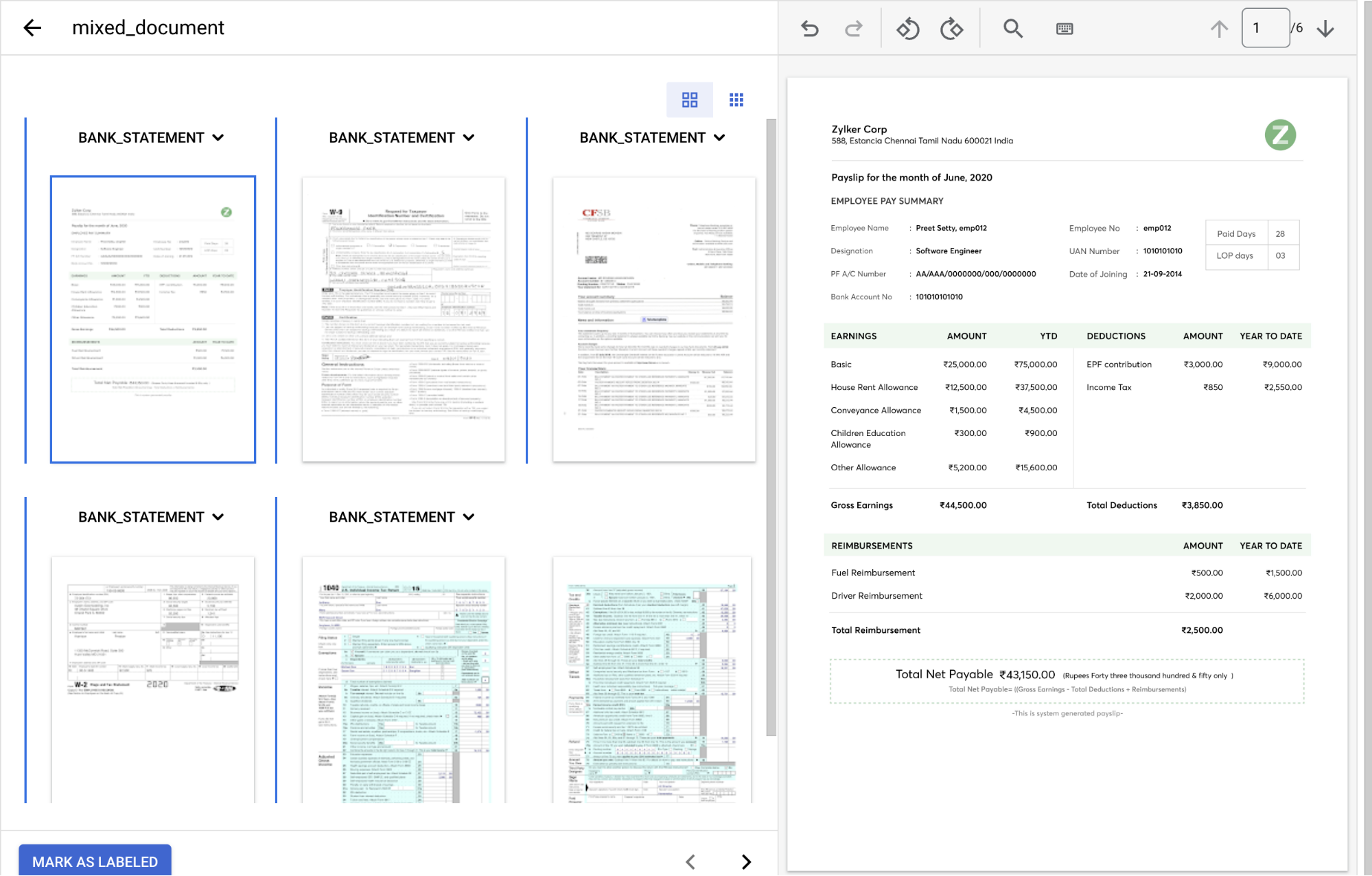
En el
menú desplegable Tipo de documento , seleccione la etiqueta adecuada para cada grupo de páginas.Página(s) Tipo de documento 1 paystub2 form_w93 bank_statement4 form_w25 y 6 form_1040El documento etiquetado debería tener este aspecto cuando esté completo:
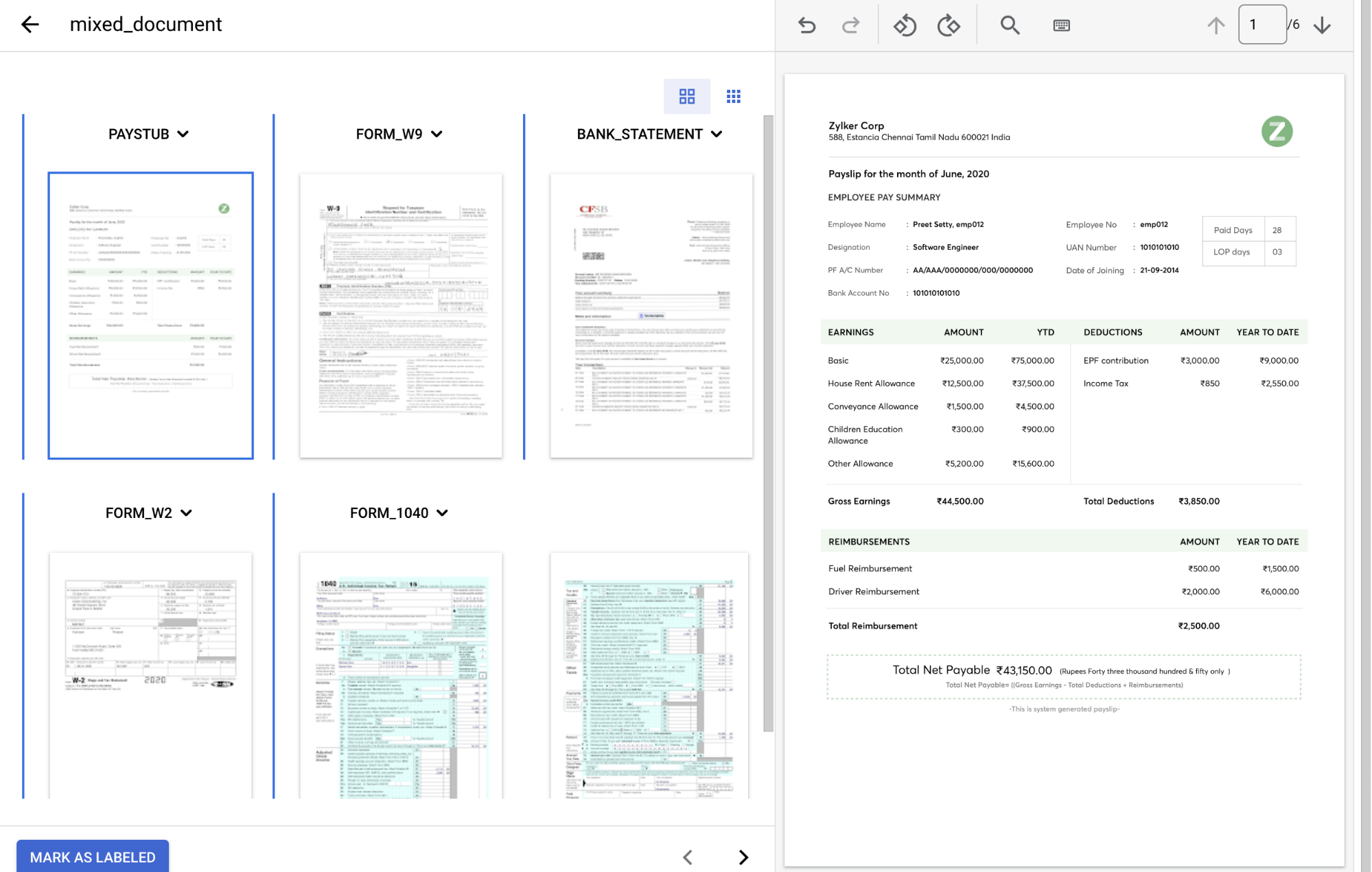
Selecciona
Marcar como etiquetado cuando hayas terminado de anotar el documento.En la pestaña Entrenamiento, el panel de la izquierda muestra que se ha etiquetado un documento.
En la pestaña Entrenar, marca la casilla
Seleccionar todo .En la lista
Asignar a conjunto , selecciona Entrenamiento.En la pestaña Entrenar, selecciona
Importar documentos .Introduce la siguiente ruta en
Ruta de origen . Esta carpeta contiene PDFs de extractos bancarios.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statementDefine la
etiqueta del documento comobank_statement.En el menú
División del conjunto de datos , selecciona División automática. De esta forma, los documentos se dividen automáticamente en un 80 % para el conjunto de entrenamiento y un 20% para el conjunto de prueba.Selecciona
Añadir otra carpeta para añadir más carpetas.Repite los pasos anteriores con las siguientes rutas y etiquetas de documento:
Ruta del segmento Etiqueta del documento cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystubCuando se haya completado, la consola debería tener este aspecto:
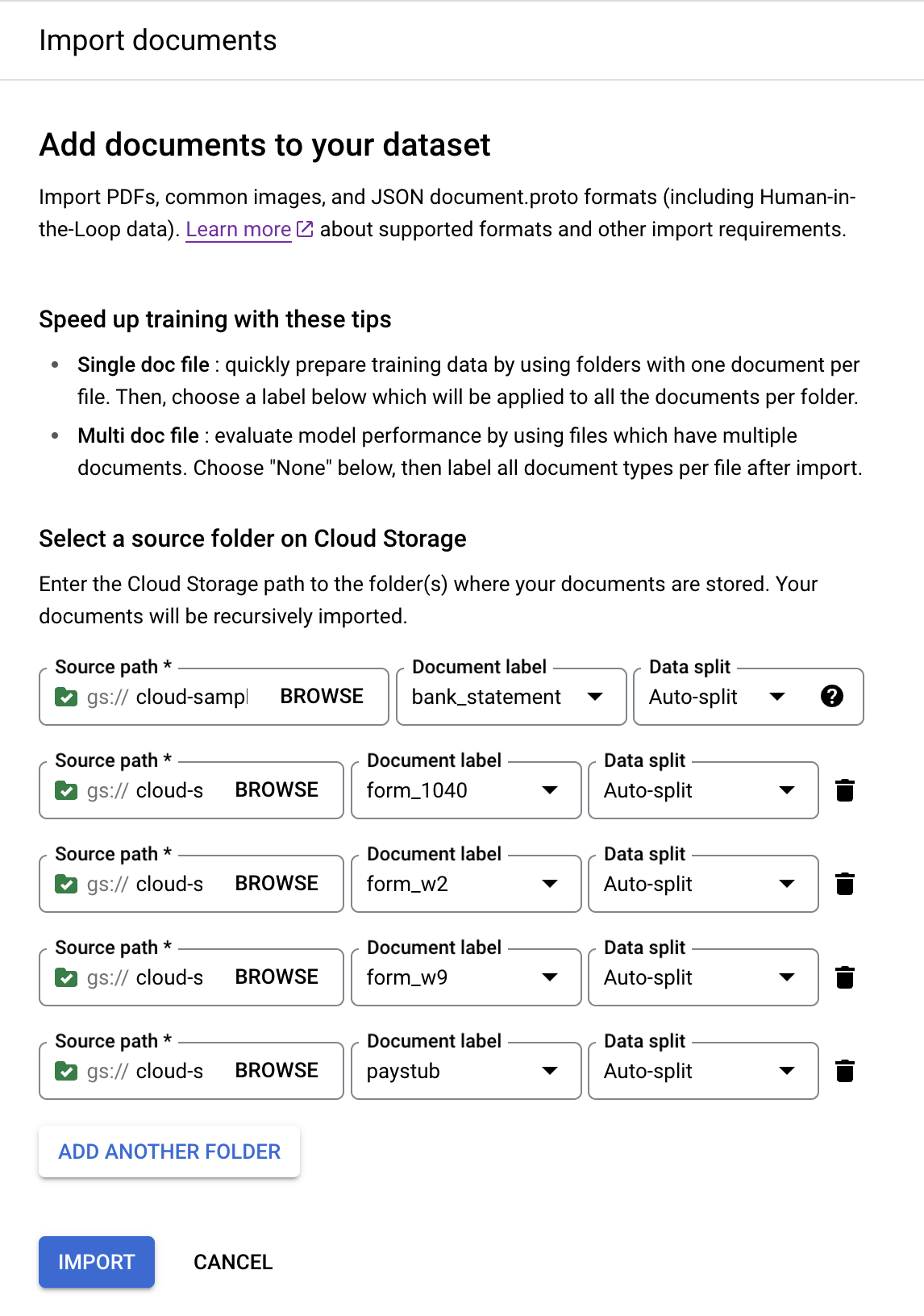
Selecciona
Importar . La importación tarda varios minutos.En la pestaña Entrenar, selecciona
Importar documentos .Introduce la siguiente ruta en
Ruta de origen .cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-LabeledEn
Etiqueta del documento , selecciona Ninguna.En el menú desplegable
División del conjunto de datos , selecciona División automática.Selecciona
Importar .Selecciona
Entrenar nueva versión .En el campo
Nombre de la versión , introduce un nombre para esta versión del procesador, comomy-cds-version-1.(Opcional) Selecciona Ver estadísticas de etiquetas para consultar información sobre las etiquetas del documento. Esto puede ayudarte a determinar tu cobertura. Selecciona Cerrar para volver a la configuración del entrenamiento.
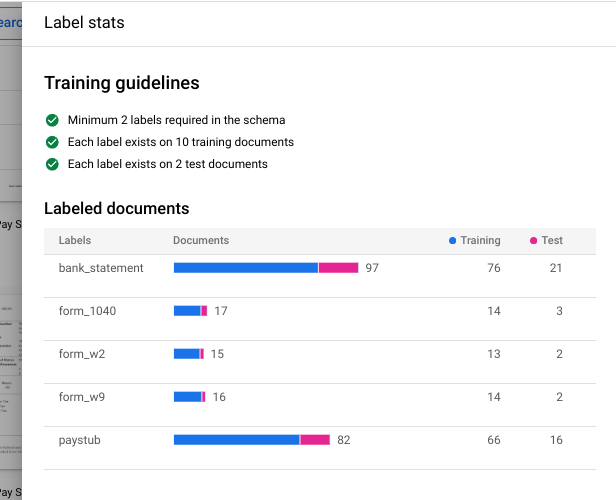
Selecciona
Iniciar entrenamiento Puedes consultar el estado en el panel de la derecha.Una vez completada la formación, ve a la pestaña
Gestionar versiones . Puedes ver los detalles de la versión que acabas de entrenar.Selecciona los
tres puntos verticales situados a la derecha de la versión que quieras implementar y, a continuación, Implementar versión.Selecciona
Implementar en la ventana emergente.El despliegue tarda unos minutos en completarse.
Una vez completada la implementación, ve a la pestaña
Evaluar y probar .En esta página, puede ver métricas de evaluación, como la puntuación F1, la precisión y la recuperación del documento completo y de las etiquetas individuales. Para obtener más información sobre la evaluación y las estadísticas, consulta Evaluar procesador.
Descarga un documento que no se haya usado en entrenamientos ni pruebas anteriores para poder usarlo y evaluar la versión del procesador. Si usas tus propios datos, debes usar un documento específico para ello.
Selecciona
Subir documento de prueba y elige el documento que acabas de descargar.Se abrirá la página Análisis de separadores personalizados. La salida de pantalla muestra cómo se ha dividido y clasificado el documento.
Cuando se haya completado, la consola debería tener este aspecto:
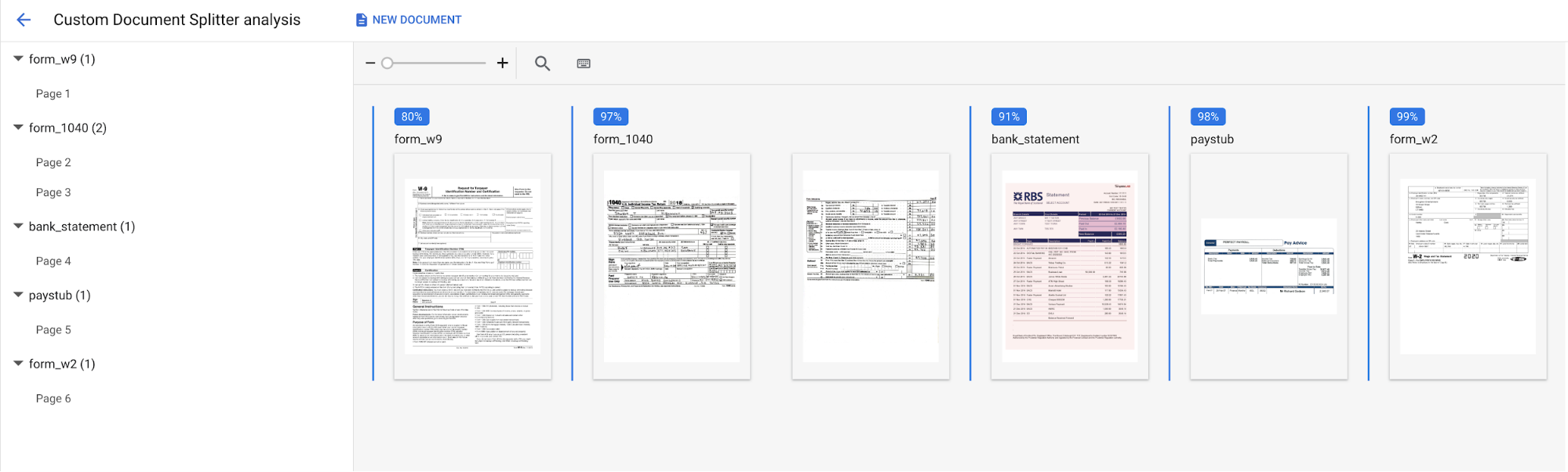
También puedes volver a ejecutar la evaluación con otro conjunto de pruebas u otra versión del procesador.
En la pestaña Entrenar, selecciona
Importar documentos .Introduce la siguiente ruta en
Ruta de origen . Esta carpeta contiene PDFs sin etiquetar de varios tipos de documentos.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabelEn
Etiqueta del documento , selecciona Etiquetado automático.En el menú desplegable
División del conjunto de datos , selecciona División automática.En la sección Etiquetado automático, define la
Versión como la versión que has entrenado anteriormente.- Por ejemplo:
2af620b2fd4d1fcf
- Por ejemplo:
Selecciona
Importar y espera a que se importen los documentos.No puedes usar documentos con etiquetas automáticas para entrenar o probar modelos sin marcarlos como etiquetados. Ve a la sección
Etiquetado automático para ver los documentos etiquetados automáticamente.Selecciona el primer documento para acceder a la consola de etiquetado.
Verifica la etiqueta para asegurarte de que sea correcta y, si no lo es, ajústala.
Cuando hayas terminado, selecciona
Marcar como etiquetado .Repite la verificación de la etiqueta en cada documento etiquetado automáticamente.
Vuelve a la página Entrenar y selecciona Entrenar nueva versión para usar los datos en el entrenamiento.
En el menú de navegación de la consola, selecciona Document AI y, a continuación, Mis procesadores. Google Cloud
Selecciona
Más acciones en la misma fila que el procesador que quieras eliminar.Selecciona Eliminar procesador, escribe el nombre del procesador y, a continuación, selecciona Eliminar de nuevo para confirmar la acción.
Crear un procesador
Configurar un conjunto de datos
Para entrenar este nuevo procesador, debes crear un conjunto de datos con datos de entrenamiento y de prueba que ayuden al procesador a identificar los documentos que quieres dividir y clasificar.
Este conjunto de datos requiere una nueva ubicación. Puede ser un segmento de Cloud Storage o una carpeta vacíos, o bien puedes permitir una ubicación gestionada por Google (interna).

Crear un segmento de Cloud Storage para el conjunto de datos
Comprueba que la ruta de destino se haya rellenado con el nombre del segmento que has seleccionado. Selecciona Crear conjunto de datos. El conjunto de datos puede tardar varios minutos en crearse.
Definir el esquema del procesador
Puede crear el esquema del procesador antes o después de importar documentos en su conjunto de datos. El esquema proporciona etiquetas que se usan para anotar documentos.
Importar un documento sin etiquetar a un conjunto de datos
El siguiente paso es empezar a importar documentos sin etiquetar en tu conjunto de datos y etiquetarlos. Una alternativa recomendada es importar documentos organizados en carpetas por clase, si están disponibles.
Si trabajas en tu propio proyecto, tú decides cómo etiquetar los datos. Consulta las opciones de etiquetado.
Los procesadores personalizados de Document AI requieren un mínimo de 10 documentos en los conjuntos de entrenamiento y de prueba, así como 10 instancias de cada etiqueta en cada conjunto. Recomendamos que cada conjunto tenga al menos 50 documentos, con 50 instancias de cada etiqueta, para obtener el mejor rendimiento. Por lo general, cuantos más datos de entrenamiento haya, mayor será la precisión.
Cuando importas documentos, puedes asignarlos al conjunto Entrenamiento o Prueba durante la importación, o bien esperar a asignarlos más adelante.
Si quieres eliminar uno o varios documentos que has importado, selecciónalos en la pestaña Entrenar y, a continuación, selecciona Eliminar.
Para obtener más información sobre cómo preparar los datos para la importación, consulta la guía de preparación de datos.
Opcional: Etiquetar documentos por lotes al importarlos
Puedes etiquetar todos los documentos que se encuentren en un directorio concreto al importarlos para ahorrar tiempo. Si tienes tus documentos de entrenamiento organizados por clase en carpetas, puedes usar el campo Etiqueta de documento para especificar la clase de esos documentos y evitar tener que etiquetar cada documento manualmente.
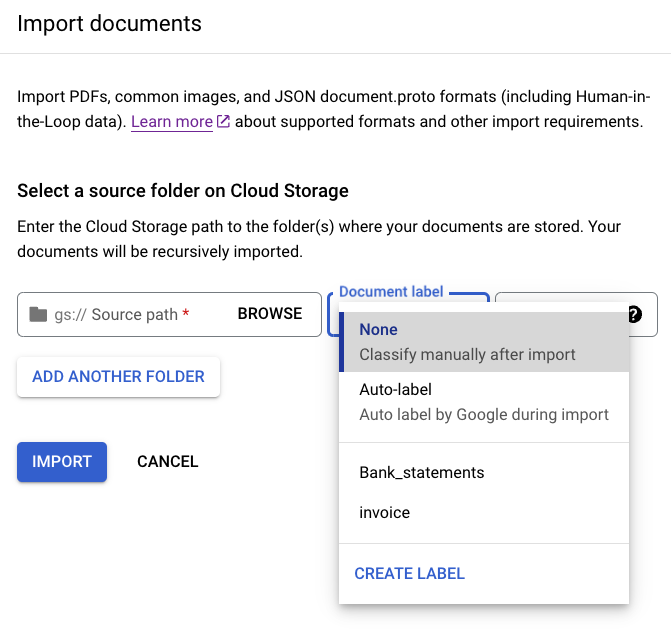
En la imagen Bank_statements (Extractos bancarios) y Invoice (Factura) se muestran etiquetas definidas (clases de documentos) que puedes seleccionar. También puedes usar CREATE LABEL y definir una nueva clase.
Etiquetar un documento
El proceso de aplicar etiquetas a un documento se denomina anotación.
Asignar el documento anotado al conjunto de entrenamiento
Ahora que has etiquetado este documento de ejemplo, puedes asignarlo al conjunto de entrenamiento.
En el panel de la izquierda, verá que se ha asignado un documento al conjunto de entrenamiento.
Importar datos con el etiquetado por lotes
A continuación, importa archivos PDF sin etiquetar que se clasifican en diferentes carpetas de Cloud Storage según su tipo. El etiquetado por lotes te ayuda a ahorrar tiempo al asignar una etiqueta en el momento de la importación en función de la ruta.
Cuando la importación haya terminado, busca los documentos en la pestaña Entrenar.
Importar datos preetiquetados
En esta guía, se le proporcionan datos preetiquetados en formato Document como archivos JSON.
Este es el mismo formato que genera Document AI al procesar un documento, etiquetar con intervención humana o exportar un conjunto de datos.
Cuando la importación haya terminado, busca los documentos en la pestaña Entrenar.
Entrenar el procesador
Ahora que has importado los datos de entrenamiento y de prueba, puedes entrenar el procesador. Como el entrenamiento puede tardar varias horas, asegúrate de configurar el procesador con los datos y las etiquetas adecuados antes de empezar.
Desplegar la versión del procesador
Evaluar y probar el procesador
(Opcional) Importar datos con el etiquetado automático
Después de implementar una versión de procesador entrenada, puedes usar el etiquetado automático para ahorrar tiempo al etiquetar documentos nuevos.
Usar el procesador
Ha creado y entrenado correctamente un procesador de división personalizado.
Puede gestionar sus versiones de procesador entrenadas de forma personalizada igual que cualquier otra versión de procesador. Para obtener más información, consulta Gestionar versiones del procesador.
Una vez implementado, puede enviar una solicitud de procesamiento a su procesador personalizado y la respuesta se puede gestionar de la misma forma que otros procesadores de división.
Limpieza
Para evitar que se apliquen cargos en tu cuenta de Google Cloud por los recursos utilizados en esta página, sigue estos pasos.
Para evitar cargos innecesarios de Google Cloud , usa la Google Cloud console para eliminar tu procesador y tu proyecto si no los necesitas.
Si has creado un proyecto para aprender a usar Document AI y ya no lo necesitas, elimínalo.
Si has usado un proyecto, elimina los recursos que hayas creado para evitar que se apliquen cargos en tu cuenta: Google Cloud