Benutzerdefinierte Extrahierermechanismen
Sie können benutzerdefinierte Extraktoren erstellen, die speziell auf Ihre Dokumente zugeschnitten sind und mit Ihren Daten trainiert und ausgewertet werden. Dieser Prozessor erkennt Entitäten aus Ihren Dokumenten und extrahiert sie daraus. Sie können diesen trainierten Prozessor dann für zusätzliche Dokumente verwenden.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Rufen Sie in der Google Cloud Console im Bereich „Document AI“ die Seite Workbench auf.
Wählen Sie für einen benutzerdefinierten Extrahierer die Option
Prozessor erstellen .
Geben Sie im Menü Prozessor erstellen einen Namen für den Prozessor ein, z. B.
my-custom-document-extractor.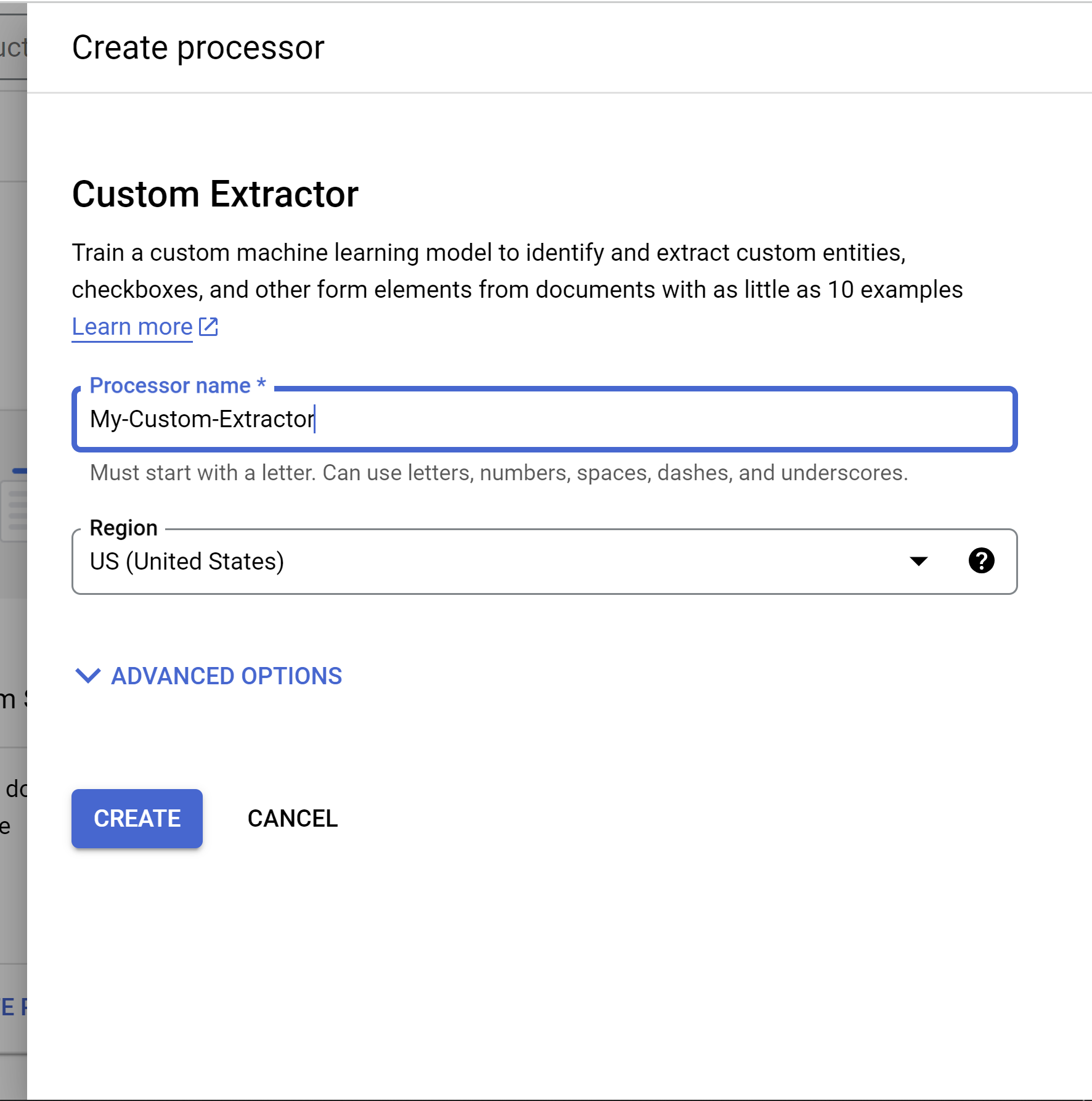
Wählen Sie die Region aus, die Ihnen am nächsten ist.
Optional: Öffnen Sie Erweiterte Optionen.
Sie können Google erlauben, einen Cloud Storage-Bucket für Sie zu erstellen, oder Ihren eigenen erstellen. Wählen Sie für diese Anleitung Von Google verwalteter Speicher aus.
Sie haben auch die Möglichkeit, von Google verwaltete oder vom Kunden verwaltete Verschlüsselungsschlüssel (CMEK) zu verwenden. Wählen Sie für diese Anleitung Google-managed encryption key aus.
Wählen Sie Erstellen aus, um den Prozessor zu erstellen.
Wählen Sie den Tab
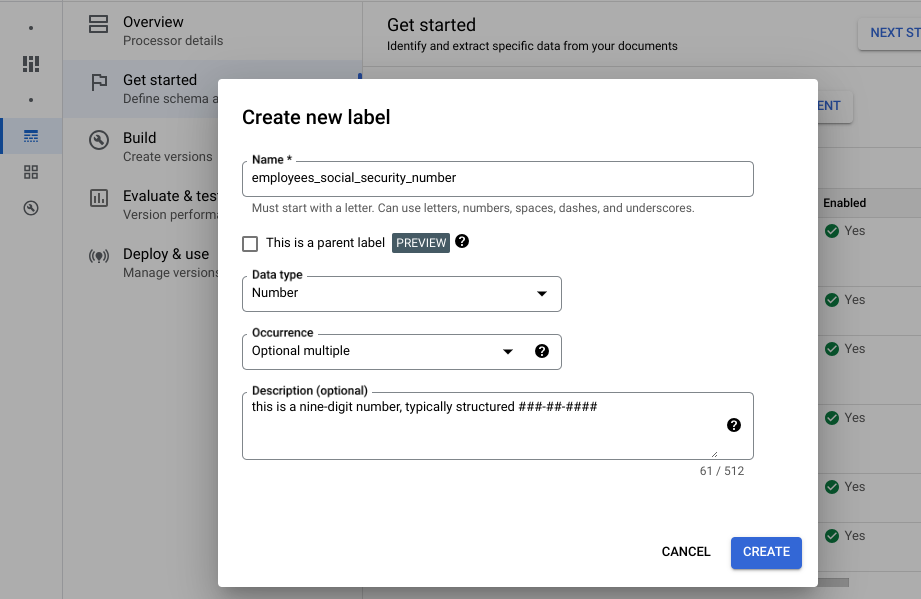
Jetzt starten aus. Das Menü Felder wird angezeigt.Wählen Sie Neues Feld erstellen aus.
Geben Sie den Namen für das Feld ein. Wählen Sie den Datentyp und die Option Häufigkeit aus. Geben Sie dem Label eine aussagekräftige, eindeutige Beschreibung. Mithilfe der Property-Beschreibung können Sie für jede Entität zusätzlichen Kontext, Statistiken und Vorwissen angeben, um die Accuracy und Leistung der Extraktion zu verbessern.
- Wählen Sie Erstellen aus. Eine ausführliche Anleitung zum Erstellen und Bearbeiten eines Schemas finden Sie in Prozessorschema definieren.
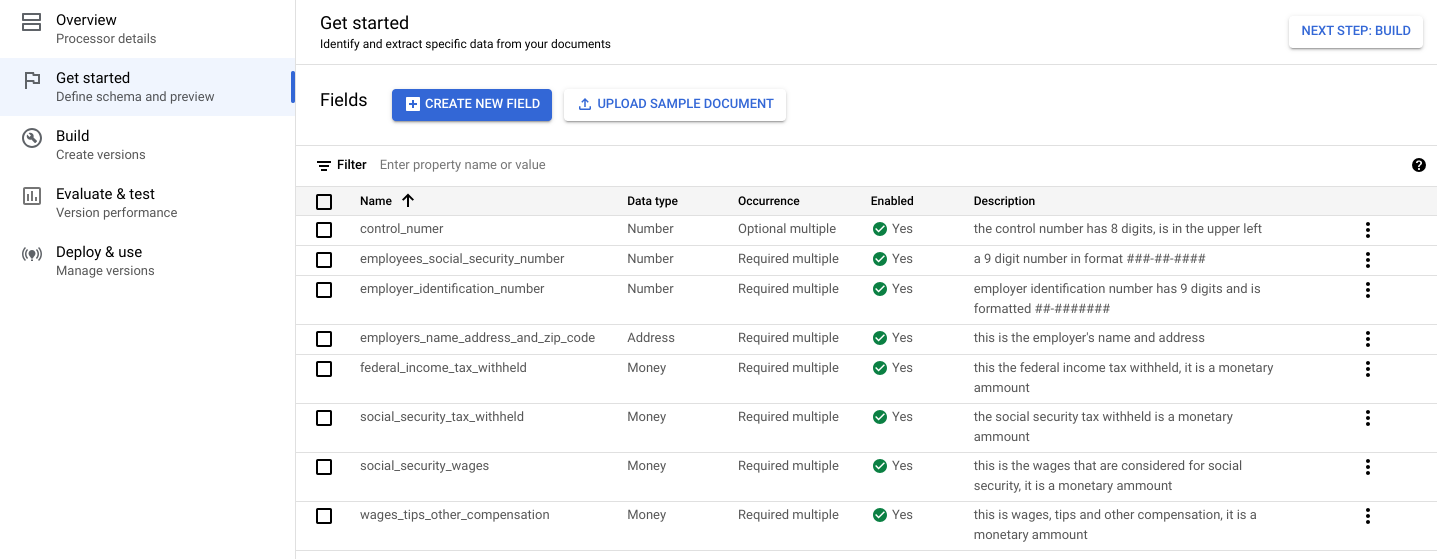
Erstellen Sie folgende Labels für das Prozessorschema.
Name Datentyp Vorkommen control_numberZahl Mehrmals optional employees_social_security_numberZahl Mehrmals erforderlich employer_identification_numberZahl Mehrmals erforderlich employers_name_address_and_zip_codeAdresse Mehrmals erforderlich federal_income_tax_withheldGeld Mehrmals erforderlich social_security_tax_withheldGeld Mehrmals erforderlich social_security_wagesGeld Mehrmals erforderlich wages_tips_other_compensationGeld Mehrmals erforderlich Sie können in Ihrem Prozessorschema auch andere Labelarten erstellen und verwenden, z. B. Kästchen und tabellarische Entitäten. Die W-2-Formulare enthalten z. B. die Kästchen Rechtspersonal, Pensionsplan und Krankenversicherung, die Sie dem Schema hinzufügen können.
Wählen Sie Beispieldokument hochladen aus.
Wählen Sie in der Seitenleiste Dokumente aus Cloud Storage importieren aus.
In diesem Beispiel geben Sie diesen Bucket-Namen unter
Quellpfad ein. Dadurch wird direkt auf ein Dokument verwiesen.cloud-samples-data/documentai/Custom/W2/PDF/W2_XL_input_clean_2950.pdfWählen Sie Importieren aus.
Wenn Sie sich in der Labeling-Konsole befinden, sehen Sie, dass viele Labels bereits mit Daten gefüllt sind. Das liegt daran, dass der Standardmodelltyp für benutzerdefinierte Extrahierer ein Foundation Model ist, das Zero-Shot-Vorhersagen ausführen kann, also ohne Training.
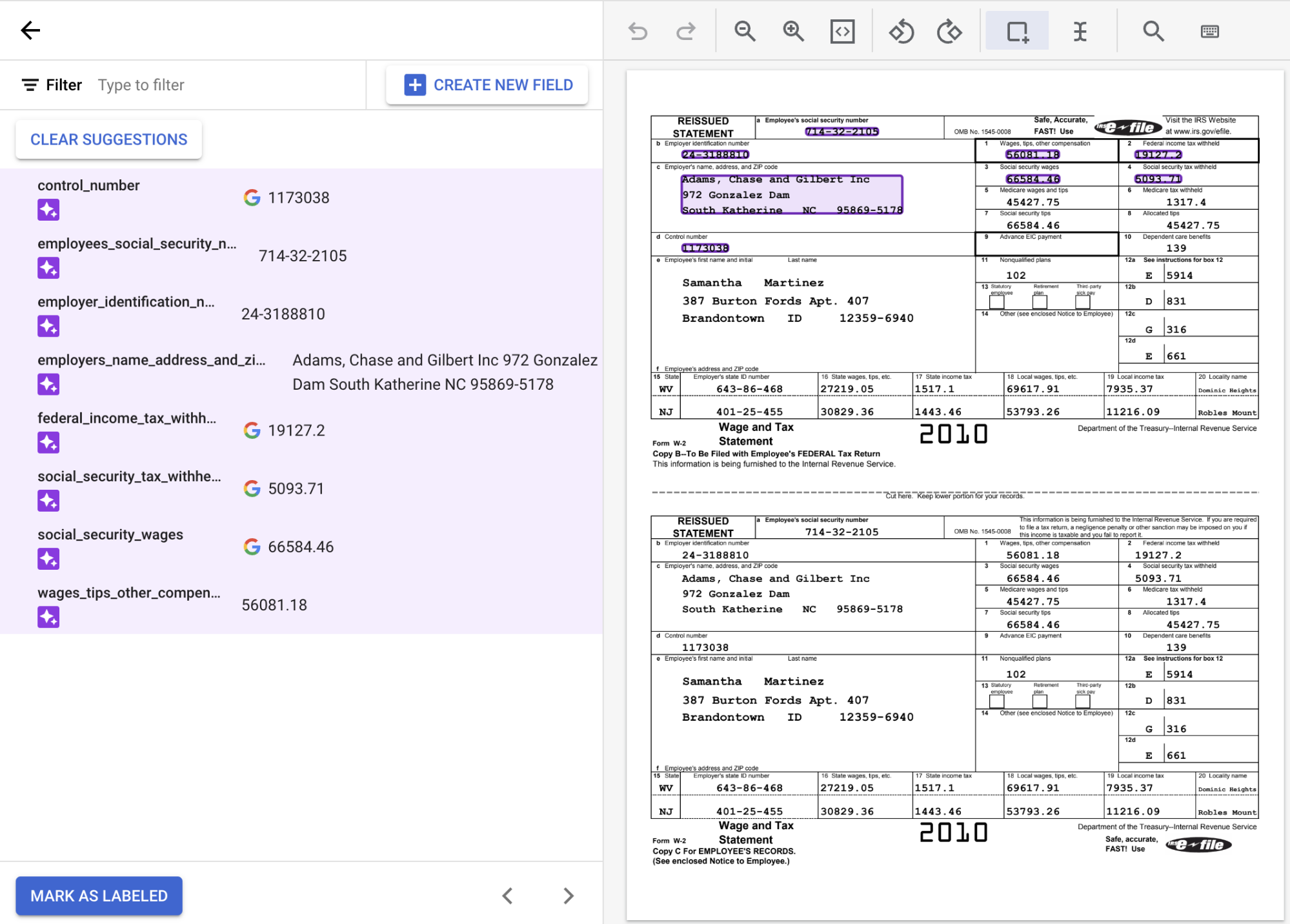
Wenn Sie die vorgeschlagenen Labels verwenden möchten, bewegen Sie den Mauszeiger auf die einzelnen
Labels in der Seitenleiste und klicken Sie auf das Häkchen, um zu bestätigen, dass das Label korrekt ist. Bearbeiten Sie den Text nicht, auch wenn die OCR ihn falsch wiedergibt.In diesem Beispiel wurden die Werte am Ende des Dokuments nicht automatisch erkannt und müssen daher manuell mit einem Label versehen werden.
Verwenden Sie die Symbole in der Symbolleiste über dem Dokument, um Labels hinzuzufügen. Verwenden Sie das Tool
Begrenzungsrahmen standardmäßig oder das ToolText auswählen , um mehrzeilige Werte auszuwählen. und weisen Sie das Label zu.Nachdem der Text ausgewählt wurde, wird ein Drop-down-Menü mit allen definierten Feldern (Entitäten) angezeigt, aus denen Sie eines auswählen können. In diesem Beispiel wurde der Wert von
wages_tips_other_compensationmit dem Begrenzungsrahmentool ausgewählt und dieses Label zugewiesen.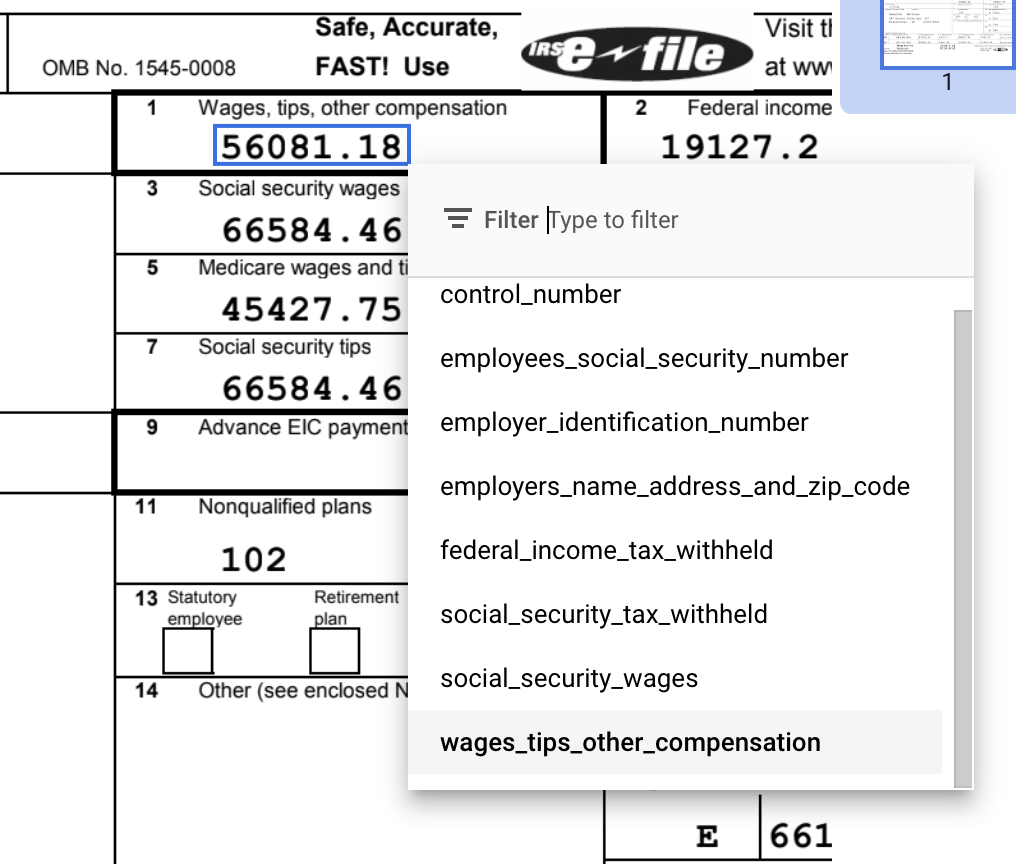
Prüfen Sie, ob die erkannten Textwerte die richtige Textposition für jedes Feld wiedergeben. Das mit einem Label versehene W2-Dokument sollte nach Abschluss so aussehen:
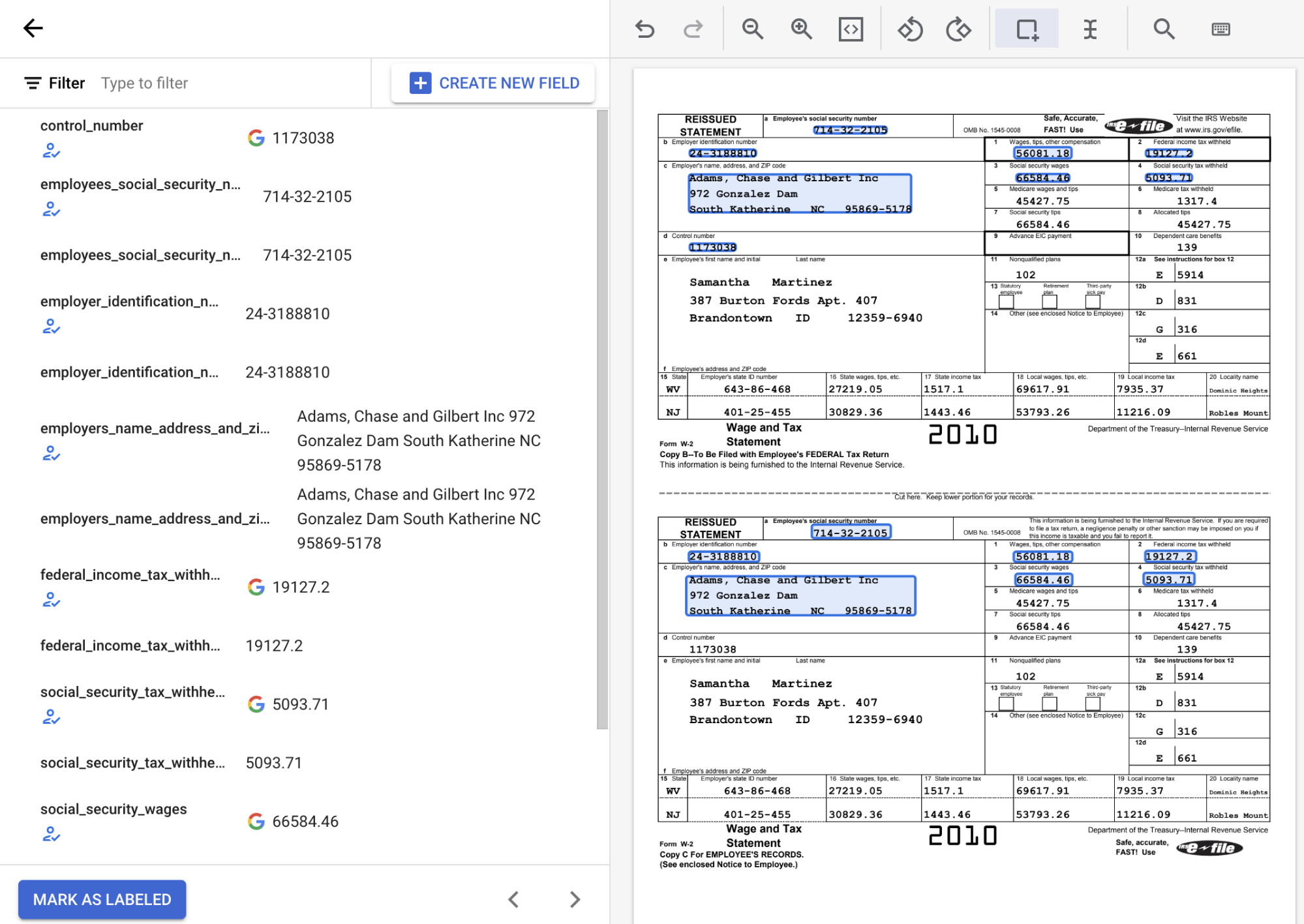
Bei Bedarf können Sie
Neues Feld erstellen auswählen, um dem Schema auf dieser Seite ein neues Feld hinzuzufügen.Wählen Sie
Als „Mit Label versehen“ markieren aus, wenn Sie das Dokument fertig annotiert haben. Sie werden zum Tab Jetzt starten weitergeleitet.Wählen Sie den Tab
Erstellen aus.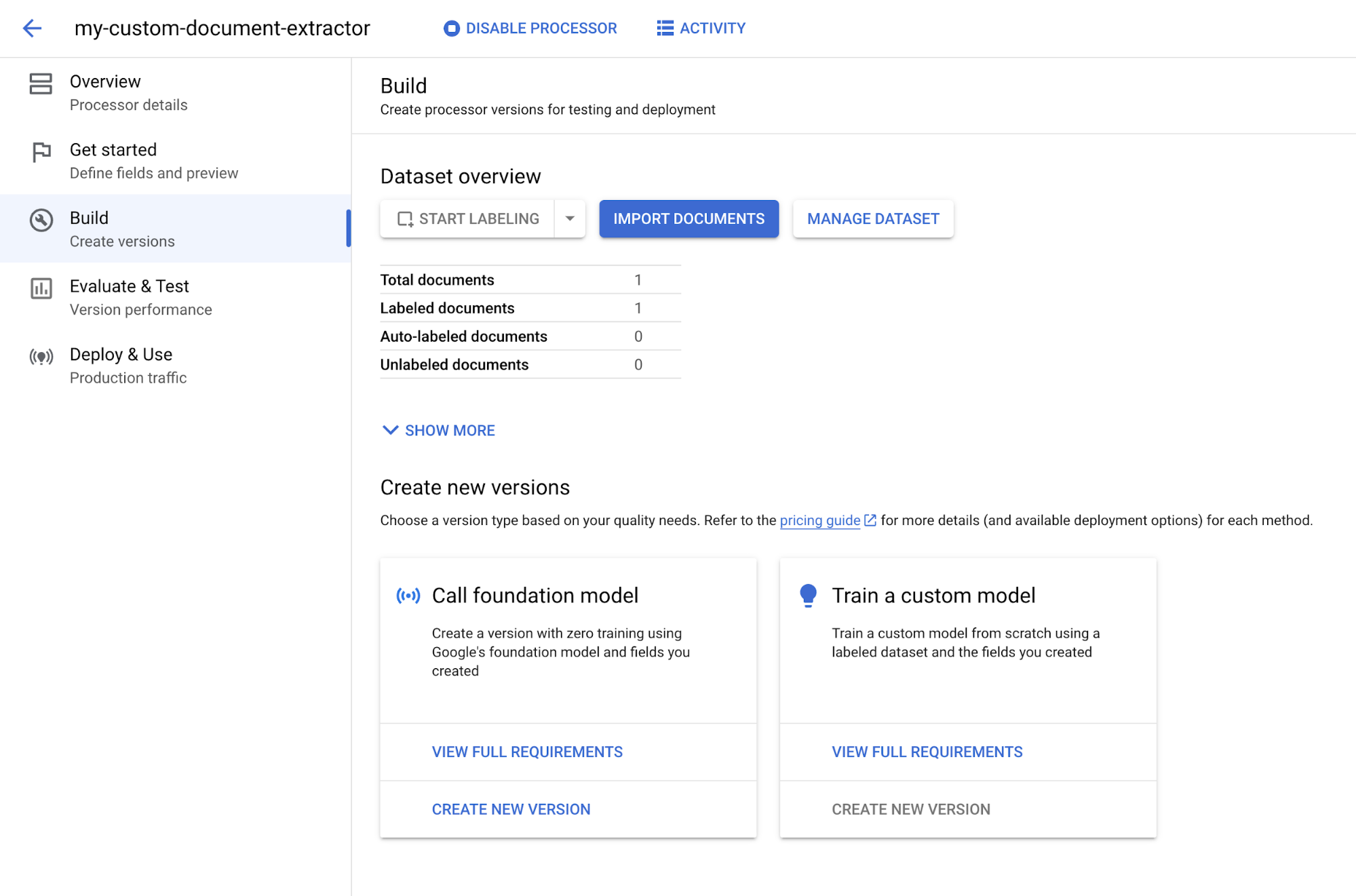
Wählen Sie unter Grundlagenmodell für Aufrufe die Option Neue Version erstellen aus.
Geben Sie einen Namen für die Prozessorversion ein, z. B.
w2-foundation-model.Wählen Sie Version erstellen. Die Erstellung dauert ein paar Minuten.
Optional: Wählen Sie den Tab
Bereitstellen und verwenden aus. Auf dieser Seite sehen Sie die verfügbaren Prozessorversionen und den Bereitstellungsstatus der neuen Version.Rufen Sie die Seite
Erstellen auf.Wählen Sie
Dokumente importieren aus.Wählen Sie in der Seitenleiste Dokumente aus Google Cloud Storage importieren aus.
Geben Sie den Namen des Buckets ein, der Ihre Dokumente enthält.
Wählen Sie in der Drop-down-Liste Datenaufteilung die Option Automatisch aufteilen. Dadurch werden die Dokumente automatisch so aufgeteilt, dass 80 % im Trainingsset und 20 % im Testset enthalten sind.
Klicken Sie im Bereich Automatisches Labeling das Kästchen
Mit automatischem Labeling importieren an.Wählen Sie die Prozessorversion des Grundlagenmodells aus, um die Dokumente mit Labels zu versehen.
Wählen Sie Importieren aus und warten Sie, bis die Dokumente importiert wurden. Sie können diese Seite in der Zwischenzeit verlassen und später wieder zurückkehren.
Sie müssen die Dokumente mit automatisch hinzugefügten Labels prüfen, bevor Sie sie für Trainings oder Tests verwenden können. Wählen Sie
Mit Labels versehen aus, um die Dokumente mit automatisch hinzugefügten Labels aufzurufen.Wenn Sie die vorgeschlagenen Labels verwenden möchten, bewegen Sie den Mauszeiger auf die einzelnen
Anmerkungen und klicken Sie auf das Häkchen, um zu bestätigen, dass das Label korrekt ist. Bearbeiten Sie die Werte nicht zu Schulungszwecken, wenn sie nicht mit dem Text im Dokument übereinstimmen. Ändern Sie den Begrenzungsrahmen nur, wenn der falsche Text ausgewählt wurde.Wählen Sie
Als „Mit Label versehen“ markieren aus, wenn Sie das Dokument fertig annotiert haben.Wiederholen Sie diesen Vorgang für jedes Dokument mit automatisch hinzugefügten Labels.
Rufen Sie die Seite
Erstellen auf.Wählen Sie
Dokumente importieren aus.Wählen Sie in der Seitenleiste Dokumente aus Cloud Storage importieren aus.
Geben Sie unter Quellpfad den Pfad zu den Dokumenten ein. Dieser Bucket sollte Dokumente mit Labels im Document JSON-Format enthalten.
Wählen Sie in der Drop-down-Liste Datenaufteilung die Option Automatisch aufteilen. Dadurch werden die Dokumente automatisch so aufgeteilt, dass 80 % im Trainingsset und 20 % im Testset enthalten sind. Das Häkchen bei Mit automatischem Labeling importieren darf nicht gesetzt sein.
Wählen Sie Importieren aus. Der Import dauert einige Minuten.
- Von der Seite Erstellen aus können Sie auf die Konsole
Dataset verwalten zugreifen, um alle Dokumente und Labels im Dataset anzusehen und zu bearbeiten. Informationen zu den Dataset-Anforderungen finden Sie, wenn Sie unter Benutzerdefiniertes Modell trainieren Neue Version erstellen oder Vollständige Anforderungen anzeigen auswählen. Dies ist kein generatives KI-Modell. Mindestens 10 Trainingsinstanzen und 10 Testinstanzen sind bei einem benutzerdefinierten modellbasierten Prozessor für jedes Feld erforderlich.
Geben Sie im Feld Versionsname einen Namen für diese Prozessorversion ein, z. B.
w2-custom-model.Optional: Wählen Sie Labelstatistiken anzeigen, um Informationen zu den Dokumentlabels aufzurufen. So können Sie Ihre Abdeckung besser einschätzen. Wählen Sie Schließen, um zur Trainingseinrichtung zurückzukehren.
Wählen Sie unter Modelltrainingsmethode die Option Modellbasiert aus.
Wählen Sie Start training (Training starten) aus. Das Training dauert einige Stunden. Sie können die Seite schließen und später zurückkehren.
Optional: Wählen Sie den Tab
Bereitstellen und verwenden aus. Auf dieser Seite sehen Sie die verfügbaren Prozessorversionen und den Trainingsstatus der neuen Version.Wählen Sie nach Abschluss des Trainings den Tab
Bereitstellen und verwenden .Klicken Sie auf das Kästchen links neben der Version, die Sie bereitstellen möchten, und wählen Sie Bereitstellen aus.
Wählen Sie im Dialogfeld Bereitstellen aus. Die Bereitstellung dauert einige Minuten.
Wenn die Version bereitgestellt ist, können Sie sie als
Standardversion festlegen oder die Versions-ID angeben, wenn Sie Dokumente mit der API verarbeiten.Wählen Sie den Tab
Bewerten , um die Prozessorversion zu testen. Auf dieser Seite sehen Sie Bewertungsmesswerte wie den F1-Wert, die Genauigkeit und die Trefferquote für das gesamte Dokument sowie einzelne Labels. Weitere Informationen zu Auswertungen und Statistiken finden Sie in Prozessor auswerten.Wählen Sie die Auswahl
Version und wählen Sie die Version mit dem Basismodell aus.Laden Sie ein Dokument herunter, das nicht an vorherigen Trainings oder Tests beteiligt war, damit Sie es zur Bewertung der Prozessorversion verwenden können. Wenn Sie eigene Daten nutzen, verwenden Sie ein speziell dafür gedachtes Dokument.
Wählen Sie
Testdokument hochladen und wählen Sie das Dokument aus, das Sie gerade heruntergeladen haben. Die Seite Analyse des benutzerdefinierten Dokumentextraktors wird geöffnet. Die Bildschirmausgabe zeigt, wie gut das Dokument extrahiert wurde.Testen Sie das Dokument noch einmal mit der Version mit einem benutzerdefiniert trainierten Modell.
- Folgen Sie den Codebeispielen unter Verarbeitungsanfrage senden, um die Online- oder Batchverarbeitung zu verwenden.
- Informationen zur Anzahl der Seiten, die für die Online- und Batchverarbeitung unterstützt werden, finden Sie unter Kontingente und Limits.
- Folgen Sie dem Codebeispiel für den benutzerdefinierten Extractor unter Verarbeitungsantwort verarbeiten, um die extrahierten Entitäten aus dem Prozessor abzurufen.
Wählen Sie im Google Cloud Navigationsmenü der Console Document AI und dann Meine Prozessoren aus.
Wählen Sie in der Zeile, in der sich der zu löschende Prozessor befindet,
Weitere Aktionen aus.Wählen Sie Prozessor löschen aus, geben Sie den Namen des Prozessors ein und wählen Sie zur Bestätigung noch einmal Löschen aus.
Prozessor erstellen
Prozessorfelder definieren
Sie befinden sich jetzt auf der Seite Prozessorübersicht des gerade erstellten Prozessors.
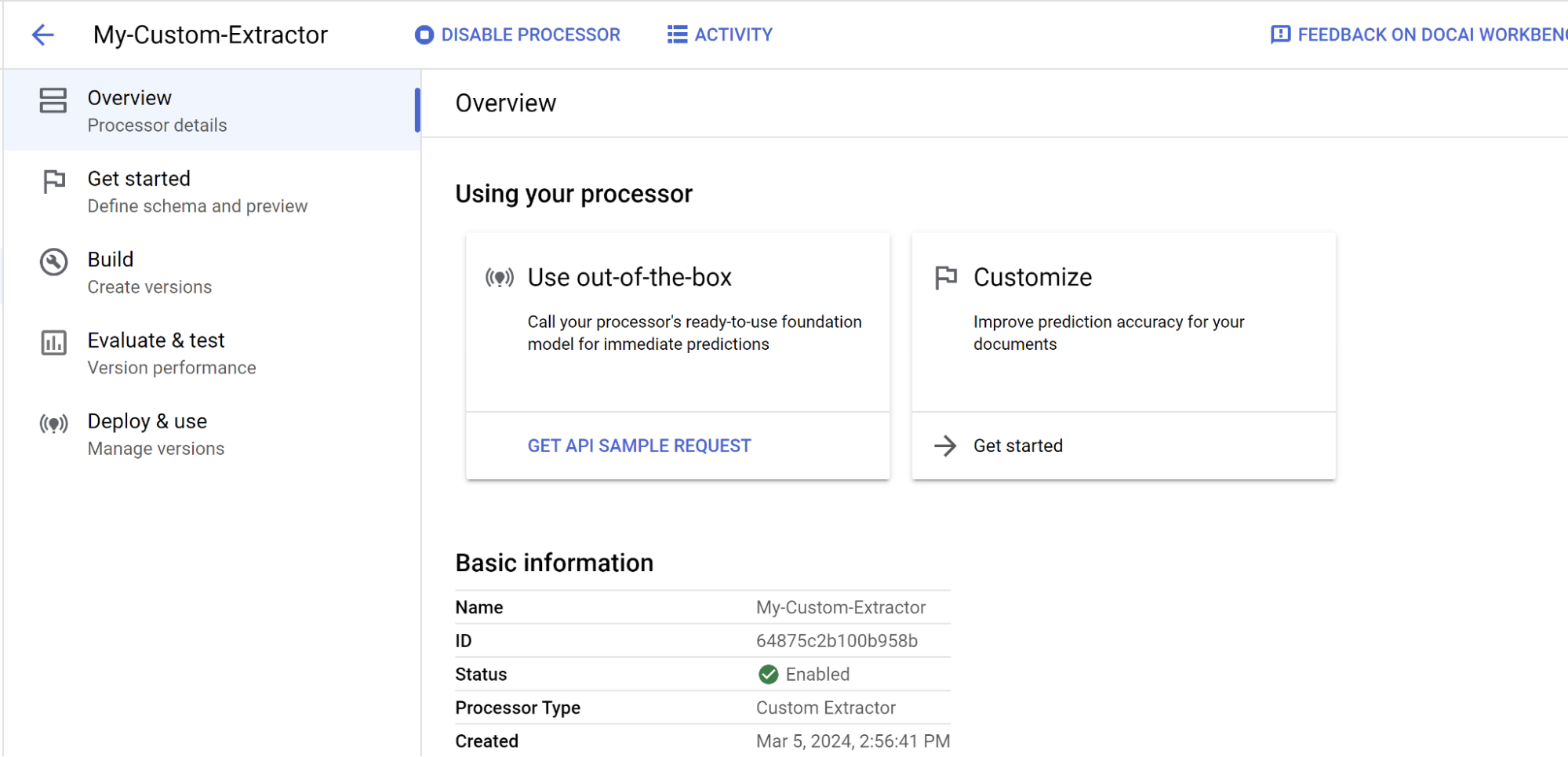
Sie können die Felder angeben, die der Prozessor extrahieren und mit dem Labeling von Dokumenten beginnen soll.
Beispieldokument hochladen
Testen Sie mit einem Beispieldokument.
Sie werden zur Labeling-Konsole weitergeleitet.
Dokument mit Label versehen
Das Auswählen von Text in einem Dokument und das Anwenden von Labels wird als Annotation oder Labeling bezeichnet.
Prozessorversion mit Basismodell erstellen
Nachdem Sie ein einzelnes Dokument mit einem Label versehen haben, können Sie mithilfe des vortrainierten Grundlagenmodells eine Prozessorversion zum Extrahieren von Entitäten erstellen.
Generative KI verwenden, um Dokumente automatisch mit Labels zu versehen
Mit dem Basismodell lassen sich Felder für eine Vielzahl von Dokumenttypen präzise extrahieren. Sie können jedoch auch zusätzliche Trainingsdaten bereitstellen, um die Genauigkeit des Modells für bestimmte Dokumentstrukturen zu verbessern.
Der benutzerdefinierte Extrahierer verwendet die von Ihnen definierten Labelnamen und vorherige Annotationen, um Dokumenten in großem Umfang mithilfe der automatischen Labels schneller und einfacher Labels hinzuzufügen.
Trainingsdokumente mit Labels importieren
Optional: Dataset ansehen und verwalten
Benutzerdefinierten modellbasierten Prozessor trainieren
Da das Training mehrere Stunden dauern kann, sollten Sie den Prozessor mit den entsprechenden Daten und Labels einrichten, bevor Sie mit dem Training beginnen.
Prozessorversion bereitstellen
Prozessor bewerten und testen
Prozessor verwenden
Sie haben erfolgreich einen benutzerdefinierten Extractor-Prozessor erstellt und trainiert.
Sie können Ihre benutzerdefiniert trainierten Prozessorversionen wie jede andere Prozessorversion verwalten. Weitere Informationen finden Sie in Prozessorversionen verwalten.
So verwenden Sie die Document AI API:
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden:
Um unnötige Google Cloud -Gebühren zu vermeiden, verwenden SieGoogle Cloud console , um den Prozessor und das Projekt zu löschen, wenn Sie diese nicht mehr benötigen.
Wenn Sie ein neues Projekt erstellt haben, um mehr über Document AI zu erfahren, und dieses Projekt nicht mehr benötigen, löschen Sie das Projekt.
Wenn Sie ein vorhandenes Google Cloud Projekt verwendet haben, löschen Sie die von Ihnen erstellten Ressourcen. So vermeiden Sie, dass Ihrem Konto Gebühren in Rechnung gestellt werden:
Nächste Schritte
Weitere Informationen finden Sie unter Leitfäden.