Mantieni tutto organizzato con le raccolte
Salva e classifica i contenuti in base alle tue preferenze.
Questo documento è una guida ai concetti fondamentali sull'utilizzo di Document AI.
Ti consigliamo di leggere questa pagina prima di consultare qualsiasi altra documentazione o guida rapida.
Automatizzare i flussi di lavoro di elaborazione dei documenti
Le attività di tutto il mondo si affidano molto ai documenti per archiviare e trasmettere informazioni.
Spesso queste informazioni devono essere digitalizzate per diventare utili. Tuttavia,
questo risultato viene solitamente ottenuto tramite procedure manuali che richiedono molto tempo.
Ad esempio:
Digitalizzazione di libri per e-reader.
Elaborazione dei moduli di anamnesi medica negli studi medici.
Analisi di ricevute e fatture per la convalida delle note spese.
Autenticazione dell'identità basata su documenti di identità.
Estrazione di informazioni sul reddito dai moduli fiscali per l'approvazione dei prestiti.
Comprensione dei contratti per i termini chiave degli accordi commerciali.
Ciascuno di questi flussi di lavoro prevede l'estrazione del testo non elaborato dai documenti, quindi l'estrazione di un testo specifico che corrisponde ai dati necessari (i campi o le entità).
Tuttavia, ogni tipo di documento ha una struttura e un layout diversi e il pattern dei campi
varia a seconda del caso d'uso specifico.
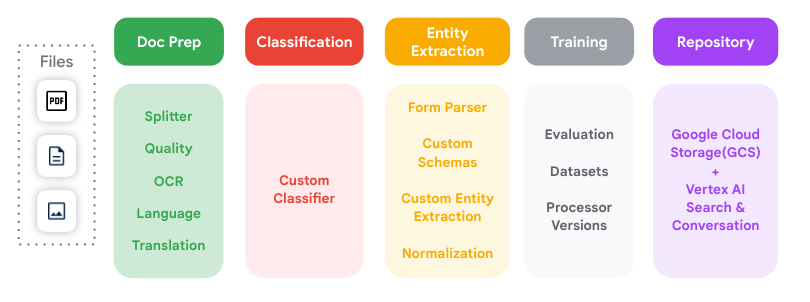
Componenti di Document AI
Document AI è una piattaforma di elaborazione e comprensione dei documenti
che prende i dati non strutturati dai documenti e li trasforma in
dati strutturati (campi specifici, adatti a un database), rendendoli più facili da comprendere, analizzare e utilizzare.
Document AI è basato sui prodotti di Vertex AI con l'IA generativa per aiutarti a
creare applicazioni di elaborazione dei documenti scalabili, end-to-end e basate sul cloud senza competenze specialistiche di machine learning.
Con Document AI puoi:
Digitalizza i documenti utilizzando l'OCR per ottenere testo, layout e vari componenti aggiuntivi come il rilevamento della qualità delle immagini (per la leggibilità) e la correzione della distorsione (completamente automatica).
Estrai testo e informazioni sul layout dai file di documenti e normalizza le entità.
Identifica le coppie chiave-valore nei moduli strutturati e nelle tabelle regolari. Ad esempio: Name: Jill Smith è una coppia chiave-valore.
Classifica i tipi di documenti per guidare i processi downstream come l'estrazione e l'archiviazione.
Suddividi e classifica i documenti per tipo. Ad esempio, un file PDF con più documenti reali.
Prepara i set di dati da utilizzare nel fine tuning e nelle valutazioni dei modelli utilizzando l'etichettatura automatica, la gestione degli schemi e le funzionalità di gestione dei set di dati come la revisione di documenti e previsioni.
Integralo con prodotti come Cloud Storage, BigQuery e Vertex AI Search
per archiviare, cercare, organizzare, gestire e analizzare documenti e metadati.
Questo diagramma illustra tutti i passaggi chiave di elaborazione dei documenti supportati da Document AI e come possono connettersi tra loro.
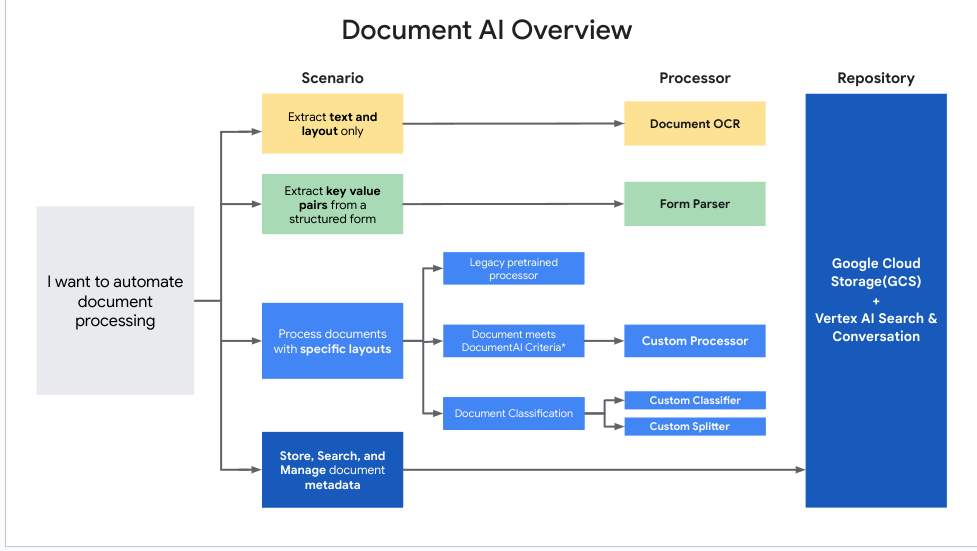
Processore
Un processore Document AI si trova tra il file del documento e un modello di machine learning che esegue azioni di elaborazione e comprensione dei documenti.
Possono essere utilizzati per classificare, dividere, analizzare o analizzare un documento.
Ogni Google Cloud progetto deve creare le proprie istanze del processore.
I processori rientrano in una delle seguenti categorie:
Digitalizza: OCR.
Estrai: estrattore personalizzato, analizzatore sintattico di moduli, analizzatore sintattico di layout e analizzatori sintattici preaddestrati.
Classifica: classificatore personalizzato e strumento per la divisione personalizzato.
Addestra un processore con dati di addestramento e test da zero oppure esegui l'uptraining di una nuova versione del processore (preaddestrato) in base a una esistente.
[[["Facile da capire","easyToUnderstand","thumb-up"],["Il problema è stato risolto","solvedMyProblem","thumb-up"],["Altra","otherUp","thumb-up"]],[["Difficile da capire","hardToUnderstand","thumb-down"],["Informazioni o codice di esempio errati","incorrectInformationOrSampleCode","thumb-down"],["Mancano le informazioni o gli esempi di cui ho bisogno","missingTheInformationSamplesINeed","thumb-down"],["Problema di traduzione","translationIssue","thumb-down"],["Altra","otherDown","thumb-down"]],["Ultimo aggiornamento 2025-09-04 UTC."],[[["\u003cp\u003eDocument AI is a platform that transforms unstructured data from documents into structured data, making it easier to understand, analyze, and use.\u003c/p\u003e\n"],["\u003cp\u003eDocument AI enables the automation of document processing workflows, such as digitizing documents, extracting text and entities, classifying document types, and preparing datasets for model training.\u003c/p\u003e\n"],["\u003cp\u003eDocument AI uses processors that fall into the categories of digitize, extract, or classify to perform specific document processing and understanding actions.\u003c/p\u003e\n"],["\u003cp\u003eTo use Document AI, you must choose a suitable processor, create the processor, optionally train it, and then send documents to the processor for processing.\u003c/p\u003e\n"],["\u003cp\u003eDocument AI can integrate with products like Cloud Storage, BigQuery, and Vertex AI Search for storing, searching, and analyzing documents.\u003c/p\u003e\n"]]],[],null,["This document is a guide to the fundamental concepts of using Document AI.\nYou should read this page before proceeding to any other documentation or quickstarts.\n\nAutomate document processing workflows\n\nBusinesses all over the world rely heavily on documents to store and convey information.\nThis information often needs to be digitized for it to become useful. However,\nthis is usually accomplished through time-intensive, manual processes.\n\nFor example:\n\n- Digitizing books for e-readers.\n- Processing medical intake forms at doctor's offices.\n- Parsing receipts and invoices for expense report validation.\n- Authenticating identity based on ID cards.\n- Extracting income information from tax forms for approving loans.\n- Understanding contracts for key business agreement terms.\n\nEach of these workflows involve getting the raw text from documents, then\nextracting specific text from that which corresponds to the data needed (the fields or entities).\nHowever, each document type has a different structure and layout, and the pattern of fields\nvary depending on the specific use case.\n\nDocument AI components\n\nDocument AI is a [document processing and understanding](https://en.wikipedia.org/wiki/Document_processing)\nplatform that takes unstructured data from documents and transforms it into\nstructured data (specific fields, suitable for a database), making it easier to understand, analyze, and consume.\n\nDocument AI is built on top of products within Vertex AI with generative AI to help you\ncreate scalable, end-to-end, cloud-based document processing applications without specialized machine learning expertise.\n\nUsing Document AI, you can:\n\n- **Digitize documents** using OCR to get text, layout, and various add ons such as image quality detection (for readability) and deskewing (fully automatic).\n- **Extract** text and layout information, from document files and normalize entities.\n- **Identify key-value pairs (kvp)** in structured forms and regular tables. For example: `Name: Jill Smith` is a kvp.\n- **Classify** document types to drive downstream processes such as extraction and storage.\n- **Split** and classify documents by type. For example, a PDF file with multiple real documents.\n- **Prepare datasets** to be used in fine-tuning and model evaluations using auto-labeling, schema management, and dataset management features such as document and prediction review.\n- **Integrate it with products** like Cloud Storage, BigQuery, and Vertex AI Search to help you store, search, organize, govern, and analyze documents and metadata.\n\nThis diagram illustrates all of the key document processing steps that are\nsupported by Document AI and how they can connect to each other.\n\nProcessor\n\nA Document AI processor lies between the document file and a machine\nlearning model that performs document processing and understanding actions.\nThey can be used to classify, split, parse, or analyze a document.\n\nEach Google Cloud project needs to create its own processor instances.\n\nProcessors fit into one of the following categories:\n\n- **Digitize**: OCR.\n- **Extract**: Custom extractor, Form Parser, layout parser, and pretrained parsers.\n- **Classify**: Custom classifier and custom splitter.\n\nRefer to the [Full processor and detail list](/document-ai/docs/processors-list) for information about all\navailable processor types for Document AI.\n\nWhich processor should I use?\n\nTo decide what processor type to use for a specific application, here are some general guidelines:\n| **Note:** All processors can extract text and layout information.\n\n| **Category** | **Use case** | **Processor type** |\n|--------------|------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|\n| Digitize | Extract text and layout information from documents. | [Enterprise Document OCR](/document-ai/docs/processors-list#processor_doc-ocr) |\n| Digitize | Analyze the scanned image quality (readability) of a document. | [Enterprise Document OCR](/document-ai/docs/processors-list#processor_doc-ocr) with [image-quality analysis](/document-ai/docs/processors-list#processor_doc-quality-processor) enabled |\n| Digitize | Extract entities from a custom document that does not meet the [custom processor criteria](/document-ai/quotas). | |\n| Extract | Extract tables or kvp from a structured form in a document. | [Form Parser](/document-ai/docs/processors-list#processor_form-parser) |\n| Extract | Extract elements like text, tables, and lists in a document and return context aware chunks. | [Layout Parser](/document-ai/docs/layout-parse-chunk) |\n| Extract | Extract entities from a custom document that meets the [custom processor criteria](/document-ai/quotas). | [Create a custom extractor](/document-ai/docs/workbench/build-custom-processor) |\n| Extract | Extract entities from a specialized document type. | A [pretrained processor](/document-ai/docs/processors-list#specialized_processors) ([Up-train](/document-ai/docs/uptrain-pretrained-processor) to improve quality.) |\n| Classify | Classify documents. | [Create a Custom Classifier](/document-ai/docs/workbench/build-custom-classification-processor) |\n| Classify | Split documents. | [Create a Custom Splitter](/document-ai/docs/workbench/build-custom-splitter-processor) |\n\nThis diagram helps determine which processor works best for each use case.\n\nUse Document AI processors\n\nHere are the major steps to use Document AI to start processing documents:\n\n1. **Choose a processor** that is suitable for your use case.\n\n - For complete information on each processor, see the [Full processor and detail list](/document-ai/docs/processors-list).\n2. **Create a processor** using the Google Cloud console or the Document AI API.\n\n - Document AI creates a **prediction endpoint** where you can send your documents.\n\n - For detailed instructions, see [Creating a processor](/document-ai/docs/create-processor).\n\n3. **Train a processor** with train and test data from scratch, or uptrain a new (pretrained) processor version on top of an existing one.\n\n - For detailed instructions, see [Train processor](/document-ai/docs/workbench/train-processor).\n4. **Send your documents** for processing.\n\n - Document AI processes the documents and returns one or more [`Document`](/document-ai/docs/reference/rest/v1/Document) objects, which contain the extracted, structured information.\n\n - For detailed instructions, see [Sending a processing request](/document-ai/docs/send-request) and [Handle the processing response](/document-ai/docs/handle-response)."]]