In diesem Dokument werden die grundlegenden Konzepte der Verwendung von Document AI erläutert. Lesen Sie diese Seite, bevor Sie mit anderen Dokumenten oder Kurzanleitungen fortfahren.
Workflows zur Dokumentverarbeitung automatisieren
Unternehmen auf der ganzen Welt sind stark auf Dokumente angewiesen, um Informationen zu speichern und zu vermitteln. Diese Informationen müssen oft digitalisiert werden, damit sie nützlich sind. Dies geschieht jedoch in der Regel durch zeitaufwendige, manuelle Prozesse.
Beispiel:
- Bücher für E-Reader digitalisieren
- Verarbeitung von medizinischen Aufnahmeformularen in Arztpraxen.
- Belege und Rechnungen für die Validierung von Spesenabrechnungen parsen.
- Identität anhand von Ausweisen authentifizieren
- Einkommensinformationen aus Steuerformularen extrahieren, um Kredite zu genehmigen.
- Verträge für wichtige Geschäftsvereinbarungen
Bei jedem dieser Workflows wird der Roh-Text aus Dokumenten abgerufen und dann der Text extrahiert, der den benötigten Daten (den Feldern oder Einheiten) entspricht. Jeder Dokumenttyp hat jedoch eine andere Struktur und ein anderes Layout. Das Muster der Felder variiert je nach Anwendungsfall.
Document AI-Komponenten
Document AI ist eine Plattform zur Verarbeitung und zum Verständnis von Dokumenten, die unstrukturierte Daten aus Dokumenten in strukturierte Daten (bestimmte Felder, geeignet für eine Datenbank) umwandelt, sodass sie leichter verständlich, analysierbar und aufnehmbar sind.
Document AI basiert auf Produkten in Vertex AI mit generativer KI, um Ihnen bei der Erstellung skalierbarer, cloudbasierter End-to-End-Anwendungen zur Dokumentenverarbeitung ohne spezielles Fachwissen im Bereich maschinelles Lernen zu helfen.
Mit Document AI haben Sie folgende Möglichkeiten:
- Dokumente digitalisieren: Mit OCR können Sie Text, Layout und verschiedene Add-ons wie die Erkennung der Bildqualität (für die Lesbarkeit) und die automatische Entzerrung erhalten.
- Extrahieren Sie Text- und Layoutinformationen aus Dokumentdateien und normalisieren Sie Entitäten.
- Schlüssel/Wert-Paare in strukturierten Formularen und regulären Tabellen identifizieren. Beispiel:
Name: Jill Smithist ein KVP. - Klassifizieren Sie Dokumenttypen, um nachgelagerte Prozesse wie Extraktion und Speicherung zu steuern.
- Dokumente nach Typ aufteilen und klassifizieren. Zum Beispiel eine PDF-Datei mit mehreren echten Dokumenten.
- Datasets für die Feinabstimmung und Modellevaluierungen vorbereiten – mit Funktionen wie automatische Kennzeichnung, Schemamanagement und Dataset-Management, z. B. Überprüfung von Dokumenten und Vorhersagen.
- In Produkte wie Cloud Storage, BigQuery und Vertex AI Search einbinden, um Dokumente und Metadaten zu speichern, zu durchsuchen, zu organisieren, zu verwalten und zu analysieren.
Dieses Diagramm veranschaulicht alle wichtigen Schritte der Dokumentverarbeitung, die von Document AI unterstützt werden, und wie sie miteinander verbunden werden können.
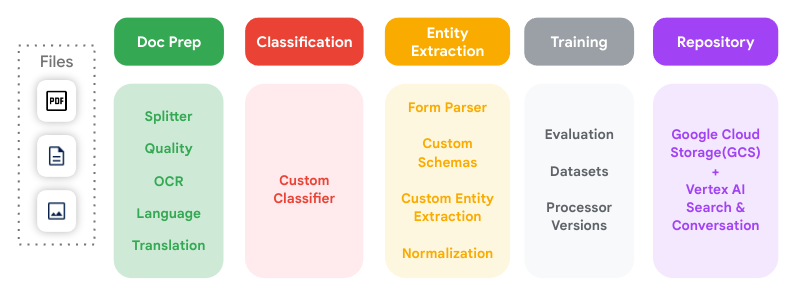
Prozessor
Ein Document AI-Prozessor befindet sich zwischen der Dokumentdatei und einem Modell für maschinelles Lernen, das Aktionen zur Dokumentverarbeitung und -analyse ausführt. Sie können zum Klassifizieren, Aufteilen, Parsen oder Analysieren eines Dokuments verwendet werden.
Für jedes Google Cloud Projekt müssen eigene Prozessorinstanzen erstellt werden.
Prozessoren lassen sich einer der folgenden Kategorien zuordnen:
- Digitalisieren: OCR.
- Extrahieren: Benutzerdefinierter Extrahierer, Formularparser, Layoutparser und vortrainierte Parser.
- Klassifizieren: Benutzerdefinierter Klassifikator und benutzerdefinierter Splitter.
Informationen zu allen verfügbaren Prozessortypen für Document AI finden Sie in der vollständigen Liste der Prozessoren und Details.
Welchen Prozessor sollte ich verwenden?
Im Folgenden finden Sie einige allgemeine Richtlinien, die Ihnen bei der Entscheidung helfen können, welcher Prozessortyp für eine bestimmte Anwendung verwendet werden soll:
| Kategorie | Anwendungsfall | Prozessortyp |
|---|---|---|
| Digitalisieren | Text- und Layoutinformationen aus Dokumenten extrahieren. | Enterprise Document OCR |
| Analysieren Sie die Qualität (Lesbarkeit) des gescannten Bildes eines Dokuments. | Enterprise Document OCR mit aktivierter Bildqualitätsanalyse | |
| Entitäten aus einem benutzerdefinierten Dokument extrahieren, das die Kriterien für benutzerdefinierte Prozessoren nicht erfüllt. | ||
| Extrahieren | Extrahieren Sie Tabellen oder Schlüssel-Wert-Paare aus einem strukturierten Formular in einem Dokument. | Formularparser |
| Extrahiert Elemente wie Text, Tabellen und Listen aus einem Dokument und gibt kontextbezogene Blöcke zurück. | Layout Parser | |
| Entitäten aus einem benutzerdefinierten Dokument extrahieren, das die Kriterien für benutzerdefinierte Prozessoren erfüllt. | Benutzerdefinierten Extraktor erstellen | |
| Entitäten aus einem speziellen Dokumenttyp extrahieren. | Ein vortrainierter Prozessor (weiter trainieren, um die Qualität zu verbessern) | |
| Klassifizieren | Dokumente klassifizieren. | Benutzerdefinierten Klassifikator erstellen |
| Dokumente aufteilen | Benutzerdefinierten Splitter erstellen |
Dieses Diagramm hilft Ihnen, den für die einzelnen Anwendungsfälle am besten geeigneten Prozessor zu ermitteln.
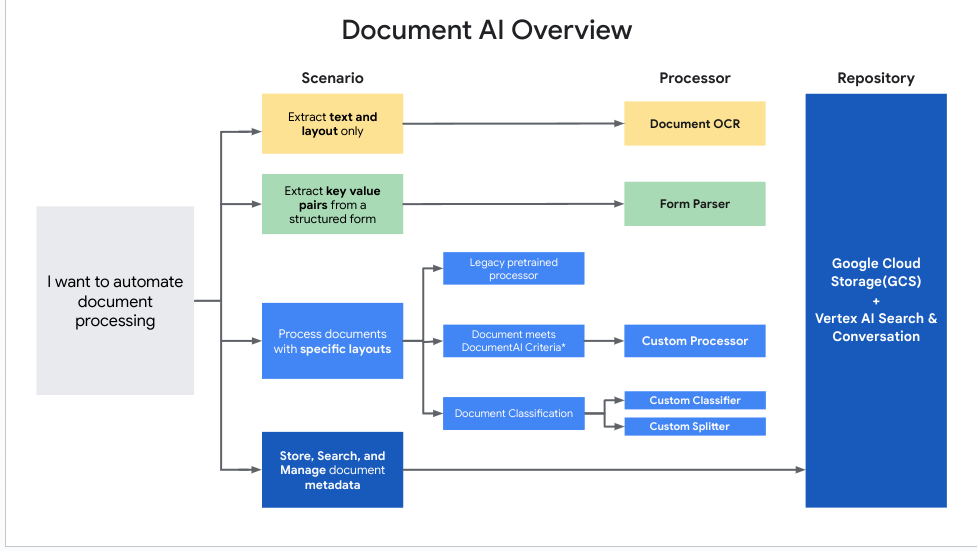
Document AI-Prozessoren verwenden
Im Folgenden finden Sie die wichtigsten Schritte, um mit Document AI Dokumente zu verarbeiten:
Wählen Sie einen Prozessor aus, der für Ihren Anwendungsfall geeignet ist.
Prozessor erstellen mit der Google Cloud -Konsole oder der Document AI API.
Document AI erstellt einen Vorhersageendpunkt, an den Sie Ihre Dokumente senden können.
Eine ausführliche Anleitung finden Sie unter Prozessor erstellen.
Prozessor trainieren: Sie können einen Prozessor mit Trainings- und Testdaten von Grund auf trainieren oder eine neue (vortrainierte) Prozessorversion auf Basis einer vorhandenen weiter trainieren.
- Eine ausführliche Anleitung finden Sie unter Prozessor trainieren.
Senden Sie Ihre Dokumente zur Bearbeitung.
Document AI verarbeitet die Dokumente und gibt ein oder mehrere
Document-Objekte zurück, die die extrahierten, strukturierten Informationen enthalten.Eine ausführliche Anleitung finden Sie unter Verarbeitungsanfrage senden und Verarbeitungsantwort verarbeiten.