Ce document est un guide présentant les concepts fondamentaux de l'utilisation de Document AI. Nous vous conseillons d'en prendre connaissance avant de passer à d'autres documents ou aux guides de démarrage rapide.
Automatiser les workflows de traitement des documents
Les entreprises du monde entier s'appuient fortement sur les documents pour stocker et transmettre des informations. Ces informations doivent souvent être numérisées pour être utiles. Toutefois, cela se fait généralement par le biais de processus manuels qui prennent beaucoup de temps.
Exemple :
- Numérisation de livres pour les liseuses
- Traitement des formulaires médicaux dans les cabinets médicaux.
- Analyse des reçus et des factures pour valider les notes de frais.
- Authentifier l'identité à l'aide de pièces d'identité.
- Extraire des informations sur les revenus à partir de formulaires fiscaux pour approuver des prêts.
- Comprendre les contrats pour les conditions clés des accords commerciaux.
Chacun de ces workflows implique d'obtenir le texte brut des documents, puis d'extraire le texte spécifique qui correspond aux données nécessaires (les champs ou les entités). Toutefois, chaque type de document possède une structure et une mise en page différentes, et le modèle de champs varie en fonction du cas d'utilisation spécifique.
Composants de Document AI
Document AI est une plate-forme de traitement et de compréhension de documents qui convertit les données non structurées des documents en données structurées (champs spécifiques adaptés à une base de données) afin d'en faciliter la compréhension, l'analyse et l'utilisation.
Document AI s'appuie sur des produits Vertex AI avec l'IA générative pour vous aider à créer des applications de traitement de documents évolutives, de bout en bout et basées dans le cloud, sans expertise spécialisée en machine learning.
Document AI vous permet d'effectuer les opérations suivantes :
- Numérisez des documents à l'aide de l'OCR pour obtenir du texte, une mise en page et divers modules complémentaires tels que la détection de la qualité des images (pour la lisibilité) et le redressement (entièrement automatique).
- Extrayez le texte et les informations de mise en page des fichiers de documents, et normalisez les entités.
- Identifier les paires clé-valeur dans les formulaires structurés et les tableaux standards. Par exemple,
Name: Jill Smithest une paire clé/valeur. - Classifiez les types de documents pour piloter les processus en aval tels que l'extraction et le stockage.
- Séparez et classez les documents par type. Par exemple, un fichier PDF contenant plusieurs documents réels.
- Préparez les ensembles de données à utiliser pour l'affinage et les évaluations de modèles à l'aide des fonctionnalités d'étiquetage automatique, de gestion des schémas et de gestion des ensembles de données, telles que l'examen des documents et des prédictions.
- Intégrez-le à des produits comme Cloud Storage, BigQuery et Vertex AI Search pour vous aider à stocker, rechercher, organiser, gérer et analyser des documents et des métadonnées.
Ce schéma illustre toutes les étapes clés du traitement des documents prises en charge par Document AI et la façon dont elles peuvent être interconnectées.
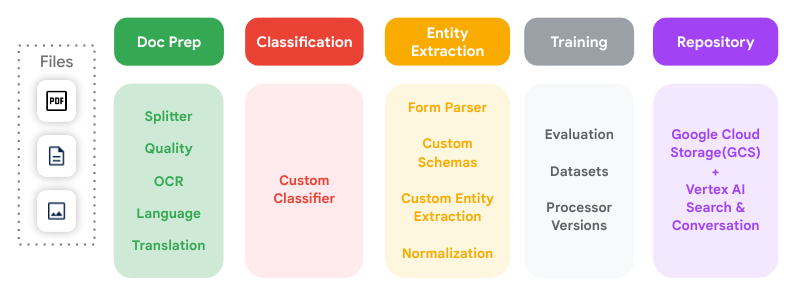
Processeur
Un processeur Document AI se trouve entre le fichier de document et un modèle de machine learning qui effectue des actions de traitement et de compréhension des documents. Ils peuvent être utilisés pour classer, fractionner, analyser ou parser un document.
Chaque projet Google Cloud doit créer ses propres instances de processeur.
Les sous-traitants appartiennent à l'une des catégories suivantes :
- Numériser : OCR.
- Extraire : extracteur personnalisé, analyseur de formulaires, analyseur de mise en page et analyseurs préentraînés.
- Classer : classificateur et séparateur personnalisés.
Pour en savoir plus sur tous les types de processeurs disponibles pour Document AI, consultez la liste complète des processeurs et des détails.
Quel processeur dois-je utiliser ?
Pour choisir le type de processeur à utiliser pour une application spécifique, voici quelques consignes générales :
| Catégorie | Cas d'utilisation | Type de processeur |
|---|---|---|
| Numériser | Extraire le texte et les informations de mise en page des documents. | Enterprise Document OCR |
| Analysez la qualité (lisibilité) de l'image numérisée d'un document. | Enterprise Document OCR avec l' analyse de la qualité des images activée | |
| Extrayez des entités à partir d'un document personnalisé qui ne répond pas aux critères du processeur personnalisé. | ||
| Extraction | Extrayez des tableaux ou des paires clé/valeur à partir d'un formulaire structuré dans un document. | Analyseur de formulaires |
| Extrayez des éléments tels que du texte, des tableaux et des listes dans un document, et renvoyez des segments contextuels. | Analyseur de mise en page | |
| Extrayez des entités à partir d'un document personnalisé qui répond aux critères du processeur personnalisé. | Créer un extracteur personnalisé | |
| Extraire des entités à partir d'un type de document spécialisé. | Un processeur pré-entraîné (surentraîné pour améliorer la qualité) | |
| Classification | classer des documents ; | Créer un classificateur personnalisé |
| Diviser des documents | Créer un séparateur personnalisé |
Ce schéma vous aide à déterminer le processeur le mieux adapté à chaque cas d'utilisation.
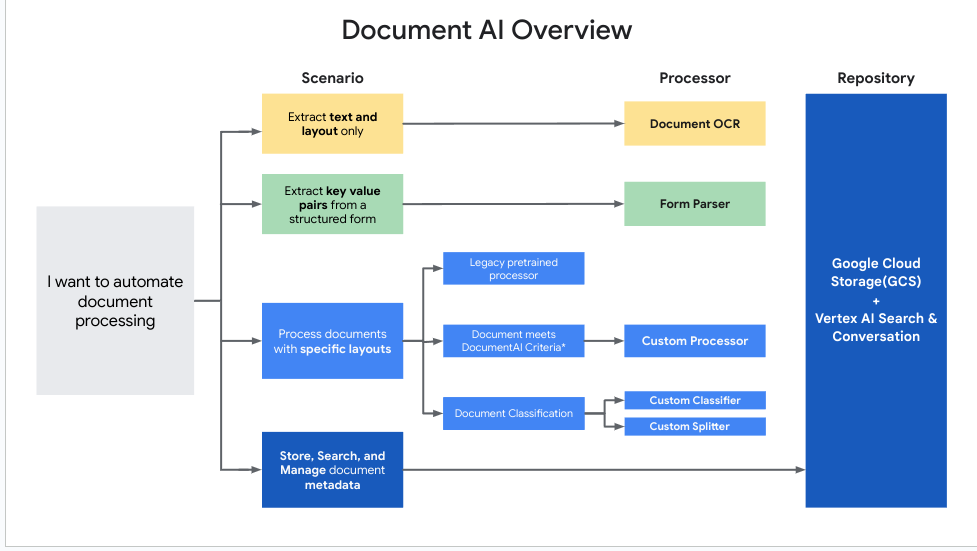
Utiliser les processeurs Document AI
Voici les principales étapes à suivre pour commencer à traiter des documents avec Document AI :
Choisissez un processeur adapté à votre cas d'utilisation.
- Pour obtenir des informations complètes sur chaque processeur, consultez la liste complète des processeurs et des détails.
Créez un processeur à l'aide de la console Google Cloud ou de l'API Document AI.
Document AI crée un point de terminaison de prédiction où vous pouvez envoyer vos documents.
Pour obtenir des instructions détaillées, consultez Créer un processeur.
Entraînez un processeur avec des données d'entraînement et de test à partir de zéro, ou surentraînez une nouvelle version (préentraînée) du processeur sur une version existante.
- Pour obtenir des instructions détaillées, consultez Processeur Train.
Envoyez vos documents pour qu'ils soient traités.
Document AI traite les documents et renvoie un ou plusieurs objets
Document, qui contiennent les informations structurées extraites.Pour obtenir des instructions détaillées, consultez Envoyer une demande de traitement et Gérer la réponse de traitement.