本文档介绍了使用 Document AI 的基本概念。您应先阅读本页面上的内容,然后再参阅其他文档或快速入门。
自动执行文档处理工作流
世界各地的企业都非常依赖文档来存储和传达信息。这些信息通常需要数字化才能发挥作用。不过,这通常需要通过耗时的手动流程来完成。
例如:
- 将图书数字化,以便在电子阅读器上阅读。
- 在诊所处理医疗信息收集表单。
- 解析收据和发票以验证费用报告。
- 基于身份证件验证身份。
- 从税务表单中提取收入信息,以审批贷款。
- 了解关键业务协议条款的合同。
这些工作流程都涉及从文档中获取原始文本,然后从中提取与所需数据(字段或实体)对应的特定文本。不过,每种文档类型的结构和布局都不同,字段模式也会因具体使用情形而异。
Document AI 组件
Document AI 是一个文档处理和理解平台,可从文档中获取非结构化数据并将其转换为结构化数据(适合数据库的特定字段),使数据更易于理解、分析和使用。
Document AI 基于 Vertex AI 中的产品构建,并利用生成式 AI 帮助您创建可伸缩的端到端云端文档处理应用,而无需具备专业的机器学习知识。
借助 Document AI,您可以:
- 使用 OCR 将文档数字化,以获取文本、布局和各种插件,例如图像质量检测(用于提高可读性)和倾斜校正(完全自动)。
- 从文档文件中提取文本和布局信息,并对实体进行归一化处理。
- 识别结构化表单和常规表格中的键值对 (kvp)。例如:
Name: Jill Smith是一个 KVP。 - 对文档类型进行分类,以驱动提取和存储等下游流程。
- 按类型拆分和分类文档。例如,包含多个真实文档的 PDF 文件。
- 使用自动标记、架构管理和数据集管理功能(例如文档和预测审核)准备数据集,以便在微调和模型评估中使用。
- 将其与产品(例如 Cloud Storage、BigQuery 和 Vertex AI Search)集成,以帮助您存储、搜索、整理、管理和分析文档及元数据。
此图展示了 Document AI 支持的所有关键文档处理步骤,以及这些步骤如何彼此关联。
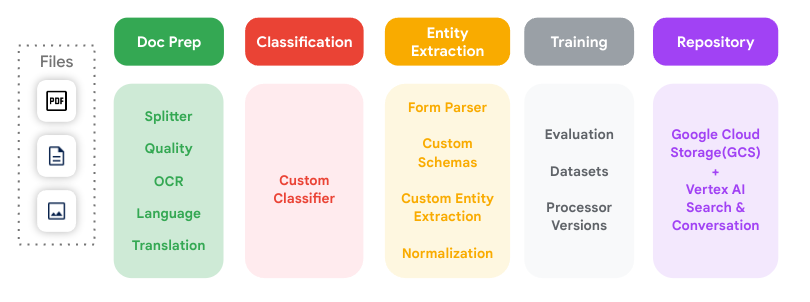
处理器
Document AI 处理器位于文档文件与执行文档处理和理解操作的机器学习模型之间。它们可用于对文档进行分类、拆分、解析或分析。
每个 Google Cloud 项目都需要创建自己的处理器实例。
处理器分为以下几类:
- 数字化:OCR。
- 提取:自定义提取器、表单解析器、布局解析器和预训练解析器。
- 分类:自定义分类器和自定义拆分器。
如需了解 Document AI 的所有可用处理器类型,请参阅处理器和详细信息完整列表。
我应该使用哪个处理器?
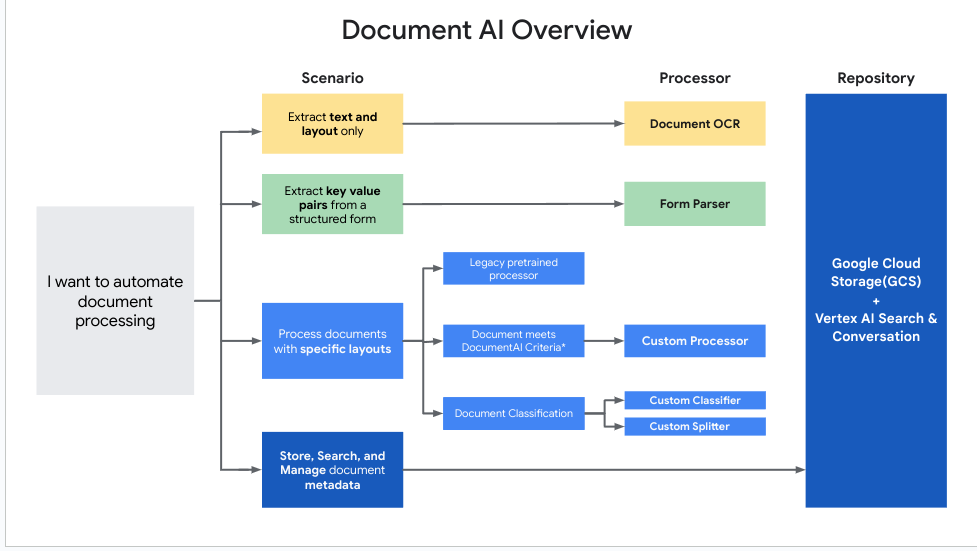
如需确定要为特定应用使用哪种处理器类型,请参考以下一般准则:
| 类别 | 用例 | 处理器类型 |
|---|---|---|
| 数字化 | 从文档中提取文本和布局信息。 | Enterprise Document OCR |
| 分析文档的扫描图片质量(可读性)。 | 启用 图像质量分析 功能的 Enterprise Document OCR | |
| 从不符合自定义处理器条件的自定义文档中提取实体。 | ||
| 提取 | 从文档中的结构化表单中提取表格或键值对。 | 表单解析器 |
| 提取文档中的文本、表格和列表等元素,并返回具有上下文意识的块。 | 布局解析器 | |
| 从符合自定义处理器条件的自定义文档中提取实体。 | 创建自定义提取器 | |
| 从专业文档类型中提取实体。 | 预训练处理器(追加训练以提高质量)。 | |
| 分类 | 对文档进行分类。 | 创建自定义分类器 |
| 拆分文档。 | 创建自定义拆分器 |
此图表有助于确定哪种处理器最适合每种使用场景。
使用 Document AI 处理器
以下是使用 Document AI 开始处理文档的主要步骤:
选择适合您的使用场景的处理器。
- 如需详细了解每款处理器,请参阅处理器及其详情的完整列表。
使用 Google Cloud 控制台或 Document AI API 创建处理器。
Document AI 会创建一个预测端点,您可以在其中发送文档。
如需查看详细说明,请参阅创建处理器。
训练处理器:从头开始使用训练数据和测试数据训练处理器,或基于现有处理器追加训练新的(预训练)处理器版本。
- 如需详细说明,请参阅训练处理器。
发送您的证件以供处理。