You can use Enterprise Document OCR as part of Document AI to detect and extract text and layout information from various documents. With configurable features, you can tailor the system to meet specific document-processing requirements.
Overview
You can use Enterprise Document OCR for tasks such as data entry based on algorithms or machine learning and improving and verifying data accuracy. You can also use Enterprise Document OCR to handle tasks like the following:
- Digitizing text: Extract text and layout data from documents for search, rules-based, document-processing pipelines, or custom-model creation.
- Using large language model applications: Use LLMs' contextual understanding and OCR's text and layout extraction capabilities to automate questions and answers. Unlock insights from data, and streamline workflows.
- Archiving: Digitize paper documents into machine-readable text to improve document accessibility.
Choosing the best OCR for your use case
| Solution | Product | Description | Use case |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Specialized model for document use cases. Advanced features include image-quality score, language hints, and rotation correction. | Recommended when extracting text from documents. Use cases include PDFs, scanned documents as images, or Microsoft DocX files. |
| Document AI | OCR add ons | Premium features for specific requirements. Only compatible with Enterprise Document OCR version 2.0 and later. | Need to detect and recognize math formulas, receive font-style information, or enable checkbox extraction. |
| Cloud Vision API | Text detection | Globally available REST API based on Google Cloud standard OCR model. Default quota of 1,800 requests per minute. | General text-extraction use cases that require low latency and high capacity. |
| Cloud Vision | OCR Google Distributed Cloud (Deprecated) | Google Cloud Marketplace application that can be deployed as a container to any GKE cluster using GKE Enterprise. | To meet data residency or compliance requirements. |
Detection and extraction
Enterprise Document OCR can detect blocks, paragraphs, lines, words, and symbols from PDFs and images, as well as deskew documents for better accuracy.
Supported layout detection and extraction attributes:
| Printed text | Handwriting | Paragraph | Block | Line | Word | Symbol-level | Page number |
|---|---|---|---|---|---|---|---|
| Default | Default | Default | Default | Default | Default | Configurable | Default |
Configurable Enterprise Document OCR features include the following:
Extract embedded or native text from digital PDFs: This feature extracts text and symbols exactly as they appear in the source documents, even for rotated texts, extreme font sizes or styles, and partially hidden text.
Rotation correction: Use Enterprise Document OCR to preprocess document images to correct rotation issues that can affect extraction quality or processing.
Image-quality score: Receive quality metrics that can help with document routing. Image-quality score provides you with page-level quality metrics in eight dimensions, including blurriness, the presence of smaller-than-usual fonts, and glare.
Specify page range: Specifies the range of the pages in an input document for OCR. This saves the spending and processing time over unneeded pages.
Language detection: Detects the languages used in the extracted texts.
Language and handwriting hints: Improve accuracy by providing the OCR model a language or handwriting hint based on the known characteristics of your dataset.
To learn how to enable OCR configurations, see Enable OCR configurations.
OCR add ons
Enterprise Document OCR offers optional analysis capabilities which can be enabled on individual processing requests as needed.
The following add-on capabilities are available for the Stable
pretrained-ocr-v2.0-2023-06-02 and pretrained-ocr-v2.1-2024-08-07 versions,
and Release Candidate pretrained-ocr-v2.1.1-2025-01-31 version.
- Math OCR: Identify and extract formulas from documents in LaTeX format.
- Checkbox extraction: Detect checkboxes and extract their status (marked/unmarked) in Enterprise Document OCR response.
- Font style detection: Identify word-level font properties including font type, font style, handwriting, weight, and color.
To learn how to enable the listed add-ons, see Enable OCR add ons.
Supported file formats
Enterprise Document OCR supports PDF, GIF, TIFF, JPEG, PNG, BMP, and WebP file formats. For more information, see Supported files.
Enterprise Document OCR also supports DocX files up to 15 pages in sync and 30 pages in async. DocX support is in private preview. To request access, submit the DocX Support Request Form .
Advanced versioning
Advanced versioning is in Preview. Upgrades to the underlying AI/ML OCR models might lead to changes in OCR behavior. If strict consistency is required, use a frozen model version to pin behavior to a legacy OCR model for up to 18 months. This ensures the same image to OCR function result. See the table about processor versions.
Processor versions
The following processor versions are compatible with this feature. For more information, see Managing processor versions.
| Version ID | Release channel | Description |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stable | Frozen model version of v1.0: Model files, configurations, and binaries of a version snapshot frozen in a container image for up to 18 months. |
pretrained-ocr-v2.0-2023-06-02 |
Stable | Production-ready model specialized for document use cases. Includes access to all OCR add-ons. |
pretrained-ocr-v2.1-2024-08-07 |
Stable | The main areas of improvement for v2.1 are: better printed text recognition, more precise checkbox detection and more accurate reading order. |
pretrained-ocr-v2.1.1-2025-01-31 |
Release candidate | v2.1.1 is similar to V2.1, and is available in all regions except: US, EU, and asia-southeast1. |
Use Enterprise Document OCR to process documents
This quickstart introduces you to Enterprise Document OCR. It shows you how to optimize document OCR results for your workflow by enabling or disabling any of the available OCR configurations.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Create an Enterprise Document OCR processor
First, create an Enterprise Document OCR processor. For more information, see creating and managing processors.
OCR configurations
All OCR configurations can be enabled by setting the respective fields in ProcessOptions.ocrConfig in the ProcessDocumentRequest or BatchProcessDocumentsRequest.
For more information, refer to Send a processing request.
Image-quality analysis
Intelligent document-quality analysis uses machine learning to perform quality assessment of a document based on the readability of its content.
This quality assessment is returned as a quality score [0, 1], where 1 means perfect quality.
If the quality score detected is lower than 0.5, a list of negative quality reasons (sorted by the likelihood) is also returned.
Likelihood greater than 0.5 is considered a positive detection.
If the document is considered to be defective, the API returns the following eight document defect types:
quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare
There are some limitations with the current document-quality analysis:
- It can return false positive detections with digital documents with no defects. The feature is best used on scanned or photographed documents.
Glare defects are local. Their presence might not hinder overall document readability.
Input
Enable by setting ProcessOptions.ocrConfig.enableImageQualityScores to true in the processing request.
This additional feature adds latency comparable to OCR processing to the process call.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Output
The defect detection results appear in Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Refer to Sample processor output for full output examples.
Language hints
The OCR processor supports language hints that you define to improve OCR engine performance. Applying a language hint allows for OCR to optimize for a selected language instead of an inferred language.
Input
Enable by setting ProcessOptions.ocrConfig.hints[].languageHints[] with a list of BCP-47 language codes.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Refer to Sample processor output for full output examples.
Symbol detection
Populate data at the symbol (or individual letter) level in the document response.
Input
Enable by setting ProcessOptions.ocrConfig.enableSymbol to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Output
If this feature is enabled, the field Document.pages[].symbols[] is populated.
Refer to Sample processor output for full output examples.
Built-in PDF parsing
Extract embedded text from digital PDF files. When enabled, if there is digital text, the built-in digital PDF model is automatically used. If there is non-digital text, the optical OCR model is automatically used. The user receives both text results merged together.
Input
Enable by setting ProcessOptions.ocrConfig.enableNativePdfParsing to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Character-in-the-box detection
By default, Enterprise Document OCR has a detector enabled to improve text-extraction quality of characters that sit within a box. Here is an example:

If you're experiencing OCR quality issues with characters inside boxes, you can disable it.
Input
Disable by setting ProcessOptions.ocrConfig.disableCharacterBoxesDetection to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Legacy layout
If you require a heuristics layout-detection algorithm, you can enable legacy layout, which serves as an alternative to the current ML-based, layout-detection algorithm. This is not the recommended configuration. Customers can choose the best suitable layout algorithm based on their document workflow.
Input
Enable by setting ProcessOptions.ocrConfig.advancedOcrOptions to ["legacy_layout"] in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Specify a page range
By default, OCR extracts text and layout information from all pages in the documents. You can select specific page numbers or page ranges and only extract text from those pages.
There are three ways to configure this in ProcessOptions:
- To only process the second and fifth page:
{
"individualPageSelector": {"pages": [2, 5]}
}
- To only process the first three pages:
{
"fromStart": 3
}
- To only process the last four pages:
{
"fromEnd": 4
}
In the response, each Document.pages[].pageNumber corresponds the same pages specified in the request.
OCR add ons uses
These Enterprise Document OCR optional analysis capabilities can be enabled on individual processing requests as needed.
Math OCR
Math OCR detects, recognizes, and extracts formulas, such as mathematical equations represented as LaTeX along with bounding box coordinates.
Here is an example of LaTeX representation:
Image detected
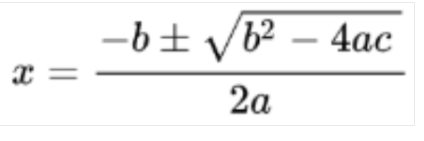
Conversion to LaTeX
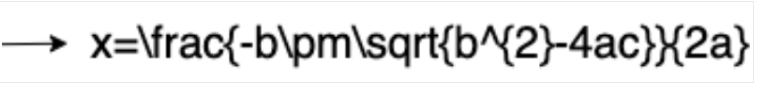
Input
Enable by setting ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Output
The Math OCR output appears in Document.pages[].visualElements[] with "type": "math_formula".

"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Selection mark extraction
If enabled, the model attempts to extract all checkboxes and radio buttons in the document, along with bounding box coordinates.
Input
Enable by setting ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Output
The checkbox output appears in Document.pages[].visualElements[] with "type": "unfilled_checkbox" or "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Font-style detection
With font-style detection enabled, Enterprise Document OCR extracts font attributes, which can be used for better post-processing.
At the token (word) level, the following attributes are detected:
- Handwriting detection
- Font style
- Font size
- Font type
- Font color
- Font weight
- Letter spacing
- Bold
- Italic
- Underlined
- Text color (RGBa)
Background color (RGBa)
Input
Enable by setting ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo to true in the processing request.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Output
The font-style output appears in Document.pages[].tokens[].styleInfo with type StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Convert document objects to Vision AI API format
The Document AI Toolbox includes a tool that converts the Document AI API Document format to the Vision AI AnnotateFileResponse format, enabling users to compare the responses between the document OCR processor and Vision AI API. Here is some sample code.
Known discrepancies between the Vision AI API response and Document AI API response and converter:
- The Vision AI API response populates only
verticesfor image requests, and populates onlynormalized_verticesfor PDF requests. The Document AI response and the converter populates bothverticesandnormalized_vertices. - The Vision AI API response populates the
detected_breakin the last symbol of the word. The Document AI API response and the converter populatesdetected_breakin the word and the last symbol of the word. - The Vision AI API response always populates symbols fields. By default, the Document AI response does not populate symbols fields. To make sure the Document AI response and the converter get symbols fields populated, set the
enable_symbolfeature as detailed.
Code samples
The following code samples demonstrate how to send a processing request enabling OCR configurations and add ons, then read and print the fields to the terminal:
REST
Before using any of the request data, make the following replacements:
- LOCATION: your processor's location, for example:
us- United Stateseu- European Union
- PROJECT_ID: Your Google Cloud project ID.
- PROCESSOR_ID: the ID of your custom processor.
- PROCESSOR_VERSION: the processor version identifier. Refer to Select a processor version for more information. For example:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: A boolean to disable human review (Supported by Human-in-the-Loop processors only.)
true- skips human reviewfalse- enables human review (default)
- MIME_TYPE†: One of the valid MIME type options.
- IMAGE_CONTENT†: One of the valid
Inline document content, represented as
a stream of bytes. For JSON representations, the base64
encoding (ASCII string) of your binary image data. This string should look similar to the
following string:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: Specifies which fields to include in the
Documentoutput. This is a comma-separated list of fully qualified names of fields inFieldMaskformat.- Example:
text,entities,pages.pageNumber
- Example:
- OCR configurations
- ENABLE_NATIVE_PDF_PARSING: (Boolean) Extracts embedded text from PDFs, if available.
- ENABLE_IMAGE_QUALITY_SCORES: (Boolean) Enables intelligent document quality scores.
- ENABLE_SYMBOL: (Boolean) Includes symbol (letter) OCR information.
- DISABLE_CHARACTER_BOXES_DETECTION: (Boolean) Turn off character box detector in OCR engine.
- LANGUAGE_HINTS: List of BCP-47 language codes to use for OCR.
- ADVANCED_OCR_OPTIONS: A list of advanced OCR options to further fine-tune OCR behavior. Current valid values are:
legacy_layout: a heuristics layout detection algorithm, which serves as an alternative to the current ML-based layout detection algorithm.
- Premium OCR add ons
- ENABLE_SELECTION_MARK_DETECTION: (Boolean) Turn on selection mark detector in OCR engine.
- COMPUTE_STYLE_INFO (Boolean) Turn on font identification model and return font style information.
- ENABLE_MATH_OCR: (Boolean) Turn on the model that can extract LaTeX math formulas.
- INDIVIDUAL_PAGES: A list of individual pages to process.
† This content can also be specified using base64-encoded content in the
inlineDocument object.
HTTP method and URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Request JSON body:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
If the request is successful, the server returns a 200 OK HTTP status code and the
response in JSON format. The response body contains an instance of
Document.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
What's next
- Review the processors list.
- Separate documents into readable chunks with Layout Parser.
- Create a custom classifier.