Es obligatorio usar un conjunto de datos etiquetado de documentos para entrenar, entrenar o evaluar una versión de procesador.
En esta página se describe cómo aplicar etiquetas desde el esquema de tu procesador a documentos importados en tu conjunto de datos.
En esta página se presupone que ya has creado un procesador que admite entrenamiento, entrenamiento adicional o evaluación. Si tu procesador es compatible, ahora verás la pestaña Entrenar en la consola Google Cloud . También se presupone que has creado un conjunto de datos, has importado documentos y has definido un esquema de procesador.
Nombres de los campos para la extracción con IA generativa
La forma en que se nombran los campos influye en la precisión con la que se extraen los campos mediante la IA generativa. Te recomendamos que sigas estas prácticas recomendadas al asignar nombres a los campos:
Asigna al campo el mismo nombre que se usa para describirlo en el documento: por ejemplo, si un documento tiene un campo descrito como
Employer Address, asigna al campo el nombreemployer_address. No uses abreviaturas comoemplr_addr.Actualmente, no se admiten espacios en los nombres de los campos: en lugar de usar espacios, usa
_. Por ejemplo,First Namese llamaríafirst_name.Iterar los nombres para mejorar la precisión: Document AI tiene una limitación que no permite cambiar los nombres de los campos. Para probar diferentes nombres, usa la herramienta para cambiar el nombre de la entidad para actualizar el nombre de la entidad antigua por uno más reciente en el conjunto de datos, importa el conjunto de datos, habilita las nuevas entidades en el procesador e inhabilita o elimina los campos existentes.
Aprendizaje sin ejemplos y con pocos ejemplos
Los modelos con Gemini tienen aprendizaje con cero ejemplos y con pocos ejemplos, lo que permite crear modelos de alto rendimiento con pocos datos de entrenamiento o sin ellos.
El aprendizaje sin ejemplos es un ejemplo de aprendizaje automático en el que un modelo preentrenado sin ningún entrenamiento adicional aprende a reconocer y clasificar clases y entidades que no ha encontrado antes durante las pruebas.
El aprendizaje con pocos ejemplos es un método en el que un modelo aprende a reconocer y clasificar nuevas clases y entidades con solo unos pocos ejemplos de entrenamiento por clase. Aprovecha los conocimientos de los modelos preentrenados en conjuntos de datos grandes y bien etiquetados para mejorar el rendimiento en tareas con pocos ejemplos.
El aprendizaje con pocos ejemplos resulta más eficaz cuando el conjunto de datos de entrenamiento está ordenado y etiquetado con cuidado. Normalmente, esto significa que el modelo debe tener al menos 10 ejemplos de prueba y 10 de entrenamiento para aprender.
Opciones de etiquetado
Estas son las opciones que tienes para etiquetar documentos:
Manual: etiqueta manualmente los documentos en la Google Cloud consola
Etiquetado automático: usa una versión de procesador para generar etiquetas.
Importar documentos preetiquetados: ahorra tiempo si ya tienes documentos etiquetados.
Etiquetar manualmente en la Google Cloud consola
En la pestaña Entrenar, selecciona un documento para abrir la herramienta de etiquetado.
En la lista de etiquetas de esquema situada en la parte izquierda de la herramienta de etiquetado, selecciona el símbolo "Añadir" para elegir la herramienta Recuadro delimitador, que te permite resaltar entidades en el documento y asignarlas a una etiqueta.
En la siguiente captura de pantalla, se han asignado etiquetas a los campos EMPL_SSN EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS, FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES y WAGES_TIPS_OTHER_COMP del documento.
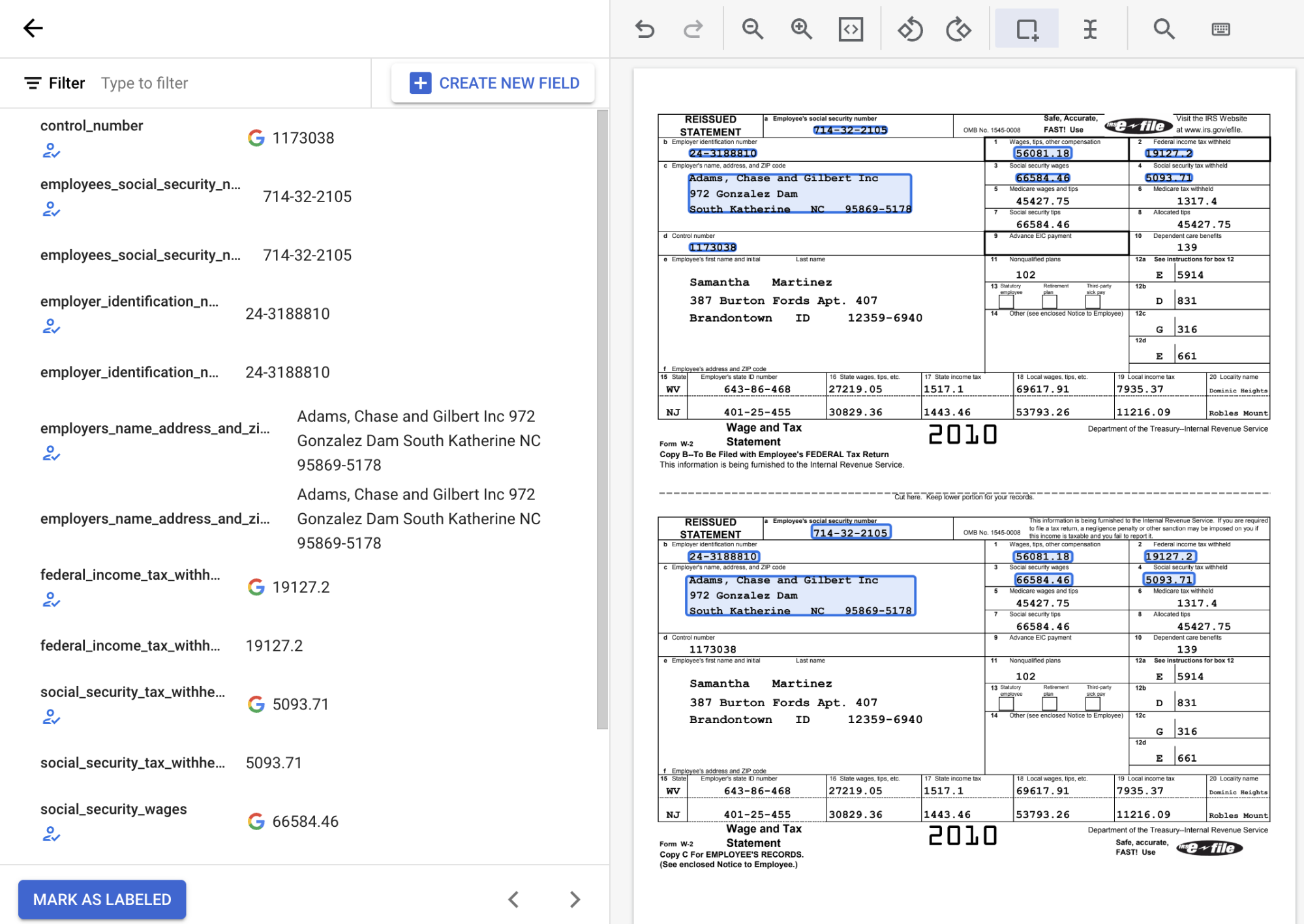
Cuando selecciones una entidad de casilla con la herramienta Contorno, selecciona solo la casilla y no el texto asociado. Asegúrate de que la casilla de la entidad que se muestra a la izquierda esté marcada o desmarcada según lo que aparezca en el documento.

Cuando etiquetes entidades principales y secundarias, no etiquetes las entidades principales. Las entidades superiores son solo contenedores de las entidades secundarias. Etiqueta solo las entidades secundarias. Las entidades principales se actualizan automáticamente.
Cuando etiquete entidades secundarias, etiquete la primera entidad secundaria y, a continuación, asocie las entidades secundarias relacionadas con esa línea. Te darás cuenta de esto en la segunda entidad secundaria la primera vez que etiquetes entidades de este tipo. Por ejemplo, en una factura, si etiquetas descripción, parece que es cualquier otra entidad. Sin embargo, si etiquetas cantidad a continuación, se te pedirá que elijas el elemento superior.
Repita este paso con cada línea de pedido seleccionando Nueva entidad principal para cada línea de pedido.
Las entidades padre-hijo se admiten en tablas con hasta tres niveles de anidación. Los modelos de base admiten tres niveles de campos (abuelo/a, padre/madre e hijo/a), por lo que las entidades secundarias pueden tener un nivel de elementos secundarios. Para obtener más información sobre la anidación, consulta Anidación de tres niveles.
Tablas rápidas
Cuando se etiqueta una tabla, puede ser tedioso etiquetar cada fila una y otra vez. Hay una herramienta muy útil que puede replicar la estructura de una entidad de fila. Ten en cuenta que esta función solo funciona en filas alineadas horizontalmente.
- Primero, etiqueta la primera fila como de costumbre.
A continuación, coloca el puntero sobre la entidad principal que representa la fila. Selecciona Añadir más filas. La fila se convierte en una plantilla para crear más filas.
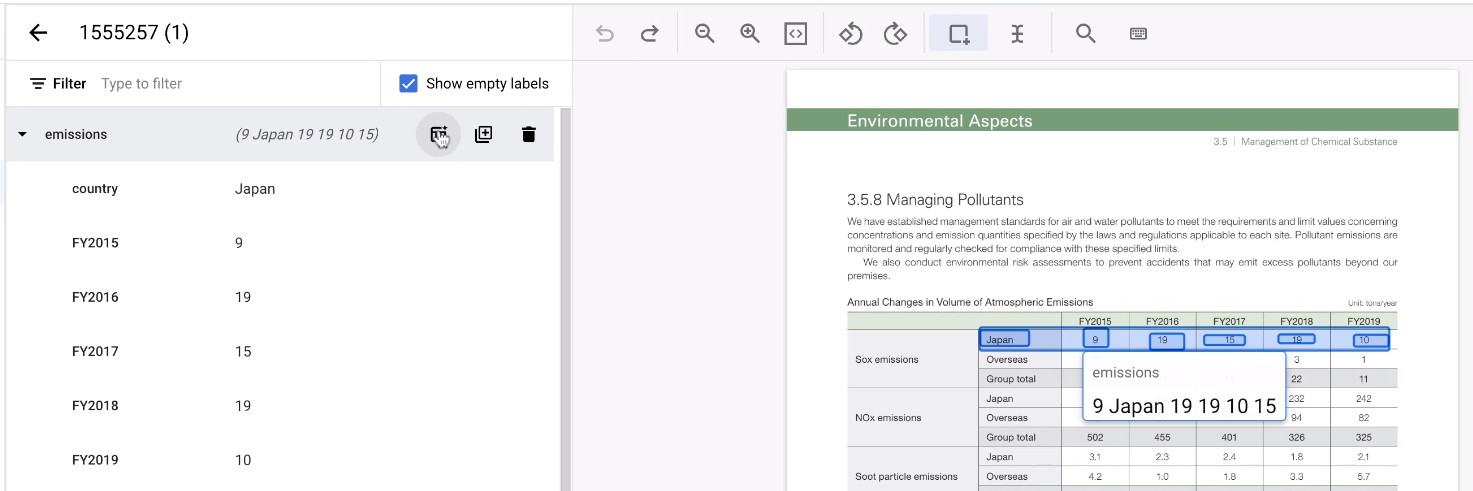
Selecciona el resto del área de la tabla.
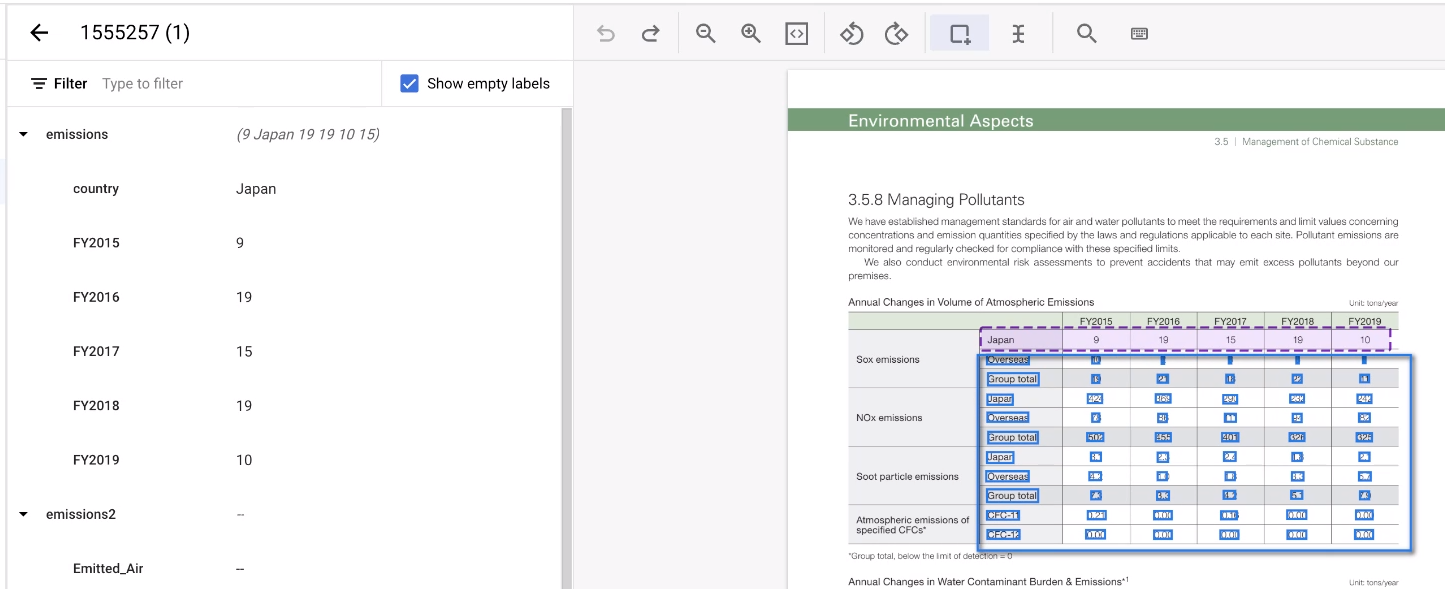
La herramienta adivina las anotaciones y suele funcionar. En las tablas que no pueda gestionar, anótelas manualmente.
Usar combinaciones de teclas en la consola
Para ver las combinaciones de teclas disponibles, selecciona el menú en la parte superior derecha de la consola de etiquetado. Muestra una lista de combinaciones de teclas, como se muestra en la siguiente tabla.
| Acción | Combinación de teclas |
|---|---|
| Aumentar | Alt + = (Opción + = en macOS) |
| Reducir | Alt + - (Opción + - en macOS) |
| Adaptar tamaño | Alt + 0 (Opción + 0 en macOS) |
| Desplazar para ampliar | Alt + Desplazamiento (Opción + Desplazamiento en macOS) |
| Panorámica | Desplazar |
| Desplazamiento invertido | Mayús + Desplazamiento |
| Arrastrar para mover | Espacio + arrastrar con el ratón |
| Deshacer | Ctrl + Z (Control + Z en macOS) |
| Rehacer | Ctrl + Mayús + Z (Control + Mayús + Z en macOS) |
Etiquetado automático
Si hay alguna disponible, puedes usar el modelo de tu versión para empezar a etiquetar.
El etiquetado automático se puede iniciar durante la importación. Todos los documentos se anotan con la versión del procesador especificada.
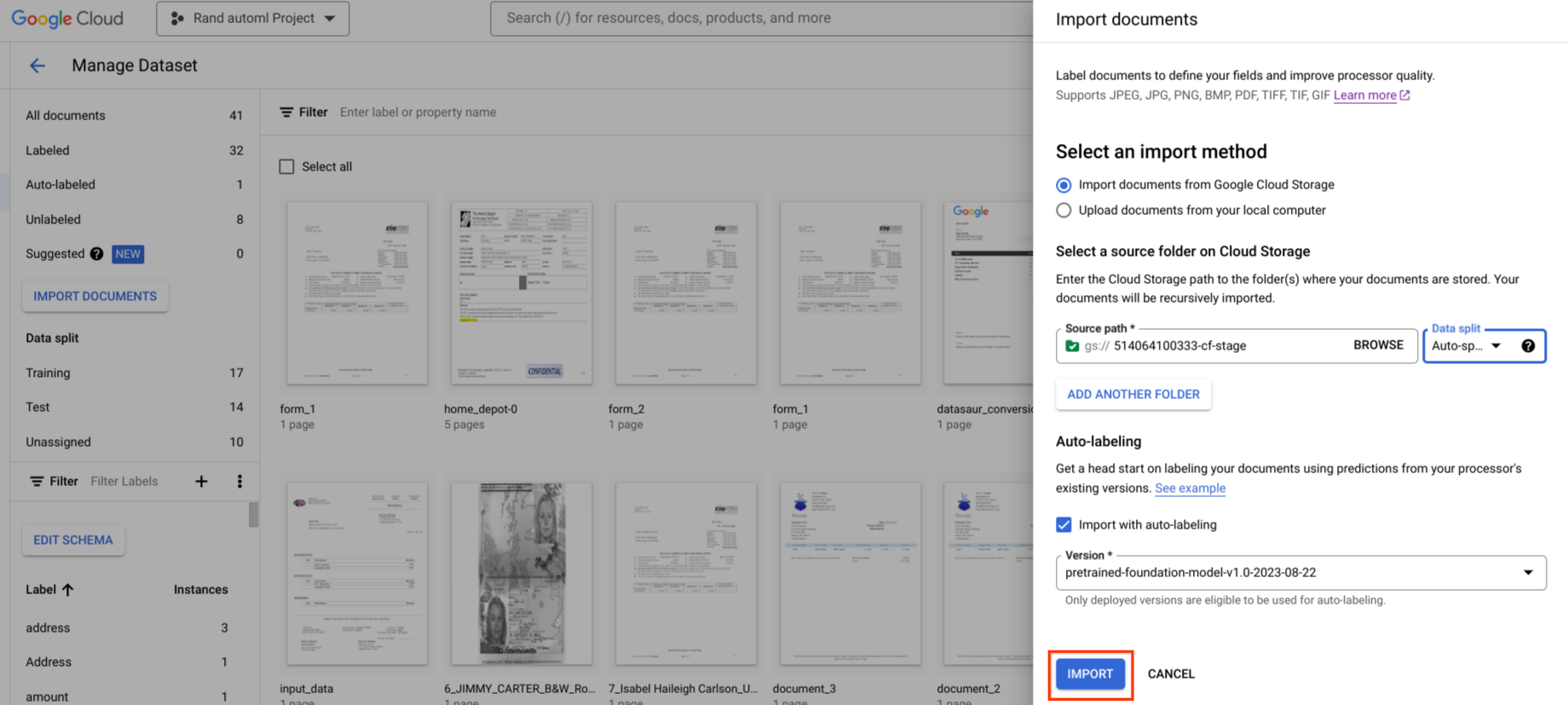
El etiquetado automático se puede iniciar después de importar documentos que no tengan etiquetas o que estén en la categoría de etiquetado automático. Todos los documentos seleccionados se anotan con la versión del procesador especificada.
No puedes entrenar ni volver a entrenar con documentos etiquetados automáticamente, ni usarlos en el conjunto de prueba, sin marcarlos como etiquetados. Revisa y corrige manualmente las anotaciones etiquetadas automáticamente y, a continuación, selecciona Marcar como etiquetado para guardar las correcciones. A continuación, puedes asignar los documentos según corresponda.
Importar documentos preetiquetados
Puedes importar archivos JSON Document. Si el entity del documento coincide con la etiqueta del esquema del procesador, el importador lo convierte en una instancia de etiqueta.entity Hay varias formas de obtener archivos de documento JSON:
Exportar un conjunto de datos de otro procesador. Consulta Exportar conjunto de datos.
Enviar una solicitud de tratamiento a un encargado del tratamiento que ya esté registrado.
Usa el kit de herramientas de importación para convertir etiquetas de otro sistema, por ejemplo, etiquetas en formato CSV, a documentos JSON.
Prácticas recomendadas para etiquetar documentos
Es necesario etiquetar los datos de forma coherente para entrenar un procesador de alta calidad. Te recomendamos que hagas lo siguiente:
Crea instrucciones de etiquetado: tus instrucciones deben incluir ejemplos de casos habituales y extremos. A continuación, te ofrecemos algunos consejos:
- Explica qué campos deben anotarse y cómo hacerlo para que el etiquetado sea coherente. Por ejemplo, al etiquetar "amount", especifica si se debe etiquetar el símbolo de la moneda. Si las etiquetas no son coherentes, la calidad del procesador se reduce.
- Etiqueta todas las menciones de una entidad, aunque el tipo de etiqueta sea
REQUIRED_ONCEoOPTIONAL_ONCE. Por ejemplo, siinvoice_idaparece dos veces en el documento, etiqueta todas las instancias. - Por lo general, se recomienda etiquetar primero con la herramienta de cuadro delimitador predeterminada. Si no funciona, usa la herramienta de selección de texto.
- Si el valor de la etiqueta no se detecta correctamente mediante OCR, no lo corrijas manualmente. De lo contrario, no se podría usar para fines de formación.
A continuación, se incluyen algunas instrucciones de etiquetado de ejemplo:
- Analizador de extractos bancarios
- Analizador de utilidades
- Analizador de nóminas
- Analizador de gastos
- Analizador de facturas
- Forma a los anotadores: asegúrate de que los anotadores entiendan y puedan seguir las directrices sin cometer errores sistemáticos. Una forma de conseguirlo es pedir a diferentes participantes que anoten el mismo conjunto de documentos. El entrenador puede comprobar la calidad del trabajo de anotación de cada participante. Es posible que tengas que repetir este proceso hasta que los participantes alcancen un nivel de precisión de referencia.
- Revisiones iniciales: los primeros documentos (unos 10) etiquetados para un caso práctico por un nuevo etiquetador deben revisarse antes de etiquetar un gran número de documentos para evitar que se cometan muchos errores que haya que corregir.
- Revisiones de la calidad de las anotaciones: dada la laboriosa naturaleza de las anotaciones, incluso los anotadores formados pueden cometer errores. Recomendamos que las anotaciones las revise al menos otro anotador formado.
Añadir una petición de descripción
Cuando añadas etiquetas al esquema en el extractor personalizado y el clasificador personalizado, puedes añadir una descripción para la etiqueta. Esto ayuda a entrenar al procesador proporcionándole una petición con la que identificar la etiqueta. Puedes probar con ligeras variaciones para comprobar la calidad de las respuestas. Por ejemplo, "importe total", "importe total de la factura" o "importe total de la factura".
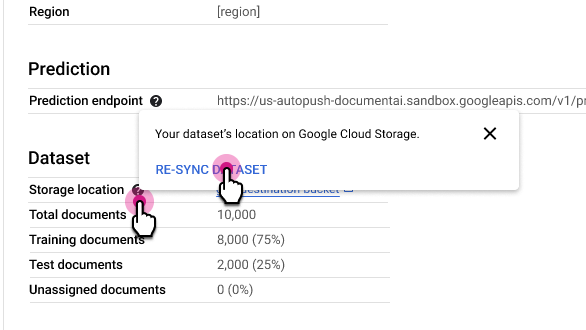
Resincronizar conjunto de datos
La resincronización mantiene la coherencia entre la carpeta de Cloud Storage de tu conjunto de datos y el índice interno de metadatos de Document AI. Esto resulta útil si has hecho cambios por error en la carpeta de Cloud Storage y quieres sincronizar los datos.
Para volver a sincronizar:
En la pestaña Detalles del procesador, junto a la fila Ubicación de almacenamiento, selecciona y, a continuación, Resincronizar conjunto de datos.
Notas sobre el uso:
- Si eliminas un documento de la carpeta de Cloud Storage, al volver a sincronizar se quitará del conjunto de datos.
- Si añades un documento a la carpeta de Cloud Storage, la resincronización no lo añade al conjunto de datos. Para añadir documentos, impórtalos.
- Si modificas las etiquetas de los documentos en la carpeta de Cloud Storage, al volver a sincronizar se actualizarán las etiquetas de los documentos en el conjunto de datos.
Migrar un conjunto de datos
La importación y la exportación te permiten mover todos los documentos de un conjunto de datos de un procesador a otro. Esto puede ser útil si tienes procesadores en diferentes regiones o Google Cloud proyectos, si tienes diferentes procesadores para las fases de desarrollo y producción, o para el consumo general sin conexión.
Ten en cuenta que solo se exportan los documentos y sus etiquetas. Los metadatos del conjunto de datos, como el esquema del procesador, las asignaciones de documentos (entrenamiento, prueba o sin asignar) y el estado del etiquetado de documentos (etiquetado, sin etiquetar o etiquetado automáticamente), no se exportan.
Copiar e importar el conjunto de datos y, a continuación, entrenar el procesador de destino no es exactamente lo mismo que entrenar el procesador de origen. Esto se debe a que se usan valores aleatorios al principio del proceso de entrenamiento. Usa la importProcessorVersion API
para importar y migrar el mismo modelo entre proyectos. Esta es la práctica recomendada para migrar procesadores a entornos superiores (por ejemplo, de desarrollo a preproducción y a producción) si las políticas lo permiten.
Exportar conjunto de datos
Para exportar todos los documentos como archivos JSON
Document a una carpeta de Cloud Storage,
selecciona Exportar conjunto de datos.
Hay algunos aspectos importantes que se deben tener en cuenta:
Durante la exportación, se crean tres subcarpetas: Test, Train y Unassigned. Tus documentos se colocarán en esas subcarpetas según corresponda.
El estado de etiquetado de un documento no se exporta. Si importas los documentos más adelante, no se marcarán como etiquetados automáticamente.
Si tu Cloud Storage está en otro Google Cloud proyecto, asegúrate de conceder acceso para que Document AI pueda escribir archivos en esa ubicación. En concreto, debes asignar el rol Creador de objetos de Storage al agente de servicio principal de Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Para obtener más información, consulta Agentes de servicio.
Importar conjunto de datos
El procedimiento es el mismo que el de Importar documentos.
Guía de usuario de etiquetado selectivo
El etiquetado selectivo te ayuda a recibir recomendaciones sobre qué documentos etiquetar. Puedes crear conjuntos de datos de entrenamiento y de prueba diversos para entrenar modelos representativos. Cada vez que se realiza un etiquetado selectivo, se seleccionan los documentos más diversos (hasta 30) del conjunto de datos.
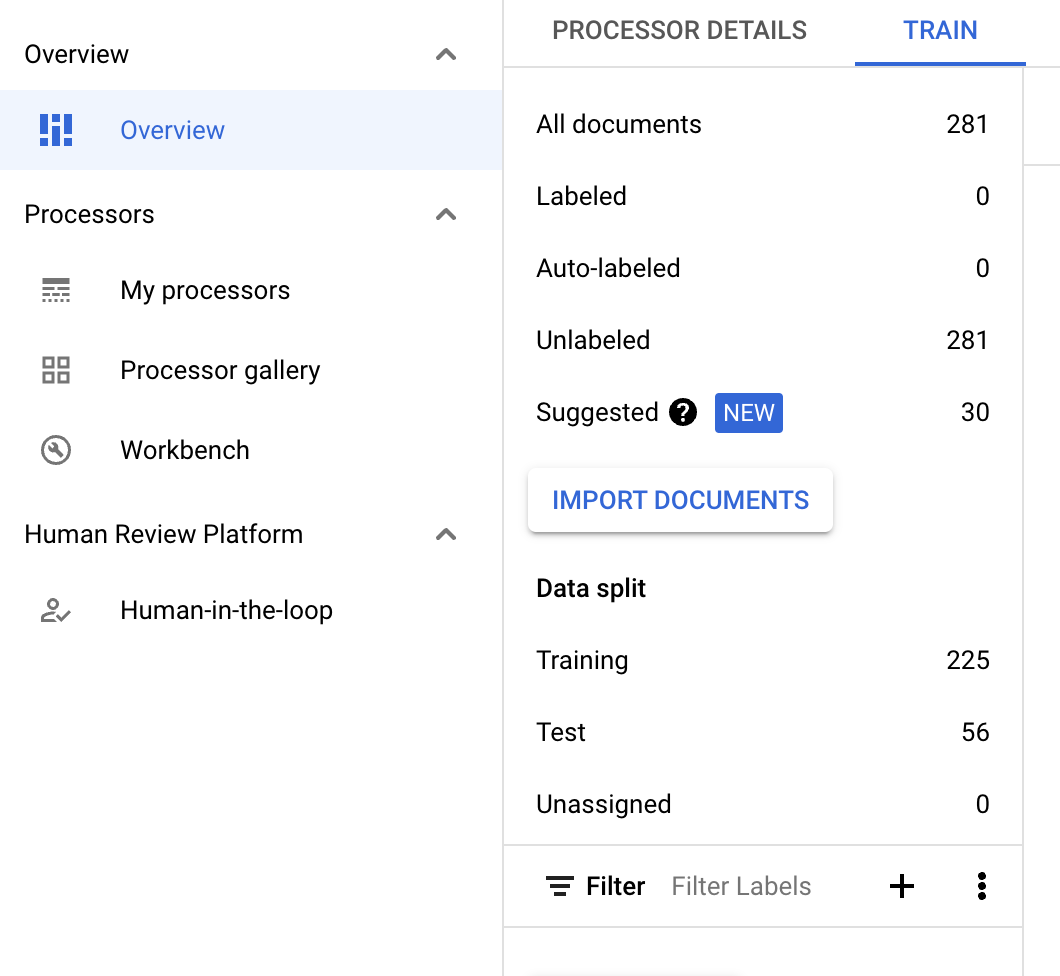
Obtener documentos sugeridos
Crea un procesador de CDE e importa documentos.
- Se necesitan al menos 100 para la preparación (25 para las pruebas).
- Una vez que se hayan importado suficientes documentos y se hayan etiquetado de forma selectiva, debería aparecer la barra de información.
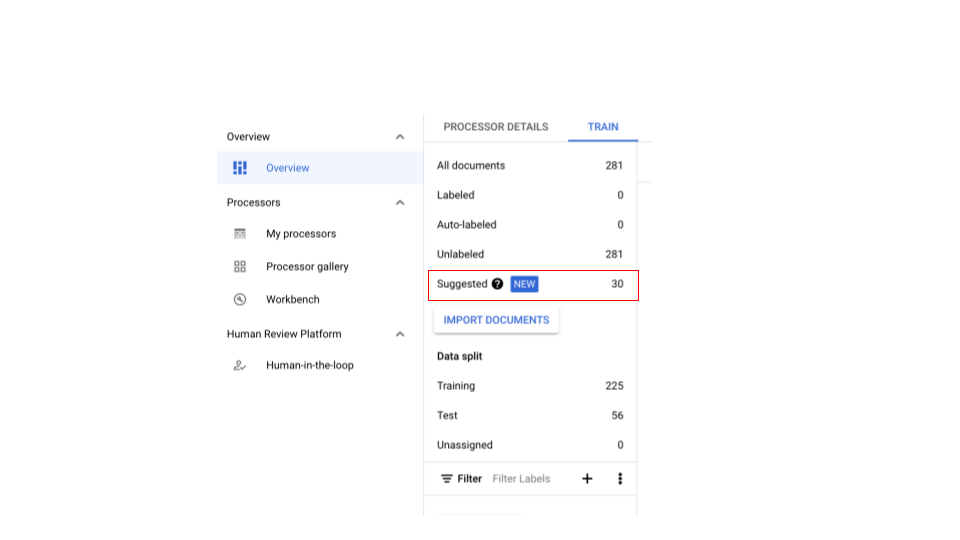
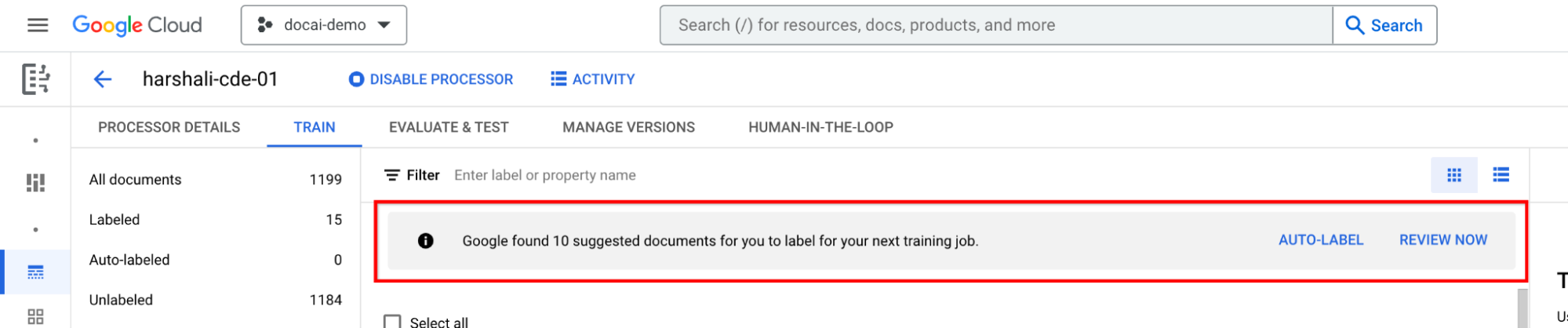
Si un procesador de CDE no tiene documentos sugeridos, importa más para que haya suficientes documentos en cualquiera de las divisiones para el muestreo.
- Deberían aparecer los documentos sugeridos en la categoría Sugerencias. Deberías poder solicitar documentos sugeridos manualmente.
- Hay un nuevo filtro en la parte superior para excluir los documentos sugeridos.
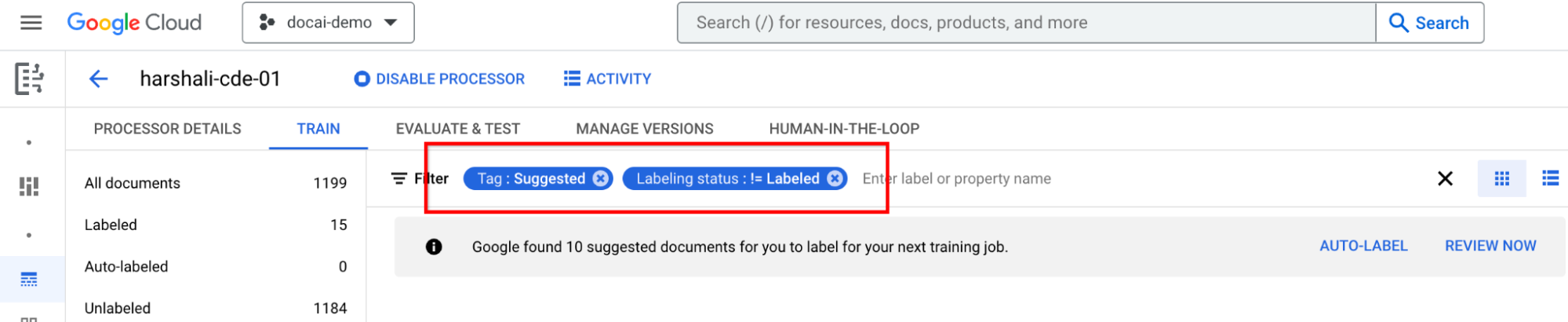
Etiquetar documentos sugeridos
Vaya a Categoría sugerida en el panel de la lista de etiquetas de la izquierda. Empieza a etiquetar estos documentos.
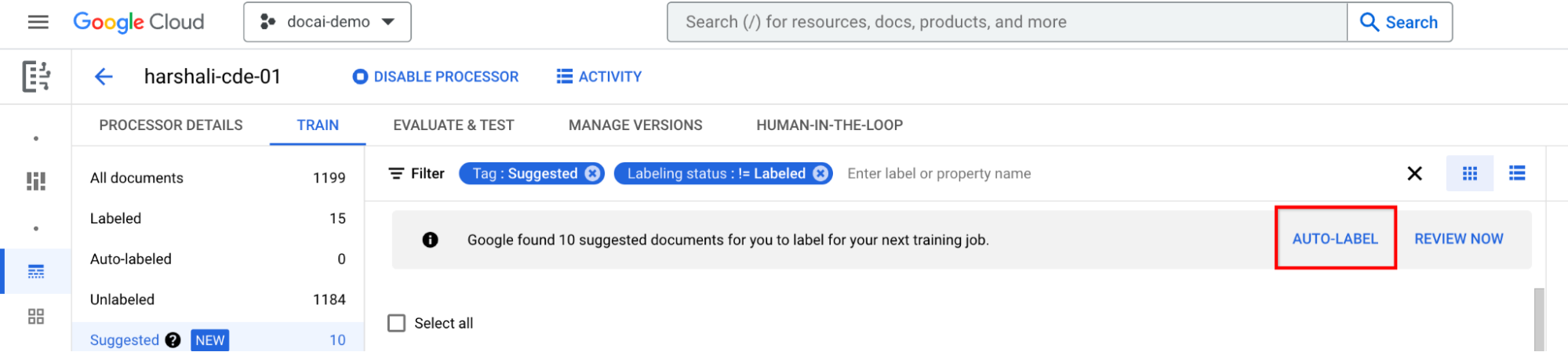
Selecciona Etiquetado automático en la barra de información si el procesador está entrenado. Etiqueta los documentos sugeridos.
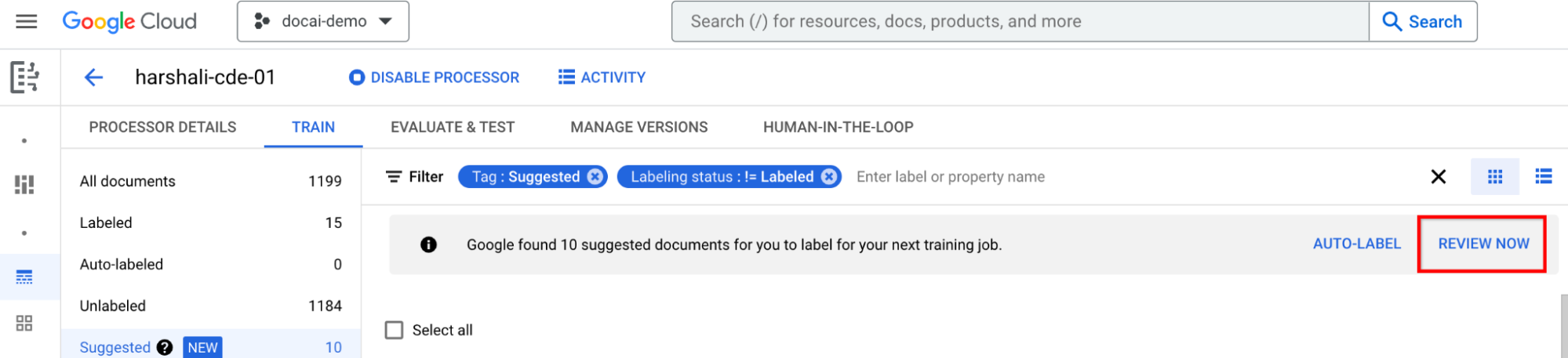
A continuación, puedes seleccionar Revisar ahora en la barra cuando tengas documentos sugeridos en el procesador para ir a ellos. Todos los documentos etiquetados automáticamente deben revisarse para comprobar su precisión. Empieza a revisar.
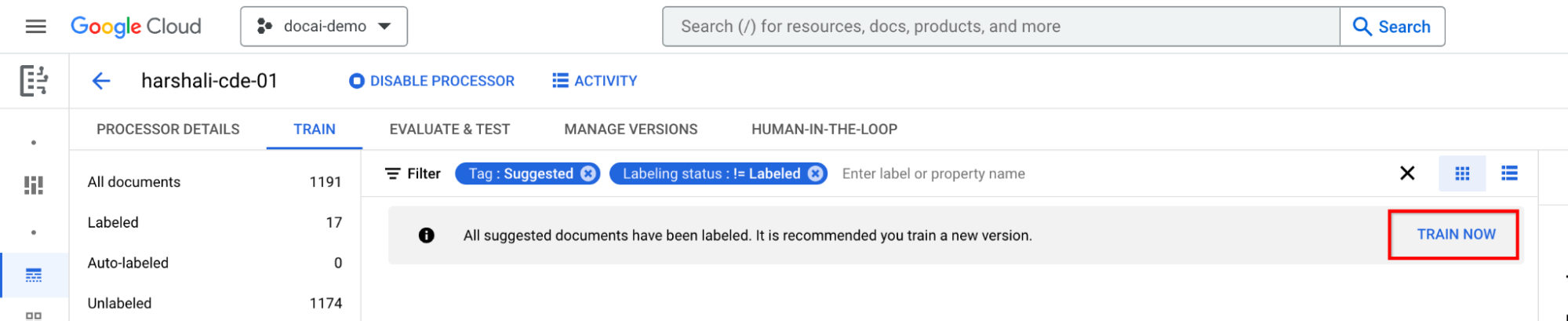
Entrenar después de etiquetar todos los documentos sugeridos
Ve a Entrenar ahora en la barra de información. Cuando se etiqueten los documentos sugeridos, verás la siguiente barra de información que recomienda formación.
Funciones admitidas y limitaciones
| Función | Descripción | Compatible |
|---|---|---|
| Compatibilidad con procesadores antiguos | Es posible que no funcione bien con procesadores antiguos con un conjunto de datos importado previamente |