Document AI generates evaluation metrics, such as precision and recall, to help you determine the predictive performance of your processors.
These evaluation metrics are generated by comparing the entities returned by the processor (the predictions) against the annotations in the test documents. If your processor does not have a test set, then you must first create a dataset and label the test documents.
Run an evaluation
An evaluation is automatically run whenever you train or uptrain a processor version.
You can also manually run an evaluation. This is required to generate updated metrics after you've modified the test set, or if you are evaluating a pretrained processor version.
Web UI
In the Google Cloud console, go to the Processors page and choose your processor.
In the Evaluate & Test tab, select the Version of the processor to evaluate and then click Run new evaluation.
Once complete, the page contains evaluation metrics for all labels and for each individual label.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Get results of an evaluation
Web UI
In the Google Cloud console, go to the Processors page and choose your processor.
In the Evaluate & Test tab, select the Version of the processor to view evaluation.
Once complete, the page contains evaluation metrics for all labels and for each individual label.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
List all evaluations for a processor version
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Evaluation metrics for all labels
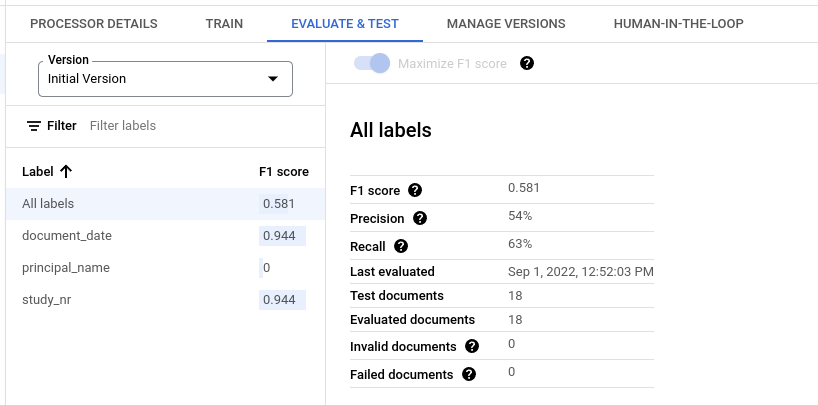
Metrics for All labels are computed based on the number of true positives, false positives, and false negatives in the dataset across all labels, and thus, are weighted by the number of times each label appears in the dataset. For definitions of these terms, see Evaluation metrics for individual labels.
Precision: the proportion of predictions that match the annotations in the test set. Defined as
True Positives / (True Positives + False Positives)Recall: the proportion of annotations in the test set that are correctly predicted. Defined as
True Positives / (True Positives + False Negatives)F1 score: the harmonic mean of precision and recall, which combines precision and recall into a single metric, providing equal weight to both. Defined as
2 * (Precision * Recall) / (Precision + Recall)
Evaluation metrics for individual labels
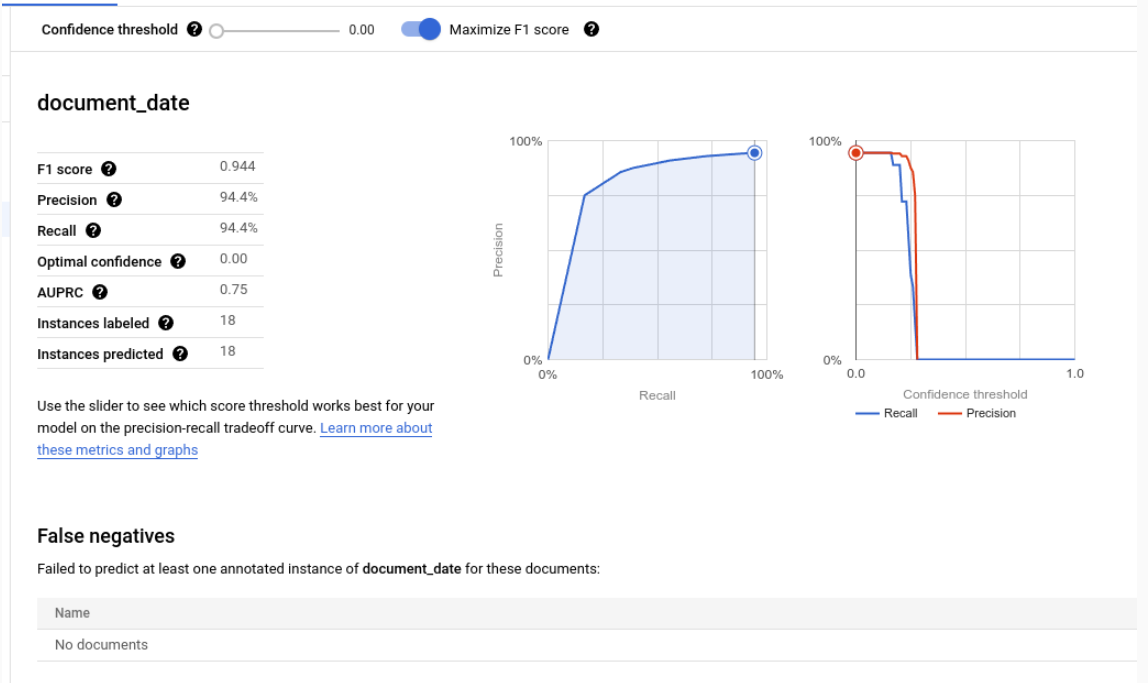
True Positives: the predicted entities that match an annotation in the test document. For more information, see matching behavior.
False Positives: the predicted entities that don't match any annotation in the test document.
False Negatives: the annotations in the test document that don't match any of the predicted entities.
- False Negatives (Below Threshold): the annotations in the test document that would have matched a predicted entity, but the predicted entity's confidence value is below the specified confidence threshold.
Confidence threshold
The evaluation logic ignores any predictions with confidence below the specified Confidence Threshold, even if the prediction is correct. Document AI provides a list of False Negatives (Below Threshold), which are the annotations that would have a match if the confidence threshold were set lower.
Document AI automatically computes the optimal threshold, which maximizes the F1 score, and by default, sets the confidence threshold to this optimal value.
You are free to choose your own confidence threshold by moving the slider bar. In general, higher confidence threshold results in:
- higher precision, because the predictions are more likely to be correct.
- lower recall, because there are fewer predictions.
Tabular entities
The metrics for a parent label are not calculated by directly averaging the child metrics, but rather, by applying the parent's confidence threshold to all of its child labels and aggregating the results.
The optimal threshold for the parent is the confidence threshold value that, when applied to all children, yields the maximum F1 score for the parent.
Matching behavior
A predicted entity matches an annotation if:
- the type of the predicted entity
(
entity.type) matches the annotation's label name - the value of the predicted entity
(
entity.mention_textorentity.normalized_value.text) matches the annotation's text value, subject to fuzzy matching if it is enabled.
Note that type and text value are all that is used for matching. Other information, such as text anchors and bounding boxes (with the exception of tabular entities described below) are not used.
Single- versus multi-occurrence labels
Single-occurrence labels have one value per document (for example, invoice ID) even if that value is annotated multiple times in the same document (for example, the invoice ID appears in every page of the same document). Even if the multiple annotations have different text, they are considered equal. In other words, if a predicted entity matches any of the annotations, it counts as a match. The extra annotations are considered duplicate mentions and don't contribute towards any of the true positive, false positive, or false negative counts.
Multi-occurrence labels can have multiple, different values. Thus, each predicted entity and annotation is considered and matched separately. If a document contains N annotations for a multi-occurrence label, then there can be N matches with the predicted entities. Each predicted entity and annotation are independently counted as a true positive, false positive, or false negative.
Fuzzy Matching
The Fuzzy Matching toggle lets you tighten or relax some of the matching rules to decrease or increase the number of matches.
For example, without fuzzy matching, the string ABC does not match abc due
to capitalization. But with fuzzy matching, they match.
When fuzzy matching is enabled, here are the rule changes:
Whitespace normalization: removes leading-trailing whitespace and condenses consecutive intermediate whitespaces (including newlines) into single spaces.
Leading/trailing punctuation removal: removes the following leading-trailing punctuation characters
!,.:;-"?|.Case-insensitive matching: converts all characters to lowercase.
Money normalization: For labels with the data type
money, remove the leading-trailing currency symbols.
Tabular entities
Parent entities and annotations don't have text values and are matched based on the combined bounding boxes of their children. If there is only one predicted parent and one annotated parent, they are automatically matched, regardless of bounding boxes.
Once parents are matched, their children are matched as if they were non-tabular entities. If parents are not matched, Document AI won't attempt to match their children. This means that child entities can be considered incorrect, even with the same text contents, if their parent entities are not matched.
Parent / child entities are a Preview feature and only supported for tables with one layer of nesting.
Export evaluation metrics
In the Google Cloud console, go to the Processors page and choose your processor.
In the Evaluate & Test tab, click Download Metrics, to download the evaluation metrics as a JSON file.