Anda dapat menggunakan Enterprise Document OCR sebagai bagian dari Document AI untuk mendeteksi dan mengekstrak teks serta informasi tata letak dari berbagai dokumen. Dengan fitur yang dapat dikonfigurasi, Anda dapat menyesuaikan sistem untuk memenuhi persyaratan pemrosesan dokumen tertentu.
Ringkasan
Anda dapat menggunakan Enterprise Document OCR untuk tugas seperti entri data berdasarkan algoritma atau machine learning serta meningkatkan dan memverifikasi akurasi data. Anda juga dapat menggunakan Enterprise Document OCR untuk menangani tugas seperti berikut:
- Mendigitalkan teks: Ekstrak data teks dan tata letak dari dokumen untuk penelusuran, pipeline pemrosesan dokumen berbasis aturan, atau pembuatan model kustom.
- Menggunakan aplikasi model bahasa besar: Gunakan pemahaman kontekstual LLM dan kemampuan ekstraksi teks dan tata letak OCR untuk mengotomatiskan pertanyaan dan jawaban. Dapatkan insight dari data, dan sederhanakan alur kerja.
- Pengarsipan: Mendigitalkan dokumen kertas menjadi teks yang dapat dibaca mesin untuk meningkatkan aksesibilitas dokumen.
Memilih OCR terbaik untuk kasus penggunaan Anda
| Solusi | Produk | Deskripsi | Kasus penggunaan |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Model khusus untuk kasus penggunaan dokumen. Fitur lanjutan mencakup skor kualitas gambar, petunjuk bahasa, dan koreksi rotasi. | Direkomendasikan saat mengekstrak teks dari dokumen. Kasus penggunaan mencakup PDF, dokumen yang dipindai sebagai gambar, atau file Microsoft DocX. |
| Document AI | Add-on OCR | Fitur premium untuk persyaratan tertentu. Hanya kompatibel dengan Enterprise Document OCR versi 2.0 dan yang lebih baru. | Perlu mendeteksi dan mengenali formula matematika, menerima informasi gaya font, atau mengaktifkan ekstraksi kotak centang. |
| Cloud Vision API | Deteksi teks | REST API yang tersedia secara global berdasarkan Google Cloud model OCR standar. Kuota default 1.800 permintaan per menit. | Kasus penggunaan ekstraksi teks umum yang memerlukan latensi rendah dan kapasitas tinggi. |
| Cloud Vision | OCR Google Distributed Cloud (Tidak digunakan lagi) | Aplikasi Google Cloud Marketplace yang dapat di-deploy sebagai container ke cluster GKE mana pun menggunakan GKE Enterprise. | Untuk memenuhi persyaratan residensi atau kepatuhan data. |
Deteksi dan ekstraksi
Enterprise Document OCR dapat mendeteksi blok, paragraf, baris, kata, dan simbol dari PDF dan gambar, serta meluruskan dokumen untuk akurasi yang lebih baik.
Atribut deteksi dan ekstraksi tata letak yang didukung:
| Teks cetak | Tulisan tangan | Paragraf | Blokir | Line | Word | Tingkat simbol | Nomor halaman |
|---|---|---|---|---|---|---|---|
| Default | Default | Default | Default | Default | Default | Dapat Dikonfigurasi | Default |
Fitur Enterprise Document OCR yang dapat dikonfigurasi meliputi:
Mengekstrak teks native atau yang disematkan dari PDF digital: Fitur ini mengekstrak teks dan simbol persis seperti yang muncul dalam dokumen sumber, bahkan untuk teks yang diputar, ukuran atau gaya font yang ekstrem, dan teks yang sebagian tersembunyi.
Koreksi rotasi: Gunakan Enterprise Document OCR untuk memproses awal gambar dokumen guna mengoreksi masalah rotasi yang dapat memengaruhi kualitas ekstraksi atau pemrosesan.
Skor kualitas gambar: Menerima metrik kualitas yang dapat membantu perutean dokumen. Skor kualitas gambar memberikan metrik kualitas tingkat halaman dalam delapan dimensi, termasuk keburaman, keberadaan font yang lebih kecil dari biasanya, dan silau.
Tentukan rentang halaman: Menentukan rentang halaman dalam dokumen input untuk OCR. Hal ini menghemat waktu pemrosesan dan pembelanjaan di halaman yang tidak diperlukan.
Deteksi bahasa: Mendeteksi bahasa yang digunakan dalam teks yang diekstrak.
Petunjuk bahasa dan tulisan tangan: Tingkatkan akurasi dengan memberikan petunjuk bahasa atau tulisan tangan kepada model OCR berdasarkan karakteristik yang diketahui dari set data Anda.
Untuk mempelajari cara mengaktifkan konfigurasi OCR, lihat Mengaktifkan konfigurasi OCR.
Add-on OCR
Enterprise Document OCR menawarkan kemampuan analisis opsional yang dapat diaktifkan pada permintaan pemrosesan individual sesuai kebutuhan.
Kemampuan add-on berikut tersedia untuk versi Stabil
pretrained-ocr-v2.0-2023-06-02 dan pretrained-ocr-v2.1-2024-08-07,
serta versi Release Candidate pretrained-ocr-v2.1.1-2025-01-31.
- OCR Matematika: Mengidentifikasi dan mengekstrak formula dari dokumen dalam format LaTeX.
- Ekstraksi kotak centang: Mendeteksi kotak centang dan mengekstrak statusnya (dicentang/tidak dicentang) dalam respons Enterprise Document OCR.
- Deteksi gaya font: Mengidentifikasi properti font tingkat kata, termasuk jenis font, gaya font, tulisan tangan, ketebalan, dan warna.
Untuk mempelajari cara mengaktifkan add-on yang tercantum, lihat Mengaktifkan add-on OCR.
Format file yang didukung
OCR Dokumen Perusahaan mendukung format file PDF, GIF, TIFF, JPEG, PNG, BMP, dan WebP. Untuk mengetahui informasi selengkapnya, lihat File yang didukung.
Enterprise Document OCR juga mendukung file DocX hingga 15 halaman dalam sinkron dan 30 halaman dalam asinkron. Dukungan DocX dalam pratinjau pribadi. Untuk meminta akses, kirimkan Formulir Permintaan Dukungan DocX .
Pembuatan versi lanjutan
Pembuatan versi lanjutan berada dalam Pratinjau. Upgrade pada model OCR AI/ML yang mendasarinya dapat menyebabkan perubahan pada perilaku OCR. Jika konsistensi ketat diperlukan, gunakan versi model yang di-freeze untuk menyematkan perilaku ke model OCR lama hingga 18 bulan. Tindakan ini memastikan hasil fungsi OCR ke gambar yang sama. Lihat tabel tentang versi pemroses.
Versi pemroses
Versi prosesor berikut kompatibel dengan fitur ini. Untuk mengetahui informasi selengkapnya, lihat Mengelola versi pemroses.
| ID versi | Saluran rilis | Deskripsi |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stabil | Versi model yang dibekukan v1.0: File model, konfigurasi, dan biner snapshot versi yang dibekukan dalam image container hingga 18 bulan. |
pretrained-ocr-v2.0-2023-06-02 |
Stabil | Model siap produksi yang dikhususkan untuk kasus penggunaan dokumen. Mencakup akses ke semua add-on OCR. |
pretrained-ocr-v2.1-2024-08-07 |
Stabil | Area utama peningkatan untuk v2.1 adalah: pengenalan teks cetak yang lebih baik, deteksi kotak centang yang lebih presisi, dan urutan baca yang lebih akurat. |
pretrained-ocr-v2.1.1-2025-01-31 |
Kandidat rilis | v2.1.1 mirip dengan V2.1, dan tersedia di semua wilayah kecuali: US, EU, dan asia-southeast1. |
Menggunakan Enterprise Document OCR untuk memproses dokumen
Panduan memulai ini memperkenalkan Enterprise Document OCR. Bagian ini menunjukkan cara mengoptimalkan hasil OCR dokumen untuk alur kerja Anda dengan mengaktifkan atau menonaktifkan salah satu konfigurasi OCR yang tersedia.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Deteksi positif palsu dapat terjadi pada dokumen digital yang tidak memiliki kecacatan. Fitur ini paling baik digunakan pada dokumen yang dipindai atau difoto.
Cacat silau bersifat lokal. Keberadaannya mungkin tidak menghalangi keterbacaan dokumen secara keseluruhan.
- Untuk hanya memproses halaman kedua dan kelima:
- Untuk hanya memproses tiga halaman pertama:
- Untuk memproses hanya empat halaman terakhir:
Gambar terdeteksi
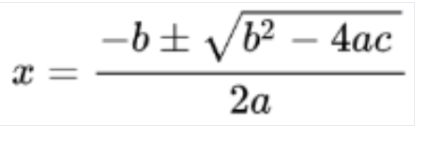
Konversi ke LaTeX
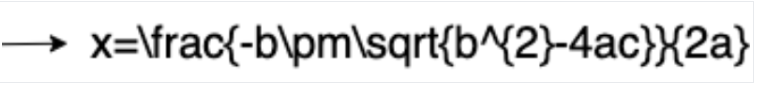
- Deteksi tulisan tangan
- Gaya font
- Ukuran font
- Jenis font
- Warna font
- Ketebalan font
- Penentuan spasi huruf
- Tebal
- Miring
- Digarisbawahi
- Warna teks (RGBa)
Warna latar belakang (RGBa)
- Respons Vision AI API hanya mengisi
verticesuntuk permintaan gambar, dan hanya mengisinormalized_verticesuntuk permintaan PDF. Respons Document AI dan pengonversi mengisiverticesdannormalized_vertices. - Respons Vision AI API mengisi
detected_breakdalam simbol terakhir kata. Respons Document AI API dan konverter mengisidetected_breakdalam kata dan simbol terakhir kata. - Respons Vision AI API selalu mengisi kolom simbol. Secara default, respons Document AI tidak mengisi kolom simbol. Untuk memastikan respons Document AI dan konverter mengisi kolom simbol, tetapkan fitur
enable_symbolsebagai mendetail. - LOCATION: lokasi pemroses Anda, misalnya:
us- Amerika Serikateu- Uni Eropa
- PROJECT_ID: ID project Google Cloud Anda.
- PROCESSOR_ID: ID pemroses kustom Anda.
- PROCESSOR_VERSION: ID versi prosesor. Lihat Memilih versi prosesor untuk mengetahui informasi selengkapnya. Misalnya:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: Nilai boolean untuk menonaktifkan peninjauan manual (Hanya didukung oleh pemroses yang memerlukan interaksi manusia.)
true- melewati peninjauan manualfalse- mengaktifkan peninjauan manual (default)
- MIME_TYPE†: Salah satu opsi jenis MIME yang valid.
- IMAGE_CONTENT†: Salah satu
Konten dokumen inline yang valid, direpresentasikan sebagai
aliran byte. Untuk representasi JSON, encoding base64 (string ASCII) dari data gambar biner Anda. String ini akan terlihat seperti
string berikut:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: Menentukan kolom mana yang akan disertakan dalam output
Document. Ini adalah daftar nama kolom yang sepenuhnya memenuhi syarat dalam formatFieldMaskyang dipisahkan koma.- Contoh:
text,entities,pages.pageNumber
- Contoh:
- Konfigurasi OCR
- ENABLE_NATIVE_PDF_PARSING: (Boolean) Mengekstrak teks yang disematkan dari PDF, jika tersedia.
- ENABLE_IMAGE_QUALITY_SCORES: (Boolean) Mengaktifkan skor kualitas dokumen cerdas.
- ENABLE_SYMBOL: (Boolean) Menyertakan informasi OCR simbol (huruf).
- DISABLE_CHARACTER_BOXES_DETECTION: (Boolean) Nonaktifkan detektor kotak karakter di mesin OCR.
- LANGUAGE_HINTS: Daftar kode bahasa BCP-47 yang akan digunakan untuk OCR.
- ADVANCED_OCR_OPTIONS: Daftar opsi OCR lanjutan untuk menyempurnakan perilaku OCR lebih lanjut. Nilai valid saat ini adalah:
legacy_layout: algoritma deteksi tata letak heuristik, yang berfungsi sebagai alternatif untuk algoritma deteksi tata letak berbasis ML saat ini.
- Add-on OCR Premium
- ENABLE_SELECTION_MARK_DETECTION: (Boolean) Aktifkan detektor tanda pilihan di mesin OCR.
- COMPUTE_STYLE_INFO (Boolean) Aktifkan model identifikasi font dan tampilkan informasi gaya font.
- ENABLE_MATH_OCR: (Boolean) Aktifkan model yang dapat mengekstrak formula matematika LaTeX.
- INDIVIDUAL_PAGES: Daftar halaman individual yang akan diproses.
- Tinjau daftar pemroses.
- Pisahkan dokumen menjadi bagian-bagian yang mudah dibaca dengan Layout Parser.
- Buat pengklasifikasi kustom.
Membuat pemroses Enterprise Document OCR
Pertama, buat pemroses Enterprise Document OCR. Untuk mengetahui informasi selengkapnya, lihat membuat dan mengelola pemroses.
Konfigurasi OCR
Semua konfigurasi OCR dapat diaktifkan dengan menyetel kolom masing-masing di ProcessOptions.ocrConfig dalam ProcessDocumentRequest atau BatchProcessDocumentsRequest.
Untuk mengetahui informasi selengkapnya, lihat Mengirim permintaan pemrosesan.
Analisis kualitas gambar
Analisis kualitas dokumen cerdas menggunakan machine learning untuk melakukan penilaian kualitas dokumen berdasarkan keterbacaan kontennya.
Penilaian kualitas ini ditampilkan sebagai skor kualitas [0, 1], dengan 1 berarti kualitas sempurna.
Jika skor kualitas yang terdeteksi lebih rendah dari 0.5, daftar alasan kualitas negatif (diurutkan berdasarkan kemungkinan) juga akan ditampilkan.
Kemungkinan lebih besar dari 0.5 dianggap sebagai deteksi positif.
Jika dokumen dianggap rusak, API akan menampilkan delapan jenis kerusakan dokumen berikut:
Ada beberapa batasan pada analisis kualitas dokumen saat ini:
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.enableImageQualityScores ke true dalam permintaan pemrosesan.
Fitur tambahan ini menambahkan latensi yang sebanding dengan pemrosesan OCR ke panggilan proses.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Output
Hasil deteksi kerusakan akan muncul di Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Lihat Contoh output pemroses untuk contoh output lengkap.
Petunjuk bahasa
Prosesor OCR mendukung petunjuk bahasa yang Anda tentukan untuk meningkatkan performa mesin OCR. Menerapkan petunjuk bahasa memungkinkan OCR mengoptimalkan bahasa yang dipilih, bukan bahasa yang disimpulkan.
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.hints[].languageHints[] dengan daftar kode bahasa BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Lihat Contoh output pemroses untuk contoh output lengkap.
Deteksi simbol
Mengisi data di tingkat simbol (atau huruf individual) dalam respons dokumen.
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.enableSymbol ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Output
Jika fitur ini diaktifkan, kolom Document.pages[].symbols[] akan diisi.
Lihat Contoh output pemroses untuk contoh output lengkap.
Penguraian PDF bawaan
Mengekstrak teks tersemat dari file PDF digital. Jika diaktifkan, model PDF digital bawaan akan otomatis digunakan jika ada teks digital. Jika ada teks non-digital, model OCR optik akan digunakan secara otomatis. Pengguna menerima kedua hasil teks yang digabungkan.
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.enableNativePdfParsing ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Deteksi karakter dalam kotak
Secara default, Enterprise Document OCR mengaktifkan detektor untuk meningkatkan kualitas ekstraksi teks karakter yang berada dalam kotak. Berikut ini contohnya:

Jika Anda mengalami masalah kualitas OCR dengan karakter di dalam kotak, Anda dapat menonaktifkannya.
Input
Nonaktifkan dengan menyetel ProcessOptions.ocrConfig.disableCharacterBoxesDetection ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Tata letak lama
Jika memerlukan algoritma deteksi tata letak heuristik, Anda dapat mengaktifkan tata letak lama, yang berfungsi sebagai alternatif untuk algoritma deteksi tata letak berbasis ML saat ini. Ini bukan konfigurasi yang direkomendasikan. Pelanggan dapat memilih algoritma tata letak yang paling sesuai berdasarkan alur kerja dokumen mereka.
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.advancedOcrOptions ke ["legacy_layout"] dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Menentukan rentang halaman
Secara default, OCR mengekstrak informasi teks dan tata letak dari semua halaman dalam dokumen. Anda dapat memilih nomor halaman atau rentang halaman tertentu dan hanya mengekstrak teks dari halaman tersebut.
Ada tiga cara untuk mengonfigurasi ini di ProcessOptions:
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
Dalam respons, setiap Document.pages[].pageNumber sesuai dengan halaman yang sama yang ditentukan dalam permintaan.
Penggunaan add-on OCR
Kemampuan analisis opsional Enterprise Document OCR ini dapat diaktifkan pada setiap permintaan pemrosesan sesuai kebutuhan.
OCR Matematika
OCR Matematika mendeteksi, mengenali, dan mengekstrak formula, seperti persamaan matematika yang ditampilkan sebagai LaTeX beserta koordinat kotak pembatas.
Berikut adalah contoh representasi LaTeX:
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Output
Output OCR Matematika muncul di Document.pages[].visualElements[] dengan "type": "math_formula".
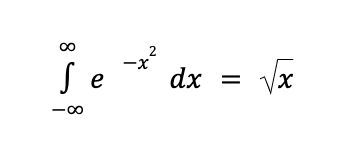
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Anda dapat memeriksa output JSON Document lengkap di link ini .
Ekstraksi tanda pilihan
Jika diaktifkan, model akan mencoba mengekstrak semua kotak centang dan tombol pilihan dalam dokumen, beserta koordinat kotak pembatas.
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Output
Output kotak centang muncul di Document.pages[].visualElements[] dengan "type": "unfilled_checkbox" atau "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Anda dapat memeriksa output JSON Document lengkap di link ini .
Deteksi gaya font
Dengan mengaktifkan deteksi gaya font, Enterprise Document OCR mengekstrak atribut font, yang dapat digunakan untuk pemrosesan pasca-pemrosesan yang lebih baik.
Di tingkat token (kata), atribut berikut terdeteksi:
Input
Aktifkan dengan menyetel ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo ke true dalam permintaan pemrosesan.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Output
Output font-style muncul di Document.pages[].tokens[].styleInfo dengan jenis StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Anda dapat memeriksa output JSON Document lengkap di link ini .
Mengonversi objek dokumen ke format Vision AI API
Toolbox Document AI menyertakan alat yang mengonversi format Document Document AI API ke format AnnotateFileResponse Vision AI, sehingga pengguna dapat membandingkan respons antara pemroses OCR dokumen dan Vision AI API. Berikut beberapa contoh kode.
Perbedaan yang diketahui antara respons Vision AI API dan respons serta pengonversi Document AI API:
Contoh kode
Contoh kode berikut menunjukkan cara mengirim permintaan pemrosesan yang mengaktifkan konfigurasi dan add-on OCR, lalu membaca dan mencetak kolom ke terminal:
REST
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
† Konten ini juga dapat ditentukan menggunakan konten berenkode base64 dalam objek
inlineDocument.
Metode HTTP dan URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Isi JSON permintaan:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Jika permintaan berhasil, server akan menampilkan kode status HTTP 200 OK dan
respons dalam format JSON. Isi respons berisi instance
Document.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.