Pelatihan dan ekstraksi AI generatif memungkinkan Anda:
- Gunakan teknologi zero-shot dan few-shot untuk mendapatkan model berperforma tinggi dengan sedikit atau tanpa data pelatihan menggunakan model dasar.
- Gunakan penyesuaian untuk lebih meningkatkan akurasi saat Anda memberikan lebih banyak data pelatihan.
Metode pelatihan AI generatif
Metode pelatihan yang Anda pilih bergantung pada jumlah dokumen yang tersedia dan upaya yang dapat Anda lakukan untuk melatih model. Ada tiga cara untuk melatih model AI generatif:
| Metode pelatihan | Zero-shot | Few-shot | Fine tuning |
|---|---|---|---|
| Akurasi | Sedang | Sedang-tinggi | Tinggi |
| Upaya | Rendah | Rendah | Sedang |
| Jumlah dokumen pelatihan yang direkomendasikan | 0 | 5 hingga 10 | 10 hingga 50+ |
Versi model ekstraktor kustom
Model berikut tersedia untuk ekstraktor kustom. Untuk mengubah versi model, lihat Mengelola versi pemroses.
Versi 1.4, 1.5, dan 1.5 Pro mendukung skor keyakinan.
| Versi model | Deskripsi | Saluran rilis | Pemrosesan ML di Amerika Serikat/Uni Eropa | Penyesuaian di Amerika Serikat/Uni Eropa | Tanggal rilis |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Model GA yang didukung oleh LLM Gemini 2.0 Flash. Juga mencakup fitur OCR tingkat lanjut seperti deteksi kotak centang. | Stabil | Ya | Amerika Serikat, Uni Eropa | 5 Februari 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Kandidat siap produksi yang didukung oleh LLM Gemini 2.5 Flash. Direkomendasikan bagi mereka yang ingin bereksperimen dengan model yang lebih baru. | Stabil | Ya | Amerika Serikat, Uni Eropa (Pratinjau) | 5 Mei 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Model siap produksi yang didukung oleh LLM Gemini 2.5 Pro. Mendukung kuota hingga 30 halaman per menit untuk permintaan proses online. Model ini memiliki kualitas yang lebih baik dibandingkan dengan v1.5, dan mungkin memiliki latensi yang lebih tinggi. | Stabil | Ya | Tidak | 20 Juni 2025 |
pretrained-foundation-model-v1.5.1-2025-08-07 |
Model pratinjau publik yang didukung oleh LLM Gemini 2.5 Flash. Model ini memiliki fitur yang sama dengan v1.5, dan telah meningkatkan pembelajaran adaptif few-shot. | Kandidat rilis | Ya | Tidak | 8 Agustus 2025 |
Untuk mengubah versi pemroses dalam project Anda, tinjau Mengelola versi pemroses.
Untuk membuat Permintaan Penambahan Kuota (QIR) untuk kuota pemroses default, ikuti langkah-langkah di Mengelola kuota Anda.
Penyiapan awal
Jika belum melakukannya, aktifkan penagihan dan Document AI API.
Membangun dan mengevaluasi model AI generatif
Buat pemroses dan tentukan kolom yang ingin Anda ekstrak dengan mengikuti praktik terbaik, yang penting karena memengaruhi kualitas ekstraksi.
- Buka Workbench > Custom extractor > Create processor > Assign a name.
- Buka Mulai > Buat kolom baru.
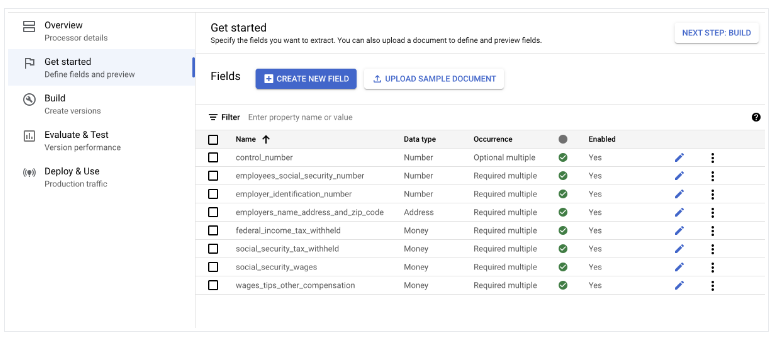
Mengimpor dokumen
- Impor dokumen dengan pelabelan otomatis dan tetapkan dokumen ke set pelatihan dan pengujian.
- Untuk zero-shot, hanya skema yang diperlukan. Untuk mengevaluasi akurasi model, hanya set pengujian yang diperlukan.
- Untuk few-shot, sebaiknya gunakan lima dokumen pelatihan.
- Jumlah dokumen pengujian yang diperlukan bergantung pada kasus penggunaan. Secara umum, semakin banyak dokumen pengujian, semakin baik.
- Konfirmasi atau edit label dalam dokumen.
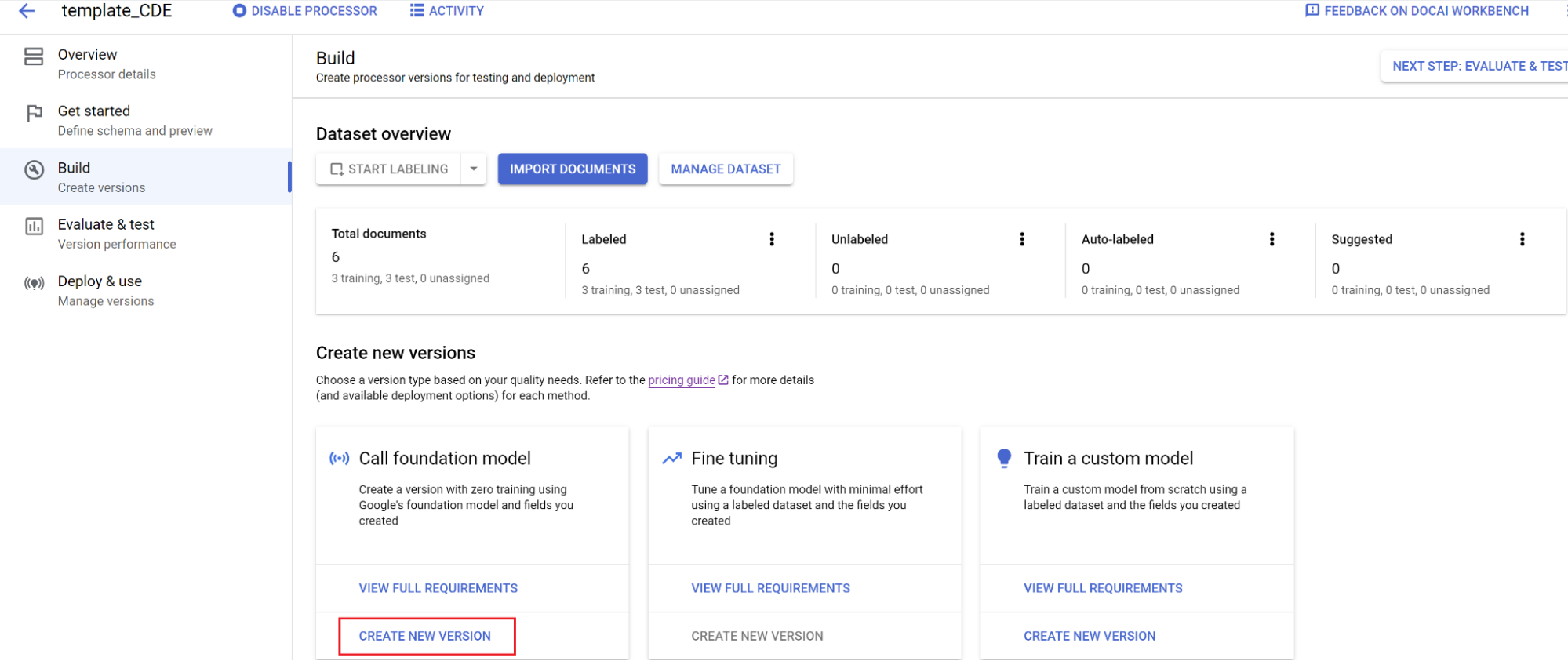
Melatih model:
- Pilih Build, lalu Create new version.
- Masukkan nama, lalu pilih Buat.
Evaluasi:
- Buka Evaluasi & uji, pilih versi yang baru saja Anda latih, lalu pilih Lihat evaluasi lengkap.
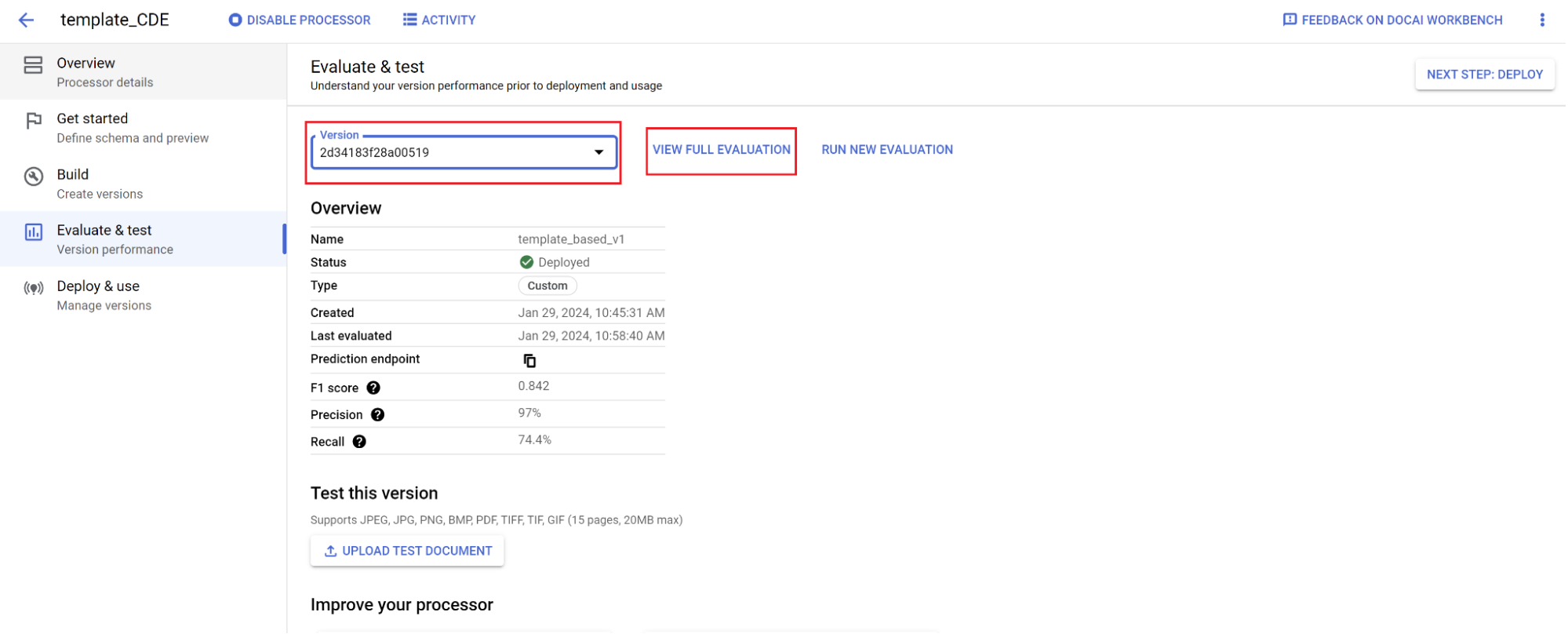
- Sekarang Anda akan melihat metrik seperti f1, presisi, dan perolehan untuk seluruh dokumen dan setiap kolom.
- Tentukan apakah performa memenuhi sasaran produksi Anda. Jika tidak, evaluasi ulang set pelatihan dan pengujian.
Menetapkan versi baru sebagai default:
- Buka Kelola versi.
- Pilih untuk meluaskan opsi, lalu pilih Tetapkan sebagai default.
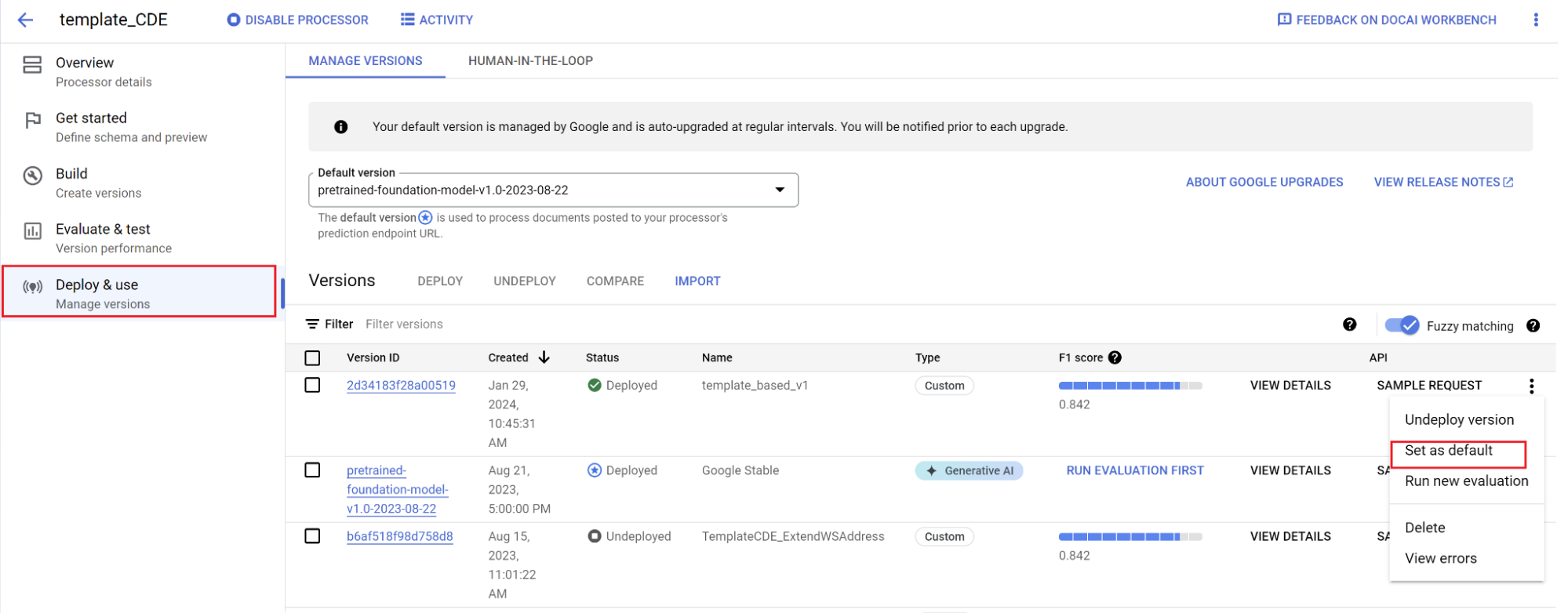
Model Anda kini telah di-deploy. Dokumen yang dikirim ke pemroses ini menggunakan versi kustom Anda. Anda dapat mengevaluasi performa model untuk memeriksa apakah model memerlukan pelatihan lebih lanjut.
Referensi evaluasi
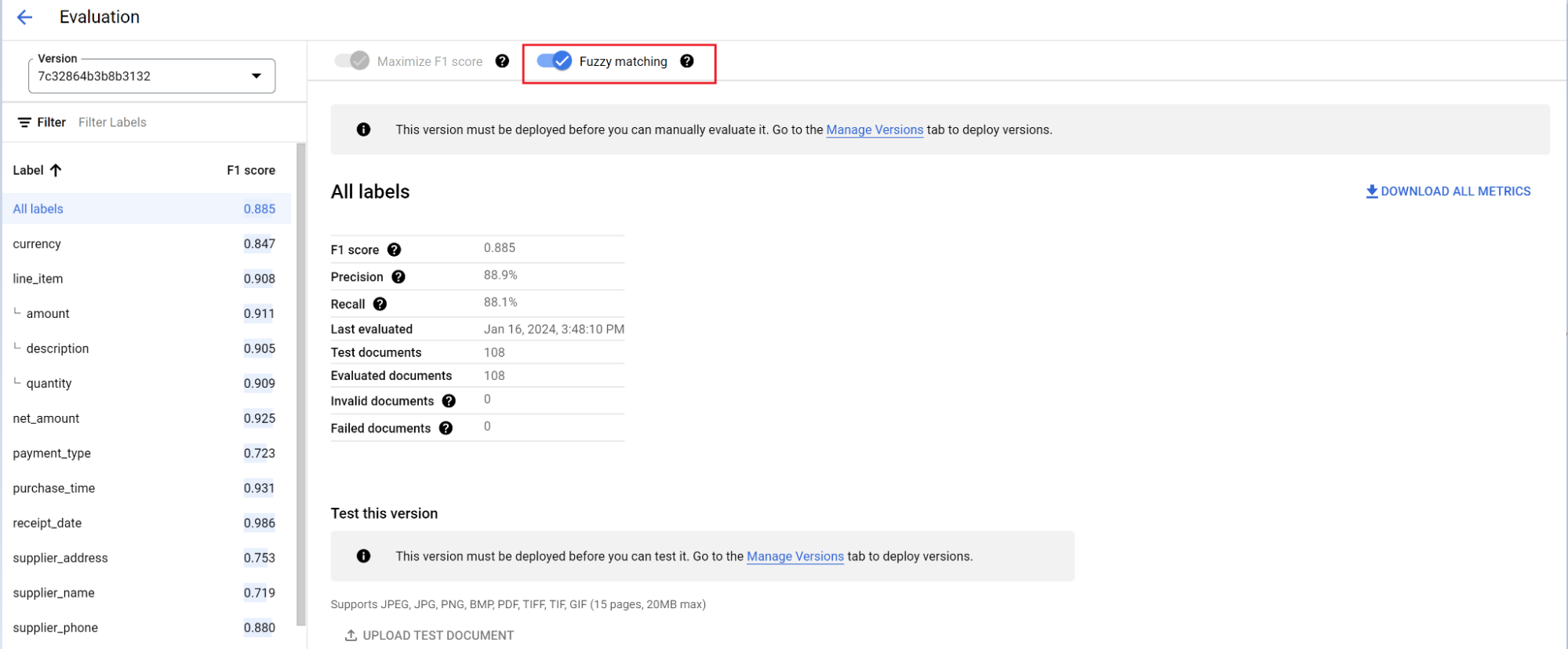
Mesin evaluasi dapat melakukan pencocokan persis atau pencocokan tidak persis. Untuk kecocokan persis, nilai yang diekstrak harus sama persis dengan data sebenarnya atau dihitung sebagai tidak cocok.
Ekstraksi pencocokan tidak jelas yang memiliki sedikit perbedaan seperti perbedaan kapitalisasi tetap dihitung sebagai kecocokan. Setelan ini dapat diubah di layar Evaluasi.
Fine tuning
Dengan penyempurnaan, Anda menggunakan ratusan atau ribuan dokumen untuk pelatihan.
Buat pemroses dan tentukan kolom yang ingin Anda ekstrak dengan mengikuti praktik terbaik, yang penting karena memengaruhi kualitas ekstraksi.
Impor dokumen dengan pemberian label otomatis, dan tetapkan dokumen ke set pelatihan dan pengujian.
Konfirmasi atau edit label dalam dokumen.
Latih model.
- Pilih tab Build, lalu pilih Create New Version di kotak Fine-tuning.
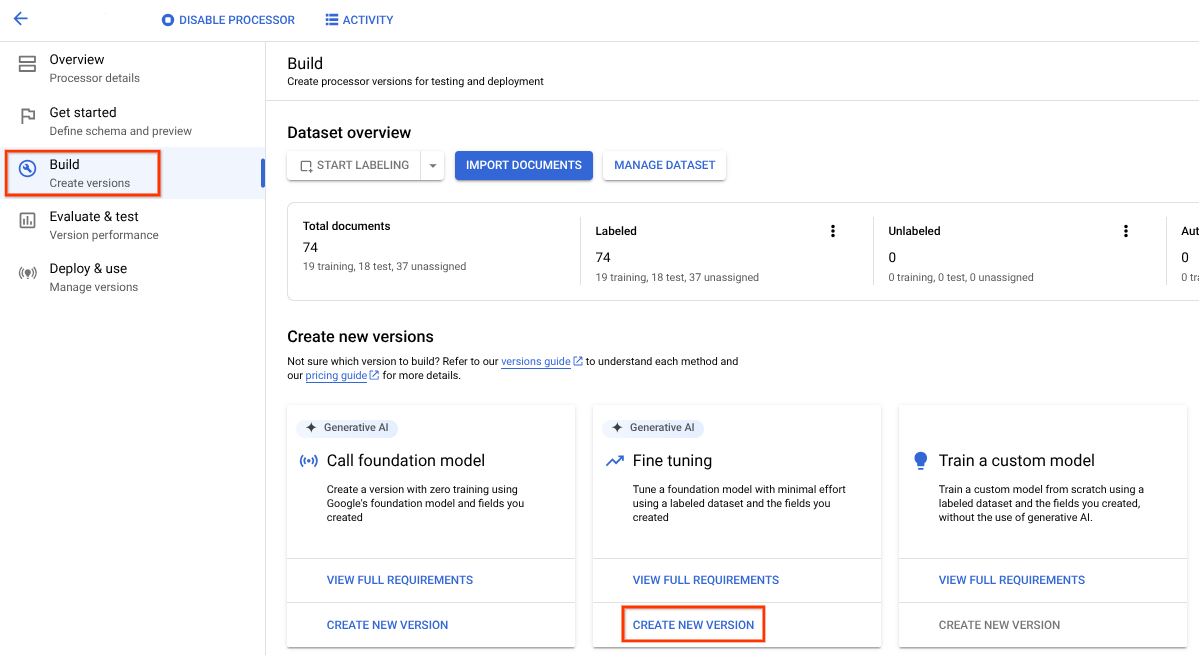
Coba parameter atau nilai pelatihan default yang diberikan. Jika hasilnya tidak memuaskan, coba opsi lanjutan berikut:
Langkah pelatihan (antara 100 dan 400): Mengontrol seberapa sering bobot dioptimalkan pada batch data selama penyesuaian.
- Nilai yang terlalu rendah menunjukkan risiko bahwa pelatihan berakhir sebelum konvergensi (kurang sesuai).
- Nilai yang terlalu tinggi berarti model mungkin melihat batch data yang sama beberapa kali selama pelatihan, yang dapat menyebabkan overfitting.
- Lebih sedikit langkah akan menghasilkan waktu pelatihan yang lebih cepat. Jumlah yang lebih tinggi dapat membantu dokumen dengan sedikit variasi template (dan jumlah yang lebih rendah untuk dokumen dengan lebih banyak variasi).
Pengali kecepatan pembelajaran (antara 0,1 dan 10): Mengontrol seberapa cepat parameter model dioptimalkan pada data pelatihan. Nilai ini kurang lebih sesuai dengan ukuran setiap langkah pelatihan.
- Tingkat yang rendah berarti perubahan kecil pada bobot model di setiap langkah pelatihan. Jika terlalu rendah, model mungkin tidak akan menyatu ke solusi yang stabil.
- Rasio yang tinggi menunjukkan perubahan besar, dan jika terlalu tinggi, model dapat melampaui solusi optimal dan malah menyatu dengan solusi yang kurang optimal.
- Waktu pelatihan tidak terpengaruh oleh pilihan laju pembelajaran.
Beri nama, pilih versi prosesor dasar yang diperlukan, lalu pilih Buat.
Evaluasi: Buka Evaluasi & uji, lalu pilih versi yang baru saja Anda latih dan pilih Lihat evaluasi lengkap.
- Sekarang Anda akan melihat metrik seperti f1, presisi, dan perolehan untuk seluruh dokumen dan setiap kolom.
- Tentukan apakah performa memenuhi sasaran produksi Anda. Jika tidak, dokumentasi pelatihan lebih lanjut mungkin diperlukan.
Menetapkan versi baru sebagai default:
- Buka Kelola versi.
- Pilih untuk meluaskan opsi, lalu pilih Tetapkan sebagai default.
Model Anda kini di-deploy dan dokumen yang dikirim ke pemroses ini kini menggunakan versi kustom Anda. Anda ingin mengevaluasi performa model untuk memeriksa apakah model memerlukan pelatihan lebih lanjut.
Pelabelan otomatis dengan model dasar
Model dasar dapat mengekstrak kolom secara akurat untuk berbagai jenis dokumen, tetapi Anda juga dapat menyediakan data pelatihan tambahan untuk meningkatkan akurasi model untuk struktur dokumen tertentu.
Document AI menggunakan nama label yang Anda tentukan dan anotasi sebelumnya untuk mempercepat dan mempermudah pelabelan dokumen dalam skala besar dengan pelabelan otomatis.
- Setelah Anda membuat pemroses kustom, buka tab Mulai.
- Pilih Create New Field.
Beri label nama yang deskriptif dan berbeda. Pilih Ekstrak untuk nilai langsung dari dokumen atau Turunkan untuk nilai yang disimpulkan oleh sistem. Hal ini meningkatkan akurasi dan performa model dasar.
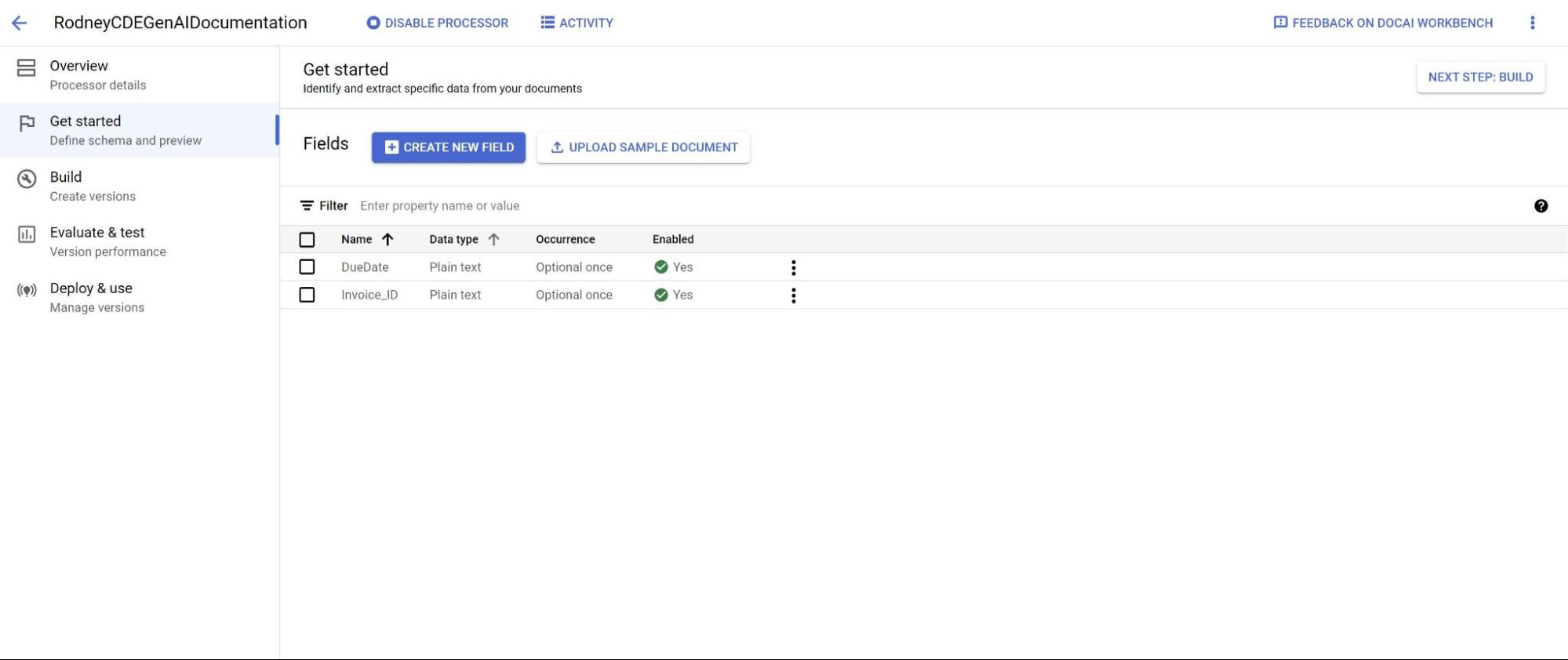
Untuk akurasi dan performa ekstraksi, tambahkan deskripsi (seperti konteks tambahan, insight, dan pengetahuan sebelumnya untuk setiap entitas) untuk jenis entitas yang harus diambil.
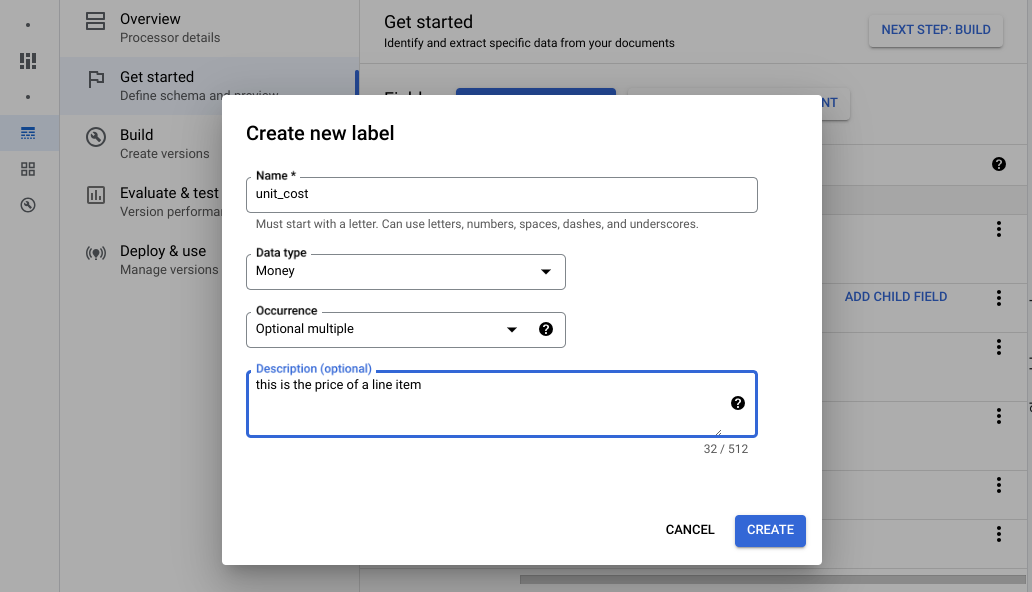
Buka tab Build, lalu pilih Import Documents.
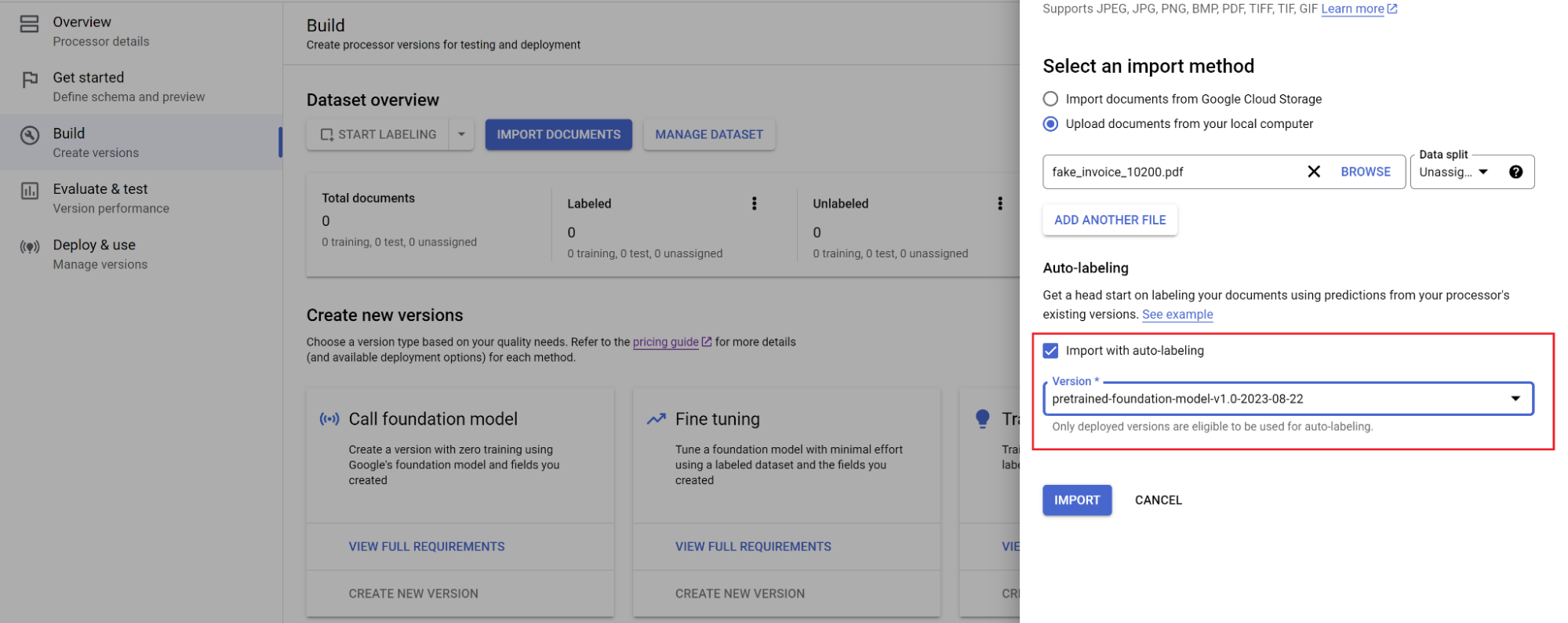
Pilih jalur dokumen dan kumpulan dokumen yang akan diimpor. Centang opsi pemberian label otomatis dan pilih model dasar.
Di tab Build, pilih Kelola Set Data.
Saat Anda melihat dokumen yang diimpor, pilih salah satunya.
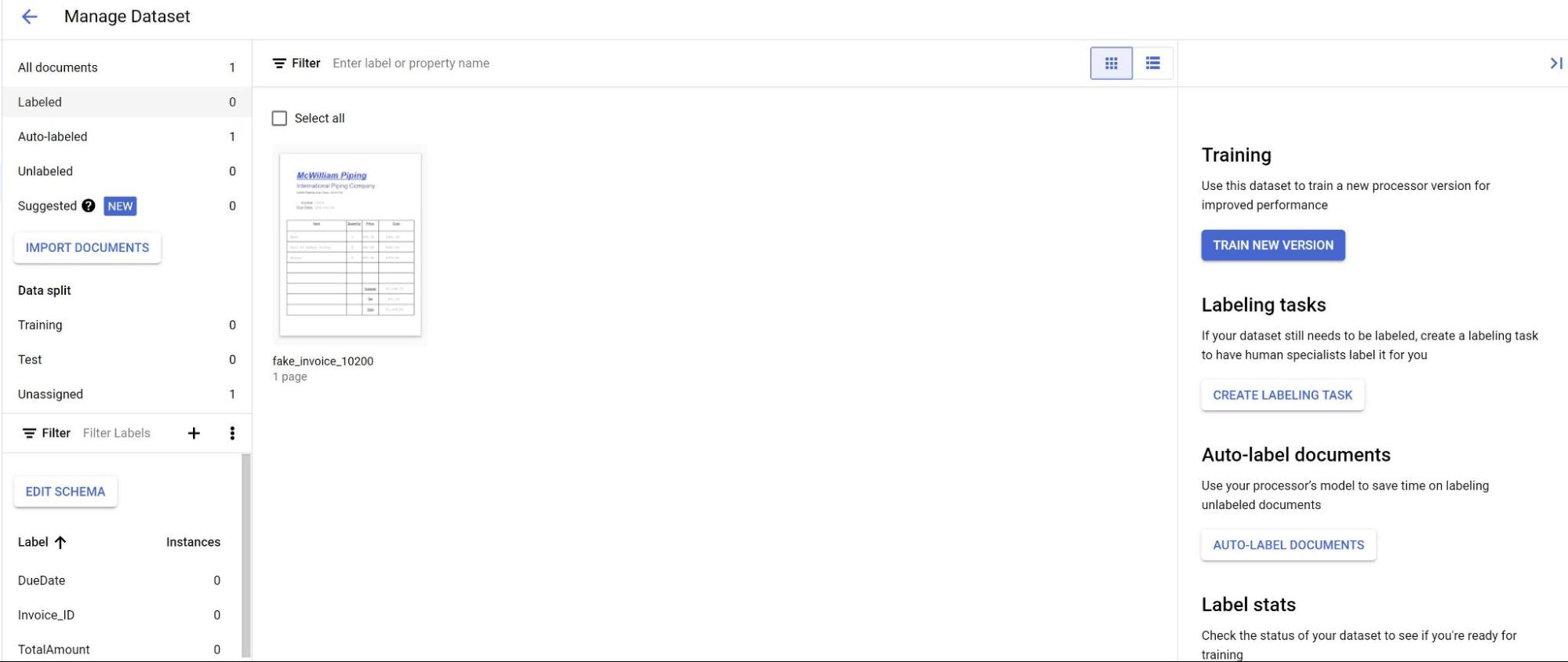
Prediksi dari model kini ditampilkan dengan warna ungu.
- Tinjau setiap label yang diprediksi oleh model, dan pastikan label tersebut sudah benar.
Jika ada kolom yang tidak ada, tambahkan juga kolom tersebut.
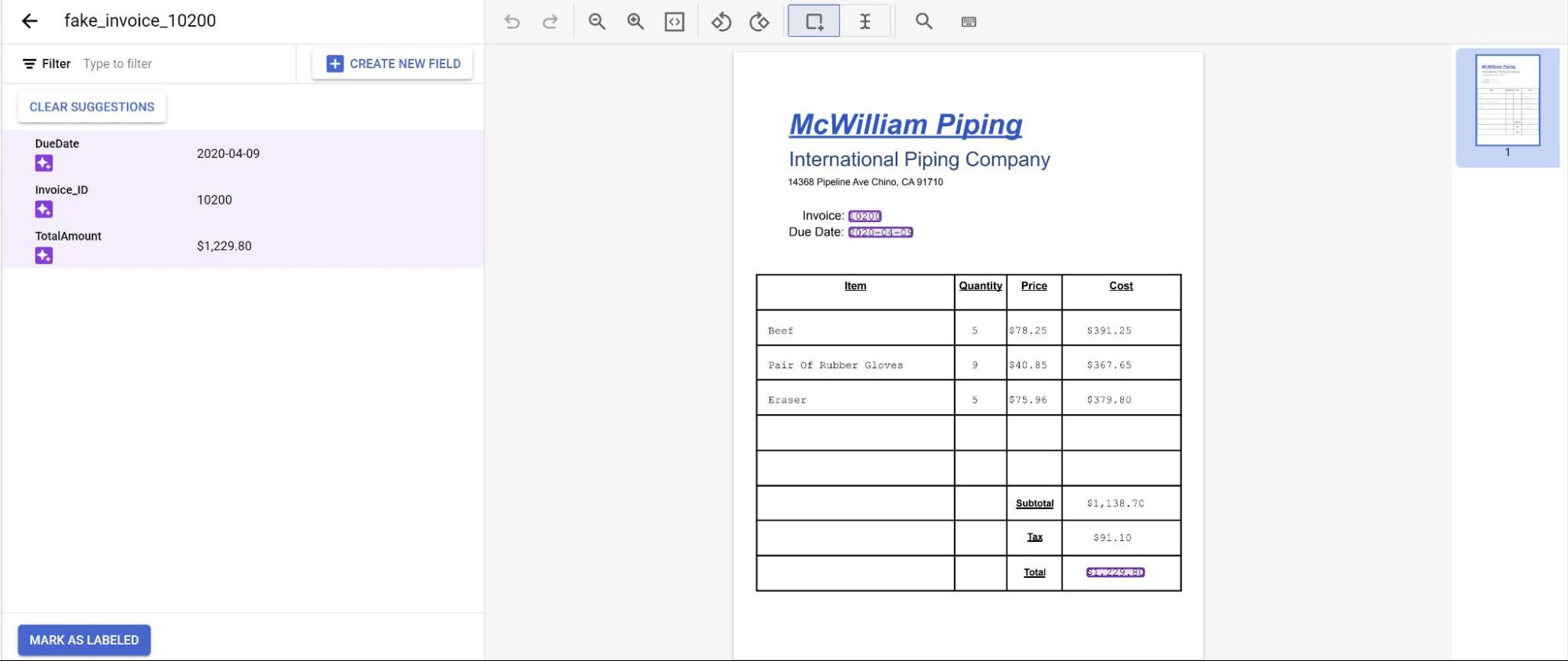
Setelah dokumen ditinjau, pilih Tandai sebagai Berlabel. Dokumen kini siap digunakan oleh model.
Pastikan dokumen berada dalam set pengujian atau pelatihan.
Penyusunan tiga tingkat
Pengekstrak Kustom kini menyediakan tiga tingkat penyusunan bertingkat. Fitur ini memberikan ekstraksi yang lebih baik untuk tabel yang kompleks.
Anda dapat menentukan jenis model menggunakan panggilan API berikut:
Responsnya adalah ProcessorVersion, yang berisi kolom modelType dalam pratinjau v1beta3.
Prosedur dan contoh
Kita menggunakan contoh ini:
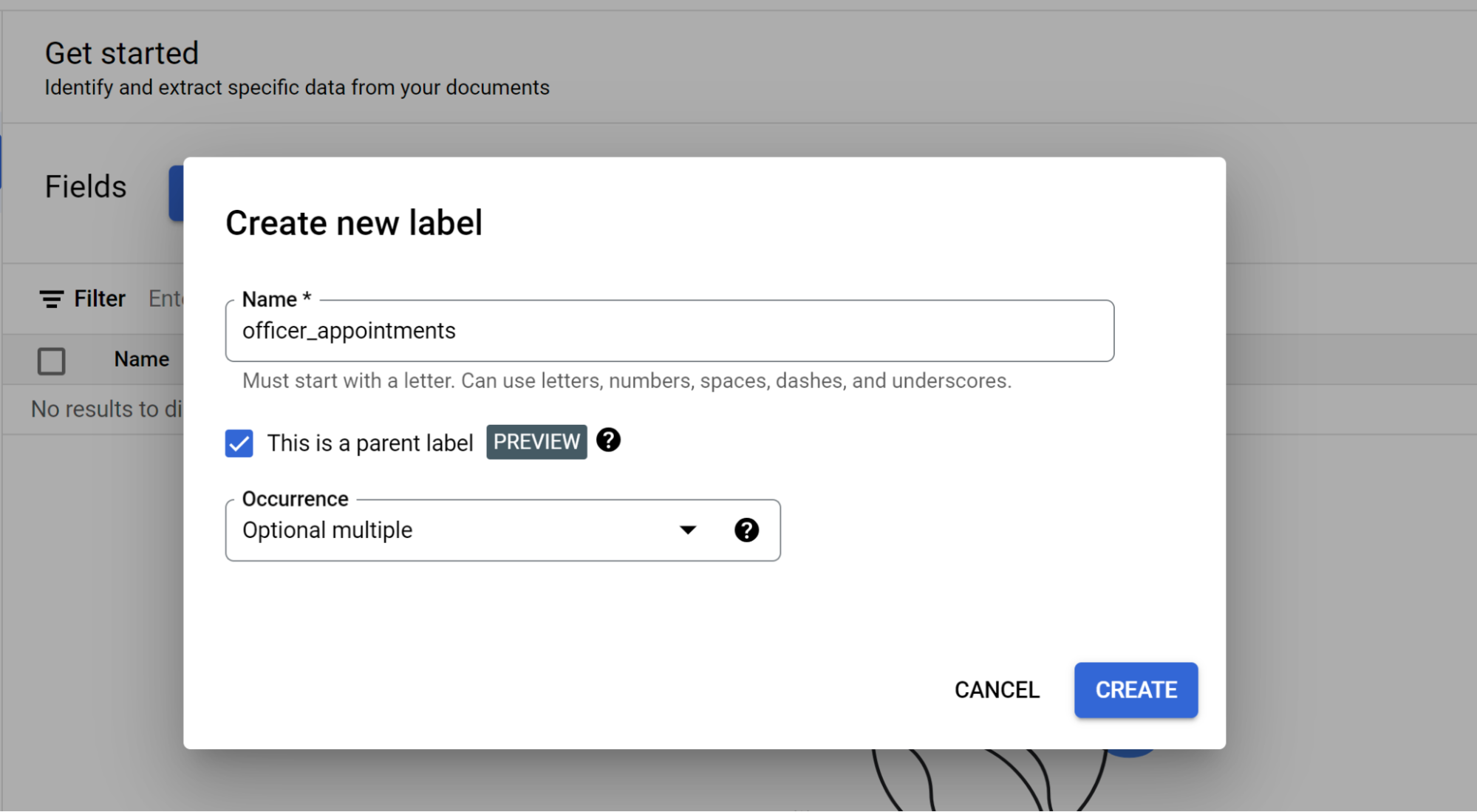
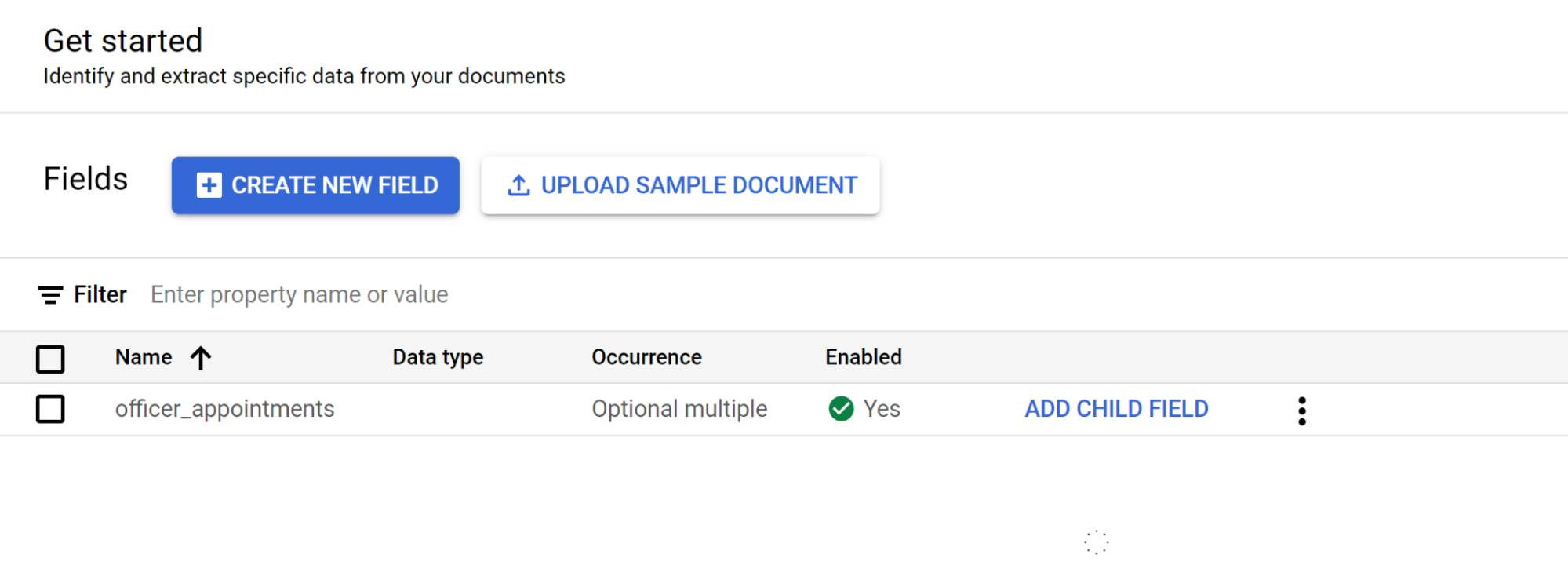
Pilih Mulai, lalu buat kolom:
- Buat tingkat teratas.
- Dalam contoh ini,
officer_appointmentsdigunakan. - Pilih Ini adalah label induk.
- Pilih Kemunculan:
Optional multiple.
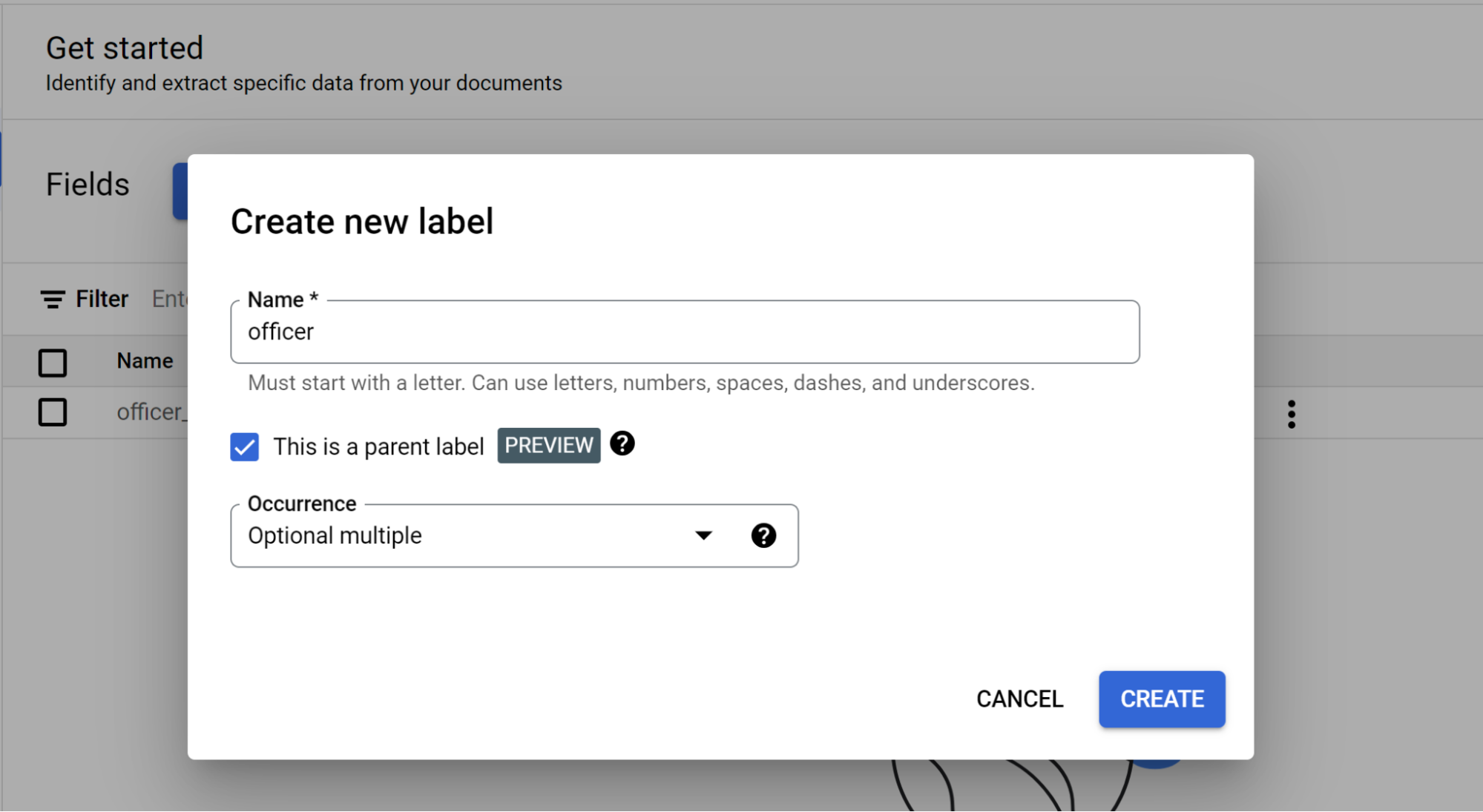
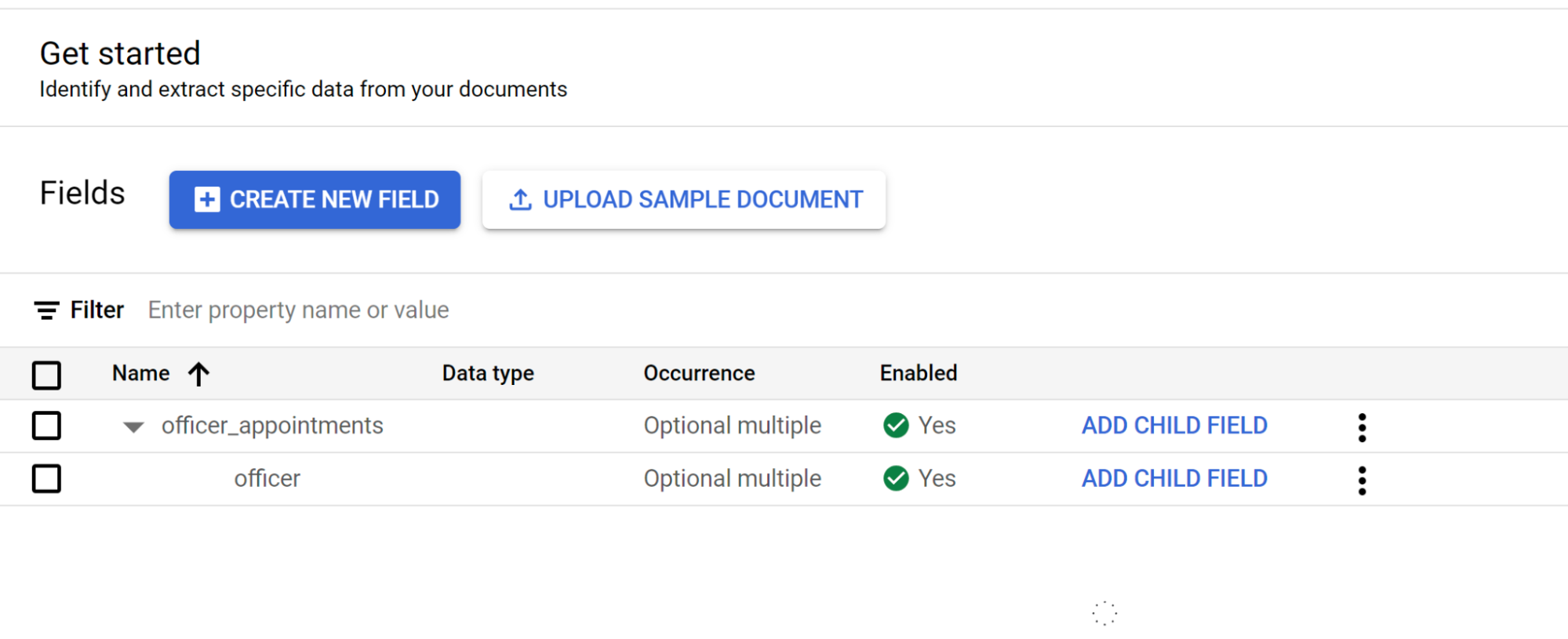
Pilih Tambahkan kolom turunan. Label tingkat kedua kini dapat dibuat:
- Untuk label tingkat ini, buat
officer. - Pilih Ini adalah label induk.
- Pilih Kemunculan:
Optional multiple.
- Untuk label tingkat ini, buat
Pilih Tambahkan kolom turunan dari
officertingkat kedua. Buat label turunan untuk tingkat ketiga penataan.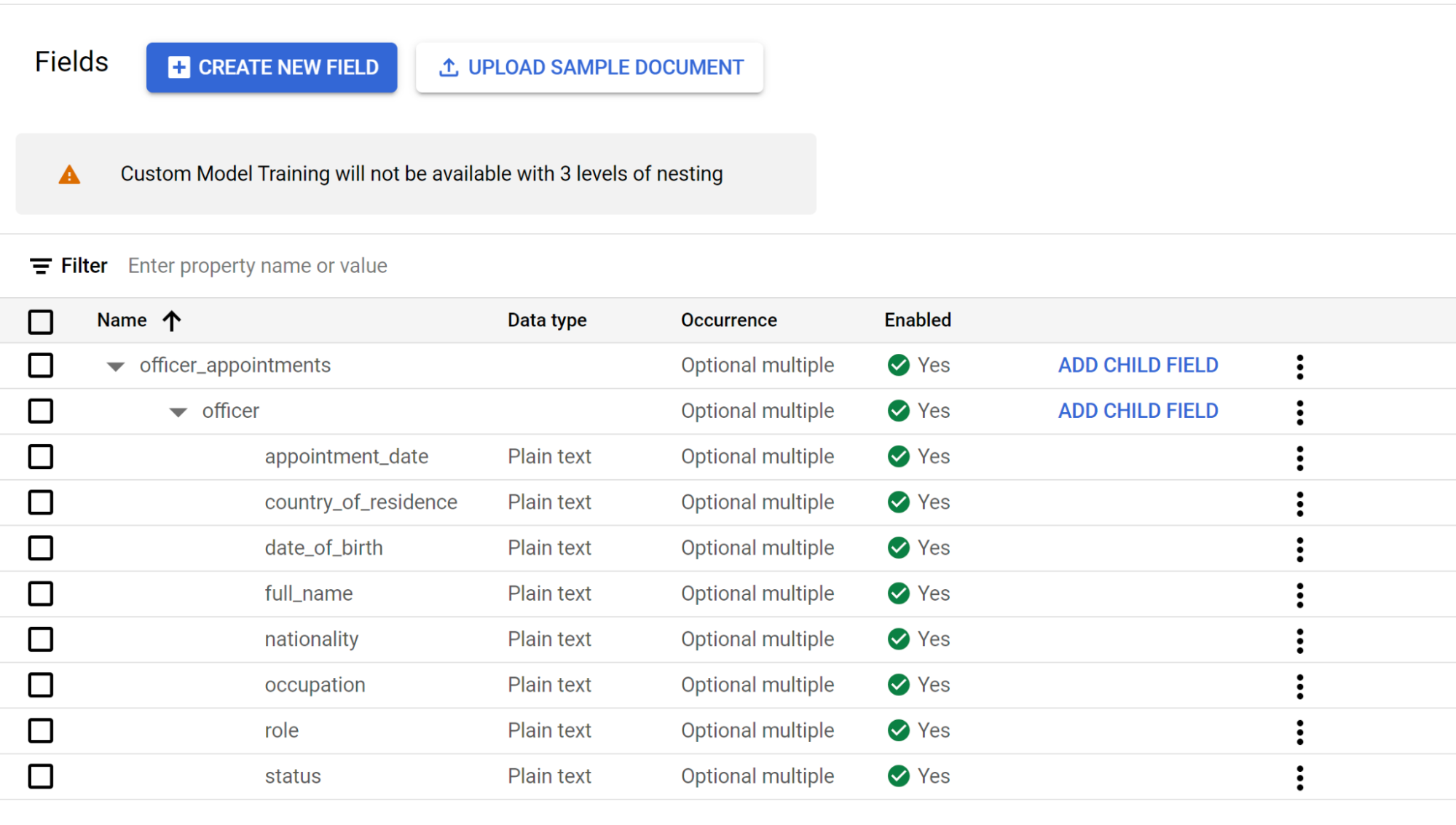
Setelah skema Anda ditetapkan, Anda bisa mendapatkan prediksi dari dokumen dengan tiga tingkat penyusunan menggunakan pelabelan otomatis.
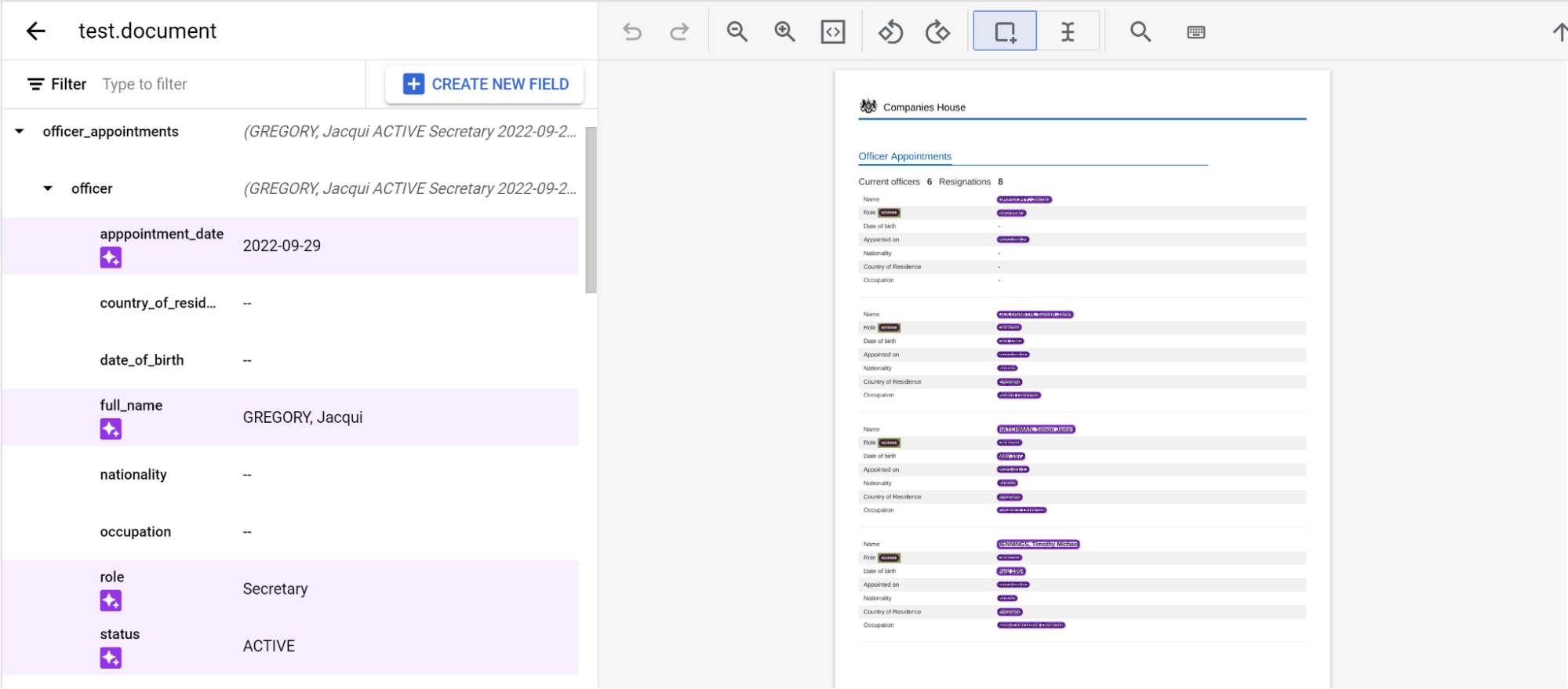
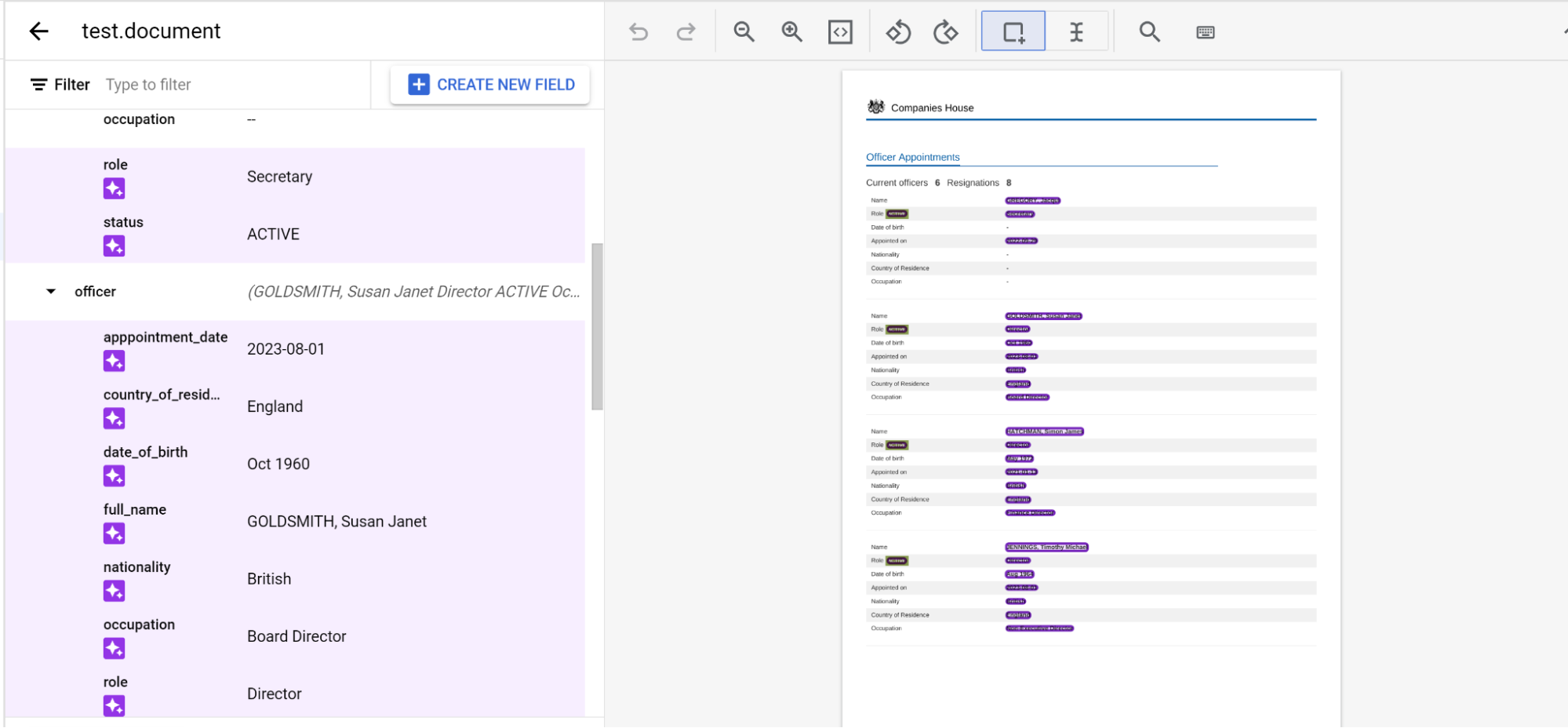
Memberi label pada entitas bertingkat lintas halaman
Prosesor pretrained-foundation-model-v1.5-2025-05-05 mendukung susunan tiga tingkat di seluruh
halaman.
Beri label pada entity secara normal di seluruh halaman. Catatan: Entitas berlabel hanya akan terlihat di halaman tempat entitas tersebut diberi label, dengan menu navigasi yang berubah dari halaman ke halaman. Dengan menyematkan entitas induk, menu navigasi ini akan tetap ada.
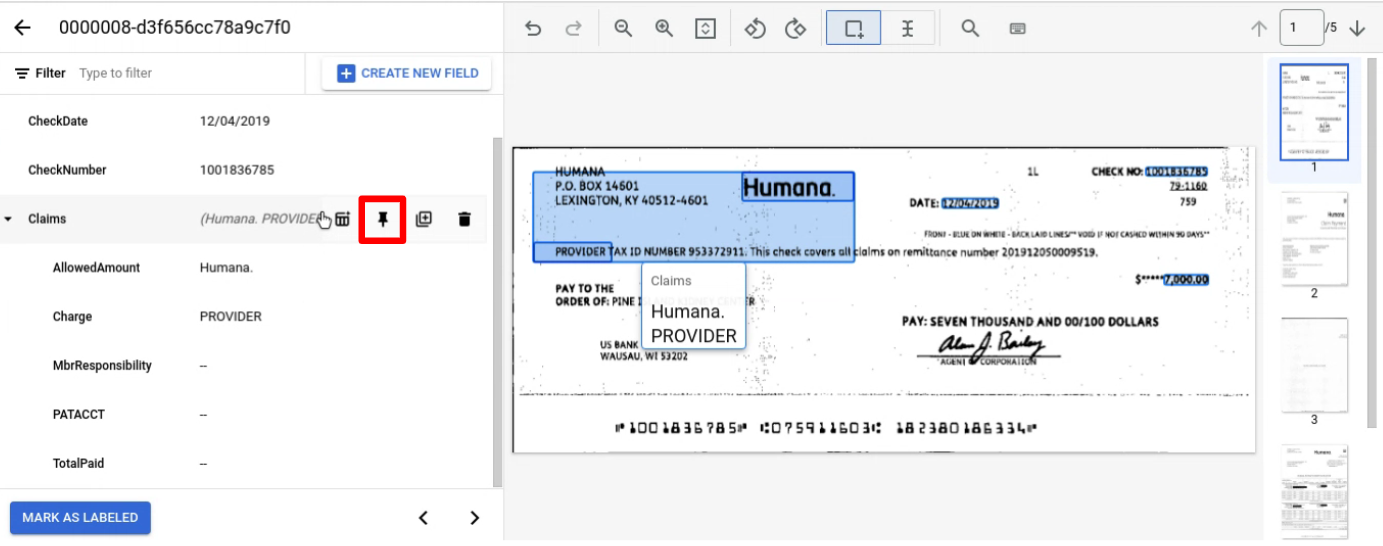
Sematkan entitas induk dengan turunan yang ingin Anda beri label di seluruh halaman.
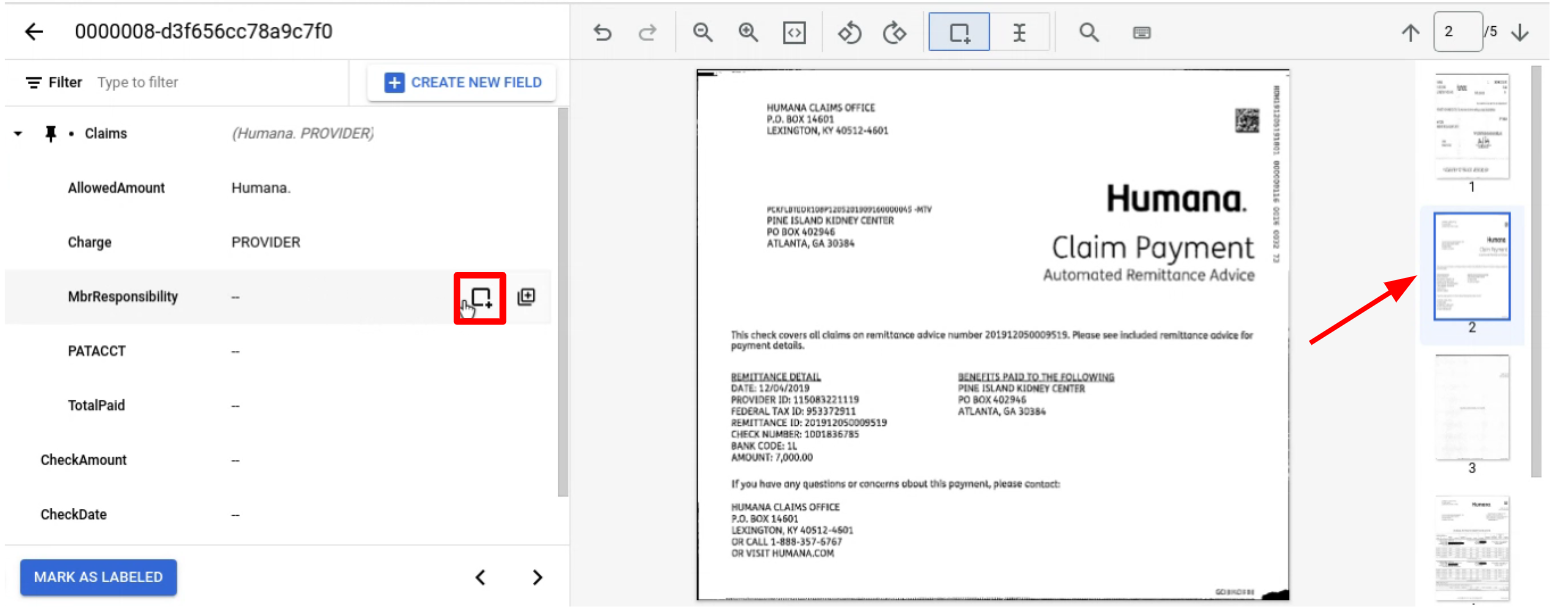
Buka halaman yang berisi entitas turunan yang akan diberi label.
Konfigurasi set data
Set data dokumen diperlukan untuk melatih, melatih ulang, atau mengevaluasi versi pemroses. Prosesor Document AI belajar dari contoh, seperti halnya manusia. Set data memicu stabilitas prosesor dalam hal performa.Set data pelatihan
Untuk meningkatkan model dan akurasinya, latih set data pada dokumen Anda. Model terdiri dari dokumen dengan kebenaran dasar.- Untuk penyesuaian, Anda memerlukan minimal 1 dokumen untuk melatih model baru dengan versi
untuk
pretrained-foundation-model-v1.2-2024-05-10danpretrained-foundation-model-v1.3-2024-08-31. - Untuk few-shot, sebaiknya gunakan lima dokumen.
- Untuk zero-shot, hanya skema yang diperlukan.
Set data pengujian
Set data pengujian adalah yang digunakan model untuk menghasilkan skor F1 (akurasi). Set data ini terdiri dari dokumen dengan kebenaran dasar. Untuk melihat seberapa sering model benar, kebenaran dasar digunakan untuk membandingkan prediksi model (kolom yang diekstrak dari model) dengan jawaban yang benar. Set data pengujian harus memiliki minimal satu dokumen untukpretrained-foundation-model-v1.2-2024-05-10 dan
pretrained-foundation-model-v1.3-2024-08-31.
Pengekstrak kustom dengan deskripsi properti
Dengan deskripsi properti, Anda dapat melatih model dengan mendeskripsikan seperti apa kolom berlabel tersebut. Anda dapat memberikan konteks dan insight tambahan untuk setiap entitas. Hal ini memungkinkan model dilatih dengan mencocokkan kolom yang sesuai dengan deskripsi yang Anda berikan dan meningkatkan akurasi ekstraksi. Deskripsi properti dapat ditentukan untuk entitas induk dan turunan.
Contoh deskripsi properti yang baik mencakup informasi lokasi dan pola teks nilai properti, yang membantu memperjelas potensi sumber kebingungan dalam dokumen. Deskripsi properti yang jelas dan tepat memandu model dengan aturan yang meningkatkan ekstraksi yang lebih andal dan konsisten, terlepas dari struktur dokumen atau variasi konten tertentu.
Memperbarui skema dokumen untuk pemroses
Untuk mengetahui cara menetapkan deskripsi properti, lihat Memperbarui skema dokumen.
Mengirim permintaan pemrosesan dengan deskripsi properti
Jika skema dokumen sudah memiliki deskripsi yang ditetapkan, Anda dapat mengirim permintaan pemrosesan dengan petunjuk di Mengirim permintaan pemrosesan.
Menyesuaikan pemroses dengan deskripsi properti
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- LOCATION: lokasi pemroses Anda, misalnya:
us- Amerika Serikateu- Uni Eropa
- PROJECT_ID: ID project Google Cloud Anda.
- PROCESSOR_ID: ID pemroses kustom Anda.
- DISPLAY_NAME: Nama tampilan untuk pemroses.
- PRETRAINED_PROCESSOR_VERSION: ID versi prosesor. Lihat Memilih versi prosesor untuk mengetahui informasi selengkapnya. Misalnya:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: Langkah-langkah pelatihan untuk penyesuaian model.
- LEARN_RATE_MULTIPLIER: Pengganda laju pembelajaran untuk penyesuaian model.
- DOCUMENT_SCHEMA: Skema untuk pemroses. Lihat representasi DocumentSchema.
Metode HTTP dan URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Isi JSON permintaan:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Simpan isi permintaan dalam file bernama request.json,
dan jalankan perintah berikut:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Pengekstrak kustom dengan deteksi tanda tangan
(Pratinjau publik) Pengekstrak kustom mendukung deteksi tanda tangan. Fitur ini memungkinkan Anda mendeteksi keberadaan
tanda tangan dalam dokumen. Deteksi tanda tangan hanya tersedia dengan menggunakan
jenis metode derived. Anda dapat menentukan skema dengan jenis entity signature
untuk entitas tersebut. Entitas tanda tangan diperoleh menggunakan petunjuk visual dari dokumen.
Untuk contoh dan petunjuk konfigurasi, klik Ekstraktor kustom dengan kolom turunan dan deteksi tanda tangan.
Pengekstrak kustom dengan kolom turunan
Ekstraktor kustom mendukung kolom turunan. Dengan begitu, Anda dapat mengonfigurasi kolom agar diisi melalui inferensi atau pembuatan cerdas berdasarkan konteks dokumen, bukan ekstraksi teks langsung. Anda dapat menggunakannya untuk kasus penggunaan seperti menyimpulkan negara dari alamat, meringkas dokumen, menghitung item dalam tabel, atau mendeteksi apakah tanda pengenal asli, tanpa memerlukan nilai yang ada secara eksplisit dalam teks.
Untuk contoh dan petunjuk konfigurasi, klik Ekstraktor kustom dengan kolom turunan dan deteksi tanda tangan.
Langkah berikutnya
Pelajari Pengekstrak kustom dengan kolom turunan dan deteksi tanda tangan.