A preparação e a extração de IA generativa permitem-lhe:
- Use a tecnologia de zero-shot e few-shot para obter um modelo de alto desempenho com poucos ou nenhum dado de preparação usando o modelo base.
- Use o ajuste fino para aumentar ainda mais a precisão à medida que fornece cada vez mais dados de preparação.
Métodos de preparação de IA generativa
O método de preparação que escolher depende da quantidade de documentos que tem disponíveis e do esforço que pode dedicar à preparação do modelo. Existem três formas de preparar um modelo de IA generativa:
| Método de preparação | Zero-shot | Few-shot | Ajuste |
|---|---|---|---|
| Precisão | Médio | Média a elevada | Alto |
| Esforço | Baixo | Baixo | Médio |
| Número recomendado de documentos de preparação | 0 | 5 a 10 | 10 a 50+ |
Versões do modelo de extrator personalizado
Os seguintes modelos estão disponíveis para o extrator personalizado. Para alterar as versões dos modelos, consulte o artigo Gerir versões do processador.
As versões 1.4, 1.5 e 1.5 Pro suportam pontuações de confiança.
| Versão do modelo | Descrição | Canal de lançamento | Processamento de ML nos EUA/UE | Ajuste nos EUA/UE | Data de lançamento |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Modelo de disponibilidade geral com tecnologia do MDL/CE Gemini 2.0 Flash. Também inclui funcionalidades de OCR avançadas, como a deteção de caixas de verificação. | Estável | Sim | EUA, UE | 5 de fevereiro de 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Candidato pronto para produção com tecnologia do MDL/CE Gemini 2.5 Flash. Recomendado para quem quer experimentar modelos mais recentes. | Estável | Sim | US, EU (Pré-visualização) | 5 de maio de 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Modelo pronto para produção com tecnologia do MDL/CE Gemini 2.5 Pro. Suporta uma quota de até 30 páginas por minuto para pedidos de processos online. Este modelo tem uma qualidade melhorada em comparação com a v1.5 e pode ter uma latência mais elevada. | Estável | Sim | Não | 20 de junho de 2025 |
Para alterar a versão do processador no seu projeto, reveja o artigo Gerir versões do processador.
Para fazer um pedido de aumento de quota (QIR) para a quota do processador predefinida, siga os passos em Faça a gestão da sua quota.
Configuração inicial
Se ainda não o fez, ative a faturação e as APIs Document AI.
Crie e avalie um modelo de IA generativa
Crie um processador e defina os campos que quer extrair seguindo as práticas recomendadas, o que é importante porque afeta a qualidade da extração.
- Aceda a Workbench > Extrator personalizado > Criar processador > Atribuir um nome.
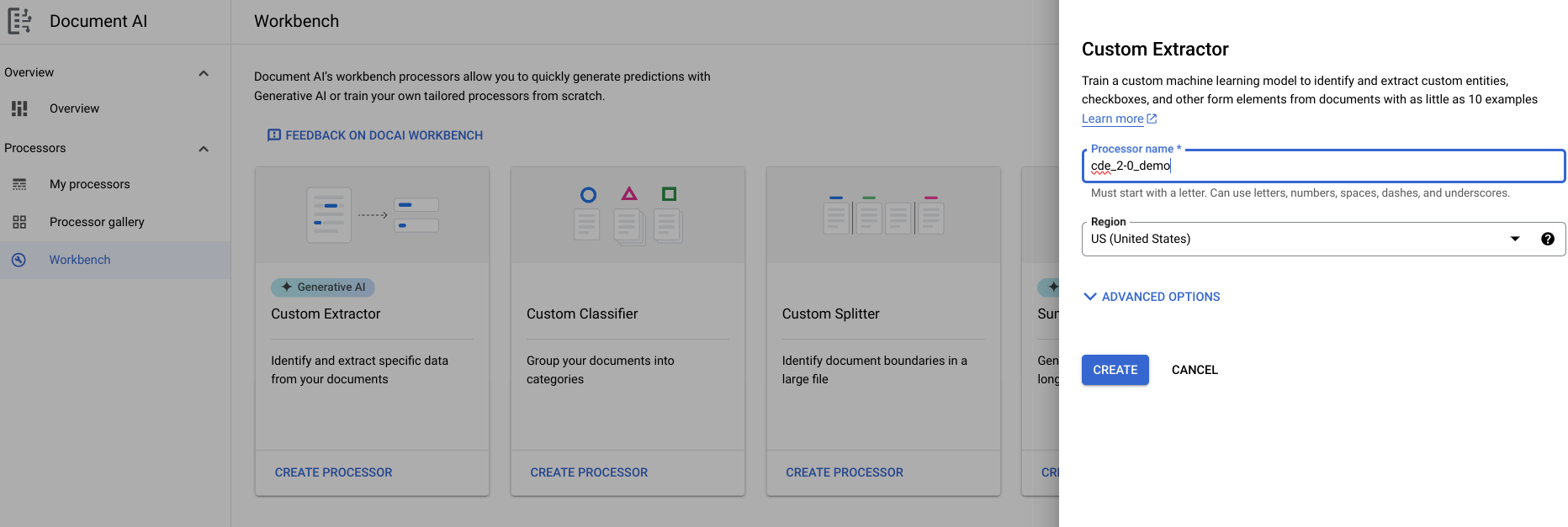
- Aceda a Começar > Criar novo campo.
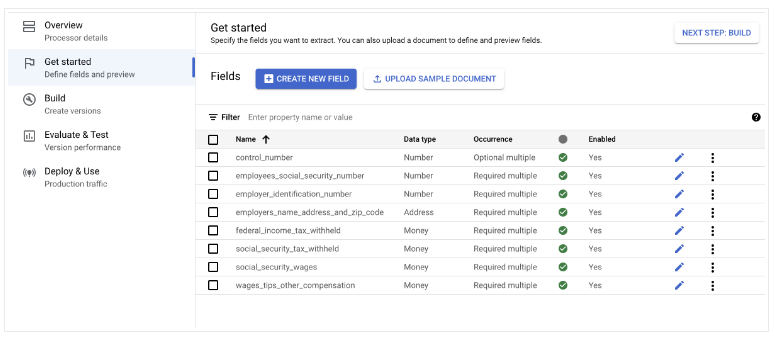
Importe documentos
- Importe documentos com etiquetagem automática e atribua documentos ao conjunto de preparação e de teste.
- Para o zero-shot, apenas o esquema é necessário. Para avaliar a precisão do modelo, apenas é necessário um conjunto de testes.
- Para o few-shot, recomendamos cinco documentos de preparação.
- O número de documentos de teste necessários depende do exemplo de utilização. Geralmente, é melhor ter mais documentos de teste.
- Confirme ou edite as etiquetas no documento.
Modelo de comboio:
- Selecione Criar e, de seguida, Criar nova versão.
- Introduza um nome e selecione Criar.
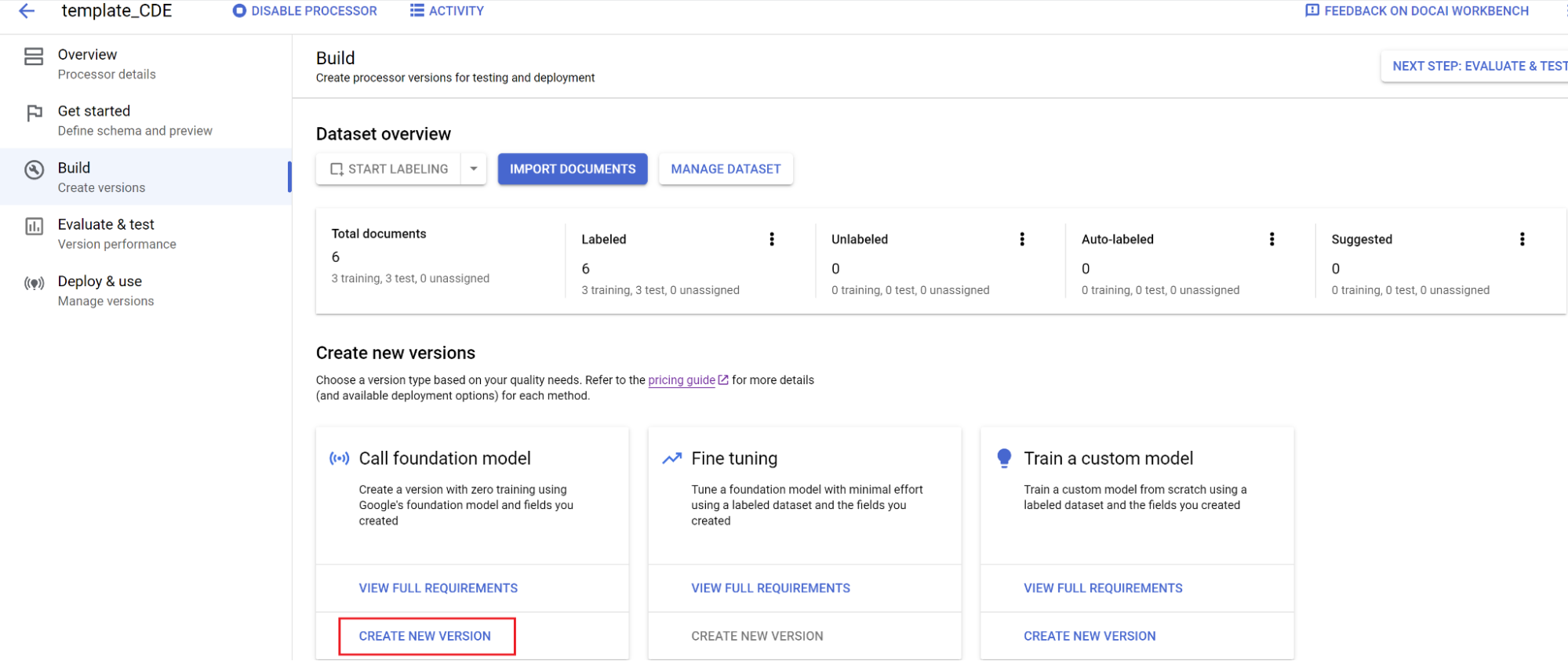
Avaliação:
- Aceda a Avaliar e testar, selecione a versão que acabou de preparar e, de seguida, selecione Ver avaliação completa.
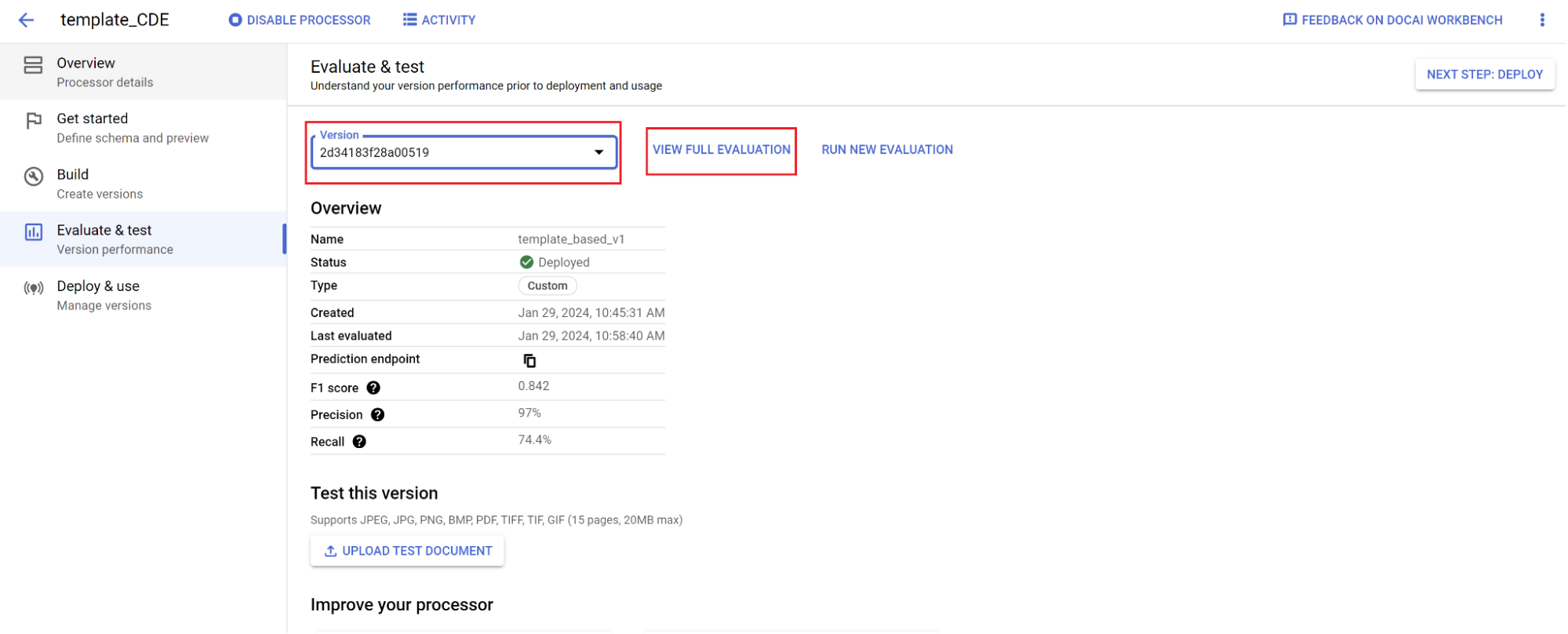
- Agora, vê métricas como f1, precisão e recall para todo o documento e cada campo.
- Decida se o desempenho cumpre os seus objetivos de produção. Se não cumprir, reavalie os conjuntos de preparação e de testes.
Defina uma nova versão como predefinição:
- Navegue para Gerir versões.
- Selecione para expandir as opções e, de seguida, selecione Definir como predefinição.
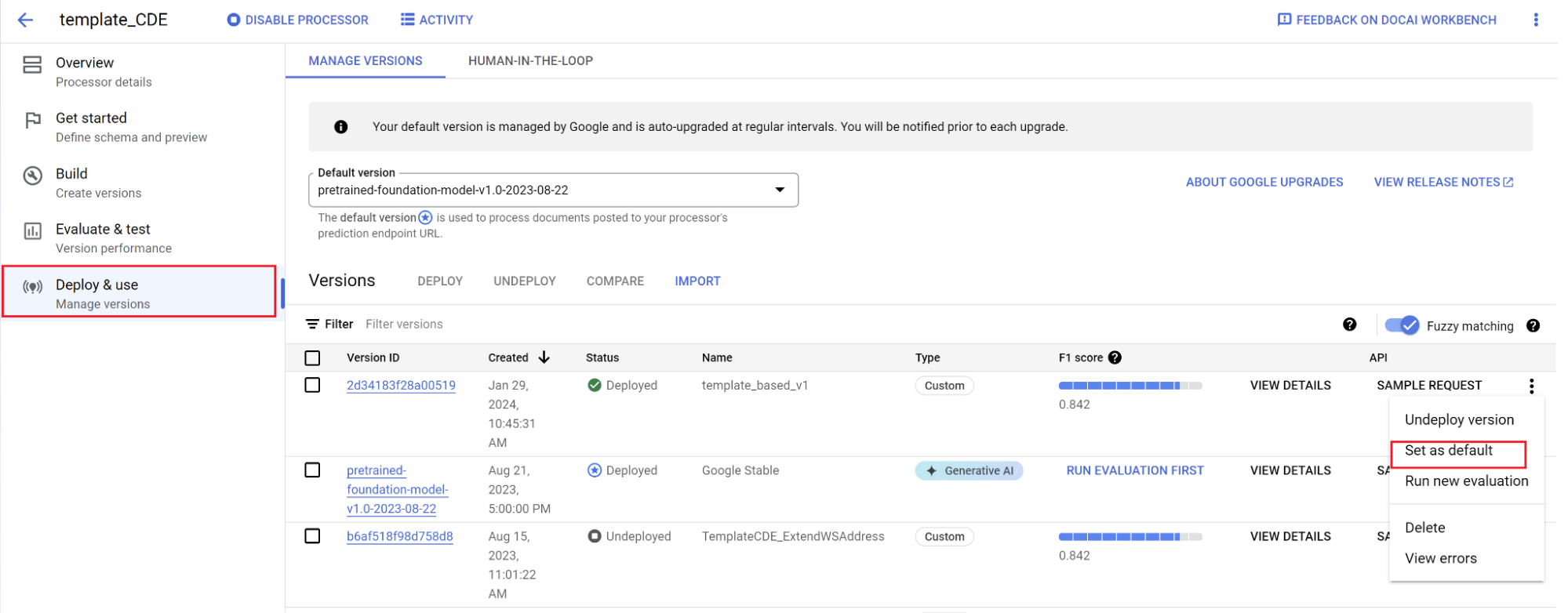
O seu modelo está agora implementado. Os documentos enviados para este processador usam a sua versão personalizada. Pode avaliar o desempenho do modelo para verificar se requer mais preparação.
Referência de avaliação
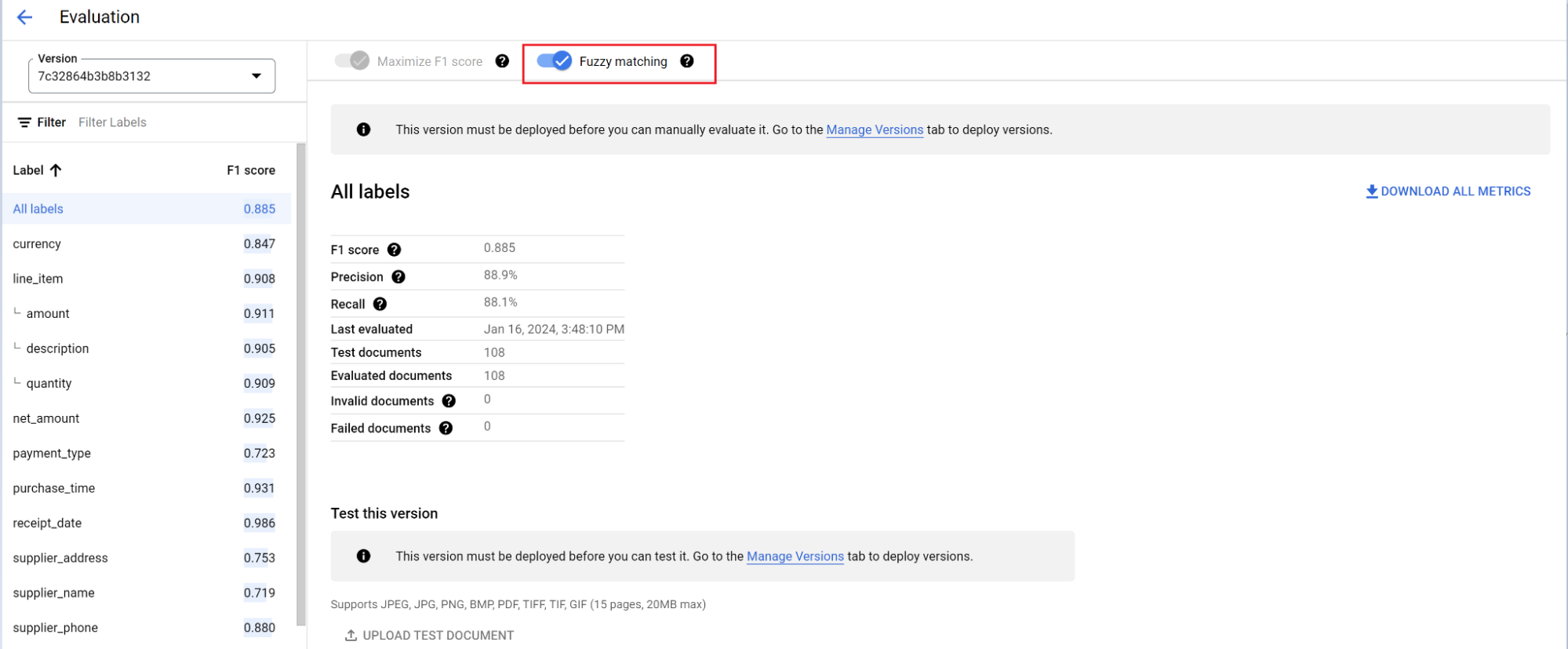
O motor de avaliação pode fazer correspondência exata ou correspondência aproximada. Para uma correspondência exata, o valor extraído tem de corresponder exatamente à verdade fundamental ou é contabilizado como uma falha.
As extrações de correspondência aproximada que tinham pequenas diferenças, como diferenças na utilização de maiúsculas e minúsculas, continuam a ser consideradas uma correspondência. Pode alterar esta opção no ecrã Avaliação.
Ajuste
Com o ajuste preciso, usa centenas ou milhares de documentos para a sua formação.
Crie um processador e defina os campos que quer extrair seguindo as práticas recomendadas, o que é importante porque afeta a qualidade da extração.
Importe documentos com etiquetagem automática e atribua documentos ao conjunto de preparação e de teste.
Confirme ou edite as etiquetas no documento.
Preparar modelo.
- Selecione o separador Criar e, de seguida, Criar nova versão na caixa Ajuste preciso.
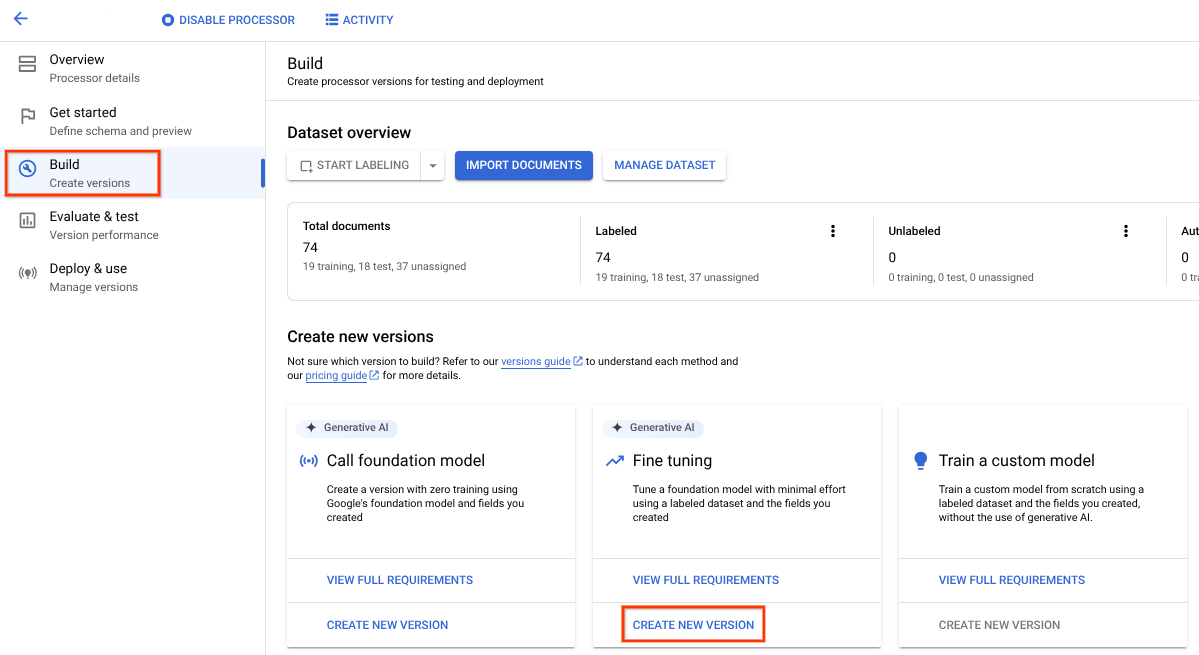
Experimente os parâmetros de preparação ou os valores predefinidos fornecidos. Se os resultados forem insatisfatórios, experimente estas opções avançadas:
Passos de preparação (entre 100 e 400): controla a frequência com que os pesos são otimizados num lote de dados durante o ajuste.
- Um valor demasiado baixo indica um risco de o treino terminar antes da convergência (ajuste insuficiente).
- Um valor demasiado elevado significa que o modelo pode ver o mesmo lote de dados várias vezes durante a preparação, o que pode levar a um ajuste excessivo.
- Menos passos resultam num tempo de preparação mais rápido. As contagens mais elevadas podem ajudar para documentos com pouca variação de modelos (e as mais baixas para aqueles com mais variação).
Multiplicador da taxa de aprendizagem (entre 0,1 e 10): controla a rapidez com que os parâmetros do modelo são otimizados nos dados de preparação. Corresponde aproximadamente ao tamanho de cada passo de preparação.
- As taxas baixas significam pequenas alterações nos pesos do modelo em cada passo de preparação. Se for demasiado baixo, o modelo pode não convergir para uma solução estável.
- As taxas elevadas indicam grandes alterações e, se forem demasiado elevadas, podem significar que o modelo ultrapassa a solução ideal e converge para uma solução abaixo do ideal.
- O tempo de preparação não é afetado pela escolha da taxa de aprendizagem.
Atribua um nome, selecione a versão do processador base necessária e selecione Criar.
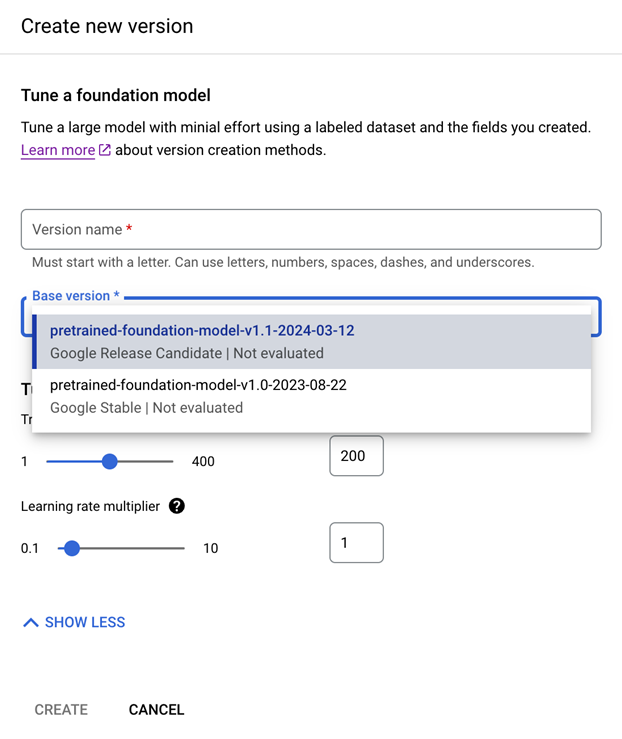
Avaliação: aceda a Avaliar e testar, selecione a versão que acabou de preparar e selecione Ver avaliação completa.
- Agora, vê métricas como f1, precisão e recall para todo o documento e cada campo.
- Decida se o desempenho cumpre os seus objetivos de produção. Caso contrário, podem ser necessários mais documentos de formação.
Defina uma nova versão como predefinição:
- Navegue para Gerir versões.
- Selecione para expandir as opções e, de seguida, selecione Definir como predefinição.
O seu modelo está agora implementado e os documentos enviados para este processador usam agora a sua versão personalizada. Quer avaliar o desempenho do modelo para verificar se requer mais preparação.
Etiquetagem automática com o modelo base
O modelo base pode extrair campos com precisão para vários tipos de documentos, mas também pode fornecer dados de preparação adicionais para melhorar a precisão do modelo para estruturas de documentos específicas.
A IA Documentos usa os nomes das etiquetas que define e as anotações anteriores para tornar a etiquetagem de documentos em grande escala mais rápida e fácil com a etiquetagem automática.
- Depois de criar um processador personalizado, aceda ao separador Começar.
- Selecione Criar novo campo.
Atribua à etiqueta um nome descritivo e distinto. Escolha Extrair para valores diretamente do documento ou Derivar para valores inferidos pelo sistema. Isto melhora a precisão e o desempenho do modelo base.
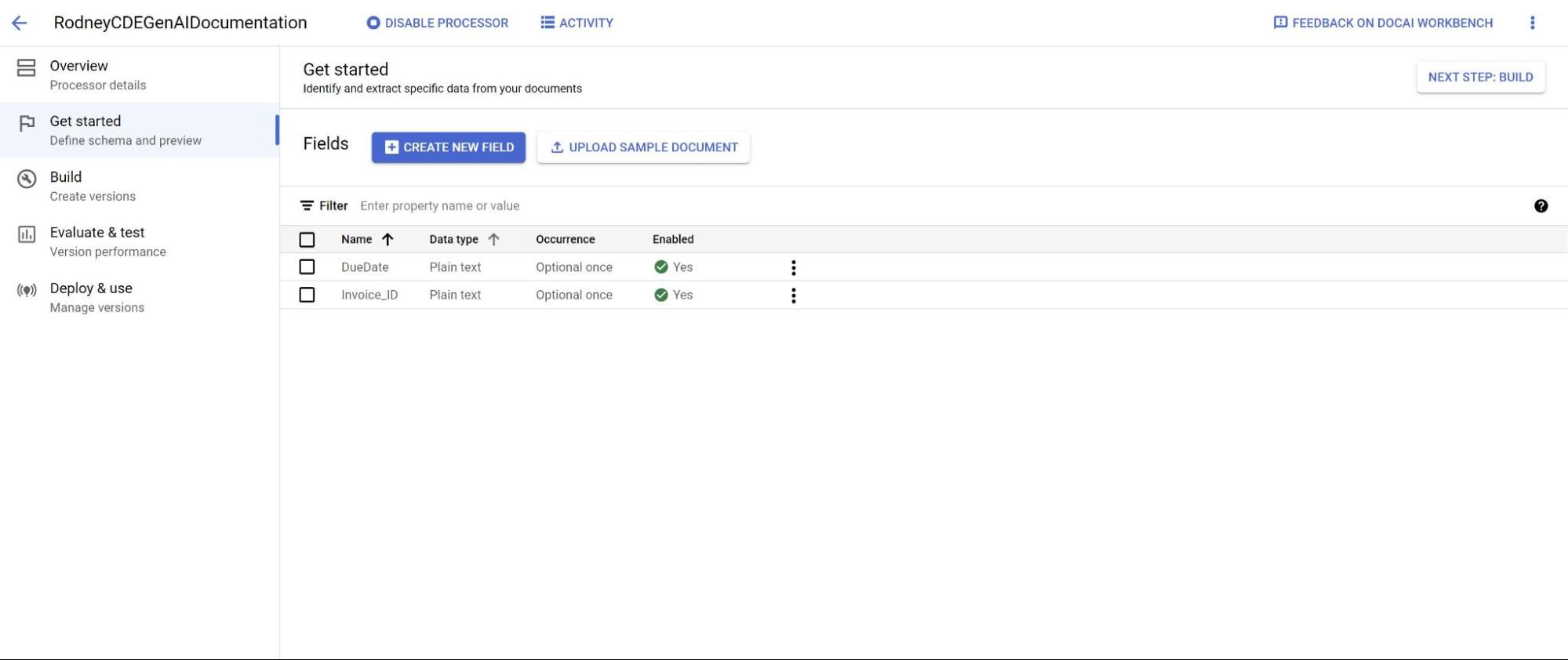
Para melhorar a precisão e o desempenho da extração, adicione uma descrição (como contexto adicional, estatísticas e conhecimentos prévios para cada entidade) dos tipos de entidades que deve detetar.
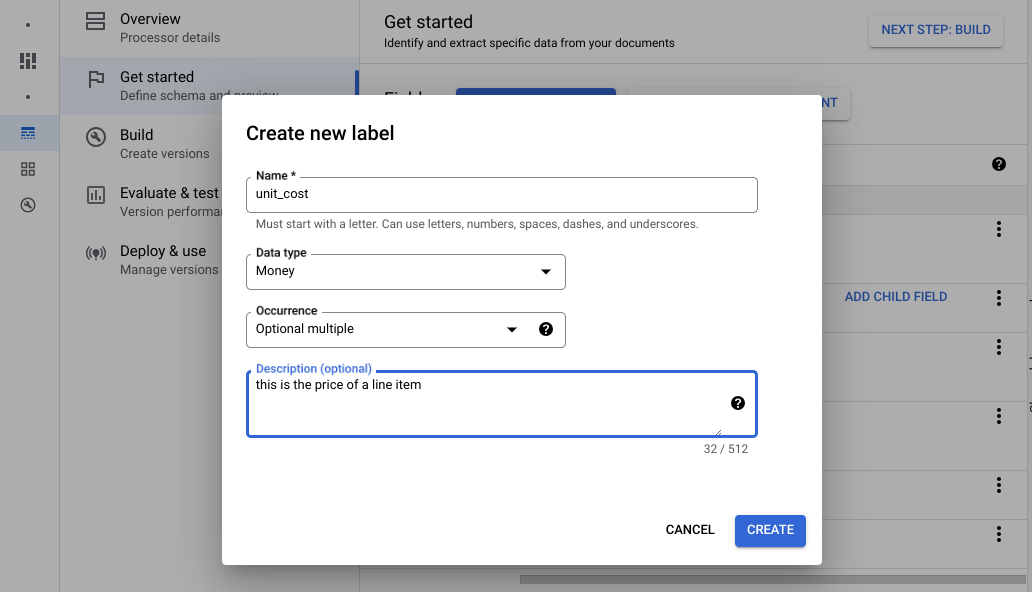
Navegue para o separador Criar e, de seguida, selecione Importar documentos.
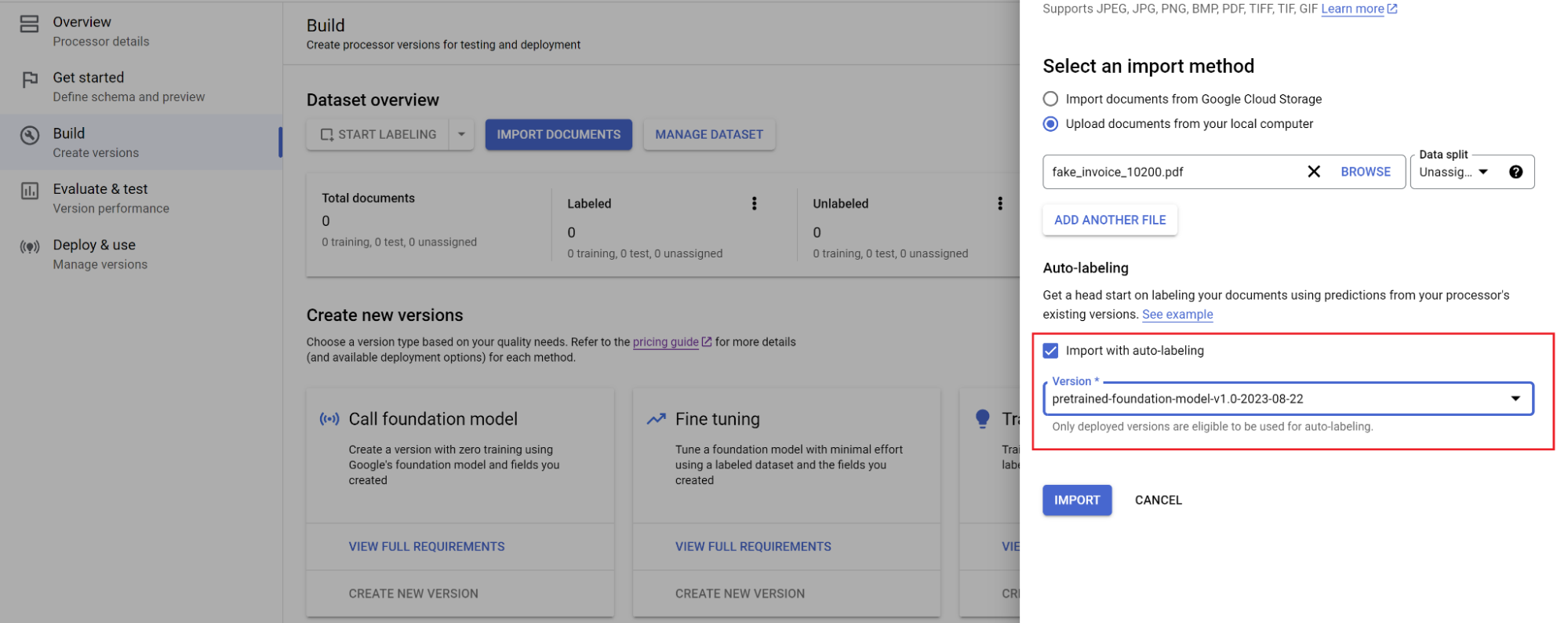
Selecione o caminho dos documentos e o conjunto para o qual os documentos devem ser importados. Selecione a opção de etiquetagem automática e o modelo base.
No separador Criar, selecione Gerir conjunto de dados.
Quando vir os documentos importados, selecione um deles.
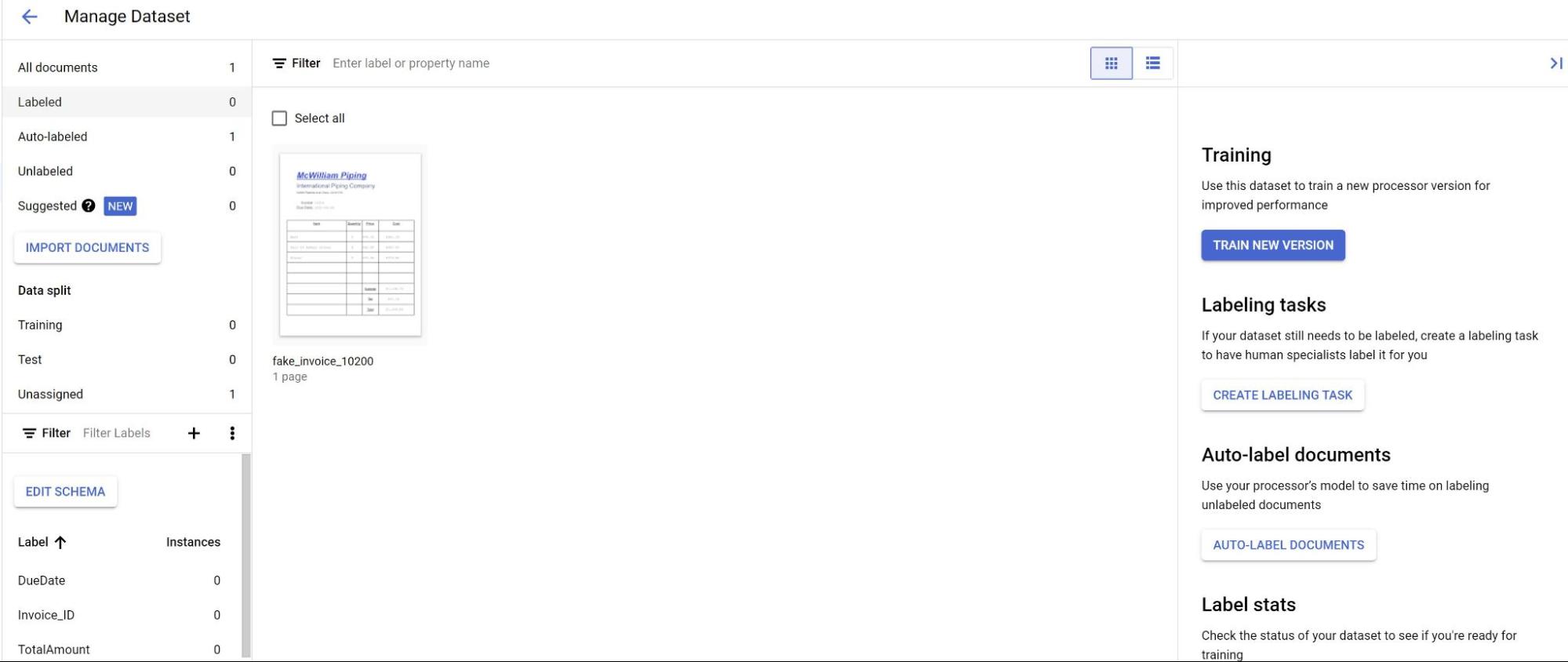
As previsões do modelo são agora apresentadas realçadas a roxo.
- Reveja cada etiqueta prevista pelo modelo e verifique se está correta.
Se existirem campos em falta, adicione-os também.
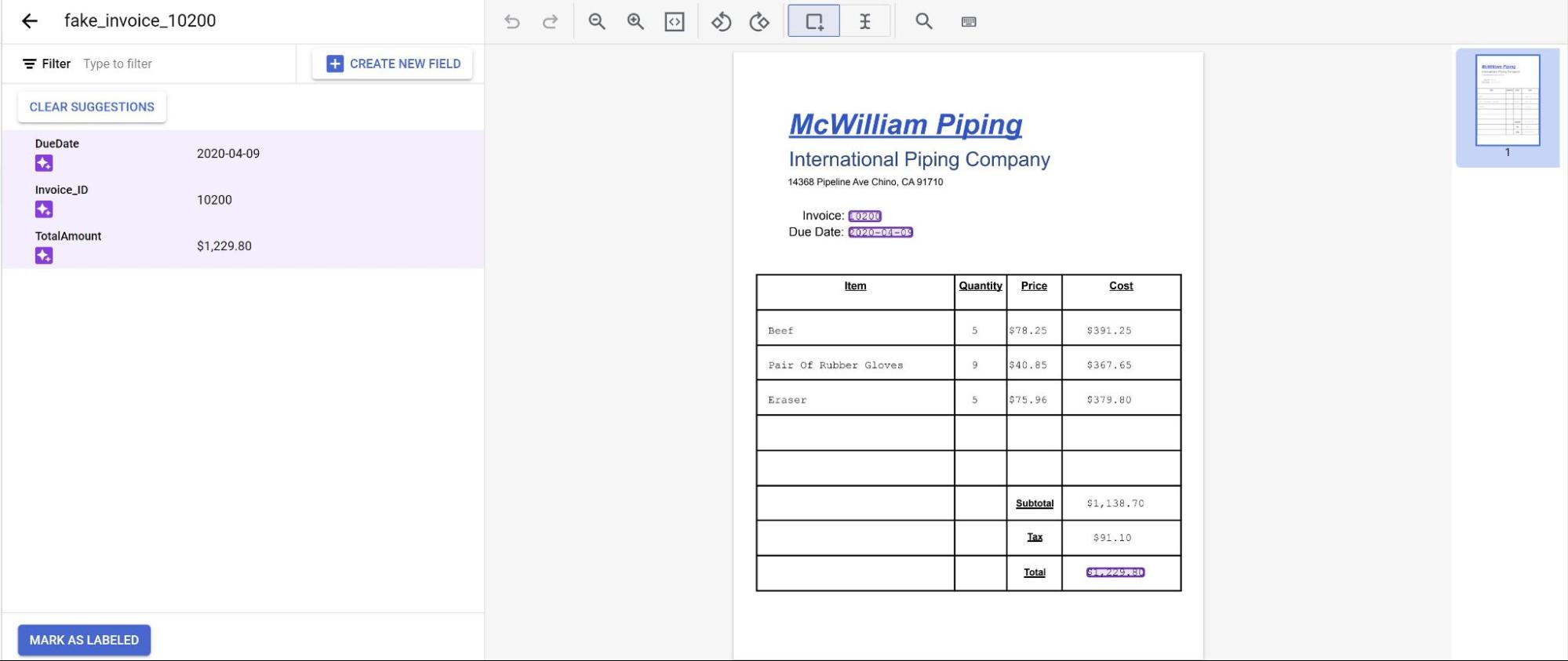
Quando o documento tiver sido revisto, selecione Marcar como etiquetado. O documento está agora pronto para ser usado pelo modelo.
Certifique-se de que o documento está no conjunto de testes ou de preparação.
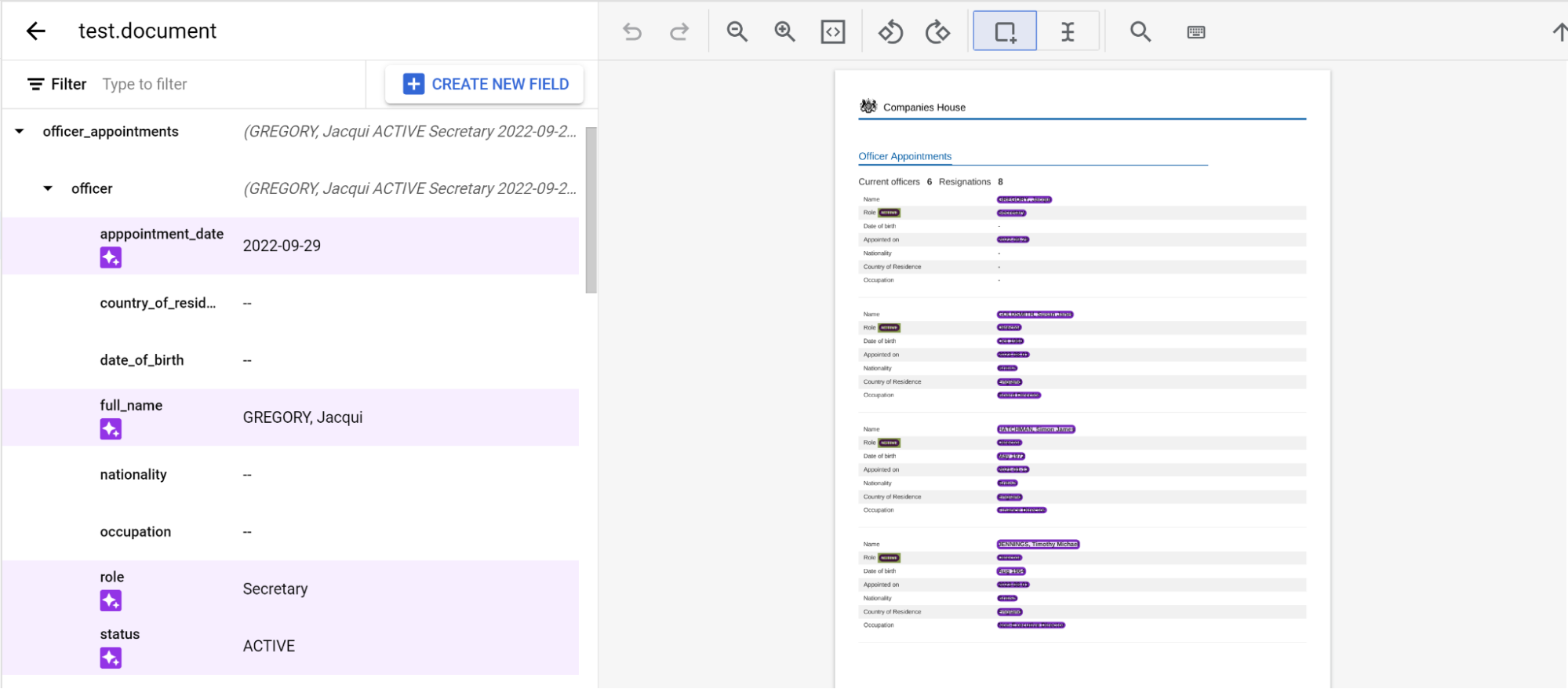
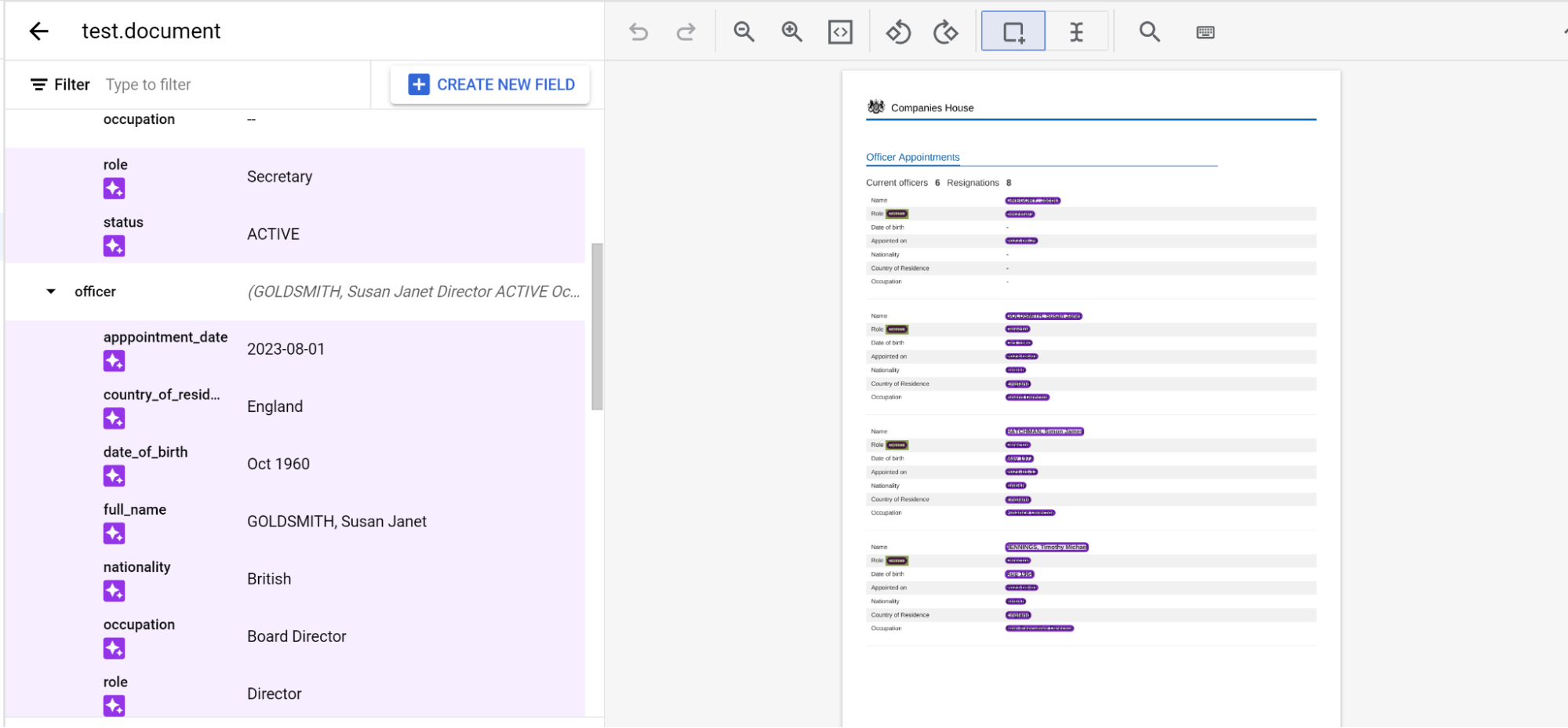
Aninhamento de três níveis
O extrator personalizado oferece agora três níveis de aninhamento. Esta funcionalidade oferece uma melhor extração para tabelas complexas.
Pode determinar o tipo de modelo através das seguintes chamadas da API:
A resposta destes é um ProcessorVersion, que contém o campo modelType na pré-visualização v1beta3.
Procedimento e exemplo
Estamos a usar esta amostra:
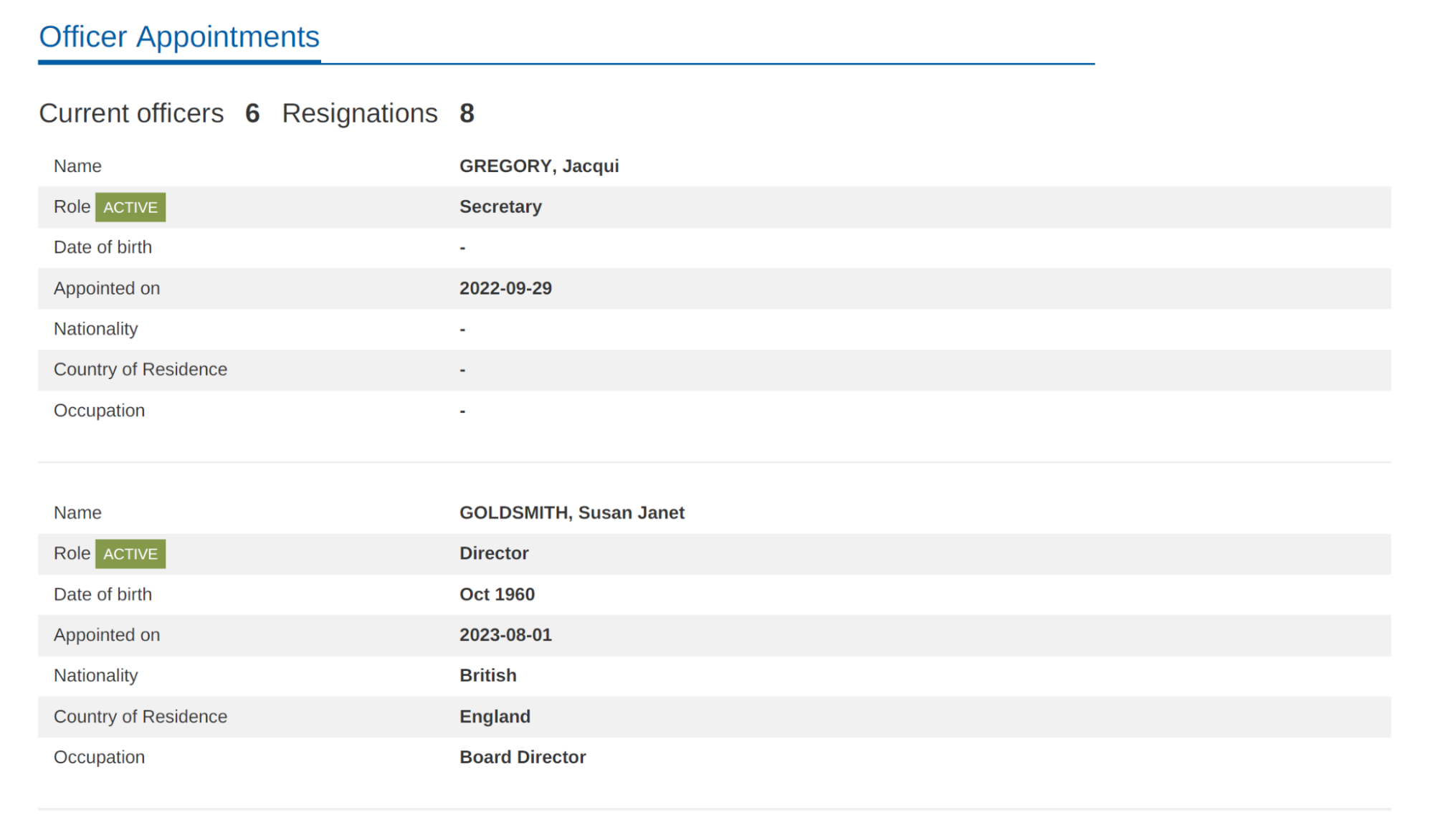
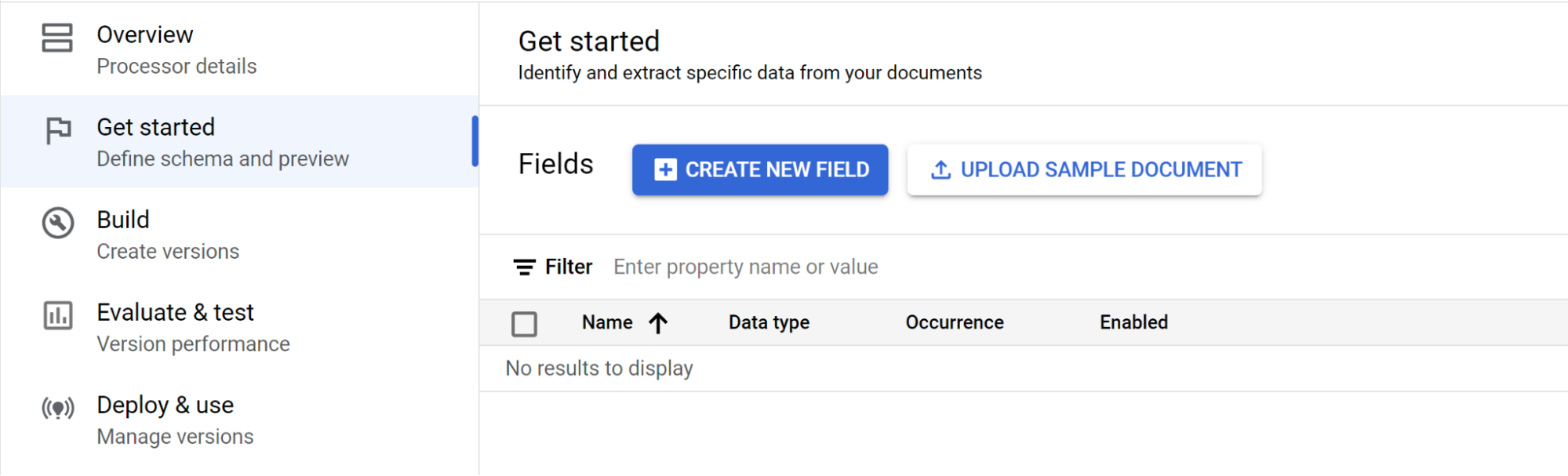
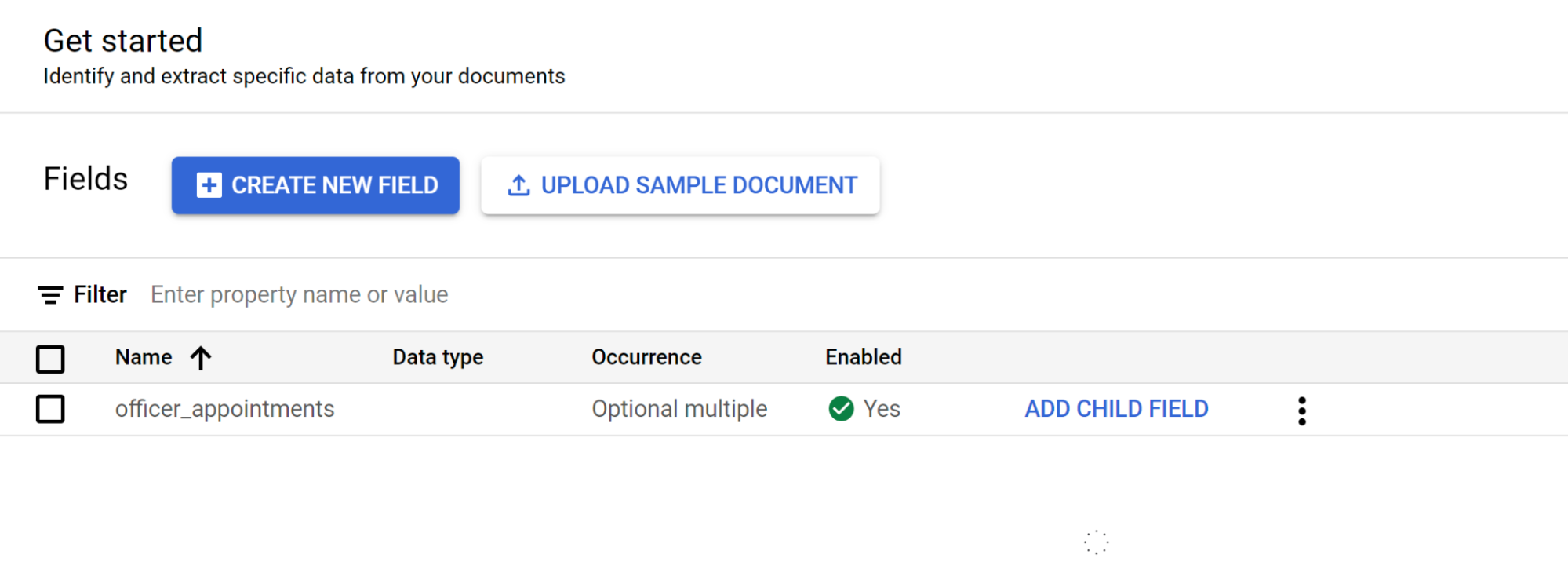
Selecione Começar e, de seguida, crie um campo:
- Crie o nível superior.
- Neste exemplo, é usado o elemento
officer_appointments. - Selecione Esta é uma etiqueta principal.
- Selecione Ocorrência:
Optional multiple.
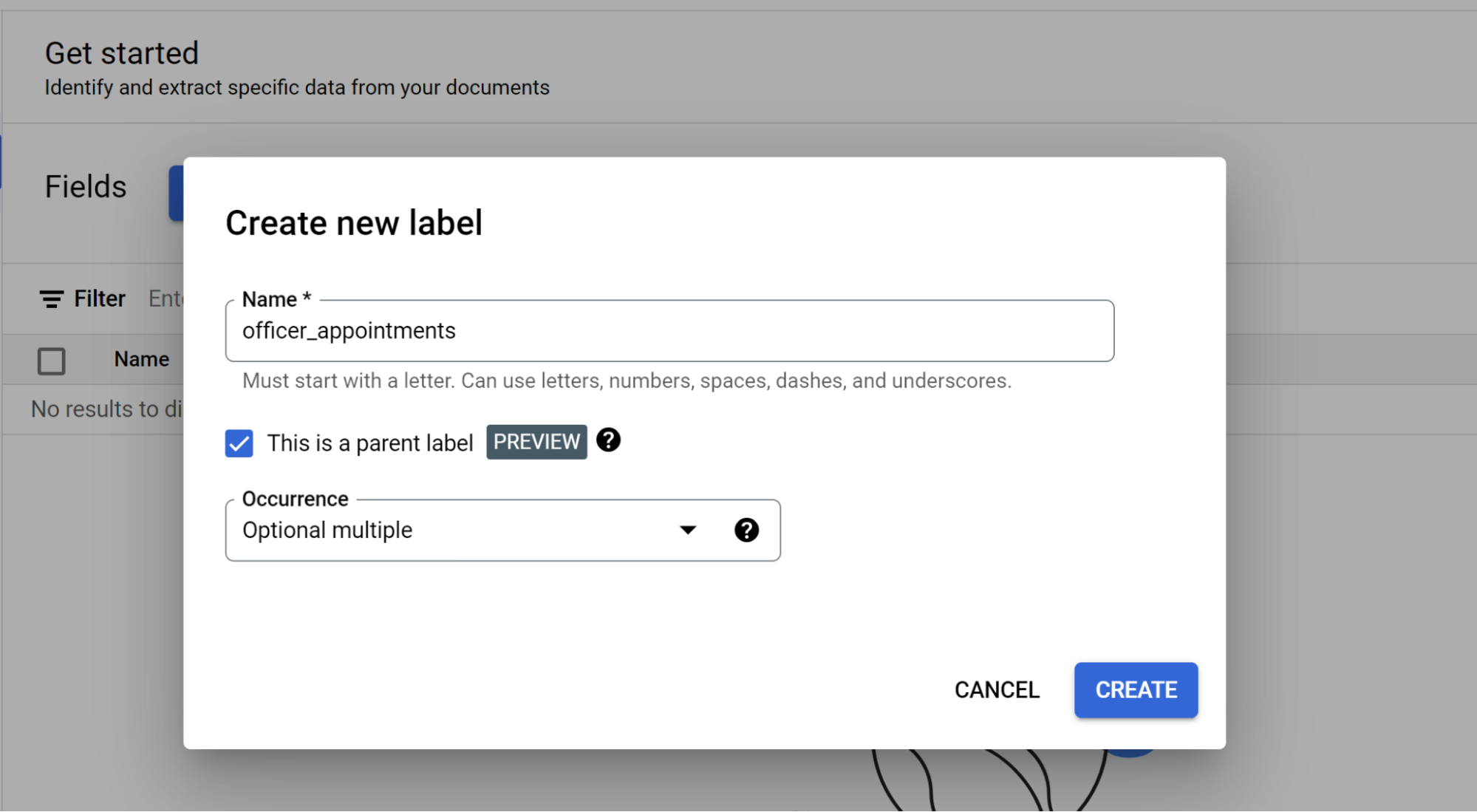
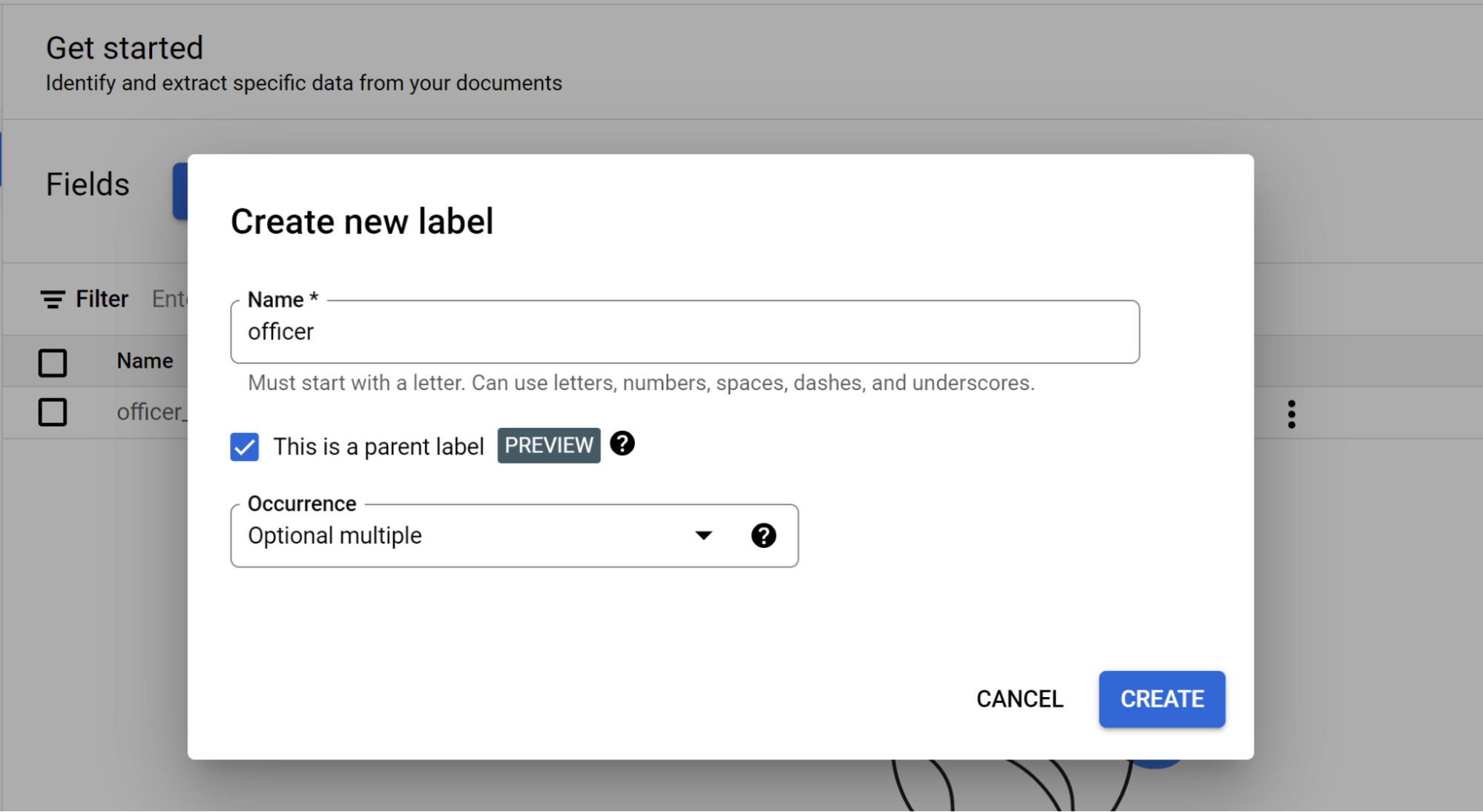
Selecione Adicionar campo filho. Agora, pode criar a etiqueta de segundo nível:
- Para esta etiqueta de nível, crie
officer. - Selecione Esta é uma etiqueta principal.
- Selecione Ocorrência:
Optional multiple.
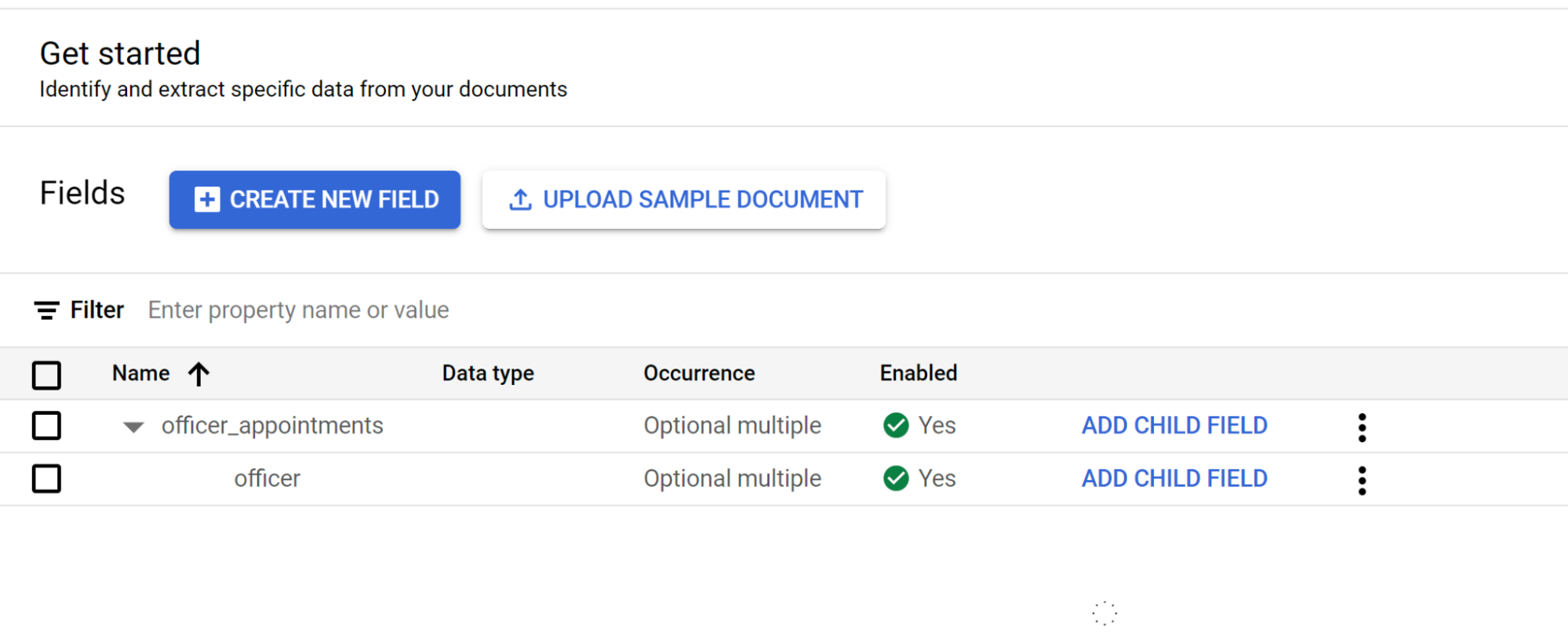
- Para esta etiqueta de nível, crie
Selecione Adicionar campo filho no segundo nível
officer. Crie etiquetas secundárias para o terceiro nível de aninhamento.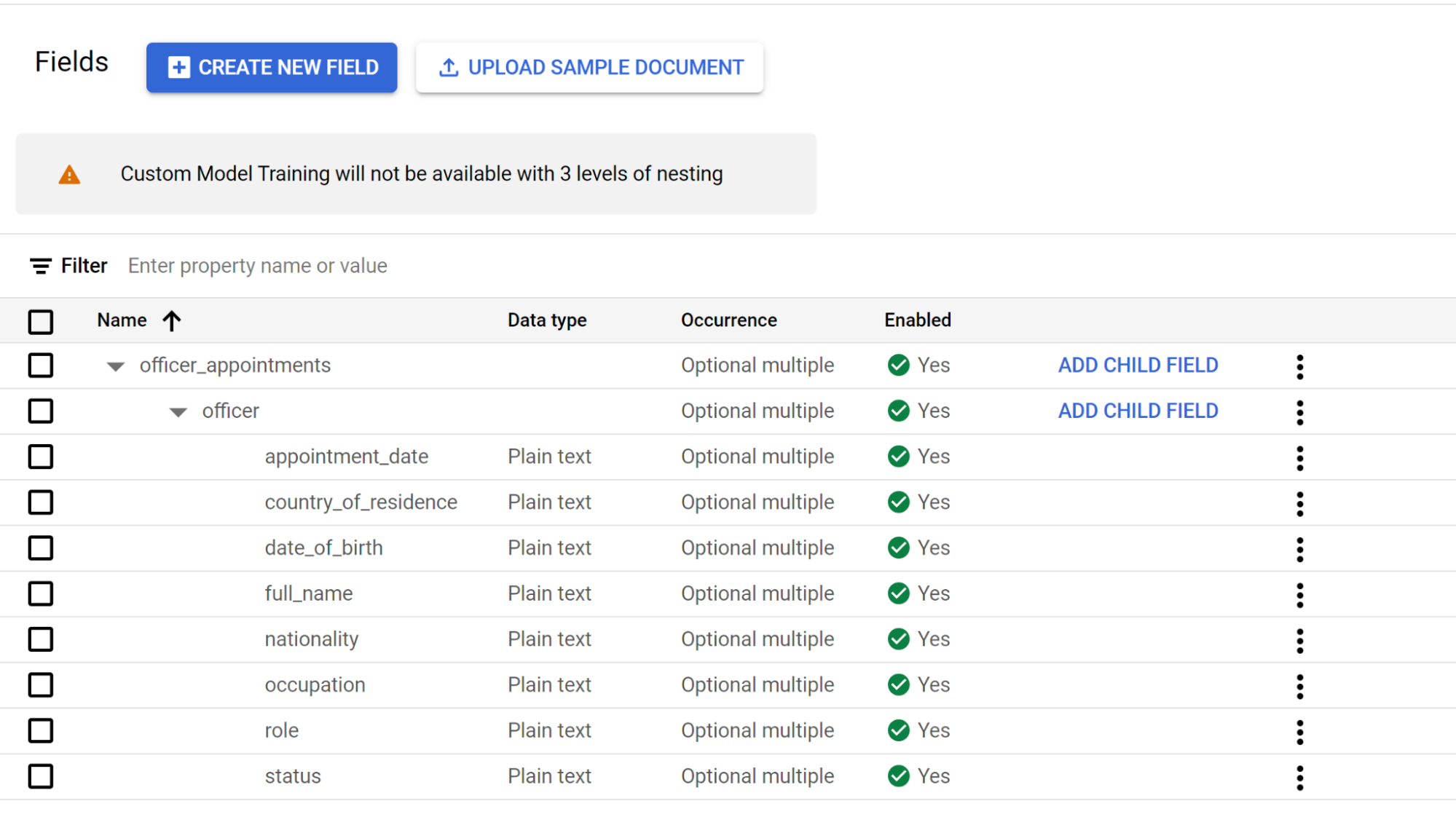
Quando o esquema estiver definido, pode obter previsões de documentos com três níveis de aninhamento através da etiquetagem automática.
Etiquete entidades aninhadas em várias páginas
O processador pretrained-foundation-model-v1.5-2025-05-05 suporta o aninhamento de três níveis em várias páginas.
Etiquete uma entidade normalmente numa página. Nota: a entidade etiquetada só é visível na página onde está etiquetada, com a barra de navegação a mudar de página para página. Ao fixar a entidade principal, esta barra de navegação mantém-se.
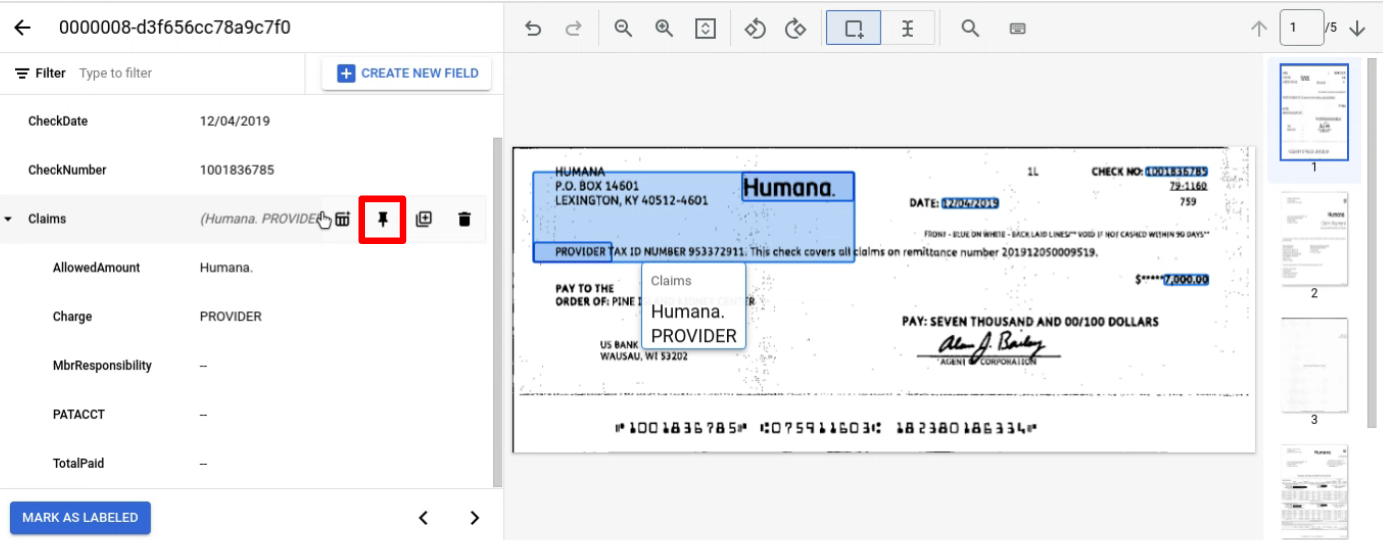
Fixe a entidade principal com os elementos secundários que quer etiquetar em várias páginas.
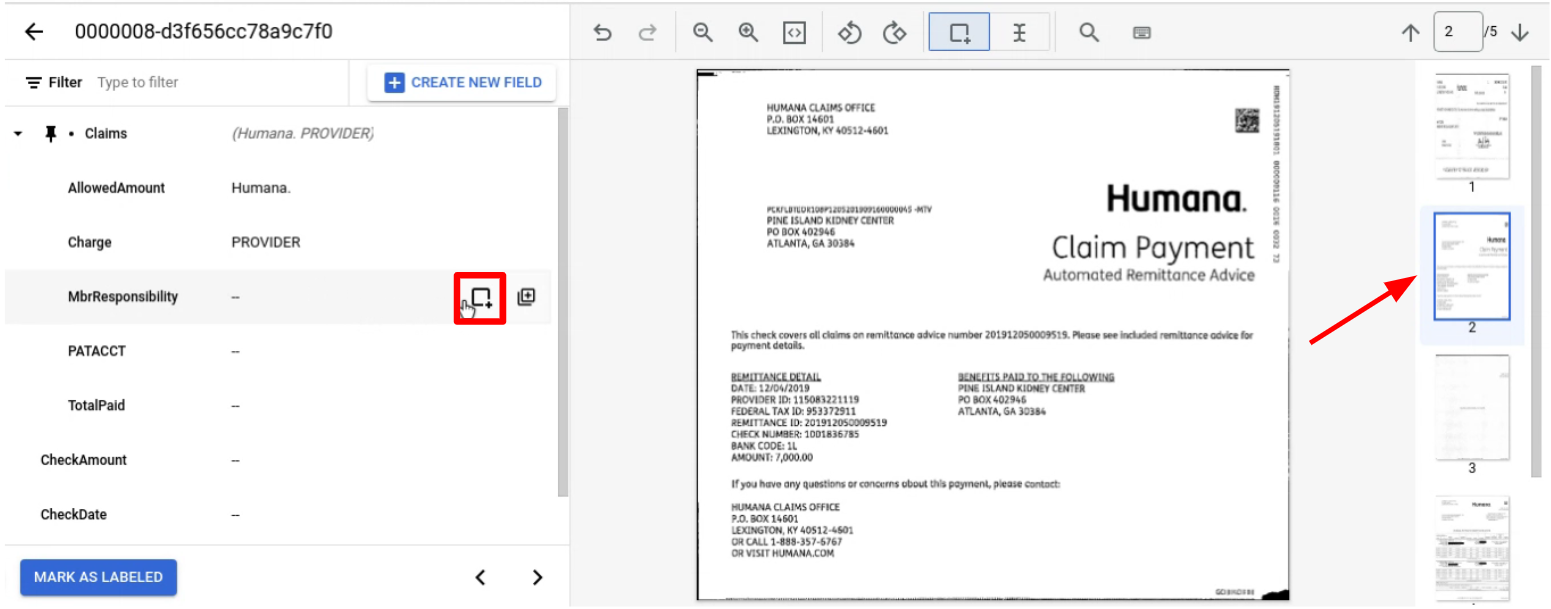
Navegue para a página com a entidade ou as entidades secundárias a etiquetar.
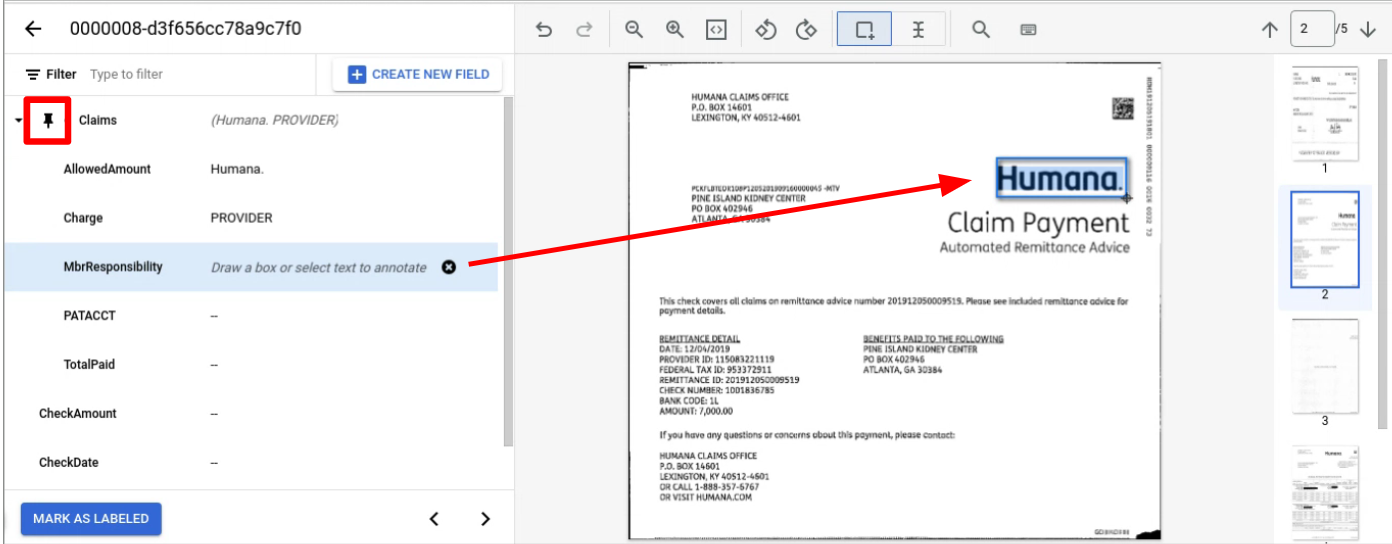
Configuração do conjunto de dados
É necessário um conjunto de dados de documentos para formar, atualizar a formação ou avaliar uma versão do processador. Os processadores do Document AI aprendem com exemplos, tal como os humanos. O conjunto de dados melhora a estabilidade do processador em termos de desempenho.Conjunto de dados de preparação
Para melhorar o modelo e a respetiva precisão, prepare um conjunto de dados nos seus documentos. O modelo é composto por documentos com dados reais.- Para o ajuste preciso, precisa de um mínimo de 1 documento para preparar um novo modelo com a versão
para
pretrained-foundation-model-v1.2-2024-05-10epretrained-foundation-model-v1.3-2024-08-31. - Para um few-shot, recomendamos cinco documentos.
- Para o zero-shot, só é necessário um esquema.
Conjunto de dados de teste
O conjunto de dados de teste é o que o modelo usa para gerar uma pontuação F1 (precisão). É composto por documentos com dados reais. Para ver a frequência com que o modelo está correto, a verdade fundamental é usada para comparar as previsões do modelo (campos extraídos do modelo) com as respostas corretas. O conjunto de dados de teste deve ter, pelo menos, um documento parapretrained-foundation-model-v1.2-2024-05-10 e pretrained-foundation-model-v1.3-2024-08-31.
Extrator personalizado com descrições de propriedades
Com as descrições de propriedades, pode formar um modelo descrevendo como são os campos etiquetados. Pode fornecer contexto e estatísticas adicionais para cada entidade. Isto permite que o modelo seja preparado fazendo corresponder os campos que se adequam à descrição que fornece e melhora a precisão da extração. As descrições das propriedades podem ser especificadas para entidades principais e secundárias.
Os bons exemplos de descrições de propriedades incluem informações de localização e padrões de texto dos valores das propriedades, que ajudam a desambiguar potenciais fontes de confusão no documento. As descrições de propriedades claras e precisas orientam o modelo com regras que promovem extrações mais fiáveis e consistentes, independentemente da estrutura específica do documento ou das variações de conteúdo.
Atualize o esquema de documentos para um processador
Para saber como definir as descrições das propriedades, consulte o artigo Atualize o esquema do documento.
Envie uma solicitação de processamento com descrições de propriedades
Se o esquema do documento já tiver descrições definidas, pode enviar uma solicitação de processamento com as instruções em Envie uma solicitação de processamento.
Ajuste um processador com descrições de propriedades
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- LOCATION: a localização do seu processador, por exemplo:
us– Estados Unidoseu- União Europeia
- PROJECT_ID: o ID do seu Google Cloud projeto.
- PROCESSOR_ID: o ID do seu processador personalizado.
- DISPLAY_NAME: nome a apresentar do processador.
- PRETRAINED_PROCESSOR_VERSION: o identificador da versão do processador. Consulte o artigo Selecione uma versão do processador para mais informações. Por exemplo:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: passos de preparação para o ajuste preciso do modelo.
- LEARN_RATE_MULTIPLIER: multiplicador da taxa de aprendizagem para o ajuste fino do modelo.
- DOCUMENT_SCHEMA: esquema para o processador. Consulte a representação DocumentSchema.
Método HTTP e URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corpo JSON do pedido:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Para enviar o seu pedido, escolha uma destas opções:
curl
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Guarde o corpo do pedido num ficheiro com o nome request.json,
e execute o seguinte comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Extrator personalizado com deteção de assinatura
(Pré-visualização pública) O extrator personalizado suporta a deteção de assinaturas. Esta funcionalidade permite-lhe detetar a presença de assinaturas nos documentos. A deteção de assinaturas só está disponível através do tipo de método derived. Pode especificar um esquema com o tipo de entidade signature
para essas entidades. As entidades de assinatura são derivadas através de indicações visuais do documento.
Para ver exemplos e instruções de configuração, clique em Extrator personalizado com campo derivado e deteção de assinatura.
Extrator personalizado com campos derivados
O extrator personalizado suporta campos derivados. Permite-lhe configurar um campo para ser preenchido através de inferência ou geração inteligente com base no contexto do documento, em vez da extração direta de texto. Pode usar esta funcionalidade para exemplos de utilização como deduzir o país a partir de uma morada, resumir um documento, contar itens numa tabela ou detetar se um documento de identificação é autêntico, sem exigir que o valor esteja explicitamente presente no texto.
Para ver exemplos e instruções de configuração, clique em Extrator personalizado com campo derivado e deteção de assinatura.
O que se segue?
Saiba mais sobre o extrator personalizado com campo derivado e deteção de assinatura.