É possível treinar um modelo de alta performance com apenas três documentos de treinamento e três de teste para casos de uso de layout fixo. Acelere o desenvolvimento e reduza o tempo de produção de tipos de documentos com modelos, como W9, 1040, ACORD, pesquisas e questionários.
Configuração do conjunto de dados
Um conjunto de dados de documentos é necessário para treinar, aprimorar o treinamento ou avaliar uma versão do processador. Os processadores da Document AI aprendem com exemplos, assim como os humanos. O conjunto de dados alimenta a estabilidade do processador em termos de desempenho.Conjunto de dados de treinamento
Para melhorar o modelo e a acurácia dele, treine um conjunto de dados nos seus documentos. O modelo é composto de documentos com informações empíricas. Você precisa de pelo menos três documentos para treinar um novo modelo.Conjunto de dados de teste
O conjunto de dados de teste é o que o modelo usa para gerar uma pontuação F1 (acurácia). Ele é composto por documentos com informações empíricas. Para saber com que frequência o modelo está certo, as informações empíricas são usadas para comparar as previsões do modelo (campos extraídos do modelo) com as respostas corretas. O conjunto de dados de teste precisa ter pelo menos três documentos.Antes de começar
Se ainda não tiver feito isso, ative:
Práticas recomendadas de rotulagem no modo de modelo
A rotulagem adequada é uma das etapas mais importantes para alcançar alta precisão. O modo de modelo tem uma metodologia de rotulagem exclusiva que difere de outros modos de treinamento:
- Desenhe caixas delimitadoras em torno de toda a área em que você espera que os dados estejam (por rótulo) em um documento, mesmo que o rótulo esteja vazio no documento de treinamento que você está rotulando.
- Você pode rotular campos vazios para treinamento baseado em modelos. Não rotule campos vazios para treinamento baseado em modelo.
Criar e avaliar um extrator personalizado com o modo de modelo
Crie um extrator personalizado. Crie um processador e defina os campos que você quer extrair seguindo as práticas recomendadas, o que é importante porque afeta a qualidade da extração.
Defina o local do conjunto de dados. Selecione a pasta de opções padrão (gerenciada pelo Google). Isso pode ser feito automaticamente logo após a criação do processador.
Acesse a guia Build e selecione Importar documentos com a rotulagem automática ativada. Adicionar mais documentos do que o mínimo de três necessários geralmente não melhora a qualidade do treinamento com base em modelos. Em vez de adicionar mais, concentre-se em rotular um pequeno conjunto com muita precisão.
Estender caixas delimitadoras. Essas caixas para o modo de modelo devem ser parecidas com os exemplos anteriores. Estenda as caixas delimitadoras seguindo as práticas recomendadas para ter o melhor resultado.
Treinar o modelo.
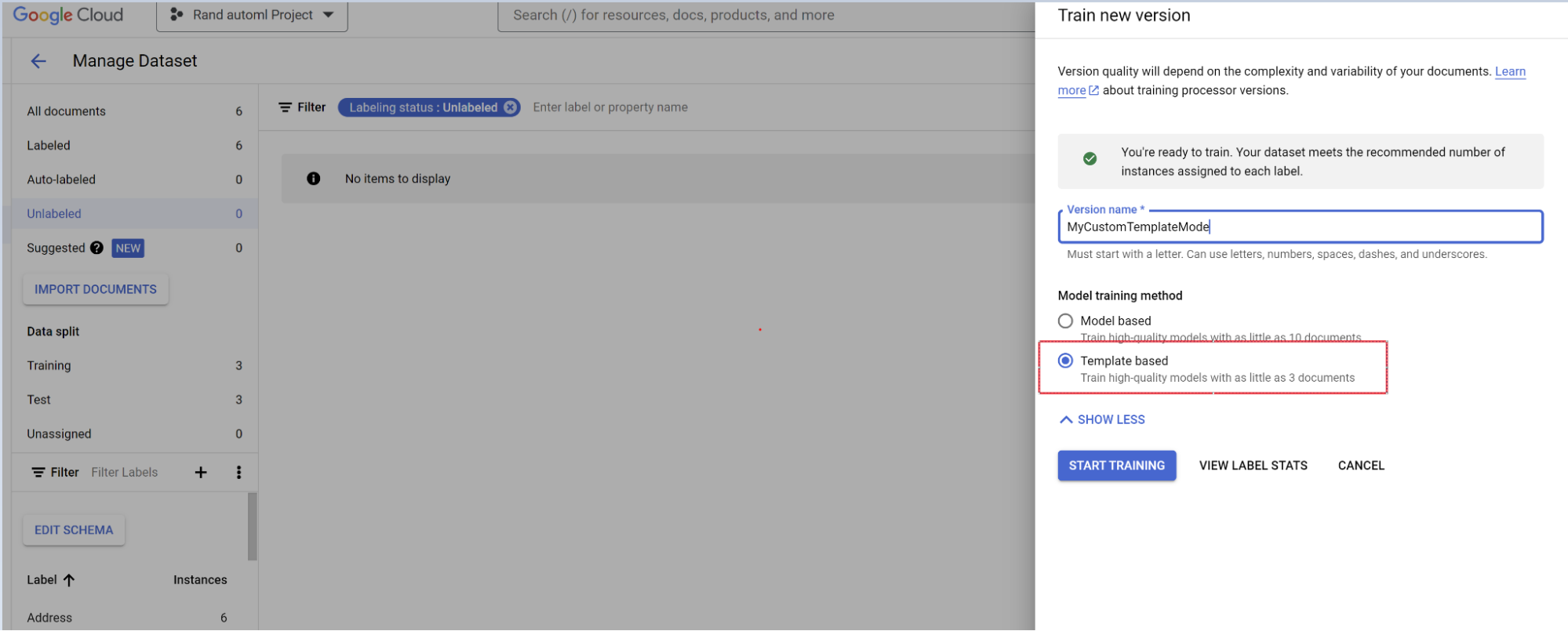
- Selecione Treinar nova versão.
- Nomeie a versão do processador.
- Acesse Mostrar opções avançadas e selecione a abordagem de modelo baseada em modelos.
Avaliação.
- Acesse Avaliar e testar.
- Selecione a versão que você acabou de treinar e clique em Ver avaliação completa.
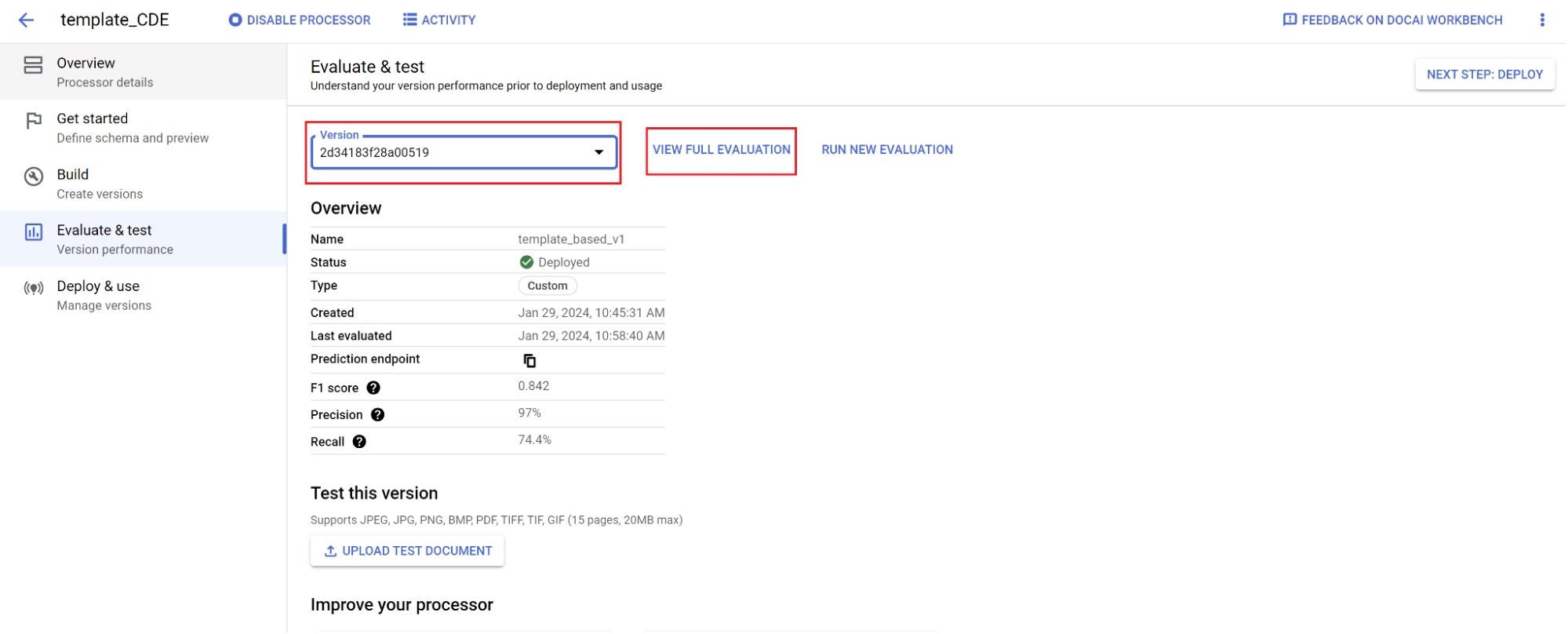
Agora você vê métricas como F1, precisão e recall para o documento inteiro e cada campo. 1. Decida se a performance atende às suas metas de produção e, se não, reavalie os conjuntos de treinamento e teste.
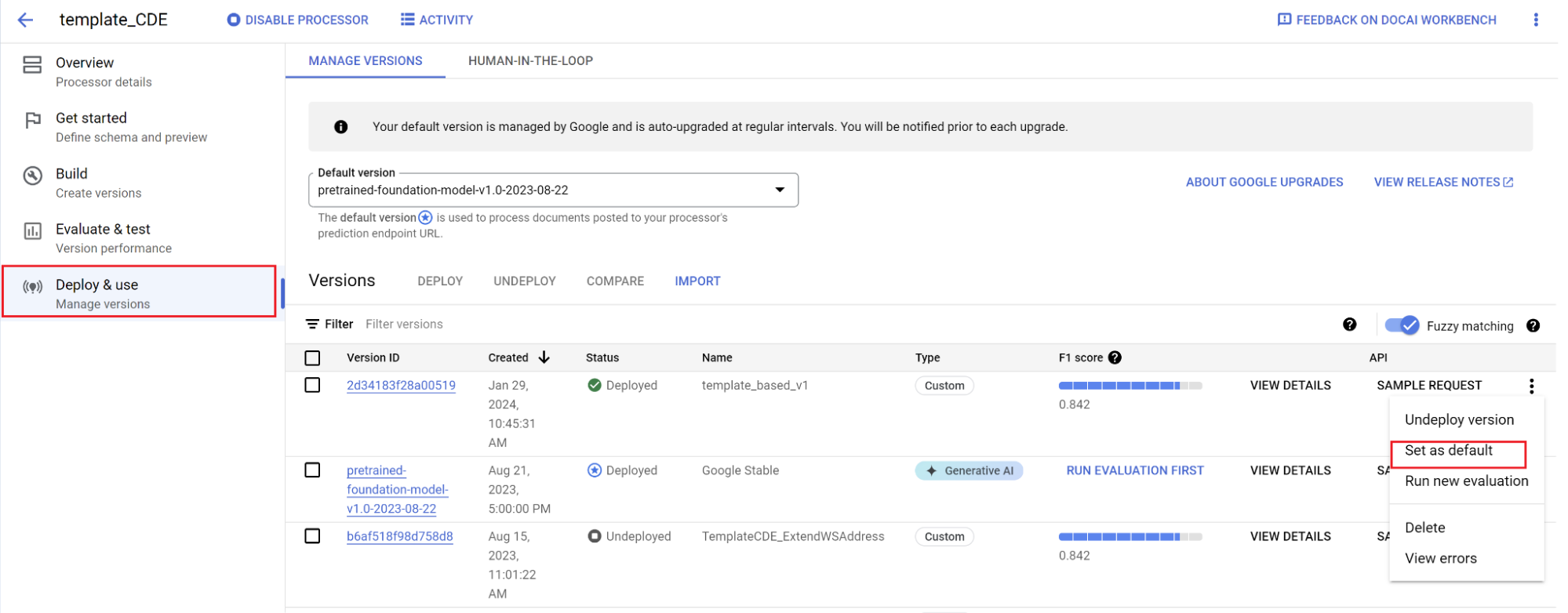
Defina uma nova versão como padrão.
- Acesse Gerenciar versões.
- Selecione para abrir o menu de configurações e marque Definir como padrão.
Seu modelo foi implantado, e os documentos enviados a esse processador usam sua versão personalizada. Você quer avaliar a performance do modelo (mais detalhes sobre como fazer isso) para verificar se ele precisa de mais treinamento.
Referência de avaliação
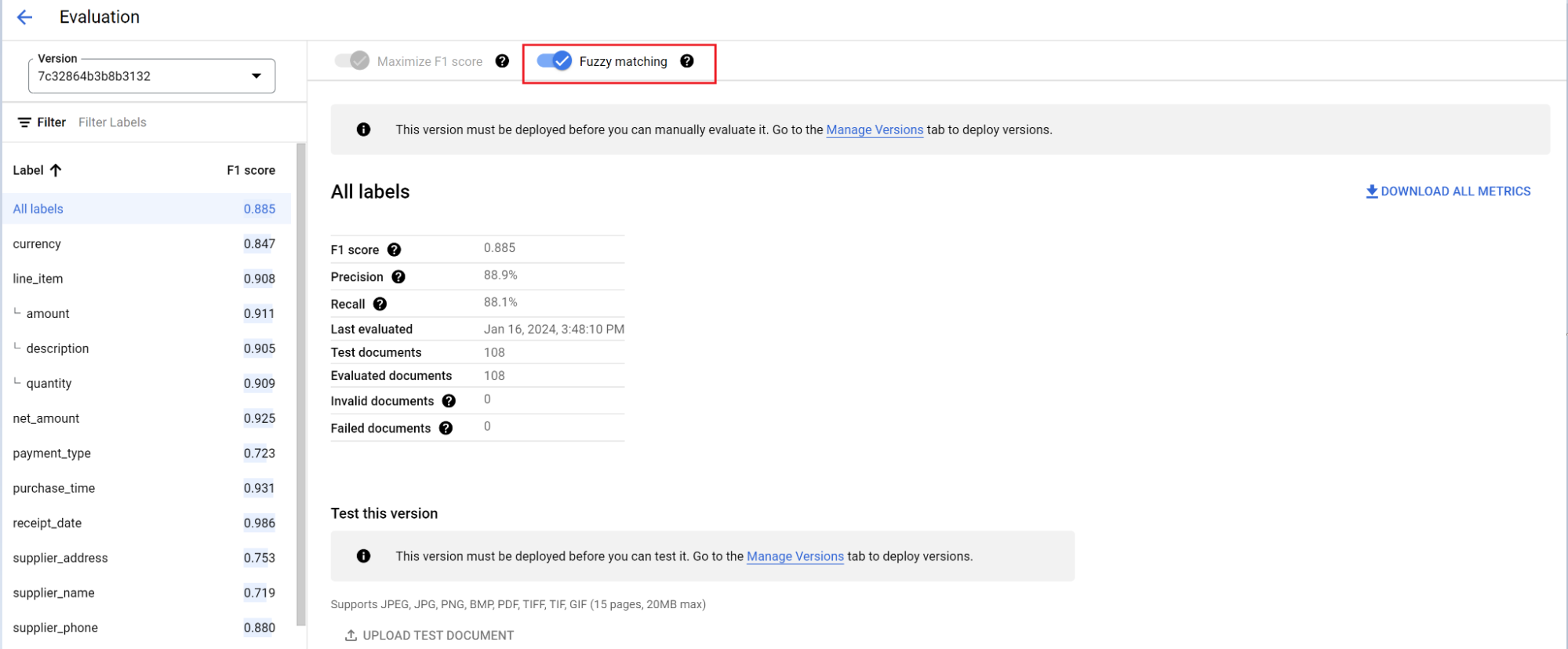
O mecanismo de avaliação pode fazer correspondência exata ou aproximada. Para uma correspondência exata, o valor extraído precisa corresponder exatamente à verdade fundamental ou é contado como uma falha.
As extrações de correspondência aproximada que tinham pequenas diferenças, como o uso de maiúsculas e minúsculas, ainda são consideradas uma correspondência. Isso pode ser mudado na tela Avaliação.
Identificação automática com o modelo de fundação
O modelo de fundação extrai campos com precisão para diversos tipos de documentos, mas também é possível fornecer mais dados de treinamento para melhorar a acurácia do modelo em estruturas de documentos específicas.
A Document AI usa os nomes de rótulo que você define e as anotações anteriores para facilitar e agilizar a rotulagem de documentos em grande escala com a rotulagem automática.
- Depois de criar um processador personalizado, acesse a guia Começar.
Selecione Criar novo campo.
Acesse a guia Build e selecione Importar documentos.
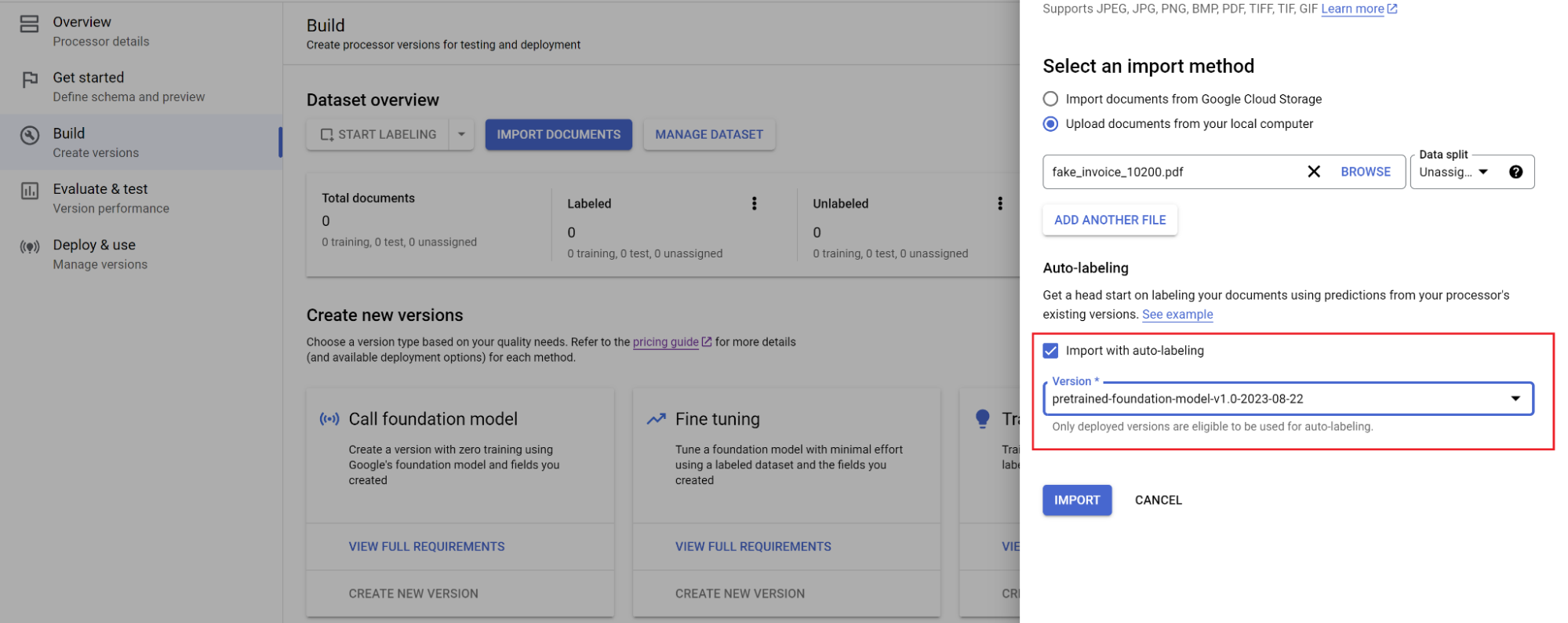
Selecione o caminho dos documentos e em qual conjunto eles serão importados. Marque a caixa de seleção de rotulagem automática e selecione o modelo de fundação.
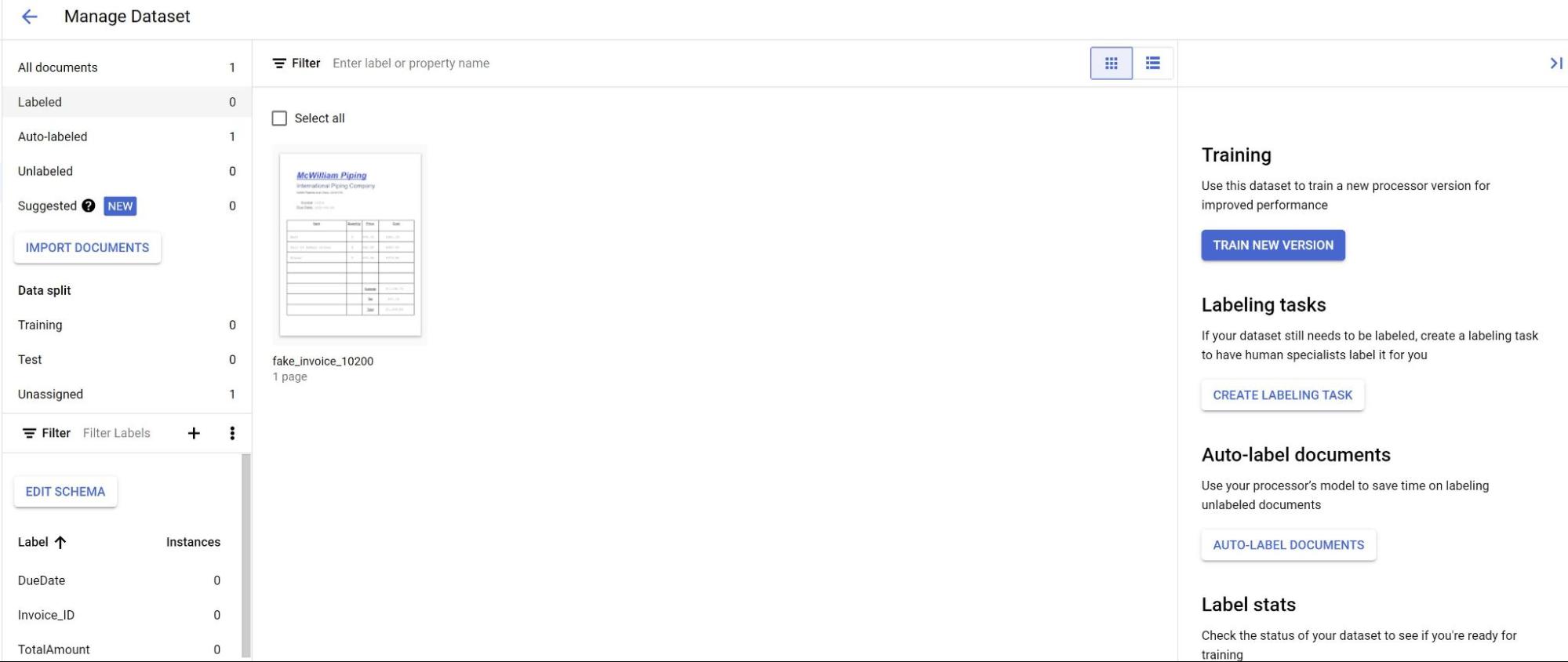
Na guia Build, selecione Gerenciar conjunto de dados. Os documentos importados vão aparecer. Selecione um dos seus documentos.
As previsões do modelo são destacadas em roxo. Revise cada rótulo previsto pelo modelo e verifique se está correto. Se houver campos ausentes, adicione-os também.
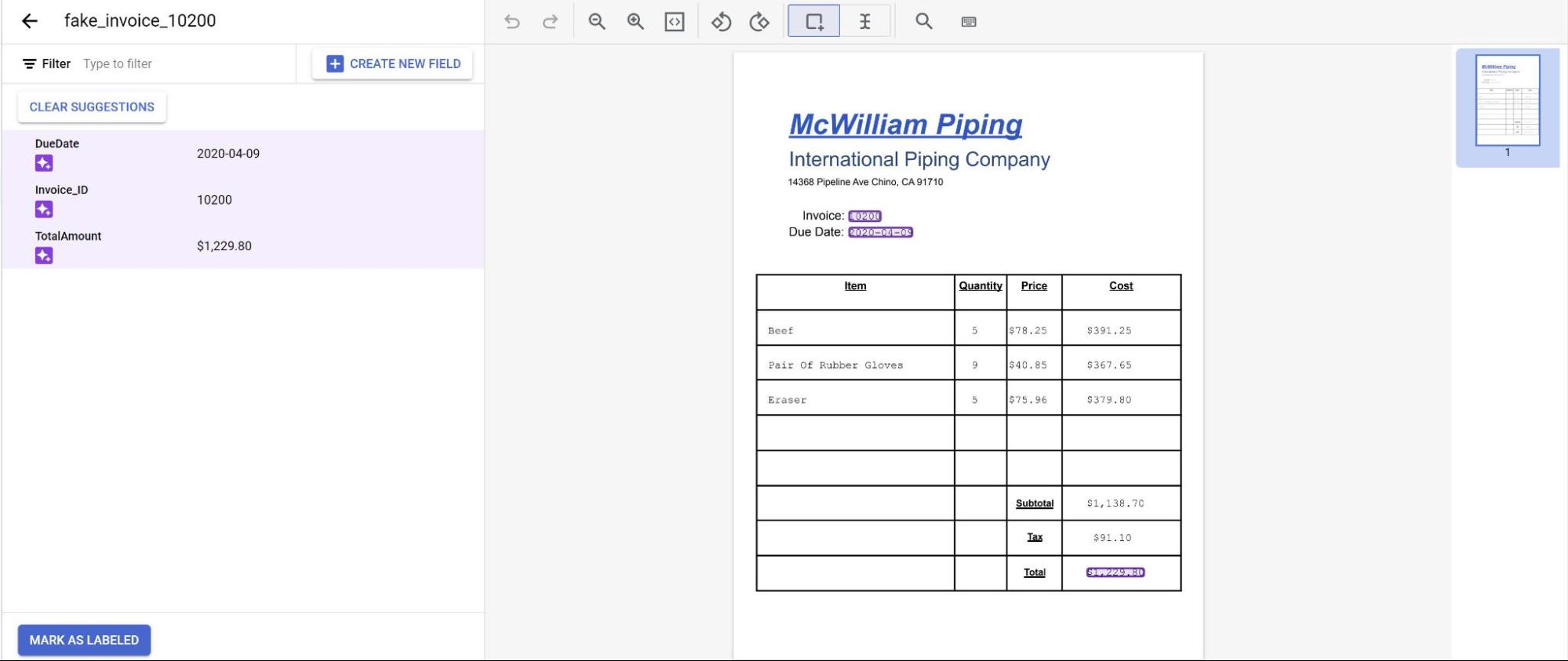
Depois que o documento for revisado, selecione Marcar como rotulado.
O documento está pronto para ser usado pelo modelo. Confira se o documento está no conjunto de teste ou treinamento.