Anda dapat melatih model berperforma tinggi hanya dengan tiga dokumen pelatihan dan tiga dokumen pengujian untuk kasus penggunaan tata letak tetap. Mempercepat pengembangan dan mengurangi waktu penyiapan produk untuk jenis dokumen berbasis template seperti W9, 1040, ACORD, survei, dan kuesioner.
Konfigurasi set data
Set data dokumen diperlukan untuk melatih, melatih ulang, atau mengevaluasi versi pemroses. Prosesor Document AI belajar dari contoh, seperti halnya manusia. Set data memicu stabilitas prosesor dalam hal performa.Set data pelatihan
Untuk meningkatkan model dan akurasinya, latih set data pada dokumen Anda. Model terdiri dari dokumen dengan kebenaran dasar. Anda memerlukan minimal tiga dokumen untuk melatih model baru.Set data pengujian
Set data pengujian adalah yang digunakan model untuk menghasilkan skor F1 (akurasi). Set data ini terdiri dari dokumen dengan kebenaran dasar. Untuk melihat seberapa sering model benar, kebenaran dasar digunakan untuk membandingkan prediksi model (kolom yang diekstrak dari model) dengan jawaban yang benar. Set data pengujian harus memiliki minimal tiga dokumen.Sebelum memulai
Jika belum dilakukan, aktifkan:
Praktik terbaik pelabelan mode template
Pelabelan yang tepat adalah salah satu langkah terpenting untuk mencapai akurasi yang tinggi. Mode template memiliki beberapa metodologi pemberian label unik yang berbeda dari mode pelatihan lainnya:
- Gambar kotak pembatas di sekitar seluruh area yang Anda harapkan berisi data (per label) dalam dokumen, meskipun label kosong dalam dokumen pelatihan yang Anda beri label.
- Anda dapat memberi label pada kolom kosong untuk pelatihan berbasis template. Jangan beri label pada kolom kosong untuk pelatihan berbasis model.
Membangun dan mengevaluasi pengekstrak kustom dengan mode template
Buat pengekstrak kustom. Buat pemroses dan tentukan kolom yang ingin Anda ekstrak dengan mengikuti praktik terbaik, yang penting karena memengaruhi kualitas ekstraksi.
Tetapkan lokasi set data. Pilih folder opsi default (dikelola Google). Hal ini dapat dilakukan secara otomatis segera setelah membuat pemroses.
Buka tab Build, lalu pilih Import documents dengan mengaktifkan pelabelan otomatis. Menambahkan lebih banyak dokumen daripada minimum tiga yang diperlukan biasanya tidak meningkatkan kualitas untuk pelatihan berbasis template. Daripada menambahkan lebih banyak, fokuslah untuk memberi label pada sekumpulan kecil data dengan sangat akurat.
Perluas kotak pembatas. Kotak untuk mode template ini akan terlihat seperti contoh sebelumnya. Perluas kotak pembatas, dengan mengikuti praktik terbaik untuk hasil yang optimal.
Latih model.
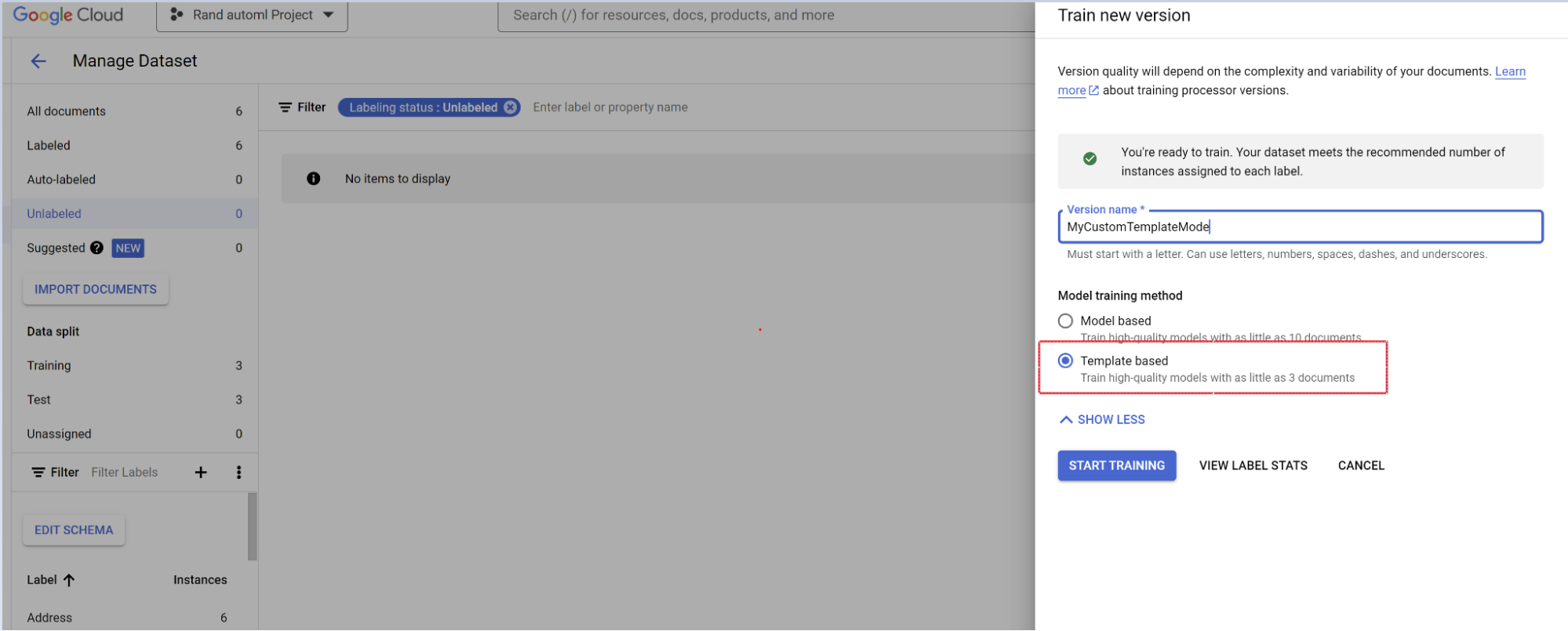
- Pilih Train new version.
- Beri nama versi pemroses.
- Buka Tampilkan opsi lanjutan dan pilih pendekatan model berbasis template.
Evaluasi.
- Buka Evaluasi & uji.
- Pilih versi yang baru saja Anda latih, lalu pilih Lihat Evaluasi Lengkap.
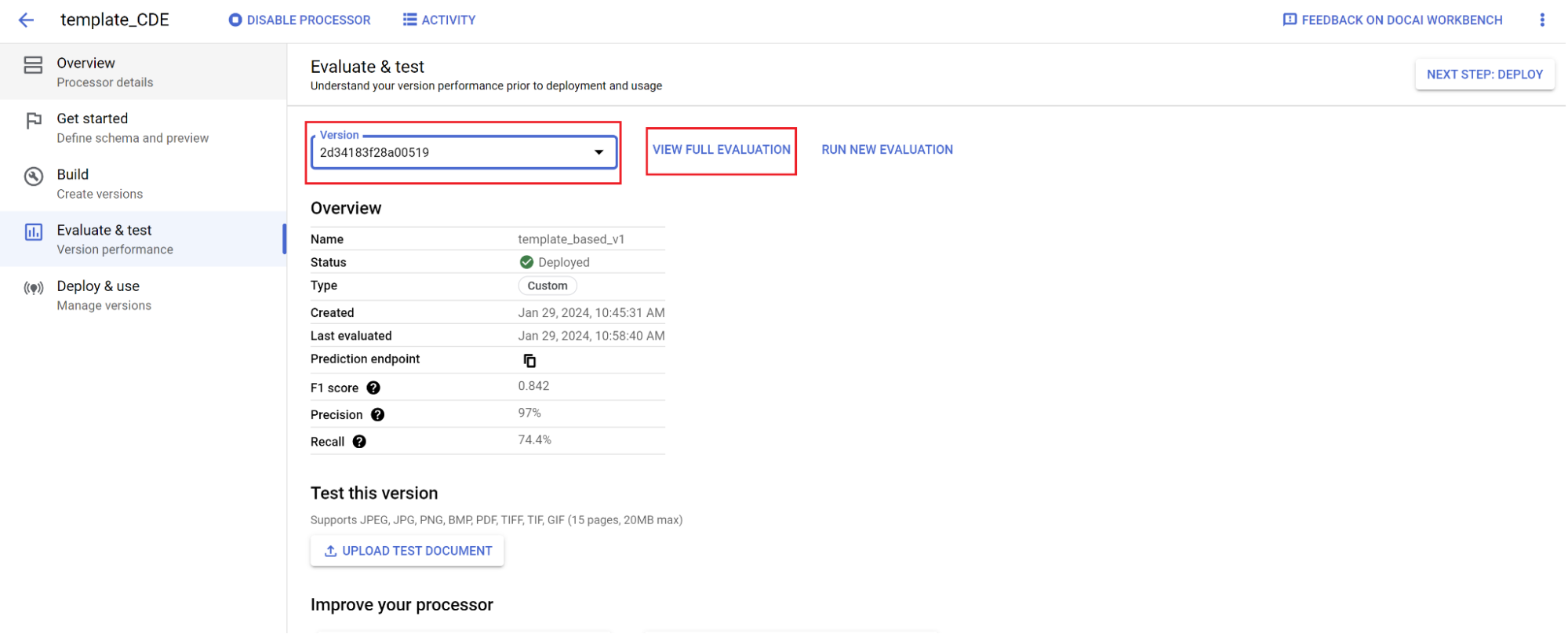
Sekarang Anda akan melihat metrik seperti F1, presisi, dan perolehan untuk seluruh dokumen dan setiap kolom. 1. Tentukan apakah performa memenuhi sasaran produksi Anda, dan jika tidak, evaluasi ulang set pelatihan dan pengujian.
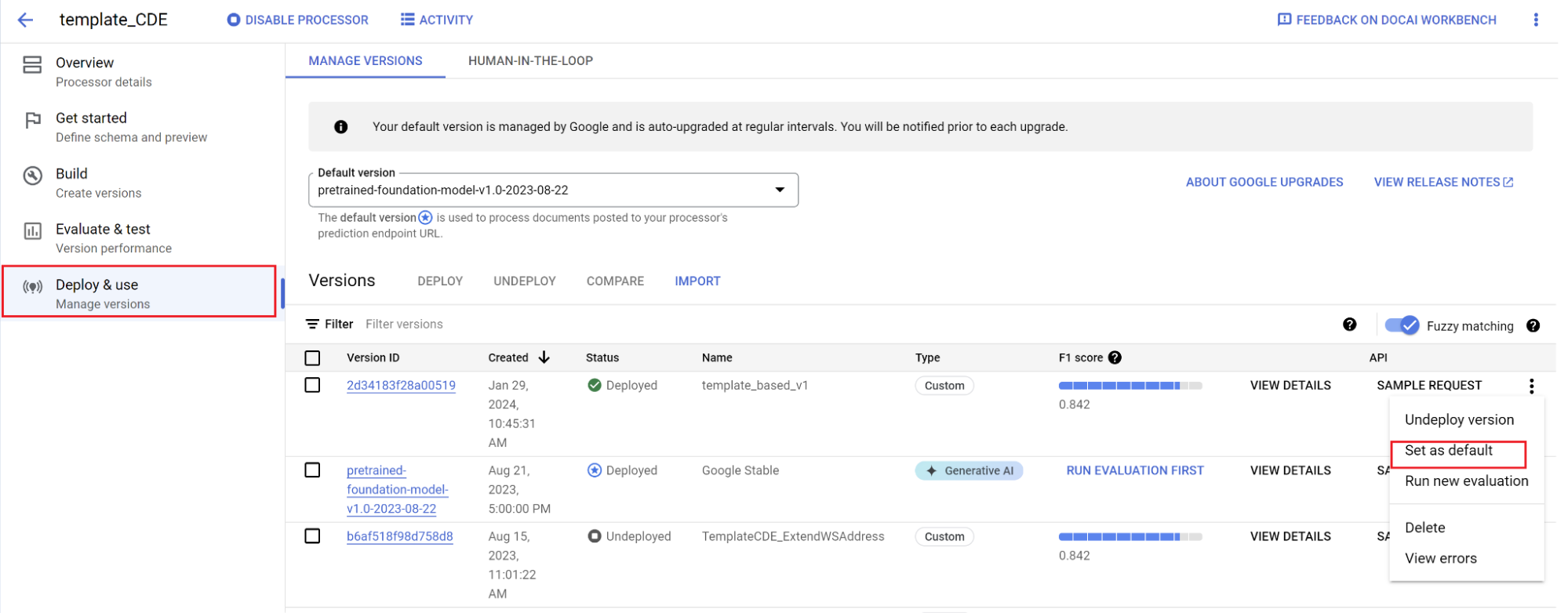
Tetapkan versi baru sebagai default.
- Buka Kelola versi.
- Pilih untuk melihat menu setelan, lalu tandai Tetapkan sebagai default.
Model Anda kini di-deploy dan dokumen yang dikirim ke pemroses ini menggunakan versi kustom Anda. Anda ingin mengevaluasi performa model (detail selengkapnya tentang cara melakukannya) untuk memeriksa apakah model memerlukan pelatihan lebih lanjut.
Referensi evaluasi
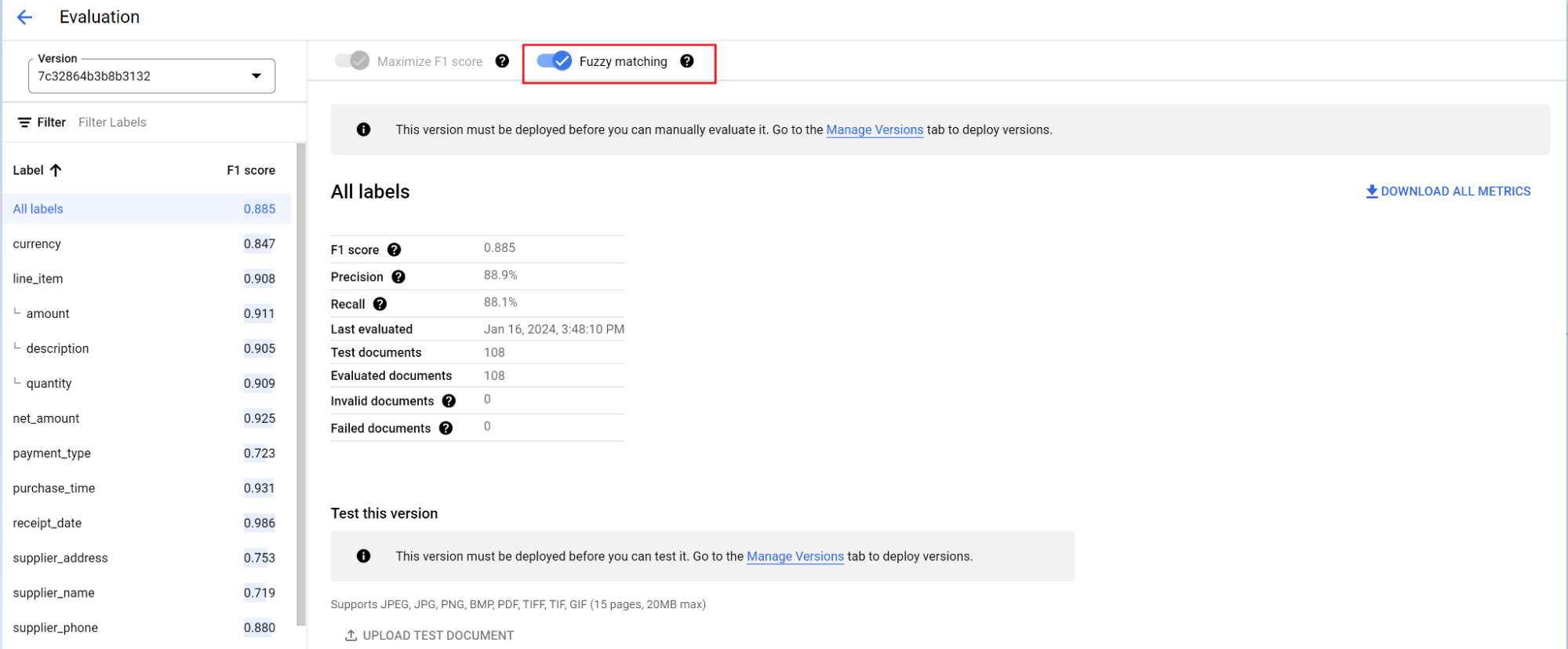
Mesin evaluasi dapat melakukan pencocokan persis atau pencocokan tidak persis. Untuk kecocokan persis, nilai yang diekstrak harus sama persis dengan data sebenarnya atau dihitung sebagai tidak cocok.
Ekstraksi pencocokan tidak persis yang memiliki sedikit perbedaan seperti perbedaan kapitalisasi tetap dihitung sebagai kecocokan. Setelan ini dapat diubah di layar Evaluasi.
Pelabelan otomatis dengan model dasar
Model dasar dapat mengekstrak kolom secara akurat untuk berbagai jenis dokumen, tetapi Anda juga dapat menyediakan data pelatihan tambahan untuk meningkatkan akurasi model untuk struktur dokumen tertentu.
Document AI menggunakan nama label yang Anda tentukan dan anotasi sebelumnya untuk mempercepat dan mempermudah pelabelan dokumen dalam skala besar dengan pelabelan otomatis.
- Setelah membuat pemroses kustom, buka tab Mulai.
Pilih Create New Field.
Buka tab Build, lalu pilih Impor dokumen.
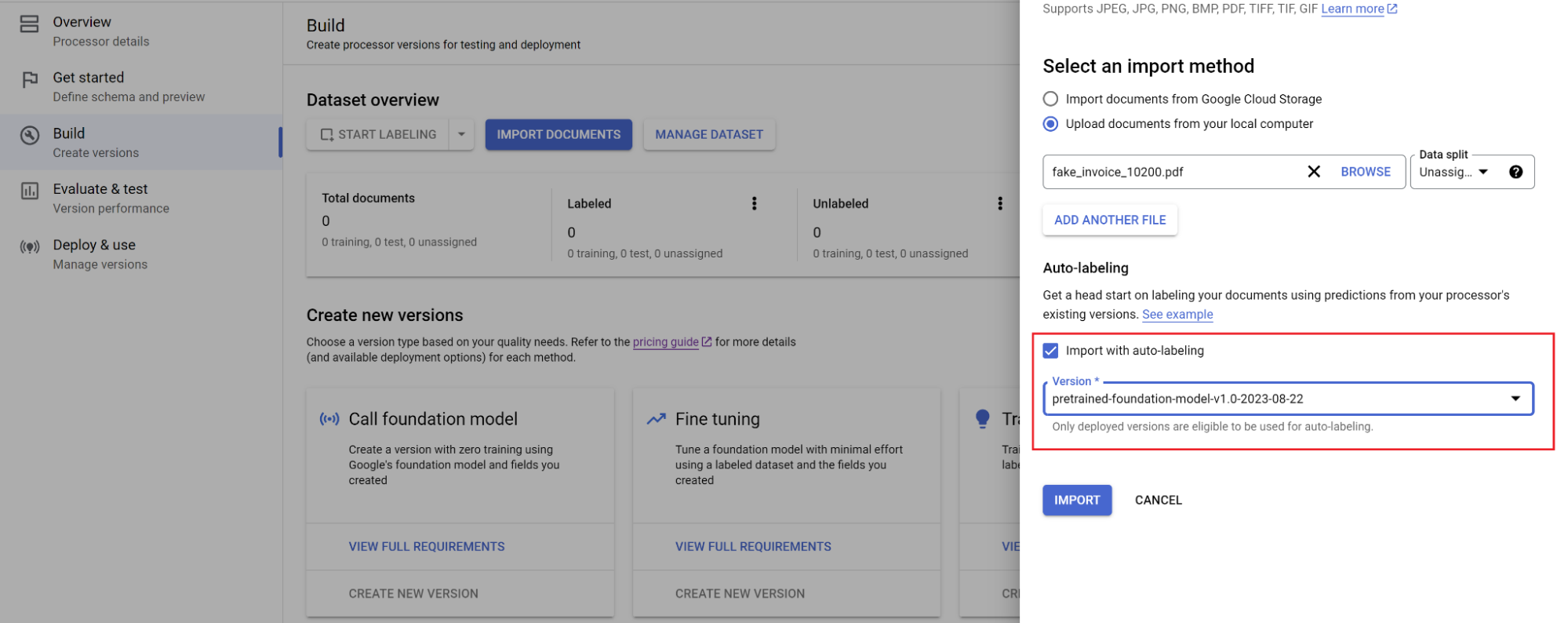
Pilih jalur dokumen dan kumpulan dokumen yang akan diimpor. Centang kotak auto-labeling dan pilih model dasar.
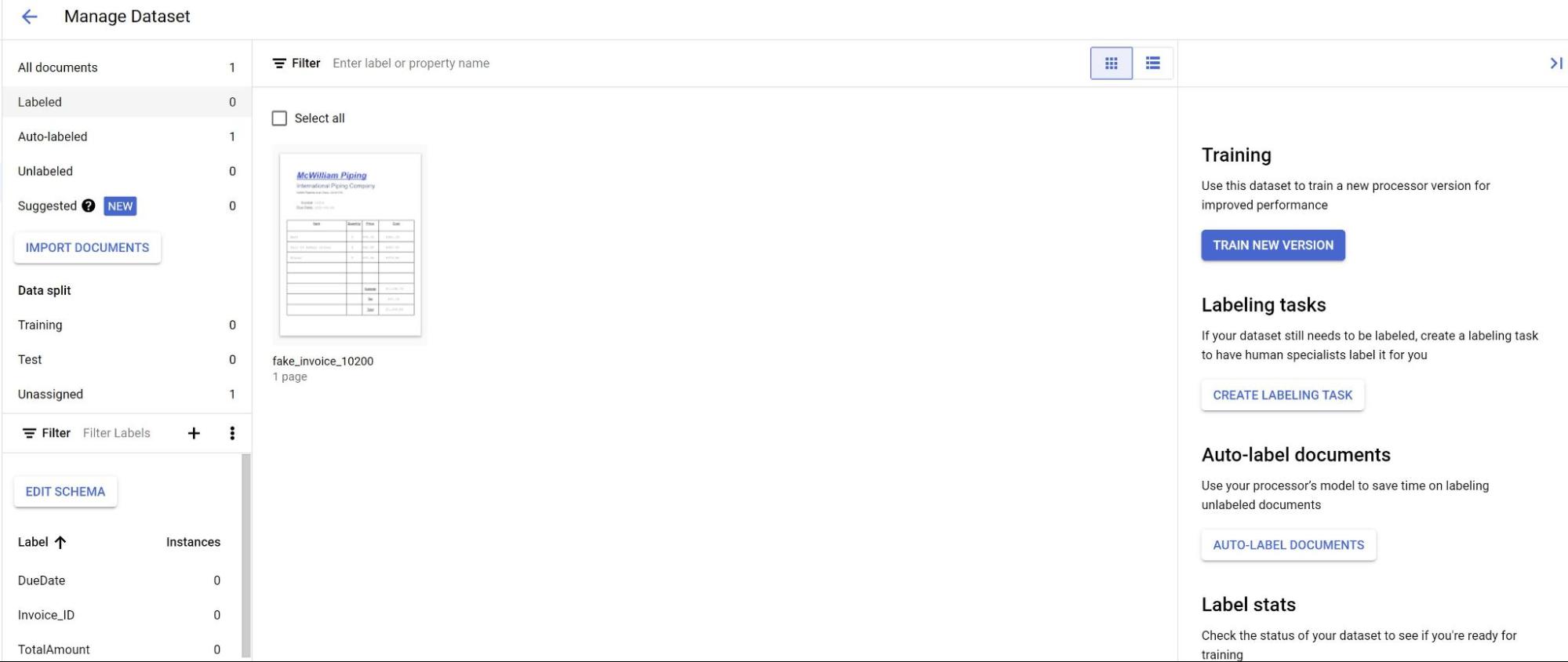
Di tab Build, pilih Kelola set data. Anda akan melihat dokumen yang diimpor. Pilih salah satu dokumen Anda.
Anda melihat prediksi dari model yang ditandai dengan warna ungu, Anda perlu meninjau setiap label yang diprediksi oleh model dan memastikan label tersebut benar. Jika ada kolom yang tidak ada, Anda juga perlu menambahkannya.
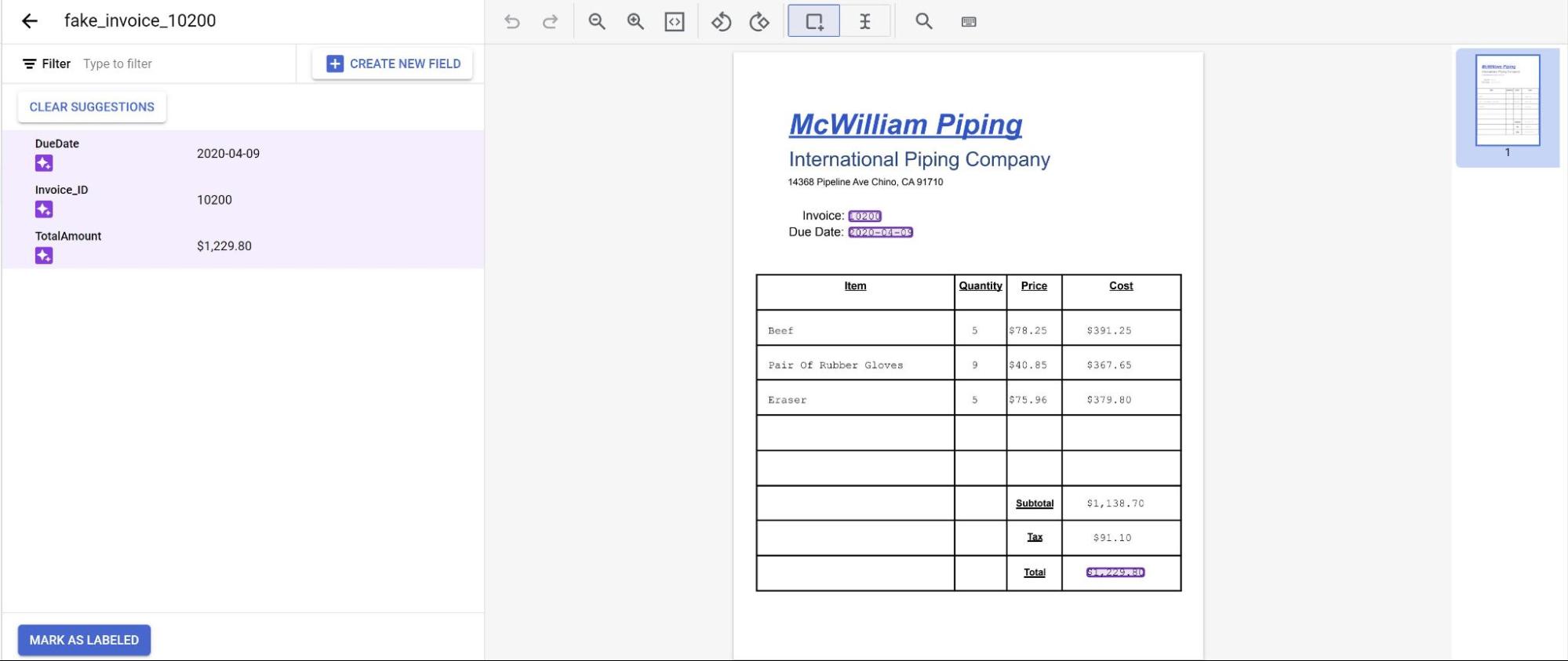
Setelah dokumen ditinjau, pilih Tandai sebagai diberi label.
Dokumen kini siap digunakan oleh model. Pastikan dokumen berada dalam set pengujian atau pelatihan.