Puedes entrenar un modelo de alto rendimiento con tan solo tres documentos de entrenamiento y tres de prueba para casos prácticos de diseño fijo. Acelera el desarrollo y reduce el tiempo de producción de tipos de documentos con plantillas, como los formularios W9 y 1040, los documentos ACORD, las encuestas y los cuestionarios.
Configuración del conjunto de datos
Se necesita un conjunto de datos de documentos para entrenar, volver a entrenar o evaluar una versión de un procesador. Los procesadores de Document AI aprenden de ejemplos, al igual que los humanos. El conjunto de datos alimenta la estabilidad del procesador en términos de rendimiento.Conjunto de datos de entrenamiento
Para mejorar el modelo y su precisión, entrena un conjunto de datos con tus documentos. El modelo se compone de documentos con información verificada. Necesitas al menos tres documentos para entrenar un modelo nuevo.Conjunto de datos de prueba
El conjunto de datos de prueba es el que usa el modelo para generar una puntuación F1 (precisión). Se compone de documentos con datos verificados. Para ver con qué frecuencia acierta el modelo, se usa la verdad fundamental para comparar las predicciones del modelo (campos extraídos del modelo) con las respuestas correctas. El conjunto de datos de prueba debe tener al menos tres documentos.Antes de empezar
Si aún no lo has hecho, habilita lo siguiente:
Prácticas recomendadas para el etiquetado en modo plantilla
Un etiquetado adecuado es uno de los pasos más importantes para conseguir una alta precisión. El modo Plantilla tiene una metodología de etiquetado única que difiere de otros modos de entrenamiento:
- Dibuja cuadros delimitadores alrededor de toda la zona en la que esperas que haya datos (por etiqueta) en un documento, aunque la etiqueta esté vacía en el documento de entrenamiento que estés etiquetando.
- Puedes etiquetar campos vacíos para el entrenamiento basado en plantillas. No etiquetes los campos vacíos para el entrenamiento basado en modelos.
Crear y evaluar un extractor personalizado con el modo de plantilla
Crea un extractor personalizado. Crea un procesador y define los campos que quieras extraer siguiendo las prácticas recomendadas, lo cual es importante porque influye en la calidad de la extracción.
Define la ubicación del conjunto de datos. Selecciona la carpeta de opciones predeterminada (gestionada por Google). Esto puede hacerse automáticamente poco después de crear el procesador.
Ve a la pestaña Compilación y selecciona Importar documentos con el etiquetado automático habilitado. Añadir más documentos de los tres necesarios no suele mejorar la calidad del entrenamiento basado en plantillas. En lugar de añadir más, céntrate en etiquetar un pequeño conjunto con mucha precisión.
Extiende los cuadros delimitadores. Los cuadros del modo de plantilla deben tener el mismo aspecto que los ejemplos anteriores. Extiende los cuadros delimitadores siguiendo las prácticas recomendadas para obtener resultados óptimos.
Entrena el modelo.
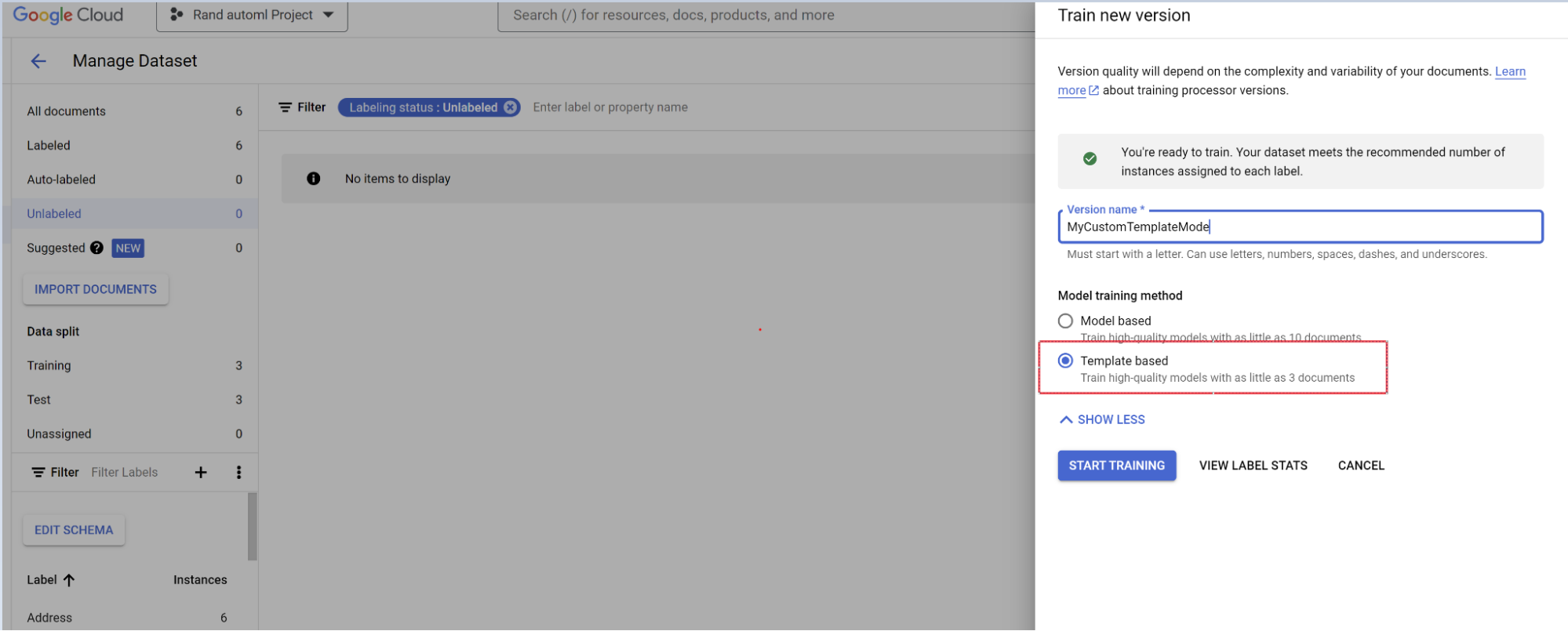
- Selecciona Entrenar nueva versión.
- Asigna un nombre a la versión del procesador.
- Ve a Mostrar opciones avanzadas y selecciona el enfoque de modelo basado en plantillas.
Evaluación.
- Vaya a Evaluar y probar.
- Selecciona la versión que acabas de entrenar y, a continuación, Ver evaluación completa.
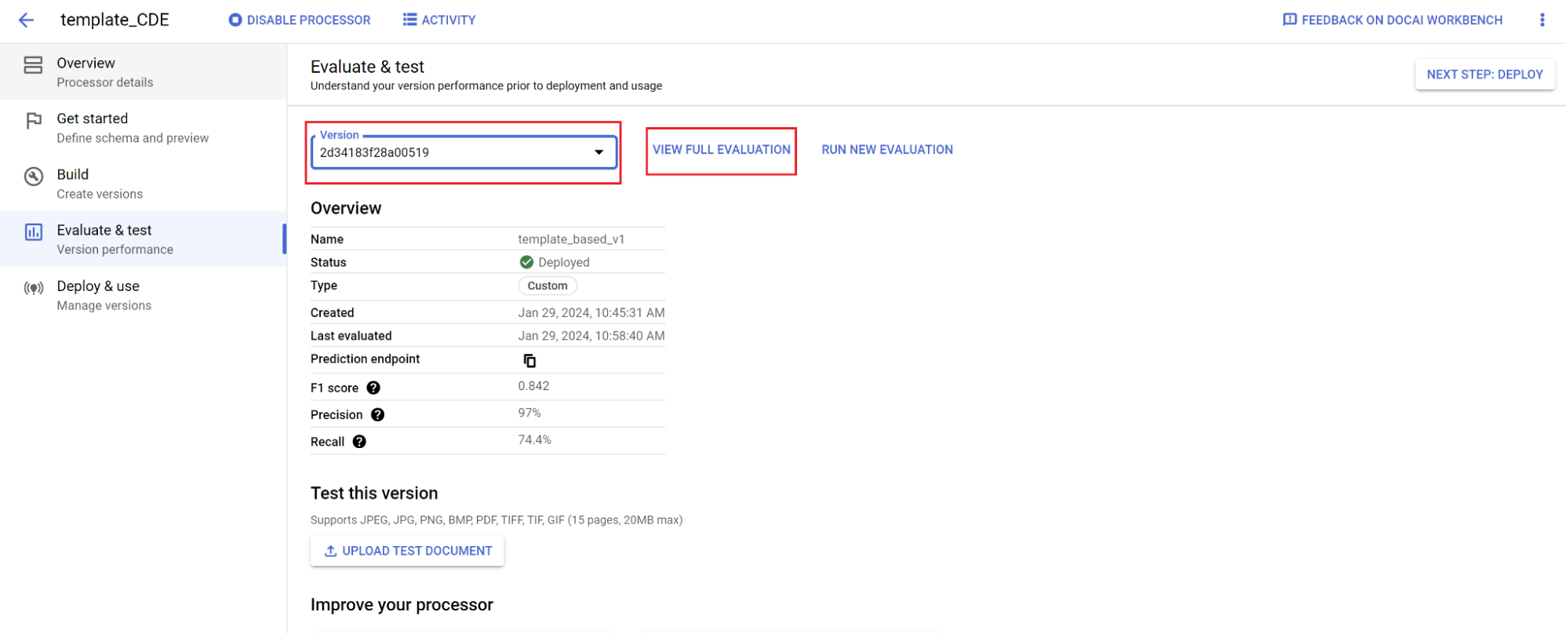
Ahora puede ver métricas como F1, precisión y recuperación de todo el documento y de cada campo. 1. Decide si el rendimiento cumple tus objetivos de producción y, si no es así, vuelve a evaluar los conjuntos de entrenamiento y de prueba.
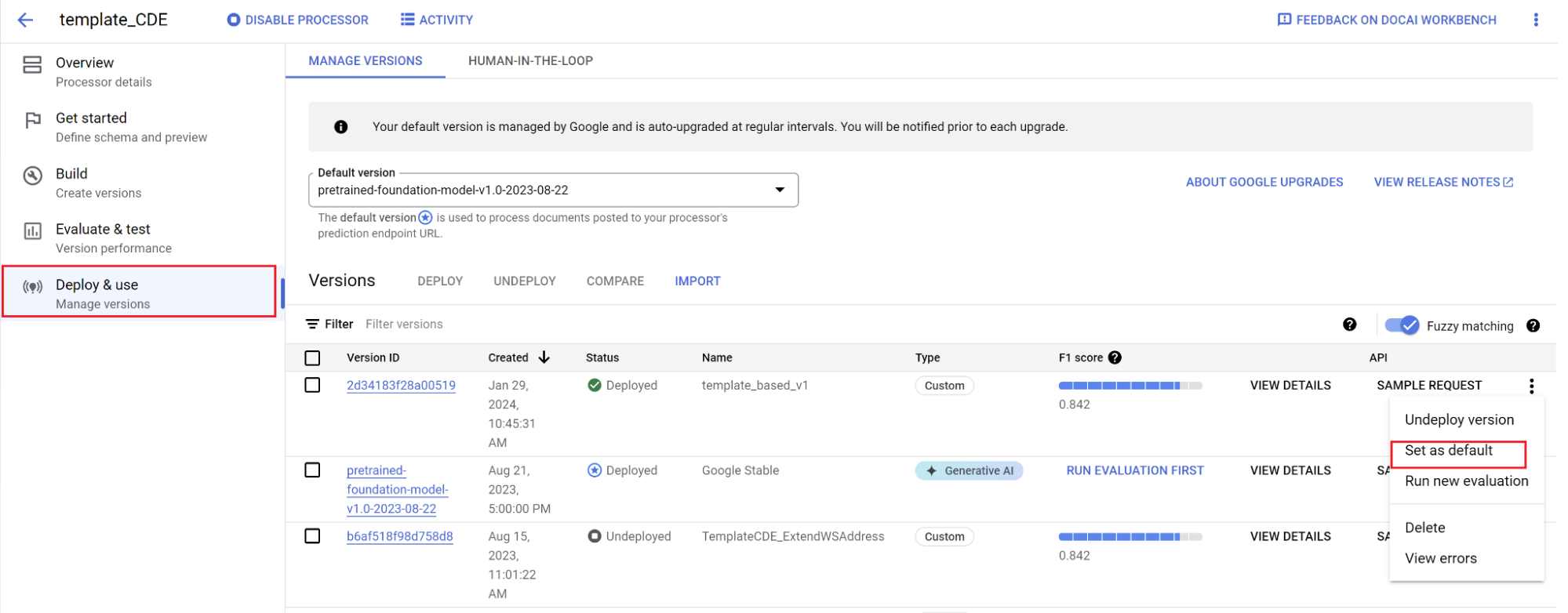
Definir una nueva versión como predeterminada.
- Vaya a Gestionar versiones.
- Selecciona para ver el menú de configuración y, a continuación, marca Definir como predeterminado.
Tu modelo ya se ha implementado y los documentos enviados a este procesador usan tu versión personalizada. Quieres evaluar el rendimiento del modelo (más información sobre cómo hacerlo) para comprobar si necesita más entrenamiento.
Referencia de evaluación
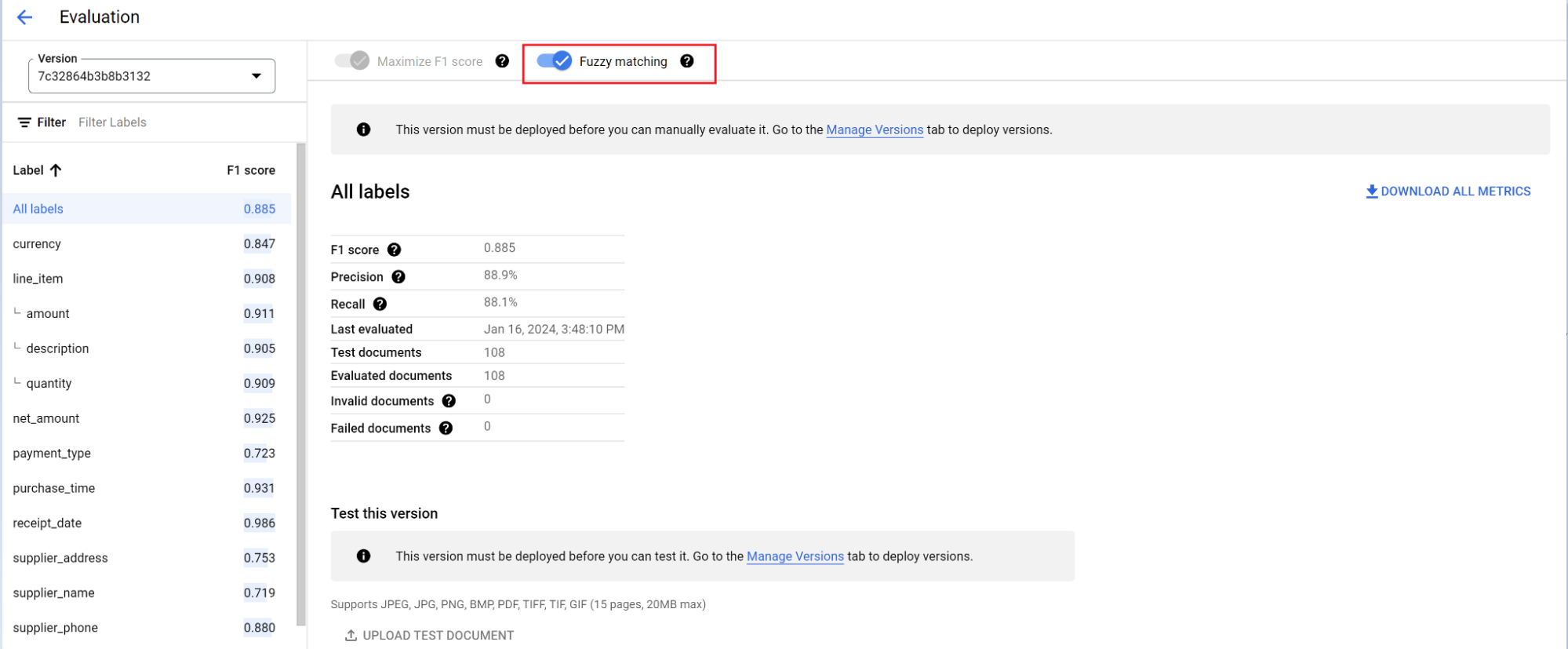
El motor de evaluación puede realizar tanto la concordancia exacta como la concordancia aproximada. Para que haya una coincidencia exacta, el valor extraído debe coincidir exactamente con el valor de referencia o se contabiliza como un error.
Las extracciones de coincidencias aproximadas que tenían pequeñas diferencias, como diferencias en el uso de mayúsculas y minúsculas, siguen contando como coincidencias. Puedes cambiarlo en la pantalla Evaluación.
Etiquetado automático con el modelo fundacional
El modelo base puede extraer campos de forma precisa para varios tipos de documentos, pero también puedes proporcionar datos de entrenamiento adicionales para mejorar la precisión del modelo en estructuras de documentos específicas.
Document AI usa los nombres de las etiquetas que definas y las anotaciones anteriores para que sea más rápido y fácil etiquetar documentos a gran escala con el etiquetado automático.
- Después de crear un procesador personalizado, vaya a la pestaña Empezar.
Selecciona Crear campo.
Ve a la pestaña Crear y selecciona Importar documentos.
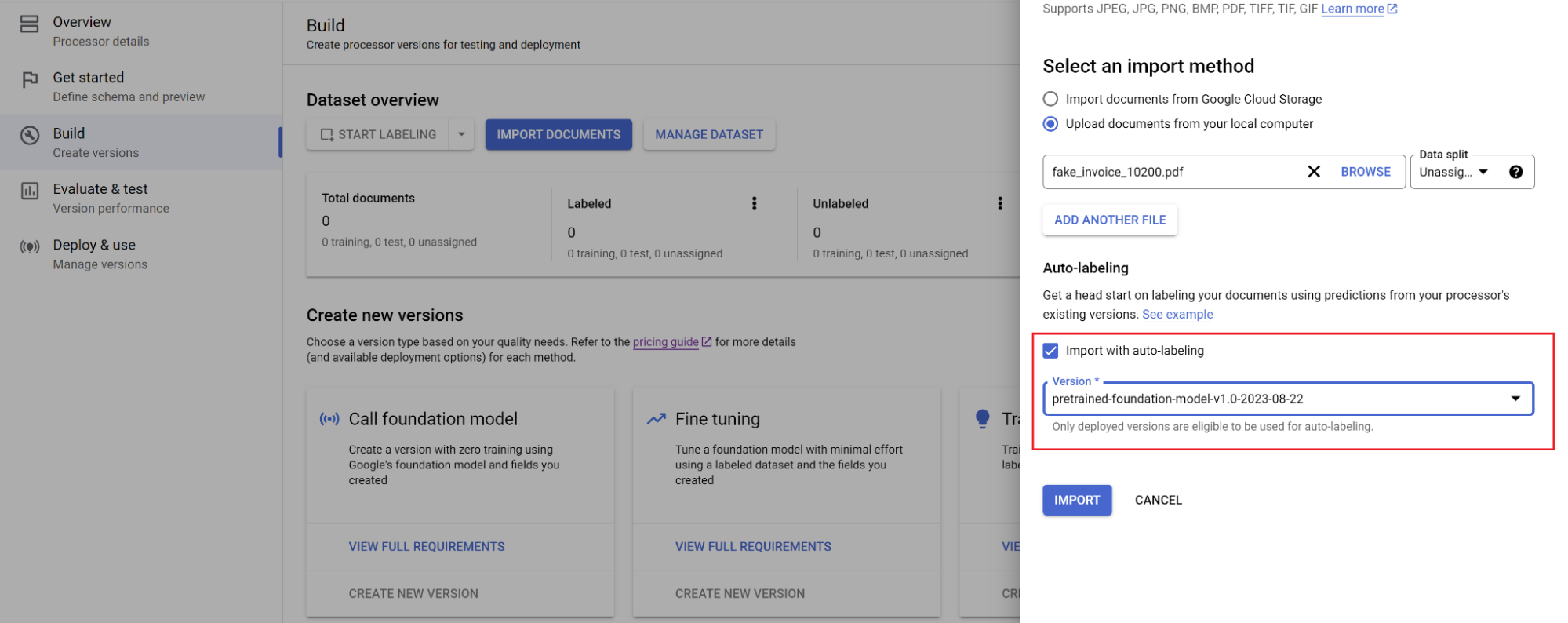
Selecciona la ruta de los documentos y el conjunto al que se deben importar. Marca la casilla de etiquetado automático y selecciona el modelo base.
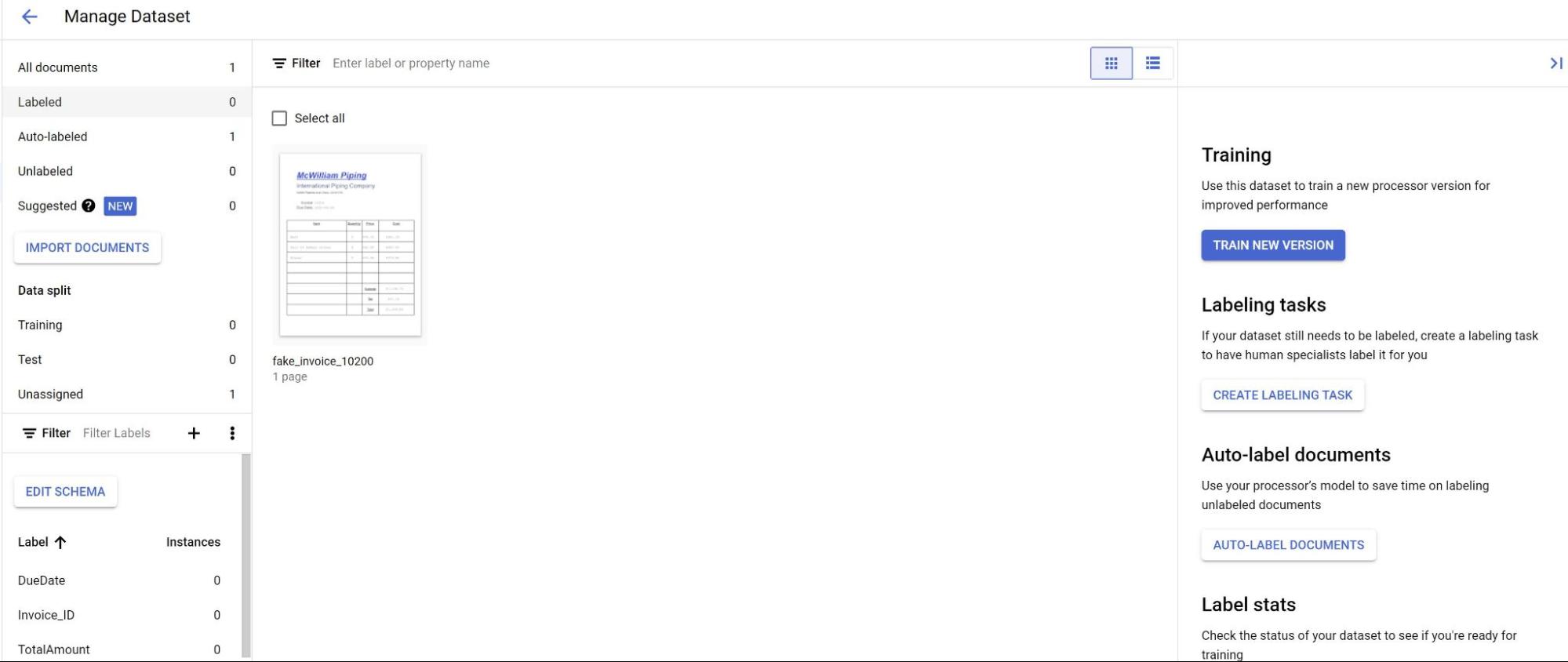
En la pestaña Crear, selecciona Gestionar conjunto de datos. Deberían aparecer los documentos que has importado. Selecciona uno de tus documentos.
Las predicciones del modelo se resaltan en morado. Debes revisar cada etiqueta predicha por el modelo y asegurarte de que sea correcta. Si faltan campos, también debes añadirlos.
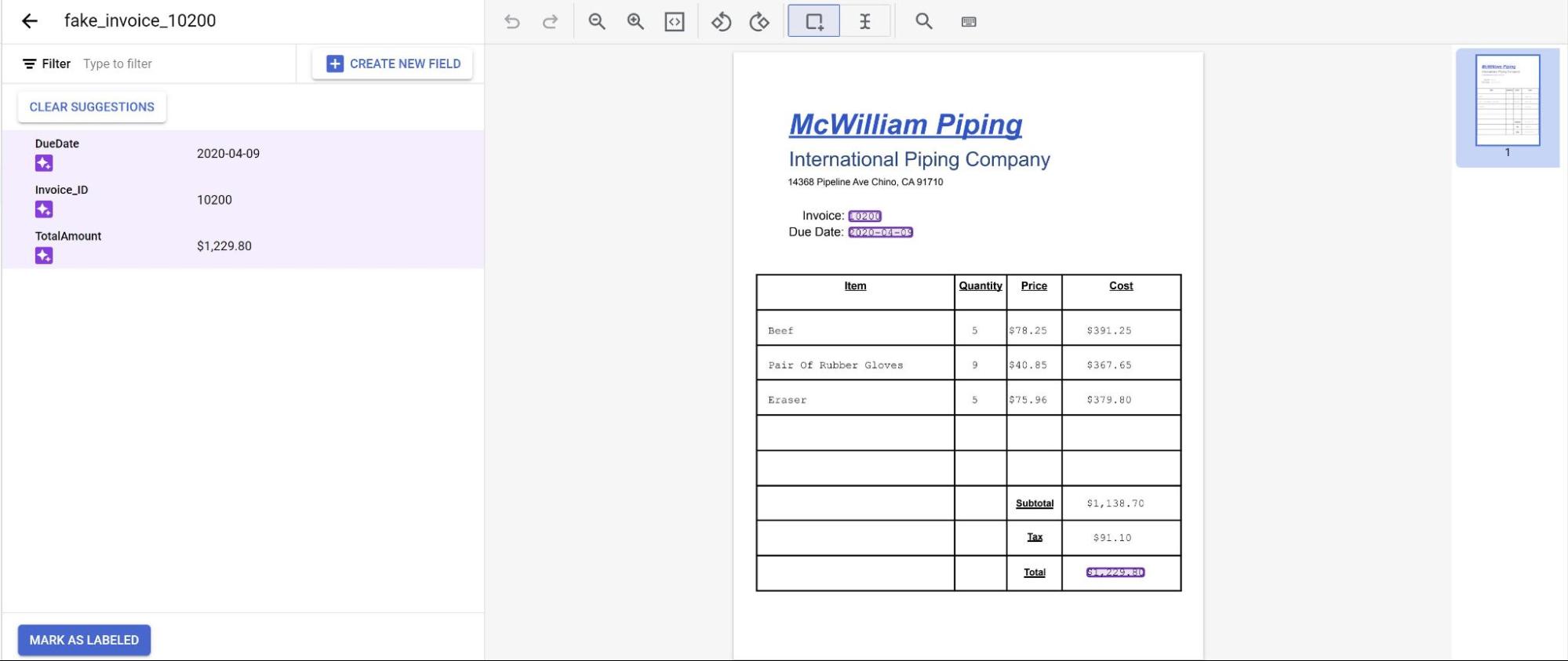
Una vez que se haya revisado el documento, selecciona Marcar como etiquetado.
El documento ya está listo para que lo use el modelo. Asegúrate de que el documento esté en el conjunto de pruebas o en el de entrenamiento.